英伟达(NVIDIA)的GPU产品线庞大而复杂,从游戏娱乐到专业设计,再到引爆全球的AI大模型训练与推理,不同型号对应着截然不同的应用场景和性能需求。面对GeForce、RTX Pro、L系列、H系列以及各种中国特供版,你是否感到眼花缭乱?
本文旨在为你提供一份清晰的导航图,系统梳理NVIDIA五大产品线的定位、核心规格与选型逻辑。无论你是游戏玩家、内容创作者、AI工程师还是企业IT采购,都能在这里找到匹配你需求的GPU答案。
核心逻辑:抓住三个关键
在深入细节之前,请先记住驱动所有选型决策的三个核心物理维度:
- 显存容量:决定你能装载多大的模型或场景数据。装不下,一切免谈。
- 计算算力:决定数据处理的速度,通常以TFLOPS(每秒万亿次浮点运算)衡量。
- 互连带宽:在多GPU协作场景(尤其是大模型训练)中,决定数据交换的效率,瓶颈往往是NVLink或PCIe带宽。
产品线速览
- 消费级(GeForce):为游戏玩家和创作者设计,性价比高,支持实时光线追踪和DLSS超分辨率技术。
- 工作站级(RTX Pro):面向专业视觉领域(如CAD、影视特效),具备大显存、ECC纠错和ISV专业软件认证。
