本文基于DPDK 17.11版本源码,对其内存管理部分的实现机制进行梳理与分析。
概述
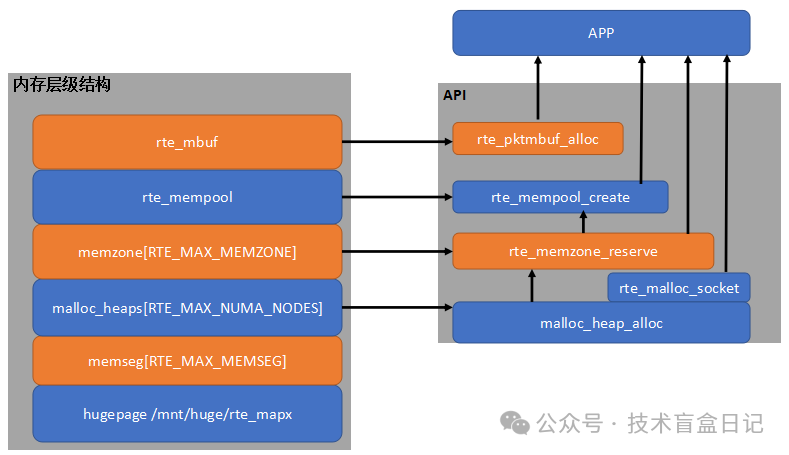
DPDK的内存管理采用分层结构。我们可以通过下图来直观理解,图中左侧展示了内存的层级架构,下方三层在rte_eal_init初始化时完成构建,而上方的三层则通过用户调用API来生成。右侧列出了每一层结构对外提供的API接口。
下图展示了内存管理相关的核心数据结构。其中,rte_config->mem_config指向共享内存文件 /var/run/.rte_config,其对应的结构体为struct rte_mem_config。该结构体中的mem_cfg_addr保存了映射文件后的虚拟地址,从进程使用此值进行映射,确保了主从进程能以相同的虚拟地址访问rte_mem_config结构体。
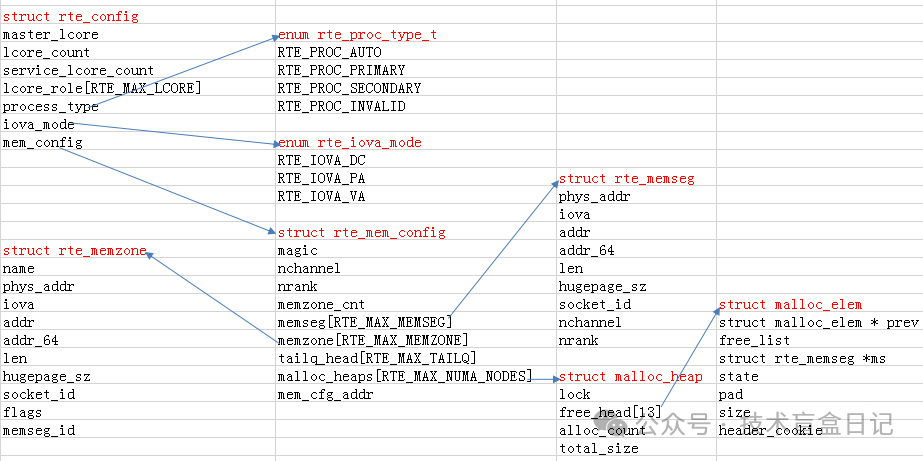
这个共享内存结构体struct rte_mem_config还保存了以下几个关键部分:
- memseg: 将同时满足以下四个条件的大页内存块归入同一个
memseg中:
- 同属一个socket(NUMA节点)
- 大页(hugepage)大小相同
- 物理地址连续
- 虚拟地址连续
- malloc_heap: 将属于同一socket的
memseg挂载到同一个malloc_heap上,这是对外提供内存分配API的最底层实现。
- memzone: 用于申请整块的大内存区域。
- tailq_head: 共享队列的实现,允许主从进程同时访问。
内存初始化的核心流程如下,后续我们将逐一深入每个关键函数的实现细节:
rte_eal_init
// internal_config为本进程全局变量,用来保存参数等信息
eal_reset_internal_config(&internal_config);
// 解析参数,保存到 internal_config
eal_parse_args(argc, argv);
// 收集系统上可用的大页内存,保存到 internal_config->hugepage_info[3]
eal_hugepage_info_init();
// 初始化全局变量rte_config,并将 rte_config->mem_config 进行映射
rte_config_init();
// 大页内存映射,并保存到 rte_config->mem_config->memseg[]
rte_eal_memory_init();
// 将 memseg 插入 rte_config->mem_config->malloc_heaps[]
rte_eal_memzone_init();
// 主进程初始化完成
rte_eal_mcfg_complete();
/* ALL shared mem_config related INIT DONE */
// 主进程完成了所有共享内存的初始化,设置RTE_MAGIC。
// 从进程在等待magic变成RTE_MAGIC后才能继续下去。
if (rte_config.process_type == RTE_PROC_PRIMARY)
rte_config.mem_config->magic = RTE_MAGIC;
eal_hugepage_info_init
此函数负责遍历 /sys/kernel/mm/hugepages 目录,收集系统当前可用的不同大小的大页信息。
/*
* when we initialize the hugepage info, everything goes
* to socket 0 by default. it will later get sorted by memory
* initialization procedure.
