
表面上,人们正热衷于“养龙虾”(OpenClaw);而水面之下,一场围绕底层AI基础设施(AI Infra)的硬仗已经打响。
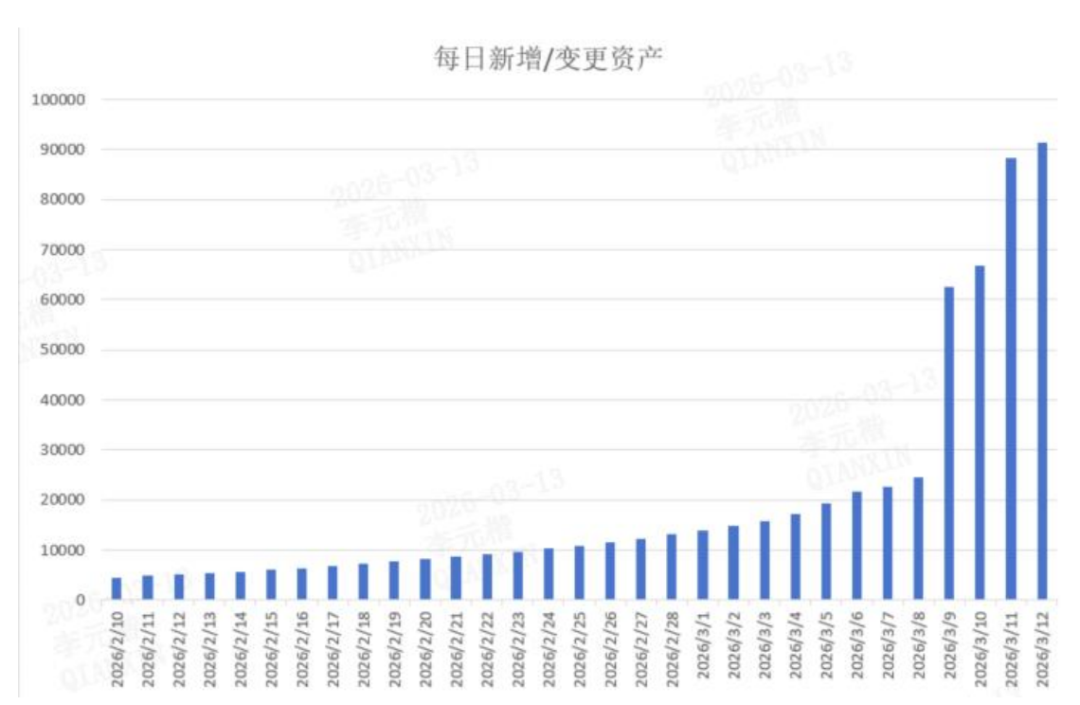
“龙虾(OpenClaw)”无疑是当下最火的现象级关键词。短短一个多月,其微信指数从1月29日的0一路飙升至3月10日的1.656亿,热度呈爆发式增长。截至3月20日,OpenClaw在GitHub上已收获32.5万颗星,登顶平台榜首。奇安信的报告显示,全球每日新增部署实例从5000跃升至9万,增长高达18倍;其中,美国和中国成为最主要的两大阵地,合计占比超过65%。
从技术圈到大众生活,“养龙虾”正在迅速出圈。各大厂商纷纷推出自己的Claw版本,从云端部署到本地托管,层出不穷。政务单位、科研院所乃至企业也迅速跟进,推出各类专用Claw,并将明星业务封装为Skills接入开放生态。截止3月中旬,GitHub上已有超过2.5万个Skills,OpenClaw官方技能平台ClawHub上的数量也接近2.8万个。
然而,在这股狂热之下,却隐藏着看不见的硝烟。OpenClaw的爆红,正将前所未有的压力传导至底层的AI Infra。
一只“龙虾”,搅动全球AI Agent生态
伴随着OpenClaw进入千行百业,越来越多人意识到,它或许不止是一款走红的产品,更可能是一个时代的拐点,将对AI Agent的落地产生全方位影响。
过去两三年,Agent的落地并不算顺利。但OpenClaw的出现,提供了一个开源、不限制模型与渠道、全面开放技能(Skills)的Agent模式,迅速让全行业达成了共识。人们已经开始用它解决复杂甚至无人问津的长尾问题。
“未来软件可能变得很碎片化,但解决问题的软件方案却变得高度统一,就是通过OpenClaw框架把Skills整合起来。”百度集团执行副总裁沈抖观察到,“谁懂业务、谁能把解决问题的方案变成Skills,谁就能在整个生态中取得最大收益。”
在这样的态势下,曾经移动互联网时代的“流量孤岛”,有望被OpenClaw连成一片大陆。毕竟,没有应用厂商敢忽略这个潜在的超级入口。
除了软件,OpenClaw也快速跑入了各类硬件,从小度音箱、宇树机器人到华为手机、联想PC,它有望打破硬件间的壁垒,形成一个更宏大的统一智能生态。也因此,英伟达创始人黄仁勋在最近的GTC大会上明确表态“OpenClaw是适用于个人AI的操作系统”,并抛出一个让所有CEO都必须思考的问题:“你的OpenClaw战略是什么?”