- 推理卡(L/T系列):为数据中心AI推理服务优化,追求高吞吐、低延迟和优异的能效比。
- 训练卡(B/H/A系列):AI大模型训练的引擎,拥有极高的计算密度和高速多卡互连能力。
- 中国特供版:为符合出口管制法规而推出的合规版本,在核心规格上有所调整。
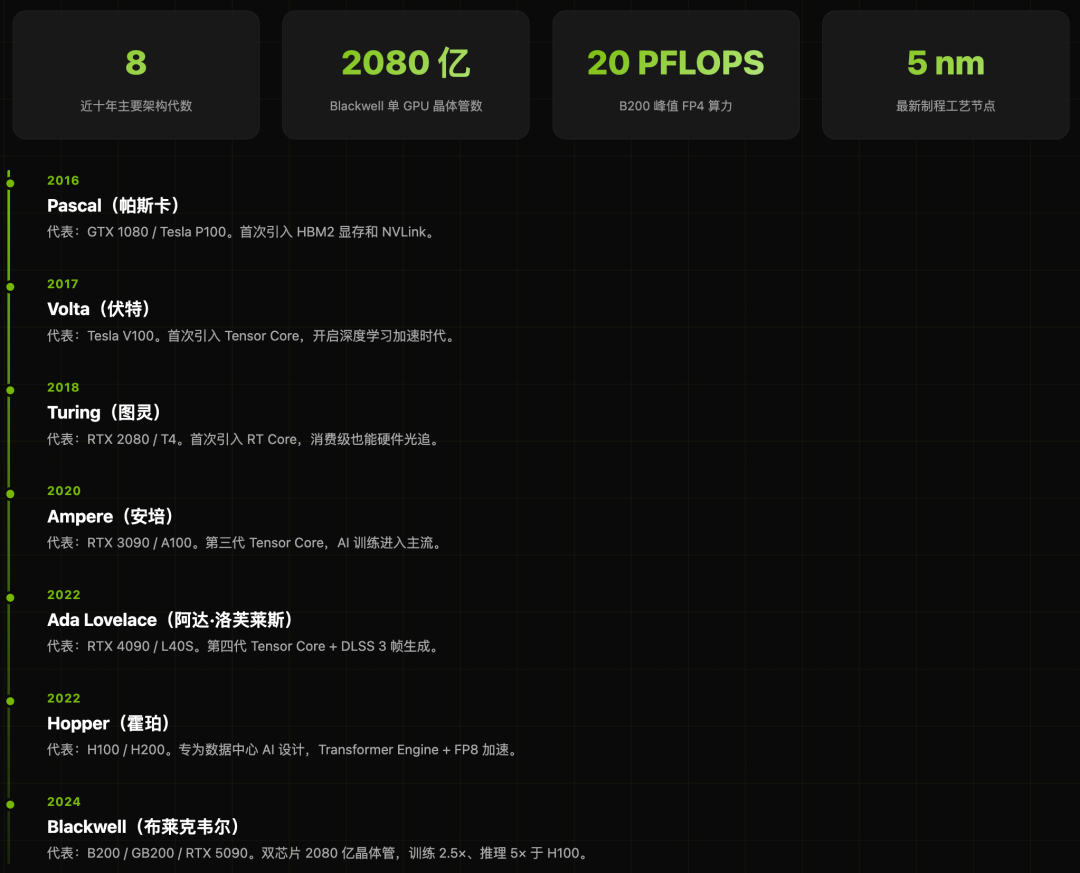
命名规则解密
理解命名规则是快速识别芯片定位的第一步。

关键硬件概念
在对比具体型号前,了解这些核心规格的含义至关重要。

1. 消费级 GPU(GeForce系列)
面向个人用户,是游戏、直播、视频剪辑和轻量级AI应用的性价比之选。最新一代基于Blackwell架构的RTX 50系列已发布。
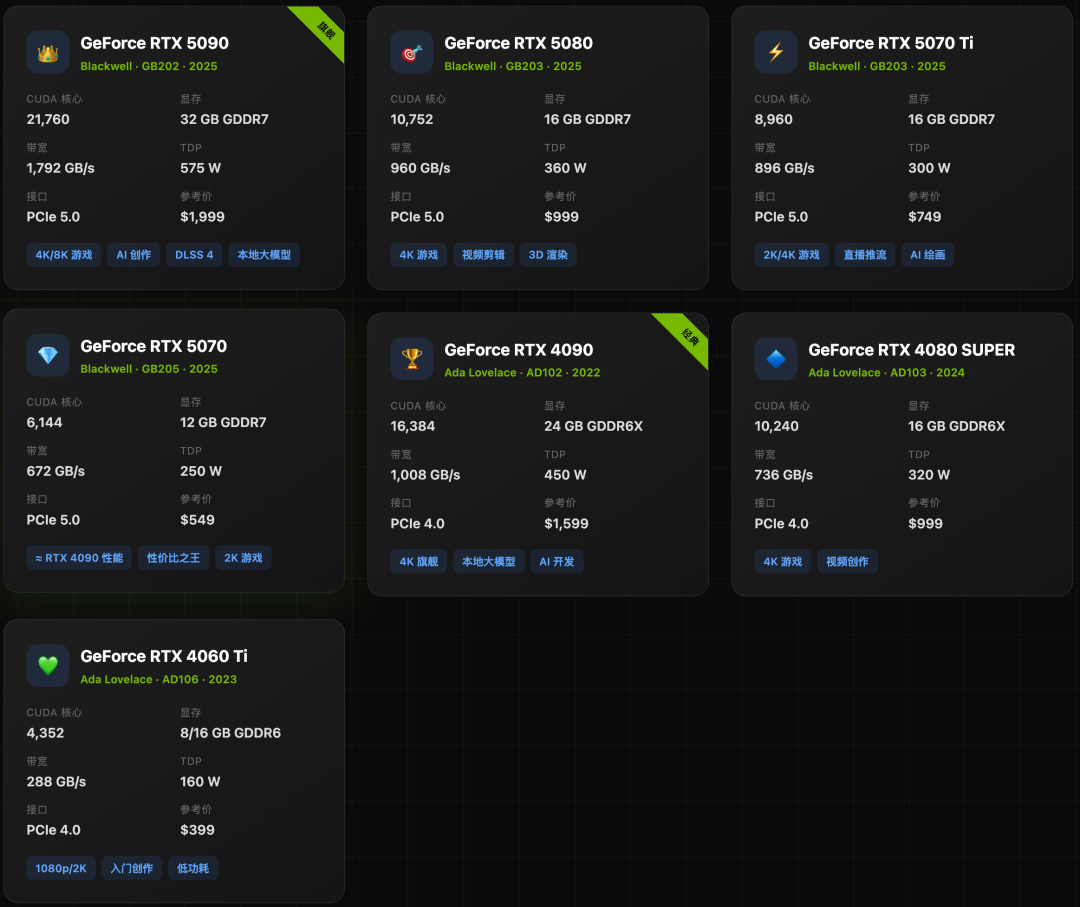
选购要点:
- 游戏玩家:关注CUDA核心数、光追核心(RT Core)性能以及DLSS版本。RTX 50系列引入了DLSS 4和多帧生成技术,帧率提升显著。
- AI创作者:运行Stable Diffusion等AI绘画工具或本地大语言模型时,显存容量是关键。RTX 5090的32GB GDDR7显存使其成为消费级AI应用的新王者。