*/
int
eal_hugepage_info_init(void)
{
const char dirent_start_text[] = "hugepages-";
const size_t dirent_start_len = sizeof(dirent_start_text) - 1;
unsigned i, num_sizes = 0;
DIR *dir;
struct dirent *dirent;
// 打开目录 /sys/kernel/mm/hugepages
dir = opendir(sys_dir_path);
for (dirent = readdir(dir); dirent != NULL; dirent = readdir(dir)) {
struct hugepage_info *hpi;
if (strncmp(dirent->d_name, dirent_start_text,
dirent_start_len) != 0)
continue;
if (num_sizes >= MAX_HUGEPAGE_SIZES)
break;
hpi = &internal_config.hugepage_info[num_sizes];
hpi->hugepage_sz =
rte_str_to_size(&dirent->d_name[dirent_start_len]);
// 打开文件 /proc/mounts 遍历所有挂载点,找到 hugetlbfs
// 相关的挂载点,再找到和hpi->hugepage_sz相等的挂载
// 点,返回其挂载目录。
hpi->hugedir = get_hugepage_dir(hpi->hugepage_sz);
// 如果对应hugepage_sz的挂载点,则跳过此种类型大页
/* first, check if we have a mountpoint */
if (hpi->hugedir == NULL) {
uint32_t num_pages;
num_pages = get_num_hugepages(dirent->d_name);
if (num_pages > 0)
RTE_LOG(NOTICE, EAL,
"%" PRIu32 " hugepages of size "
"%" PRIu64 " reserved, but no mounted "
"hugetlbfs found for that size\n",
num_pages, hpi->hugepage_sz);
continue;
}
/* try to obtain a writelock */
hpi->lock_descriptor = open(hpi->hugedir, O_RDONLY);
/* if blocking lock failed */
flock(hpi->lock_descriptor, LOCK_EX);
// 删除挂载点目录下以"map_"开头的文件
/* clear out the hugepages dir from unused pages */
clear_hugedir(hpi->hugedir);
// 获取空闲的大页数量,free_hugepages减去
// resv_hugepages。此时还不知道大页位于哪个socket,
// 所以先将大页数量统一放到socket0上
/* for now, put all pages into socket 0,
* later they will be sorted */
hpi->num_pages[0] = get_num_hugepages(dirent->d_name);
// 大页种类加一
num_sizes++;
}
closedir(dir);
// 保存大页种类: 2M, 1G等
internal_config.num_hugepage_sizes = num_sizes;
// 按照大页大小排序 hugepage_info,从大到小
/* sort the page directory entries by size, largest to smallest */
qsort(&internal_config.hugepage_info[0], num_sizes,
sizeof(internal_config.hugepage_info[0]), compare_hpi);
// 如果有可用的大页,返回0,否则返回-1
/* now we have all info, check we have at least one valid size */
for (i = 0; i < num_sizes; i++)
if (internal_config.hugepage_info[i].hugedir != NULL &&
internal_config.hugepage_info[i].num_pages[0] > 0)
return 0;
/* no valid hugepage mounts available, return error */
return -1;
}
rte_config_init
此函数映射共享配置文件 /var/run/.rte_config,该文件用于保存 rte_config->mem_config 结构体的内容。这是实现多进程间内存管理信息同步的关键。
主进程创建并映射此文件,将映射后的虚拟地址保存到 rte_config->mem_config->mem_cfg_addr。从进程则需要分两步映射:首先以只读方式映射以获取主进程使用的虚拟地址 mem_cfg_addr,然后使用这个地址再次进行映射。这样保证了主从进程可以使用完全相同的虚拟地址来访问这块共享内存。
/* Sets up rte_config structure with the pointer to shared memory config.*/
static void
rte_config_init(void)
{
rte_config.process_type = internal_config.process_type;
switch (rte_config.process_type){
case RTE_PROC_PRIMARY:
// 主进程初始化
rte_eal_config_create();
break;
case RTE_PROC_SECONDARY:
// 从进程attach
rte_eal_config_attach();
// 等待主进程初始化完成
rte_eal_mcfg_wait_complete(rte_config.mem_config);
// 再次attach
rte_eal_config_reattach();
break;
case RTE_PROC_AUTO:
case RTE_PROC_INVALID:
rte_panic("Invalid process type\n");
}
}
主进程映射文件 /var/run/.rte_config
/* create memory configuration in shared/mmap memory. Take out
* a write lock on the memsegs, so we can auto-detect primary/secondary.