显然,以OpenClaw为代表的智能体,已经带我们进入了一个新的时代。
“Token粉碎机”,源自其独特模式
就在这场全民“养虾”热蔓延的同时,一个现实问题也随之浮现:OpenClaw是名副其实的“Token粉碎机”。
过去近一个月,全球Token调用占比暴增至17%,业内形容OpenClaw“鲸吞了全球超六分之一的算力”。它为何如此“费Token”?这源于其三大独特模式:流量全民化、交互智能体化,以及社区化生态。
首先是流量全民化。OpenClaw这类智能体的用户规模与请求量呈现潮汐式爆发特点,无固定峰值规律。传统大模型对话“即用即走”,流量相对平稳。但未来每个人都可能拥有一个24小时专属AI助理,当数以千万计的用户同时使用,原本可预测的流量模型将彻底失效。流量压力不仅来自更多人,更来自永不休息的机器,例如7x24小时不间断工作的运维Claw。这形成了无规律、全天候、高密度的流量质变。
其次是交互智能体化。单次用户操作会触发多轮思考、工具调用与逻辑校验,形成显著的请求放大效应。
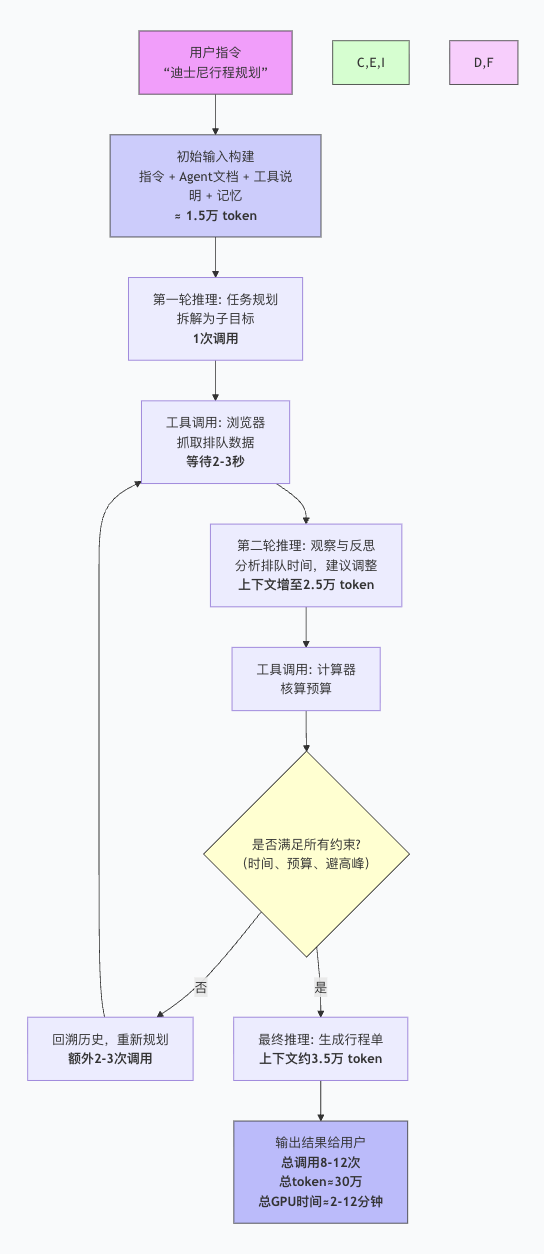
我们以一个具体任务为例。当用户向OpenClaw发出“帮我规划这周六带6岁孩子去上海迪士尼的行程,预算2000元,要避开人流高峰,晚上8点前回到市区”的指令时,OpenClaw会构建一个庞大的初始输入,其中包含用户指令、Agent角色文档、工具使用说明及过往记忆,这轻易就能消耗数万Token。
接着,OpenClaw进入 ReAct(Reasoning and Acting)循环——即“边想、边做、边反思,不对就改”。它并非一次调用就结束。首轮规划推理后,它会调用浏览器工具抓取排队数据,等待返回后触发第二轮推理分析,再调用计算器核算预算。每一轮“决策-执行-反思”都是一次完整的大模型推理,上下文也从初始的1.5万Token迅速膨胀至3.5万Token以上。
整个任务累计可能执行8~12次大模型推理,最终输出数千Token的行程单,总Token消耗约30万。相比之下,传统大模型只需一次调用、几百Token就能给出简略攻略。简言之,以前大模型是“按次调用”,现在的OpenClaw是“按流程调用”,其“动手能力”让Token消耗放大了几十到上百倍。