2. 专业工作站 GPU(RTX Pro系列)
为专业应用而生,通过了各类专业软件(如AutoCAD, Maya, SOLIDWORKS)的ISV认证,确保稳定性和兼容性。搭载ECC显存,防止长时间渲染中出现数据错误。
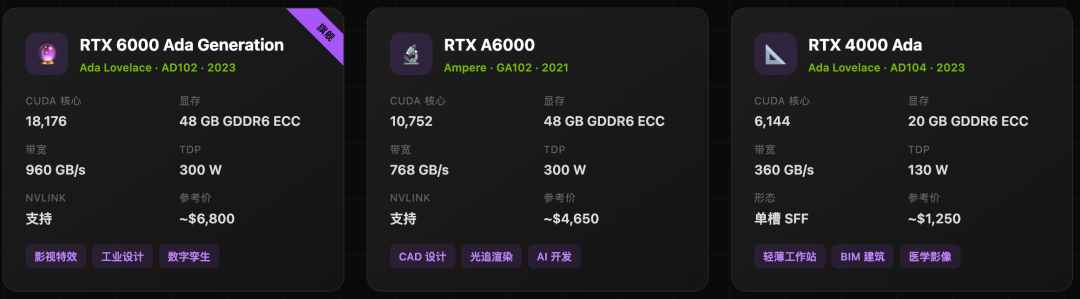
适用场景:建筑信息模型(BIM)、工业设计、影视特效渲染、科学可视化等需要处理超大规模数据集和精确计算的领域。
3. 推理加速卡(L/T系列)
部署在云端或边缘数据中心,专门用于处理训练好的AI模型,执行像ChatGPT对话、图像识别、视频分析等任务。它们极度优化了整数(INT8)和低精度浮点(FP8)运算的能效比。
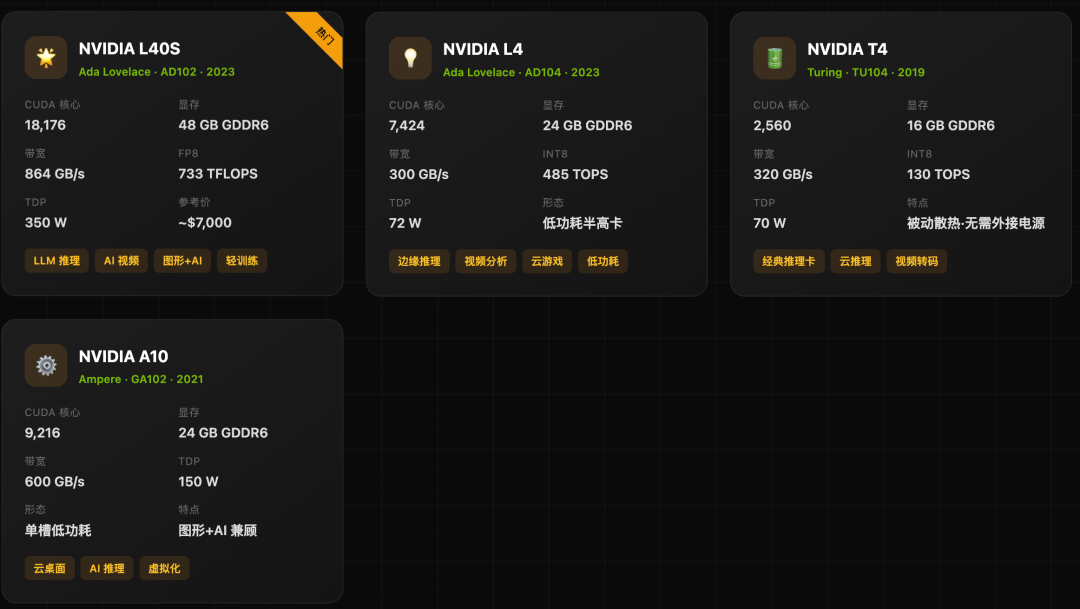
系列特点:
- L40S:全能型推理卡,兼顾图形与AI计算,适合AI视频生成、云游戏等混合负载。
- L4:低功耗设计的典范(仅72W),适合高密度部署的云端推理和视频转码。
- T4:经典的推理卡,采用被动散热,无需外接供电,至今仍在许多云服务中广泛使用。
4. 训练旗舰卡(B/H/A系列)