* This means we never close the file while running (auto-close on exit).
* We also don't lock the whole file, so that in future we can use read-locks
* on other parts, e.g. memzones, to detect if there are running secondary
* processes. */
static void
rte_eal_config_create(void)
{
void *rte_mem_cfg_addr;
int retval;
// 获取config所在路径 /var/run/.rte_config
const char *pathname = eal_runtime_config_path();
if (internal_config.no_shconf)
return;
/* map the config before hugepage address so that we don't waste a page */
if (internal_config.base_virtaddr != 0)
rte_mem_cfg_addr = (void *)
RTE_ALIGN_FLOOR(internal_config.base_virtaddr -
sizeof(struct rte_mem_config), sysconf(_SC_PAGE_SIZE));
else
rte_mem_cfg_addr = NULL;
// 打开config文件路径 /var/run/.rte_config
if (mem_cfg_fd < 0){
mem_cfg_fd = open(pathname, O_RDWR | O_CREAT, 0660);
if (mem_cfg_fd < 0)
rte_panic("Cannot open '%s' for rte_mem_config\n", pathname);
}
// 将文件大小修改为 mem_config 的长度
retval = ftruncate(mem_cfg_fd, sizeof(*rte_config.mem_config));
if (retval < 0){
close(mem_cfg_fd);
rte_panic("Cannot resize '%s' for rte_mem_config\n", pathname);
}
// 给文件mem_cfg_fd加上锁,可以调用eal_proc_type_detect检测是主进程还是从进程。
// 只有主进程能lock成功。
static struct flock wr_lock = {
.l_type = F_WRLCK,
.l_whence = SEEK_SET,
.l_start = offsetof(struct rte_mem_config, memseg),
.l_len = sizeof(early_mem_config.memseg),
};
fcntl(mem_cfg_fd, F_SETLK, &wr_lock);
// 映射config文件
rte_mem_cfg_addr = mmap(rte_mem_cfg_addr, sizeof(*rte_config.mem_config),
PROT_READ | PROT_WRITE, MAP_SHARED, mem_cfg_fd, 0);
// 将early_mem_config内容保存到共享内存 rte_mem_cfg_addr
memcpy(rte_mem_cfg_addr, &early_mem_config, sizeof(early_mem_config));
// 将映射后的虚拟地址保存到 rte_config.mem_config
rte_config.mem_config = rte_mem_cfg_addr;
// 最后将映射后的虚拟地址 rte_mem_cfg_addr 保存到共享内存 mem_config->mem_cfg_addr,
// 以便从进程获取后映射相同的虚拟地址。
/* store address of the config in the config itself so that secondary
* processes could later map the config into this exact location */
rte_config.mem_config->mem_cfg_addr = (uintptr_t) rte_mem_cfg_addr;
}
由于只有主进程能成功获取写锁(F_WRLCK),因此可以利用 eal_proc_type_detect 函数来检测当前进程是主进程还是从进程。
/* Detect if we are a primary or a secondary process */
enum rte_proc_type_t
eal_proc_type_detect(void)
{
enum rte_proc_type_t ptype = RTE_PROC_PRIMARY;
const char *pathname = eal_runtime_config_path();
/* if we can open the file but not get a write-lock we are a secondary
* process. NOTE: if we get a file handle back, we keep that open
* and don't close it to prevent a race condition between multiple opens */
if (((mem_cfg_fd = open(pathname, O_RDWR)) >= 0) &&
(fcntl(mem_cfg_fd, F_SETLK, &wr_lock) < 0))
ptype = RTE_PROC_SECONDARY;
RTE_LOG(INFO, EAL, "Auto-detected process type: %s\n",
ptype == RTE_PROC_PRIMARY ? "PRIMARY" : "SECONDARY");
return ptype;
}