实际上,黄仁勋曾透露,以OpenClaw为代表的Agent,执行复杂任务的Token消耗,比传统生成式大模型激增约1000倍;持续监测类Agent甚至可达百万倍。行业人士透露,OpenClaw重度用户日均消耗Token高达3000万至1亿,按国际顶尖模型计算,单日成本可达90至1000美元。
最后是社区化生态。智能体之间可以自主发起对话、协同作业,形成无人工干预的自激式交互闭环。有用户将不同厂商的Claw接入飞书群聊,设定分工后,它们便能自主协作:一只抓取资讯,一只分析决策,一只检查质量,形成“AI团队”。
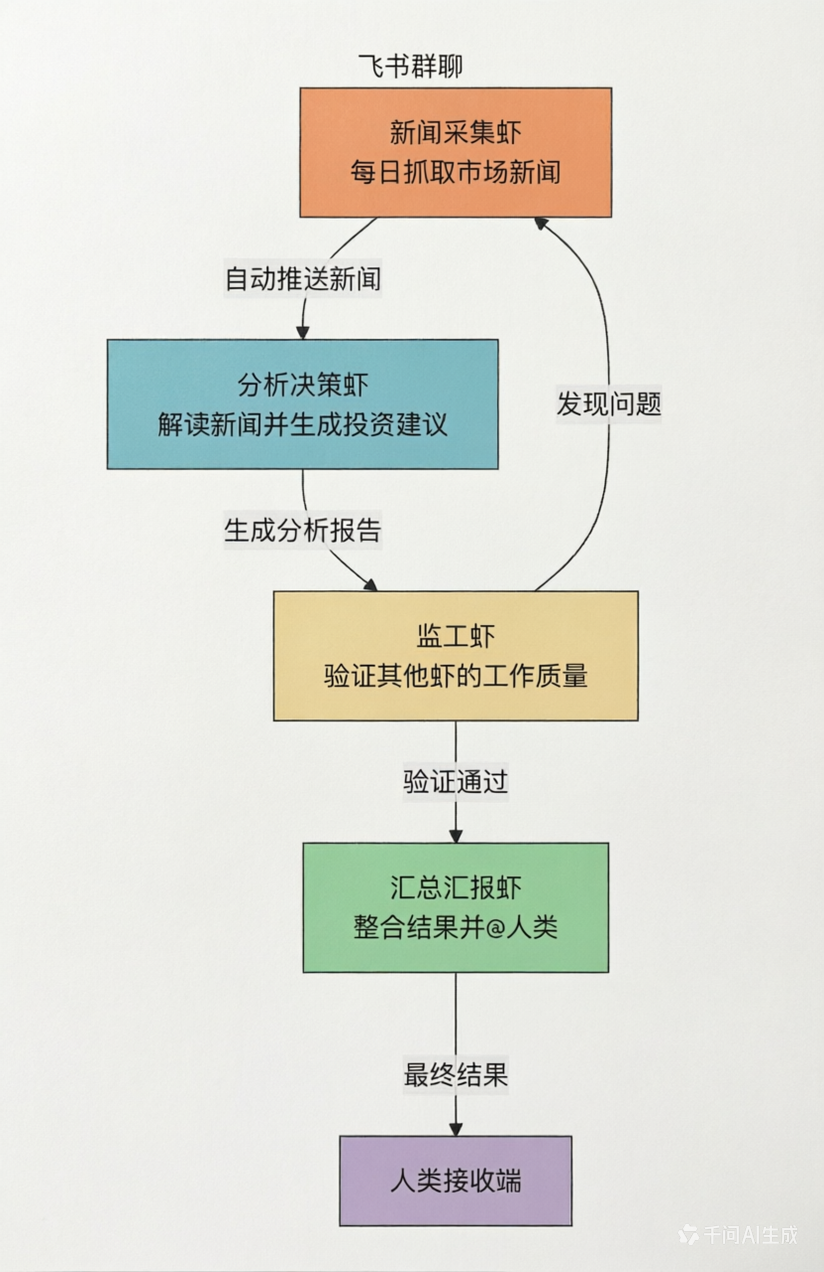
这种模式让流量从“人机对话”转向“机器自循环”,交互频次呈指数级增长,进一步加剧了算力需求的潮汐式爆发。
总体而言,OpenClaw这类Agent如果普及,三股力量将叠加共振,让单次请求裂变成难以计数的并发任务、链式调用和AI团队协作。每一个环节都在挑战着AI Infra的吞吐上限、调度效率和成本边界。一个更残酷的现实是:底层推理系统的迭代速度,可能远远跟不上Agent生态爆炸的速度。
AI Infra推理系统面临的五大挑战
OpenClaw的跨越式发展,迫使底层AI Infra推理系统必须直面五道前所未有的挑战:
挑战一:撑住洪峰,从“单次短链路”到自激爆发的极限重构
传统AI服务遵循“请求—推理—结束”的短链路逻辑。但OpenClaw的ReAct模式,要完成多轮“请求—判断—行动-反思”循环,每一轮都是一次独立的推理请求。人机交互下,单次指令可放大为几次到几十次请求;一旦进入多Agent协作模式,机器间的交互在毫秒级窗口内高频往返,会形成传统服务根本无法预见的“自激式流量洪峰”。这要求基础设施必须具备超高并发、低延迟、抗雪崩的极致吞吐能力。
挑战二:算力调度,从“谁有空谁上”到全生命周期精准匹配
OpenClaw的任务天然是串行链式的,就像接力赛,任何一环卡住,整条链就停在原地等待,期间占用的显存却不释放。此外,请求还呈现轻重混杂的特点。“谁空闲谁调度”的粗放模式彻底失效。基础设施必须进化为智能编排系统,实现针对串行链路的资源即时释放与按需激活,并从简单的负载均衡升级为全链路资源生命周期的精细管理。
挑战三:内存管理,从“用完即清”到动态交互下的记忆墙突围
KV Cache是模型的“短期工作记忆”,传统服务下较易管理。但在OpenClaw的多轮交互、工具调用与多Agent协作场景中,碎片化的中间结果不断插入,“工作记忆”指数级上升,传统缓存复用逻辑难以命中,轻则延迟飙升,重则任务链路崩溃。基础设施需要具备多角色会话隔离、动态KV裁剪与优化复用能力。