它们是创造AI大模型的“炼金炉”。GPT-4、Llama等模型的诞生,背后是成千上万张这类GPU集群数月乃至数年的持续运算。其核心在于强大的Tensor Core和超高的多卡互连带宽(NVLink)。
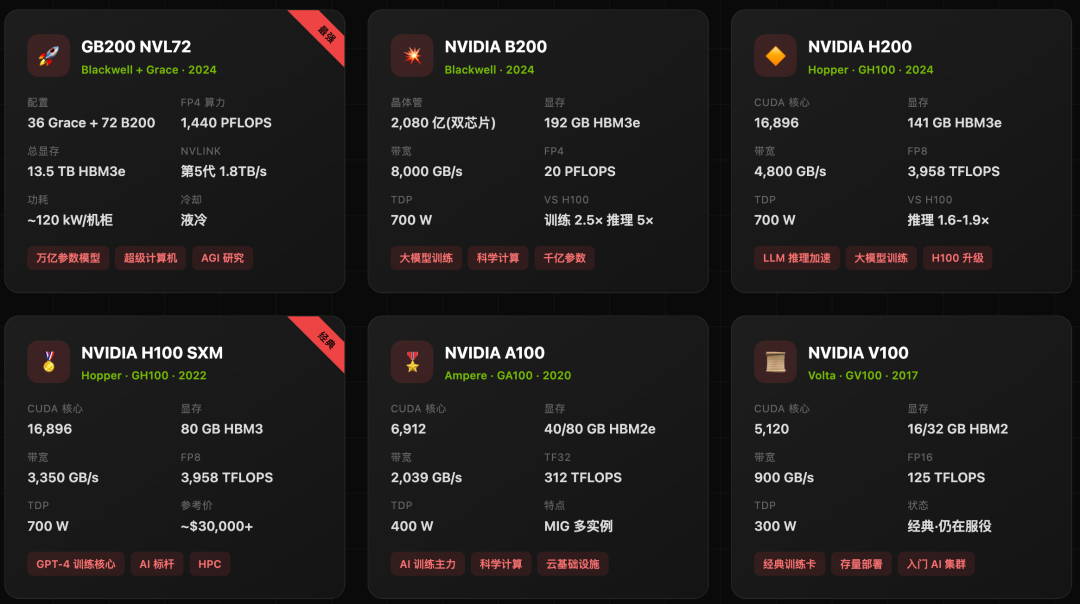
代际演进:
- B200 (Blackwell):2024年发布,采用双芯片设计,晶体管数量高达2080亿,在AI训练和科学计算领域实现了性能的跨越式提升,标志着人工智能计算进入新纪元。
- H100/H200 (Hopper):上一代AI训练标杆,H200主要将显存升级至141GB HBM3e,带宽更高,特别适合超大规模模型的推理。
- A100 (Ampere):经典的主力训练卡,引入了MIG(多实例GPU)技术,可将一张物理卡虚拟分割,仍在大量云基础设施和智能 & 数据 & 云计算集群中服役。
5. 中国特供版 GPU
为应对美国出口管制政策,NVIDIA推出了专门面向中国市场的合规版本。这些芯片在核心算力或互连带宽上进行了限制,但凭借其显存容量和生态优势,依然是国内AI产业发展的重要算力支撑。