从进程第一次映射 /var/run/.rte_config 时(可能早于主进程),主要目的是获取主进程映射的虚拟地址 mem_cfg_addr。
/* attach to an existing shared memory config */
static void
rte_eal_config_attach(void)
{
struct rte_mem_config *mem_config;
// 获取config所在路径 /var/run/.rte_config
const char *pathname = eal_runtime_config_path();
if (internal_config.no_shconf)
return;
// 打开文件 /var/run/.rte_config
if (mem_cfg_fd < 0){
mem_cfg_fd = open(pathname, O_RDWR);
if (mem_cfg_fd < 0)
rte_panic("Cannot open '%s' for rte_mem_config\n", pathname);
}
// 映射config文件,只读模式。而且第一个参数为NULL,即不知道虚拟地址
/* map it as read-only first */
mem_config = (struct rte_mem_config *) mmap(NULL, sizeof(*mem_config),
PROT_READ, MAP_SHARED, mem_cfg_fd, 0);
if (mem_config == MAP_FAILED)
rte_panic("Cannot mmap memory for rte_config! error %i (%s)\n",
errno, strerror(errno));
rte_config.mem_config = mem_config;
}
从进程需要等待主进程完成初始化。主进程初始化完成后会调用 rte_eal_mcfg_complete 将 mcfg->magic 设置为 RTE_MAGIC。
inline static void
rte_eal_mcfg_wait_complete(struct rte_mem_config* mcfg)
{
/* wait until shared mem_config finish initialising */
while(mcfg->magic != RTE_MAGIC)
rte_pause();
}
主进程初始化成功后,从进程便可以使用获取到的 mem_cfg_addr 虚拟地址进行第二次映射,以确保与主进程的地址空间完全一致。
/* reattach the shared config at exact memory location primary process has it */
static void
rte_eal_config_reattach(void)
{
struct rte_mem_config *mem_config;
void *rte_mem_cfg_addr;
if (internal_config.no_shconf)
return;
// 从共享配置文件获取主进程映射的虚拟地址 mem_cfg_addr
/* save the address primary process has mapped shared config to */
rte_mem_cfg_addr = (void *) (uintptr_t) rte_config.mem_config->mem_cfg_addr;
// 去除从进程之前的对mem_config的映射
/* unmap original config */
munmap(rte_config.mem_config, sizeof(struct rte_mem_config));
// 指定主进程映射的虚拟地址 mem_cfg_addr重新映射,获取和主进程一样的虚拟地址
/* remap the config at proper address */
mem_config = (struct rte_mem_config *) mmap(rte_mem_cfg_addr,
sizeof(*mem_config), PROT_READ | PROT_WRITE, MAP_SHARED,
mem_cfg_fd, 0);
if (mem_config == MAP_FAILED || mem_config != rte_mem_cfg_addr) {
if (mem_config != MAP_FAILED)
/* errno is stale, don't use */
rte_panic("Cannot mmap memory for rte_config at [%p], got [%p]"
" - please use '--base-virtaddr' option\n",
rte_mem_cfg_addr, mem_config);
else
rte_panic("Cannot mmap memory for rte_config! error %i (%s)\n",
errno, strerror(errno));
}
close(mem_cfg_fd);
// 将映射后的mem_config保存到从进程本地变量 rte_config.mem_config
rte_config.mem_config = mem_config;
}
至此,主从进程都能使用完全相同的虚拟地址来访问共享配置 rte_config.mem_config。
rte_eal_memory_init
这是内存初始化的核心。主进程首先进行大页映射,并将映射后的虚拟地址信息保存到文件 /var/run/.rte_hugepage_info 中。从进程随后读取此文件,并按照相同的虚拟地址进行映射。这一机制是DPDK实现多进程间零拷贝传递网络数据包的关键。
/* init memory subsystem */
int
rte_eal_memory_init(void)
{
RTE_LOG(DEBUG, EAL, "Setting up physically contiguous memory...\n");
const int retval = rte_eal_process_type() == RTE_PROC_PRIMARY ?