挑战四:弹性扩容,从“加机器救场”到秒级无缝接续
面对流量秒级暴涨,传统做法是“加机器、分流”。但OpenClaw的Agent上下文(如打开了哪个页面、正在等待哪个结果)全部绑定在特定服务器的内存中。一旦迁移,上下文断裂会导致任务失败,并可能引发级联雪崩。因此,基础设施必须在秒级完成扩容的同时,实现上下文完整迁移与无缝接续,这是传统架构从未考虑过的命题。
挑战五:模型适配,从“默认先跑英伟达”到国产芯适配无时差
OpenClaw需要前沿模型矩阵协同作业,而模型迭代速度极快。开源社区的新模型默认优先适配英伟达GPU,国产芯片往往需要二次开发,算子重适配、精度对齐可能耗时数周。结果就是,国产芯的模型适配总是慢一步,间接拖慢了OpenClaw生态的能力迭代速度。这是国产芯片必须攻克的生态难题。
如何应对挑战:重构AI Infra的实践与策略
面对智能体浪潮带来的根本性需求转变,行业领先者已经开始行动。百度智能云认为,AI正从Copilot向具备自主决策能力的AI Agent跃迁,这一转变使得 “未来AI应用的推理需求将超过训练” ,并对基础设施提出了“推理需求主导、长上下文、极致性价比”的新要求。
针对上述五大挑战,百度智能云基于其百度百舸平台,给出了一系列应对举措:
举措一:革新调度逻辑,应对流量洪峰
针对“自激式流量洪峰”导致的响应变慢与服务卡死,传统“先进先出”的调度模式在高并发下会造成大量请求堆积。百度百舸推出了“班车调度”机制,在极短时间窗口内将一批请求聚合,再预判并发送给即将空闲的推理实例,消除了引擎内部的无效等待。同时,利用批处理窗口,通过“贪心算法”将任务在计算单元间进行智能拼配,使工作量尽量均衡,从而大幅提升GPU利用率。
举措二:深入底层挖潜,实现吞吐跃升
为提升系统吞吐上限以应对高并发压力,需要从推理框架底层挖掘硬件性能。百度百舸联合昆仑芯,基于vLLM社区标准推出了面向昆仑芯XPU的高性能插件 vLLM-Kunlun Plugin。该方案通过为不同模型定制高性能“融合算子”,将零散计算步骤打包,重点缓解Attention与MoE等核心模块的计算瓶颈。实测数据显示,在DeepSeek、Qwen等主流模型上,该优化显著提升了昆仑芯的吞吐和时延表现。
举措三:优化缓存与并行,加速长上下文推理