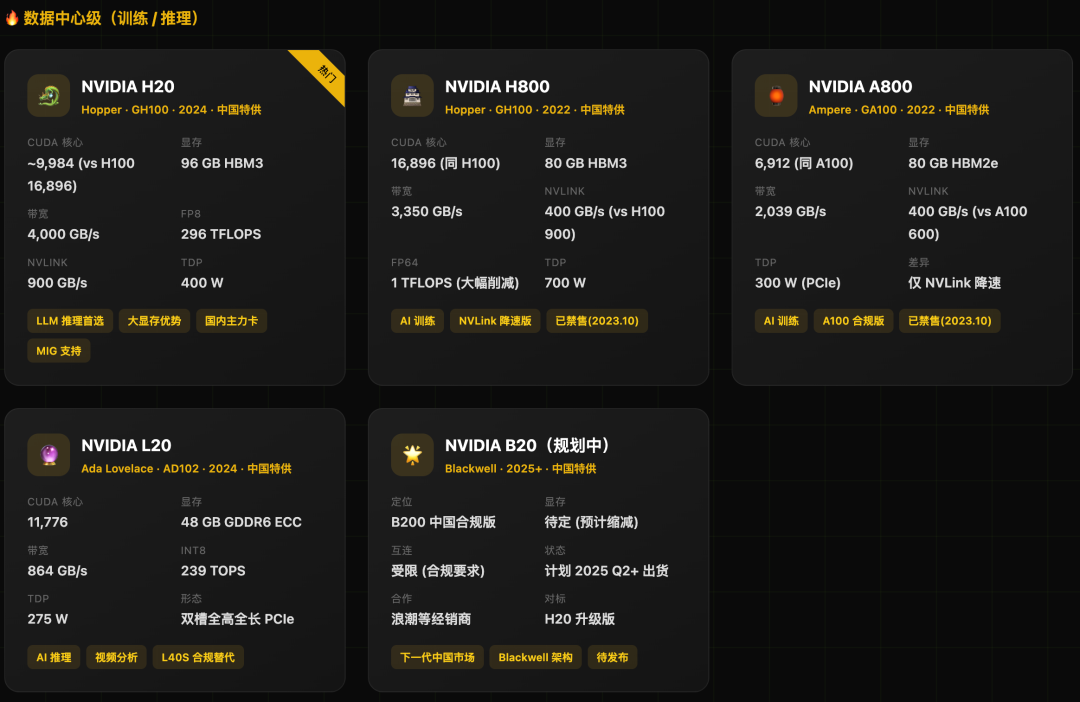
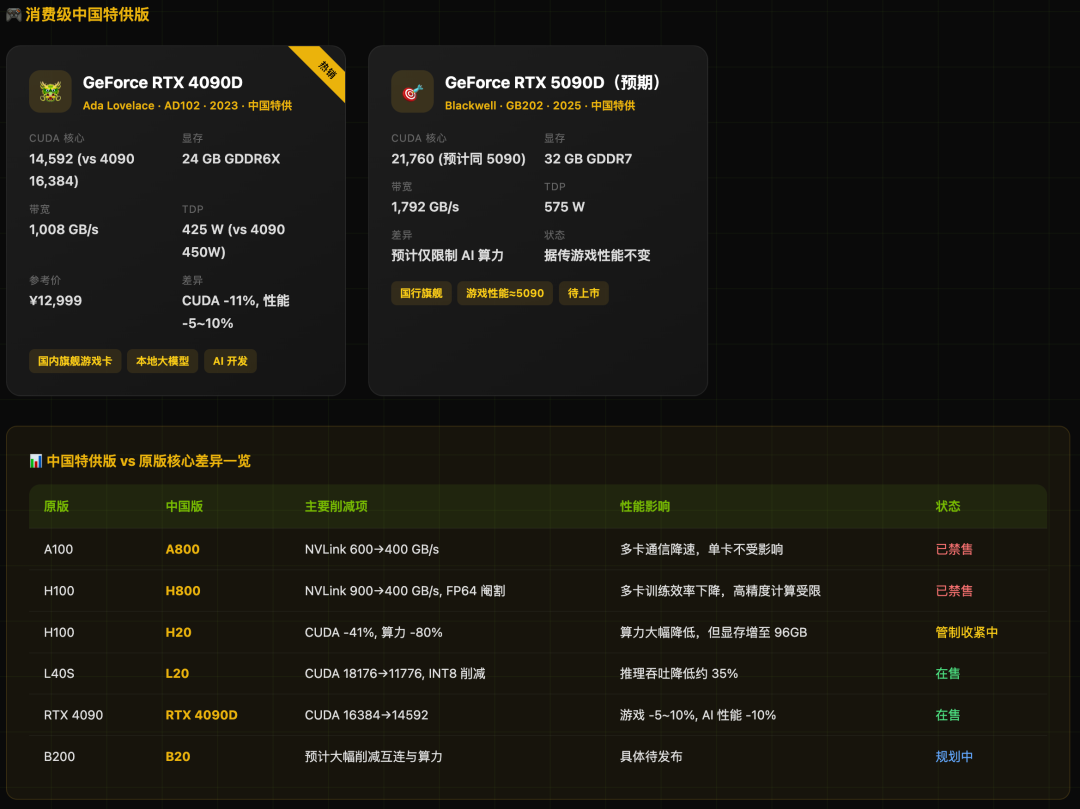
主要型号与特点:
- H20:当前国内AI推理的主力选择。虽然计算核心(CUDA)数量大幅削减,但拥有96GB HBM3大显存和4000 GB/s的高带宽,恰好匹配大语言模型推理(Memory-Bound)的特性,性价比突出。
- L20:作为L40S的合规替代,专注于推理场景。
- RTX 4090D:消费级旗舰的国内版本,主要削减了约11%的CUDA核心,游戏性能影响较小,但AI算力有所下降。
性能参数横向对比
将所有主流型号的关键规格汇总,方便快速查阅与对比。
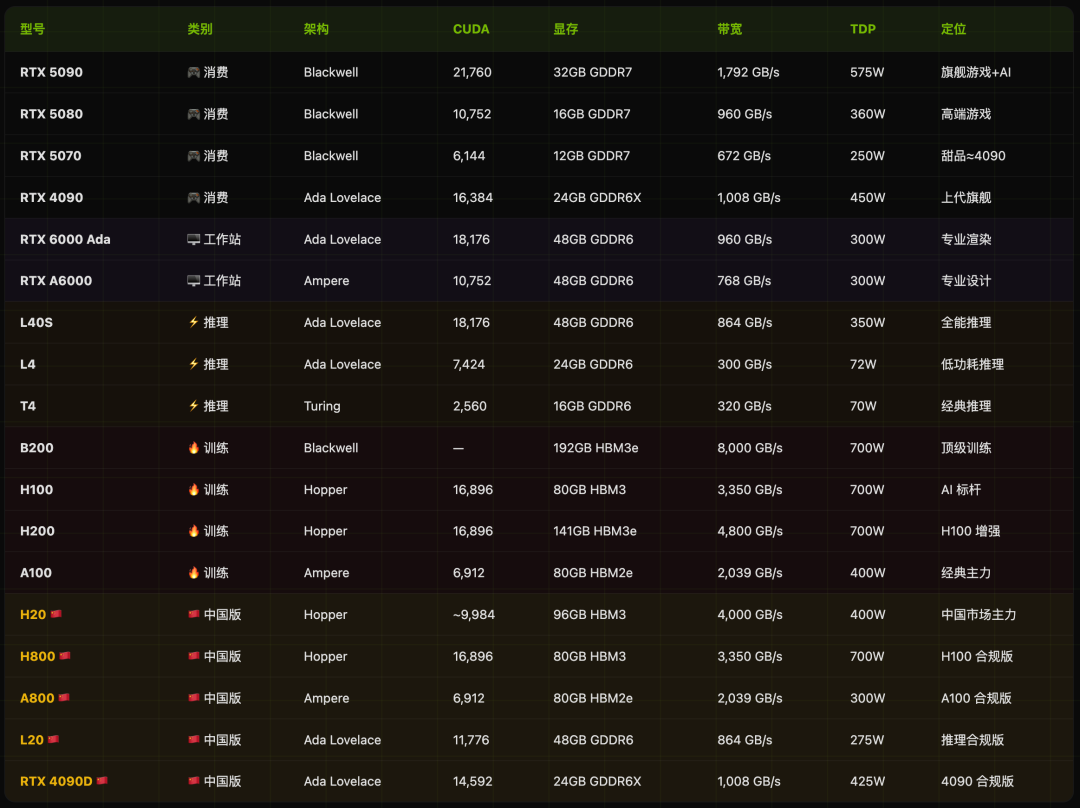
关键性能指标可视化
图形化展示更能直观感受不同型号在核心指标上的差距。
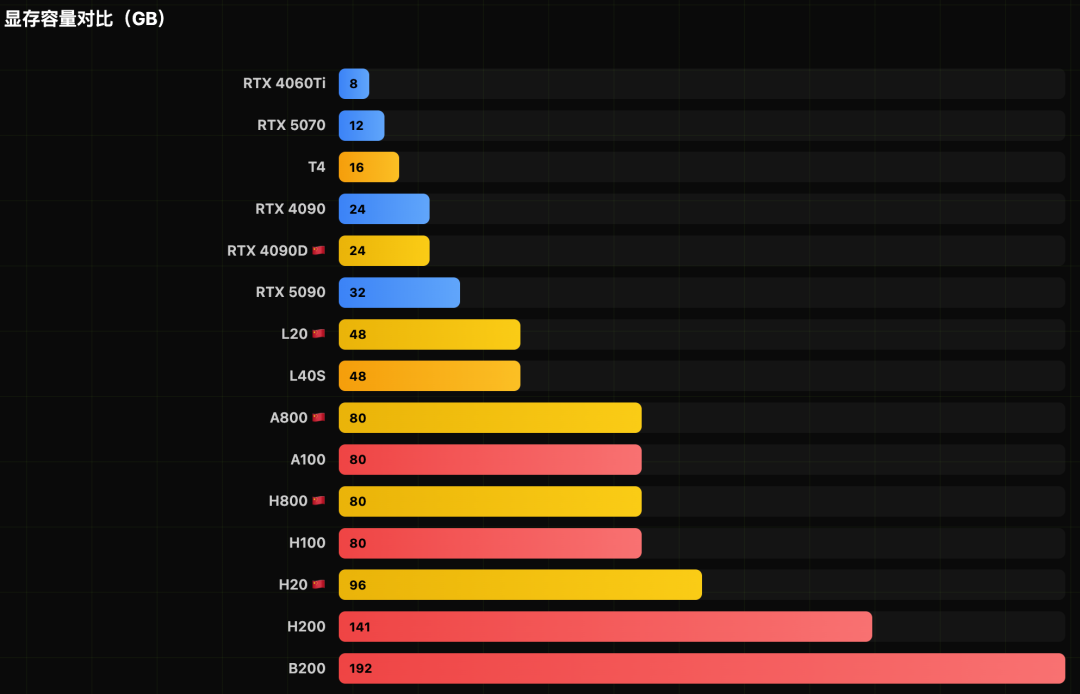
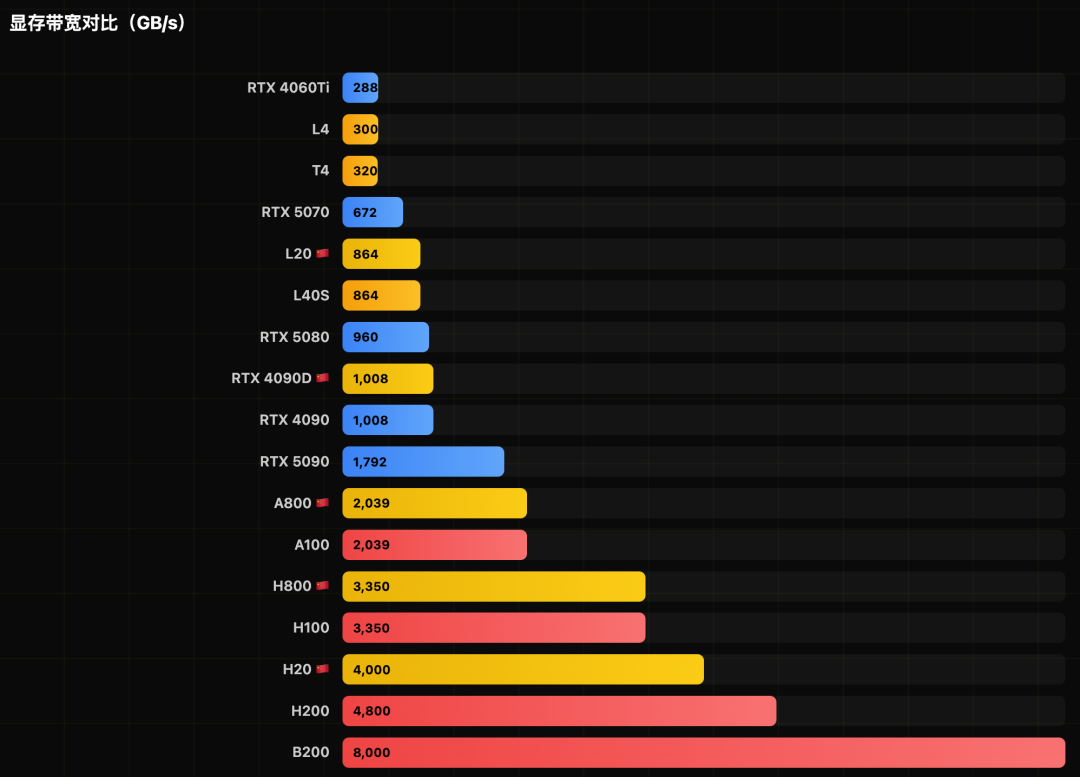
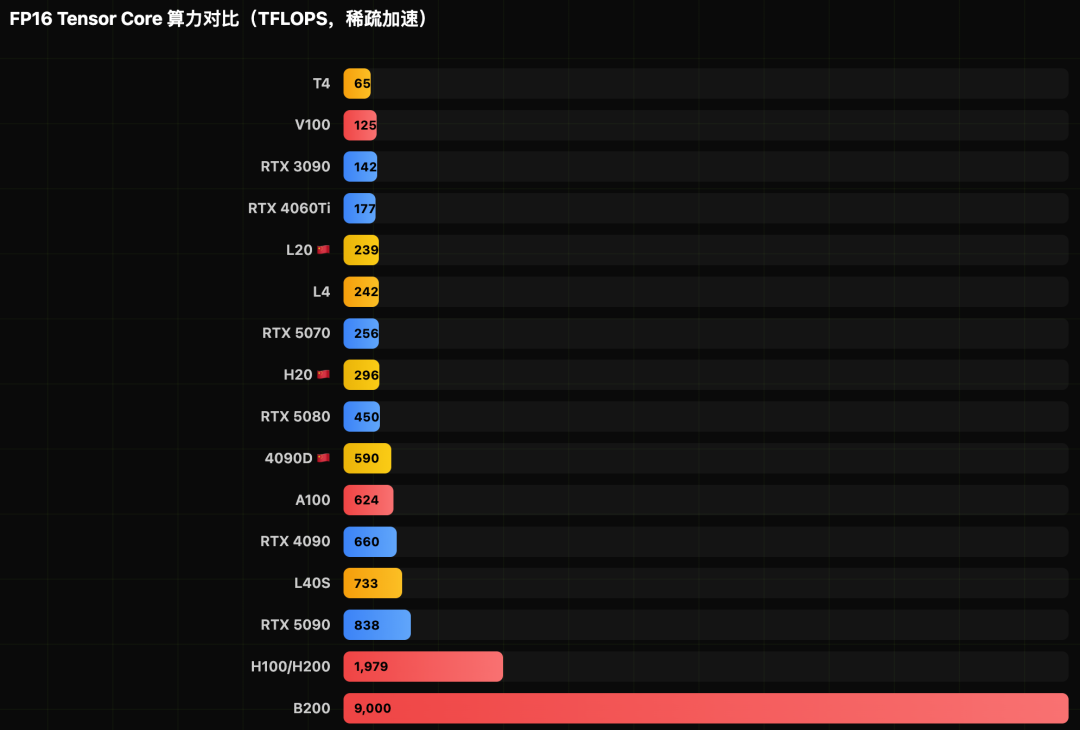