rte_eal_hugepage_init() :
rte_eal_hugepage_attach();
if (retval < 0)
return -1;
if (internal_config.no_shconf == 0 && rte_eal_memdevice_init() < 0)
return -1;
return 0;
}
主进程调用 rte_eal_hugepage_init 进行大页映射与分类
这个函数完成了大页的映射、物理地址查找、NUMA节点识别、排序、重新映射以及最终的 memseg 划分。其核心步骤正如函数前的注释所述:
- 在 hugetlbfs 中为N个大页分别创建文件并映射。
- 找到关联的物理地址。
- 找到关联的NUMA socket ID。
- 按物理地址对所有大页排序。
- 按正确的顺序重新映射这N个大页。
- 解除第一次的映射。
- 用连续的内存区域填充配置中的
memseg。
/*
* Prepare physical memory mapping: fill configuration structure with
* these infos, return 0 on success.
* 1. map N huge pages in separate files in hugetlbfs
* 2. find associated physical addr
* 3. find associated NUMA socket ID
* 4. sort all huge pages by physical address
* 5. remap these N huge pages in the correct order
* 6. unmap the first mapping
* 7. fill memsegs in configuration with contiguous zones
*/
int
rte_eal_hugepage_init(void)
{
struct rte_mem_config *mcfg;
struct hugepage_file *hugepage = NULL, *tmp_hp = NULL;
struct hugepage_info used_hp[MAX_HUGEPAGE_SIZES];
uint64_t memory[RTE_MAX_NUMA_NODES];
unsigned hp_offset;
int i, j, new_memseg;
int nr_hugefiles, nr_hugepages = 0;
void *addr;
// 测试物理地址是否可用,如果参数指定no_hugetlbfs不用大页或者
// 通过虚拟地址不能获取物理地址,则认为物理地址不可用,则设置phys_addrs_available为false。
test_phys_addrs_available();
memset(used_hp, 0, sizeof(used_hp));
// 获取全局共享配置 mem_config
/* get pointer to global configuration */
mcfg = rte_eal_get_configuration()->mem_config;
// 遍历 num_hugepage_sizes 中大页内存
/* calculate total number of hugepages available. at this point we haven't
* yet started sorting them so they all are on socket 0 */
for (i = 0; i < (int) internal_config.num_hugepage_sizes; i++) {
/* meanwhile, also initialize used_hp hugepage sizes in used_hp */
used_hp[i].hugepage_sz = internal_config.hugepage_info[i].hugepage_sz;
// 获取所有大页的个数
nr_hugepages += internal_config.hugepage_info[i].num_pages[0];
}
/*
* allocate a memory area for hugepage table.
* this isn't shared memory yet. due to the fact that we need some
* processing done on these pages, shared memory will be created
* at a later stage.