面对OpenClaw等智能体超长上下文带来的挑战,百度百舸采用分布式KV Cache实现全局缓存的智能调度,并通过高速传输通道与异步调度,确保Prefill和Decode两阶段高效衔接,减少等待。针对128K超长序列下首Token延迟(TTFT)高的问题,推出了轻量级上下文并行(CP)方案,通过逻辑双倍切分与重新拼配确保多卡负载均衡。实测在32卡部署下,能将128K序列的TTFT控制在2秒内。
举措四:重构启动流程,实现秒级弹性扩容
针对智能体流量的潮汐特性与大模型冷启动慢的难题,百度百舸对扩容启动流程进行全面重构。针对权重加载慢、编译缓存重复生成、计算图初始化耗时高三大核心瓶颈,推出了自适应权重传输、编译缓存复用、分阶段计算图捕获与守护实例机制。实测将Qwen3-235B的启动时间从521秒压缩至4.91秒,让模型扩容从分钟级跨入秒级时代。
举措五:拥抱开源生态,加速国产芯片模型适配
为解决国产芯片部署大模型“慢一步”的问题,百度智能云的策略是坚定融入vLLM开源生态,让开发者无需重新学习即可平滑迁移。vLLM-Kunlun插件将适配工作收敛到底层算子,93%的算子与社区接口对齐,大幅降低开发门槛。目前已完成50余款主流大模型的推理适配,并借助自动化工具提升精度排查效率。实测小米MiMO-Flash-V2从零到上线仅需两天,Qwen3.5适配全程仅半小时。
面对OpenClaw等智能体浪潮带来的挑战,需要“前瞻布局、从底层入手、软硬协同”的策略。这背后依赖的是深耕多年的全栈AI Infra能力,从自研芯片、超大规模集群到高效的计算平台,形成完整的技术闭环。这样的能力,是支撑智能体生态高速发展的关键,也是在AI基础设施格局加速重塑的今天,最核心的胜负手。
这场硬仗还远未结束。当前全球日均Token消耗量已超过360万亿,而未来5年可能还会再增长数亿倍。表面上人们在“养龙虾”,水面之下,一场关乎Agent普及的AI基础设施硬战,正在全面开打。每一次应用层的范式跃迁,都会引爆基础设施层的军备竞赛。而在OpenClaw生态急速扩张的当下,这场AI Infra的战争,正以更快的速度、更高的烈度上演。要深入探讨更多AI前沿技术与基础设施挑战,可以关注云栈社区的相关板块,那里汇聚了大量开发者的实战经验与深度解析。
 发表于 2026-3-20 23:23:35
|
查看: 166|
回复: 0
发表于 2026-3-20 23:23:35
|
查看: 166|
回复: 0