GPU算力深度排行与洞察
算力是衡量GPU绝对性能的核心。以下排行榜综合了FP32通用算力、FP16 Tensor Core AI算力、显存带宽及能效比。

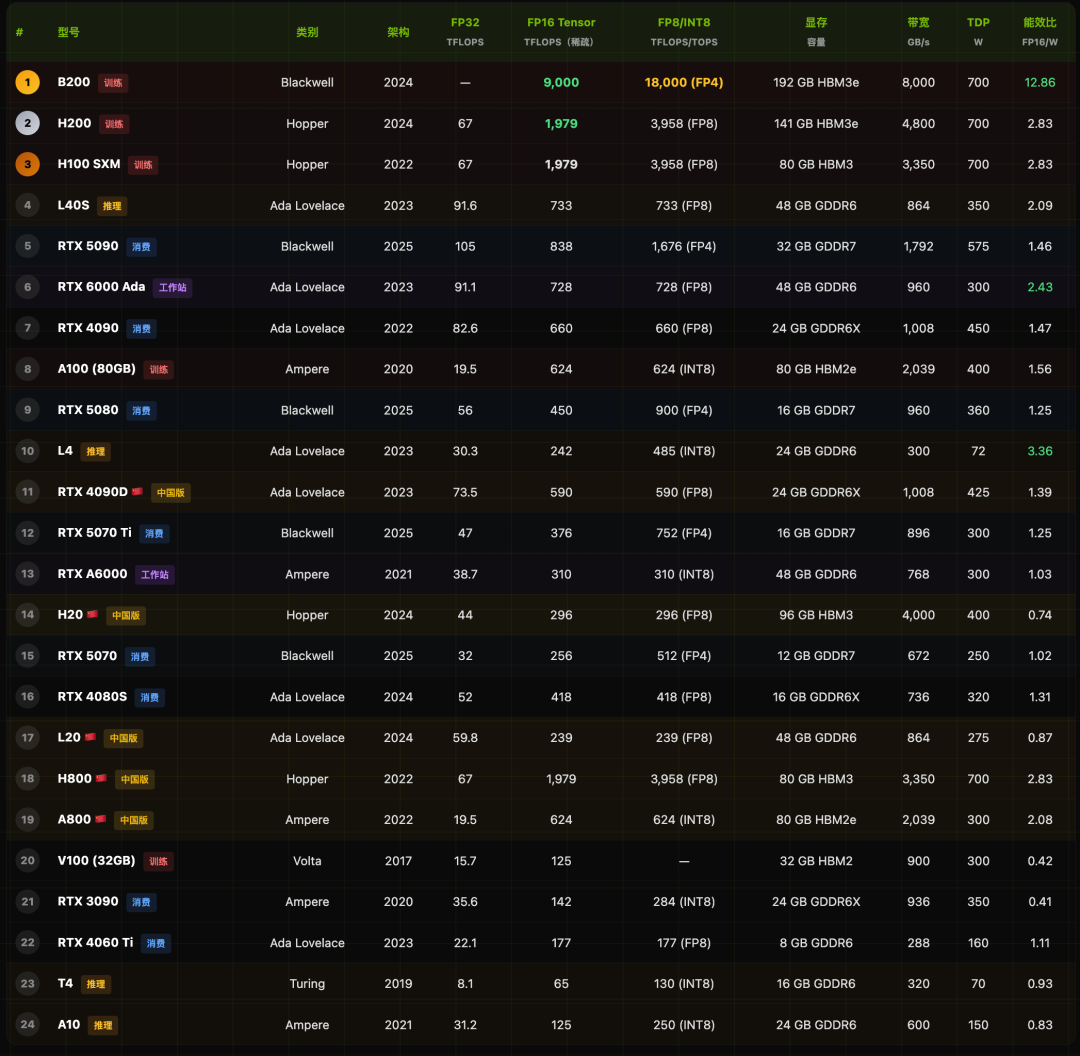
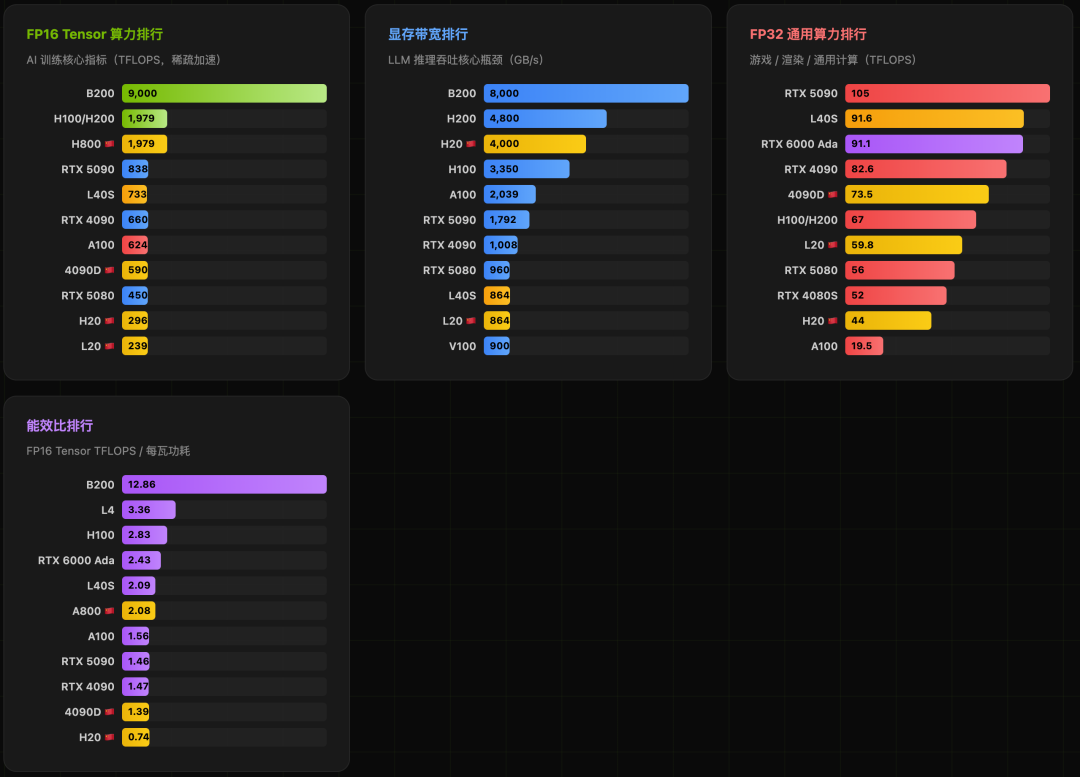
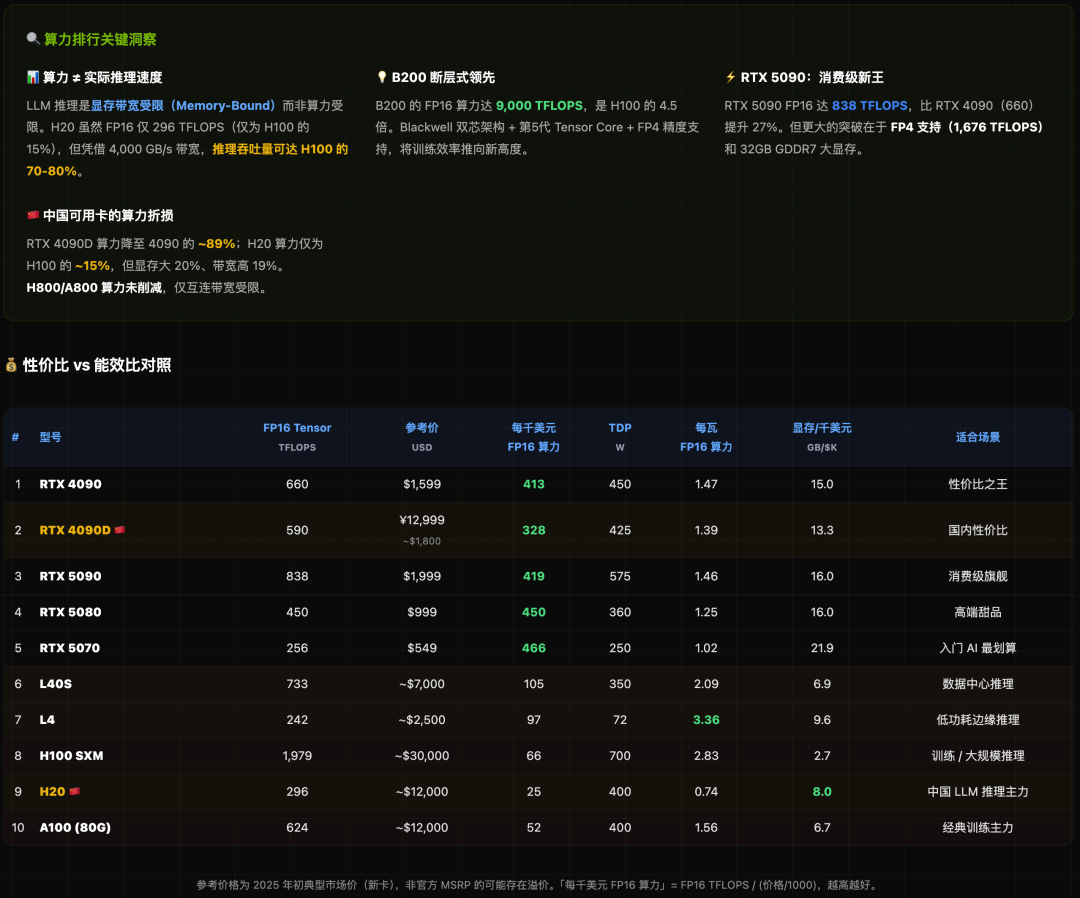
核心洞察:
- 算力≠推理速度:对于大语言模型(LLM)推理,瓶颈往往是显存带宽而非峰值算力。这就是为什么算力仅为H100约15%的H20,在实际LLM推理吞吐上能达到H100的70%-80%。
- B200断层领先:其FP16算力达9000 TFLOPS,是H100的4.5倍,重新定义了AI训练的速度。
- RTX 5090的突破:作为消费级新旗舰,其838 TFLOPS的FP16算力和对FP4精度的支持,让个人设备进行严肃的AI工作成为可能。
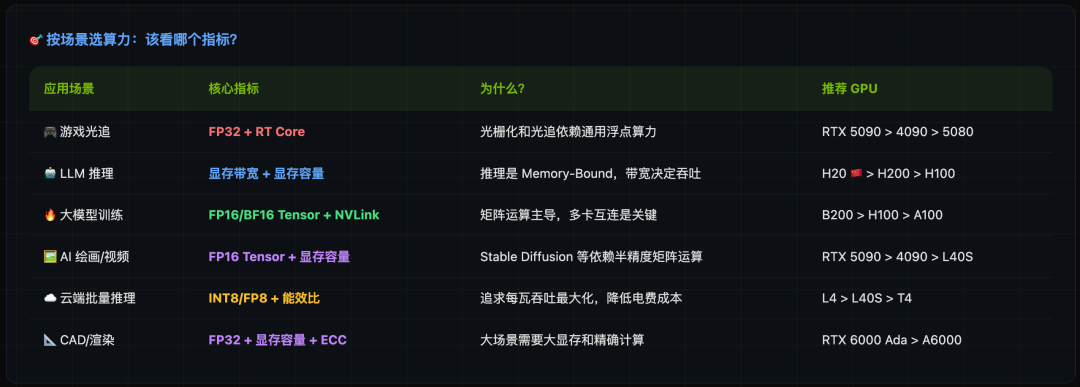
按应用场景选型
不同的任务对GPU能力的侧重点不同。选对指标,才能选对卡。