*/
// 分配整块内存,用于保存 nr_hugepages 个 struct hugepage_file
tmp_hp = malloc(nr_hugepages * sizeof(struct hugepage_file));
if (tmp_hp == NULL)
goto fail;
memset(tmp_hp, 0, nr_hugepages * sizeof(struct hugepage_file));
hp_offset = 0; /* where we start the current page size entries */
// internal_config.socket_mem[i] 保存的是参数 --socket-mem 1024,1024 指定的每个socket上的内存。
// 复制一份到局部变量 memory 中
/* make a copy of socket_mem, needed for balanced allocation. */
for (i = 0; i < RTE_MAX_NUMA_NODES; i++)
memory[i] = internal_config.socket_mem[i];
// 开始映射大页内存,主要工作为函数前面注释的前6条。
/* map all hugepages and sort them */
// 遍历当前系统上配置的几种大页内存
for (i = 0; i < (int)internal_config.num_hugepage_sizes; i ++){
unsigned pages_old, pages_new;
struct hugepage_info *hpi;
/*
* we don't yet mark hugepages as used at this stage, so
* we just map all hugepages available to the system
* all hugepages are still located on socket 0
*/
hpi = &internal_config.hugepage_info[i];
// 如果为0,说明此种大页没有free可用的,跳过
if (hpi->num_pages[0] == 0)
continue;
/* map all hugepages available */
// 先获取当前此种类型的大页个数
pages_old = hpi->num_pages[0];
// 映射大页,返回实际成功应该的个数。
// map_all_hugepages最后一个参数为1,表示第一次映射,将映射后的虚拟地址保存到 hugepg_tbl[i].orig_va,
// 后面再单独分析此函数
pages_new = map_all_hugepages(&tmp_hp[hp_offset], hpi, memory, 1);
if (pages_new < pages_old) {
RTE_LOG(DEBUG, EAL,
"%d not %d hugepages of size %u MB allocated\n",
pages_new, pages_old,
(unsigned)(hpi->hugepage_sz / 0x100000));
// 获取未映射成功的大页个数
int pages = pages_old - pages_new;
// 更新总大页个数
nr_hugepages -= pages;
// 保存映射成功的大页
hpi->num_pages[0] = pages_new;
// 如果映射成功的大页个数为0,直接跳过,开始下一种大页的映射
if (pages_new == 0)
continue;
}
// 物理地址可用,则调用 find_physaddrs 获取映射后的虚拟地址对应的物理地址,
// 并保存到 hugepg_tbl[i].physaddr
if (phys_addrs_available) {
/* find physical addresses for each hugepage */
if (find_physaddrs(&tmp_hp[hp_offset], hpi) < 0) {
RTE_LOG(DEBUG, EAL, "Failed to find phys addr "
"for %u MB pages\n",
(unsigned int)(hpi->hugepage_sz / 0x100000));
goto fail;
}
} else {
/* set physical addresses for each hugepage */
if (set_physaddrs(&tmp_hp[hp_offset], hpi) < 0) {
RTE_LOG(DEBUG, EAL, "Failed to set phys addr "
"for %u MB pages\n",
(unsigned int)(hpi->hugepage_sz / 0x100000));
goto fail;
}
}
// 根据映射后的huge文件(rte_map0等)获取socket,并保存到hugepg_tbl[i].socket_id
if (find_numasocket(&tmp_hp[hp_offset], hpi) < 0){
RTE_LOG(DEBUG, EAL, "Failed to find NUMA socket for %u MB pages\n",
(unsigned)(hpi->hugepage_sz / 0x100000));
goto fail;
}
// 根据物理地址从小到大排序 tmp_hp
qsort(&tmp_hp[hp_offset], hpi->num_pages[0],
sizeof(struct hugepage_file), cmp_physaddr);
// 重新映射大页内存,这次最后一个参数为0,会将映射后的虚拟地址保存到 hugepg_tbl[i].final_va,
// 这也是最终的虚拟地址。
// 重新映射的目的是为了尽量找到物理地址和虚拟地址都连续的大页内存。
/* remap all hugepages */
if (map_all_hugepages(&tmp_hp[hp_offset], hpi, NULL, 0) !=
hpi->num_pages[0]) {
RTE_LOG(ERR, EAL, "Failed to remap %u MB pages\n",
(unsigned)(hpi->hugepage_sz / 0x100000));
goto fail;
}
// 解除第一次映射的虚拟地址 hugepg_tbl[i].orig_va
/* unmap original mappings */
if (unmap_all_hugepages_orig(&tmp_hp[hp_offset], hpi) < 0)
goto fail;
// 偏移,遍历下一种大页