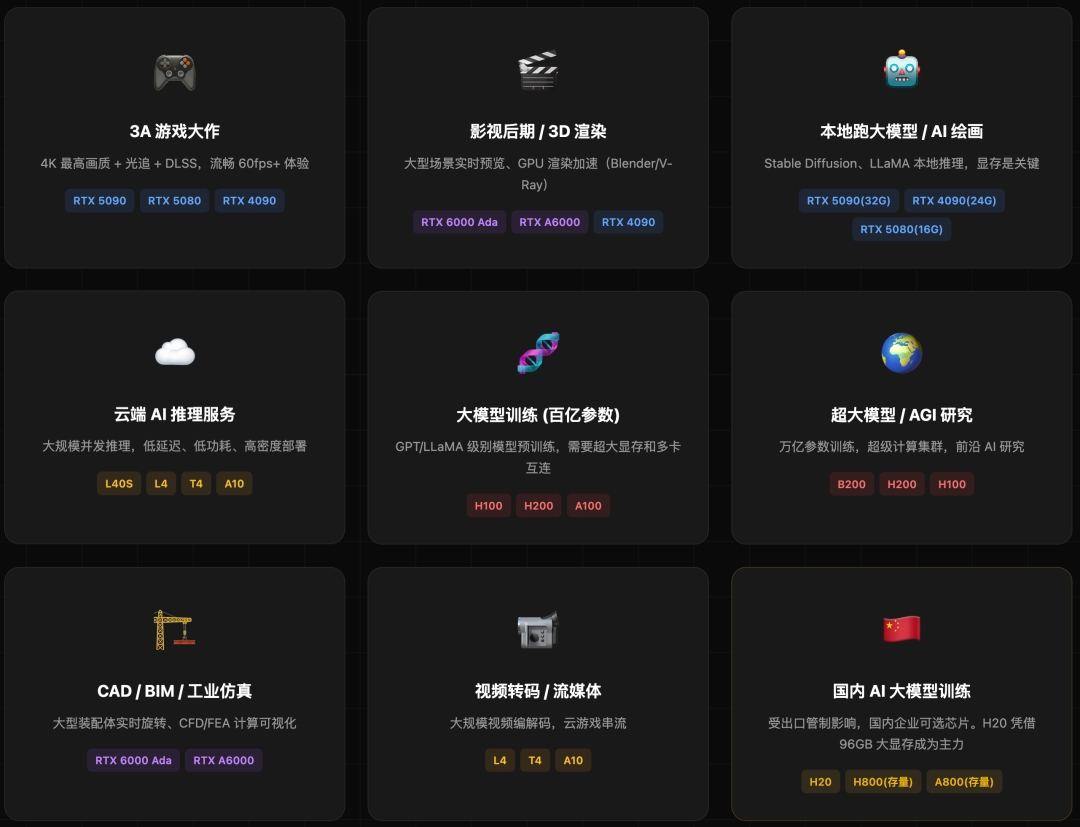
模型参数与GPU选择对照
这是AI开发者最关心的部分:我的模型,需要什么样的硬件?
显存需求估算公式:
显存需求 ≈ 模型参数量 × 每参数字节数(精度系数)× 安全系数(通常为1.2)

安全系数用于预留KV缓存(用于生成式推理)、激活值以及框架本身的开销。如果是全参数训练,还需要额外3-4倍的显存来存储梯度、优化器状态等。
以下是根据不同参数规模模型给出的硬件配置参考:
轻量级模型 (1.5B - 7B)
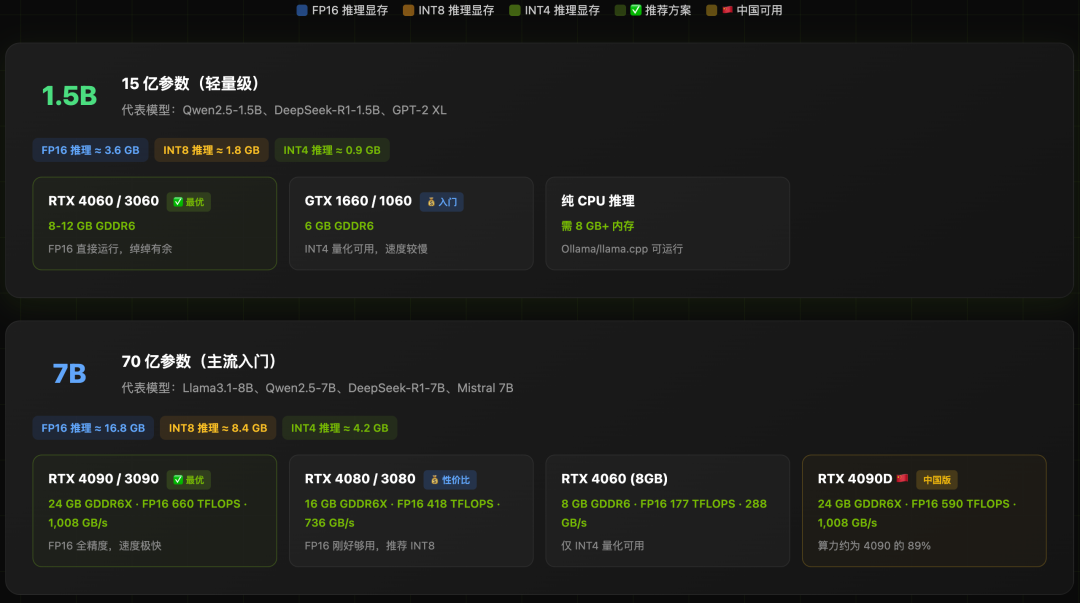
中等规模模型 (14B - 32B)
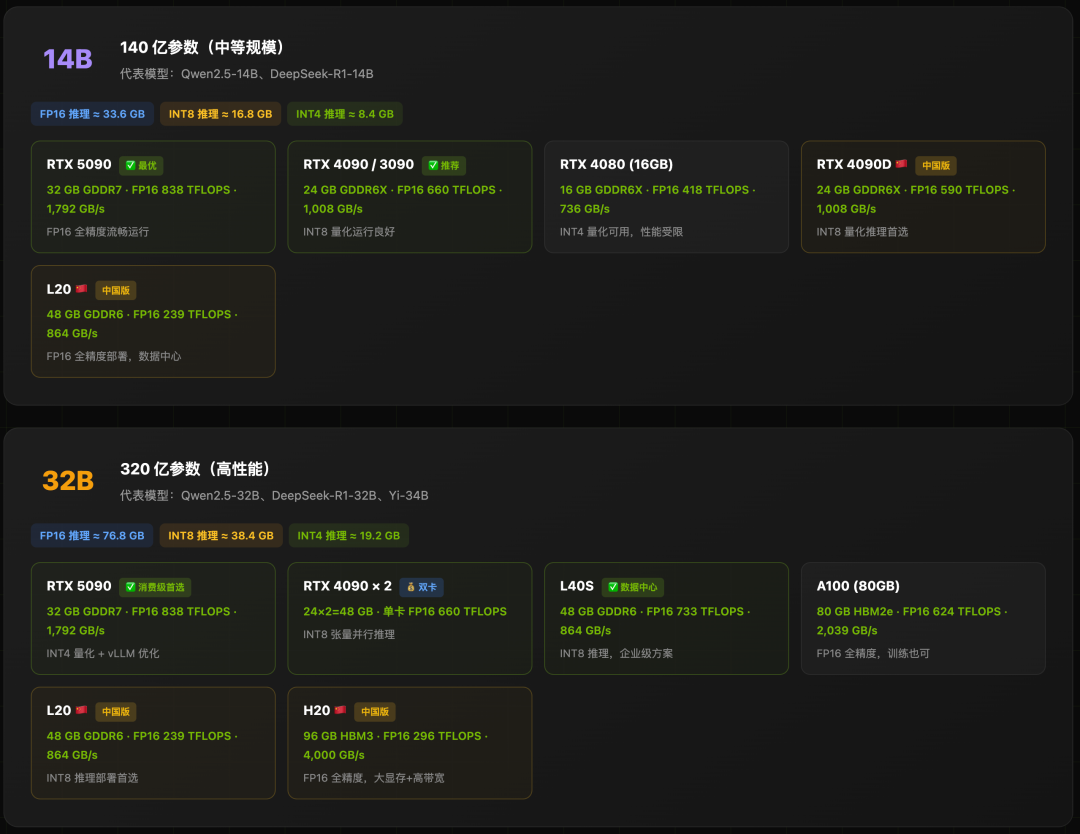
大规模与企业级模型 (70B - 千亿参数)
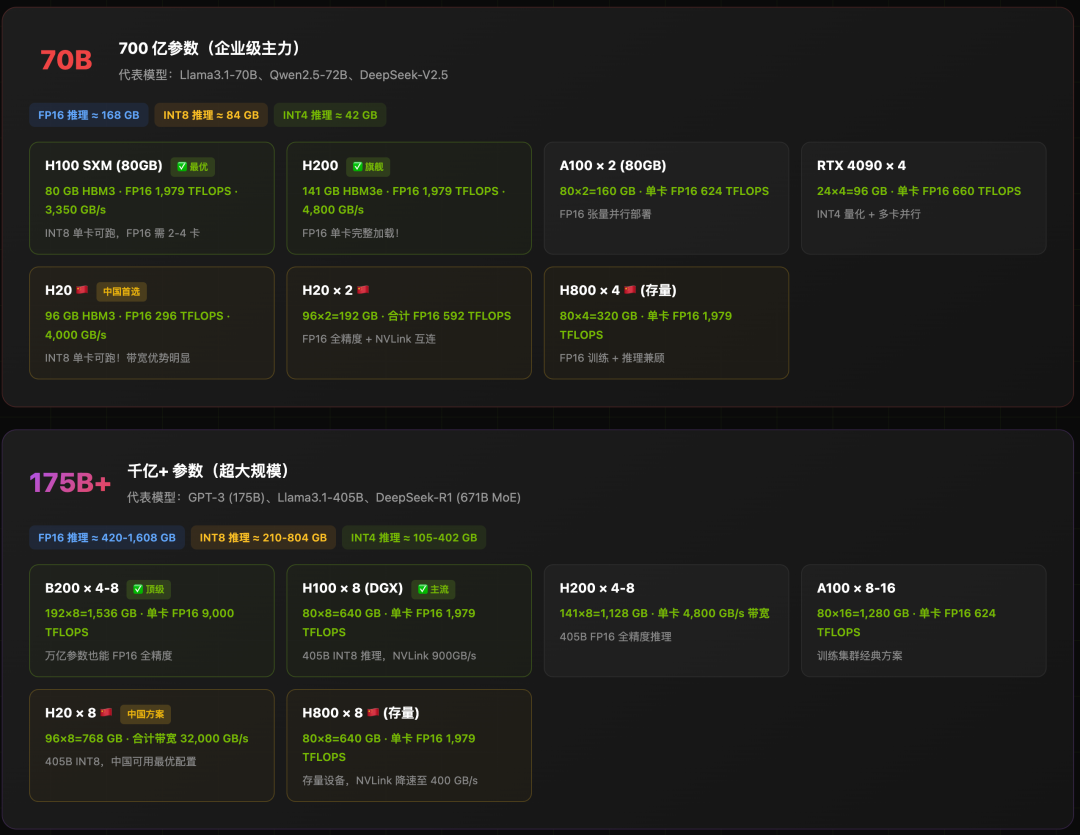
快速对照总表
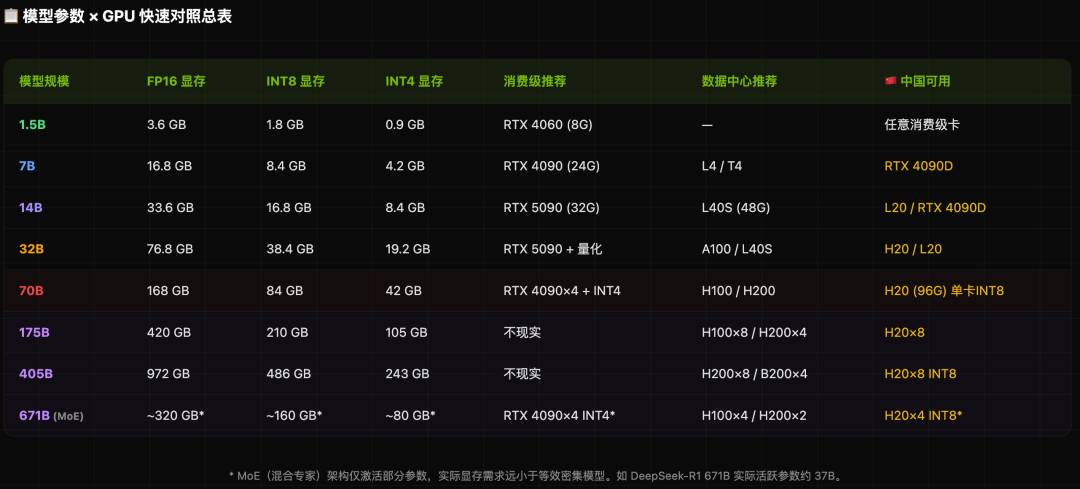
训练与推理的显存差异
理解推理(Inference)、全参微调(Full Fine-tuning)和高效微调(如LoRA)之间的显存需求差异,对于合理利用资源至关重要。

最终选购决策指南
如果看完以上所有信息仍然难以抉择,可以跟随这个简单的决策树快速定位。

最终建议:
对于AI相关场景,务必首先确认显存容量是否能满足你的模型需求,这是硬性门槛。其次,根据你的任务是训练还是推理,关注对应的算力指标(FP16/FP8)和互连带宽。对于游戏和专业图形应用,则更关注核心的通用计算性能(FP32)和特定的图形技术(如DLSS、RT Core)。
希望这份详尽的指南能帮助你拨开NVIDIA GPU世界的迷雾,做出最明智的硬件选择。技术迭代迅速,保持对底层参数逻辑的理解,才能以不变应万变。欢迎在云栈社区与更多开发者交流硬件选型与性能优化的实践经验。
数据说明:本文数据整理自NVIDIA官方资料及公开报道,参考价格为发布时建议零售价(MSRP),实际市场价格可能因供需关系变化。中国特供版信息基于公开报道整理,规格可能随出口管制政策调整。内容仅供参考,不构成任何购买建议。
 发表于 2026-3-21 02:00:04
|
查看: 156|
回复: 0
发表于 2026-3-21 02:00:04
|
查看: 156|
回复: 0