/* we have processed a num of hugepages of this size, so inc offset */
hp_offset += hpi->num_pages[0];
}
// 如果没有通过参数 -m 或者 --socket-mem 指定内存,则获取当前所有大页内存总和
if (internal_config.memory == 0 && internal_config.force_sockets == 0)
internal_config.memory = eal_get_hugepage_mem_size();
nr_hugefiles = nr_hugepages;
// 清空hugepage_info的大页个数
/* clean out the numbers of pages */
for (i = 0; i < (int) internal_config.num_hugepage_sizes; i++)
for (j = 0; j < RTE_MAX_NUMA_NODES; j++)
internal_config.hugepage_info[i].num_pages[j] = 0;
// 前面获取了大页所在socket,这里计算每种大页在各个socket上的大页个数
/* get hugepages for each socket */
for (i = 0; i < nr_hugefiles; i++) {
int socket = tmp_hp[i].socket_id;
/* find a hugepage info with right size and increment num_pages */
const int nb_hpsizes = RTE_MIN(MAX_HUGEPAGE_SIZES,
(int)internal_config.num_hugepage_sizes);
for (j = 0; j < nb_hpsizes; j++) {
if (tmp_hp[i].size ==
internal_config.hugepage_info[j].hugepage_sz) {
internal_config.hugepage_info[j].num_pages[socket]++;
}
}
}
// 复制参数指定的socket内存到memory
/* make a copy of socket_mem, needed for number of pages calculation */
for (i = 0; i < RTE_MAX_NUMA_NODES; i++)
memory[i] = internal_config.socket_mem[i];
// 计算最后需要的大页个数。
// 前面映射的当前系统上所有可用的大页,但是如果参数指定了内存大小,就有可能用不到所有的
// 大页。所以此函数时根据实际需要返回大页个数。
// 如果参数申请的内存大于当前可用的内存,直接返回-1
/* calculate final number of pages */
nr_hugepages = calc_num_pages_per_socket(memory,
internal_config.hugepage_info, used_hp,
internal_config.num_hugepage_sizes);
// 没有足够内存
/* error if not enough memory available */
if (nr_hugepages < 0)
goto fail;
// 创建文件 /var/run/.rte_hugepage_info,文件大小为nr_hugefiles * sizeof(struct hugepage_file),
// 用来保存实际使用的大页信息,并将此文件进行mmap映射。
/* create shared memory */
hugepage = create_shared_memory(eal_hugepage_info_path(),
nr_hugefiles * sizeof(struct hugepage_file));
memset(hugepage, 0, nr_hugefiles * sizeof(struct hugepage_file));
/*
* unmap pages that we won't need (looks at used_hp).
* also, sets final_va to NULL on pages that were unmapped.
*/
// 删除前面映射的但是不需要的大页文件。
// 比如当前系统有10个1G可用大页内存,进行映射后会生成10个1G的文件,
// 但是参数 --socket-mem 只指定了1G内存,则需要删除9个1G的文件。
if (unmap_unneeded_hugepages(tmp_hp, used_hp,
internal_config.num_hugepage_sizes) < 0) {
RTE_LOG(ERR, EAL, "Unmapping and locking hugepages failed!\n");
goto fail;
}
/*
* copy stuff from malloc'd hugepage* to the actual shared memory.
* this procedure only copies those hugepages that have final_va
* not NULL. has overflow protection.
*/
// 这里只将实际需要的大页信息保存到 hugepage
if (copy_hugepages_to_shared_mem(hugepage, nr_hugefiles,
tmp_hp, nr_hugefiles) < 0) {
RTE_LOG(ERR, EAL, "Copying tables to shared memory failed!\n");
goto fail;
}
// 如果参数指定了 unlink,则要将映射后大页文件unlink掉。unlink会将文件删除(ls 看不到文件了),
// 但是前面打开了这些文件,实际上不会真正删除(lsof 可以看到)。
/* free the hugepage backing files */
if (internal_config.hugepage_unlink &&
unlink_hugepage_files(tmp_hp, internal_config.num_hugepage_sizes) < 0) {
RTE_LOG(ERR, EAL, "Unlinking hugepage files failed!\n");
goto fail;
}
/* free the temporary hugepage table */
free(tmp_hp);
tmp_hp = NULL;
// 前面完成了大页内存的映射,这里要将他们分别保存到 memseg 中。
// 同时满足下面四个条件的hugepage 放在同一个memseg中.
// 1. 同socket
// 2. hugepage 大小相同
// 3. 物理地址连续
// 4. 虚拟地址连续
/* first memseg index shall be 0 after incrementing it below */
j = -1;
for (i = 0; i < nr_hugefiles; i++) {
new_memseg = 0;
/* if this is a new section, create a new memseg */
// 第一个大页内存,肯定是新memseg
if (i == 0)
new_memseg = 1;
// 和前一个大页的socket不一样,认为是新的memseg
else if (hugepage[i].socket_id != hugepage[i-1].socket_id)
new_memseg = 1;
// 和前一个大页的大小不一样,认为是新的memseg
else if (hugepage[i].size != hugepage[i-1].size)
new_memseg = 1;
// 和前一个大页的物理地址不连续,认为是新的memseg
else if ((hugepage[i].physaddr - hugepage[i-1].physaddr) !=
hugepage[i].size)
new_memseg = 1;
// 和前一个大页的虚拟地址不连续,认为是新的memseg
else if (((unsigned long)hugepage[i].final_va -
(unsigned long)hugepage[i-1].final_va) != hugepage[i].size)
new_memseg = 1;
// 将大页信息保存到 memseg中。
// 最坏情况下,每个大页使用有一个memseg。
if (new_memseg) {
j += 1;
if (j == RTE_MAX_MEMSEG)
break;
mcfg->memseg[j].iova = hugepage[i].physaddr;
mcfg->memseg[j].addr = hugepage[i].final_va;
mcfg->memseg[j].len = hugepage[i].size;
mcfg->memseg[j].socket_id = hugepage[i].socket_id;
mcfg->memseg[j].hugepage_sz = hugepage[i].size;
}
/* continuation of previous memseg */
else {
mcfg->memseg[j].len += mcfg->memseg[j].hugepage_sz;
}
hugepage[i].memseg_id = j;
}
if (i < nr_hugefiles) {
RTE_LOG(ERR, EAL, "Can only reserve %d pages "
"from %d requested\n"
"Current %s=%d is not enough\n"
"Please either increase it or request less amount "
"of memory.\n",
i, nr_hugefiles, RTE_STR(CONFIG_RTE_MAX_MEMSEG),
RTE_MAX_MEMSEG);
goto fail;
}
// 将大页信息保存到文件 /var/run/.rte_hugepage_info 后,就可以将其解除映射,
// 等待从进程读取此文件即可。
munmap(hugepage, nr_hugefiles * sizeof(struct hugepage_file));
return 0;
}
其中关键的 map_all_hugepages 函数负责实际的文件创建和映射工作。它根据 orig 参数决定将映射地址存入 orig_va(第一次映射)还是 final_va(第二次重新映射)。
/*
* Mmap all hugepages of hugepage table: it first open a file in
* hugetlbfs, then mmap() hugepage_sz data in it. If orig is set, the
* virtual address is stored in hugepg_tbl[i].orig_va, else it is stored
* in hugepg_tbl[i].final_va. The second mapping (when orig is 0) tries to
* map contiguous physical blocks in contiguous virtual blocks.
*/
static unsigned
map_all_hugepages(struct hugepage_file *hugepg_tbl, struct hugepage_info *hpi,
uint64_t *essential_memory __rte_unused, int orig)
{
int fd;
unsigned i;
void *virtaddr;
void *vma_addr = NULL;
size_t vma_len = 0;
// 遍历大页
for (i = 0; i < hpi->num_pages[0]; i++) {
uint64_t hugepage_sz = hpi->hugepage_sz;
// 如果是第一次映射,保存大页索引,获取大页所在路径
if (orig) {
hugepg_tbl[i].file_id = i;
hugepg_tbl[i].size = hugepage_sz;
// 大页文件所在路径 /mnt/huge/rte_mapx
eal_get_hugefile_path(hugepg_tbl[i].filepath,
sizeof(hugepg_tbl[i].filepath), hpi->hugedir,
hugepg_tbl[i].file_id);
hugepg_tbl[i].filepath[sizeof(hugepg_tbl[i].filepath) - 1] = '\0';
}
else if (vma_len == 0) {
unsigned j, num_pages;
/* reserve a virtual area for next contiguous
* physical block: count the number of
* contiguous physical pages. */
// 找到和当前大页物理地址连续的大页
for (j = i+1; j < hpi->num_pages[0] ; j++) {
// 前一个大页的物理地址加上大页大小不等于当前页的物理地址,
// 说明这两个大页物理地址不连续。
if (hugepg_tbl[j].physaddr !=
hugepg_tbl[j-1].physaddr + hugepage_sz)
break;
}
num_pages = j - i;
vma_len = num_pages * hugepage_sz;
/* get the biggest virtual memory area up to
* vma_len. If it fails, vma_addr is NULL, so
* let the kernel provide the address. */
// 如果物理地址连续,则判断虚拟地址是否也可以连续
vma_addr = get_virtual_area(&vma_len, hpi->hugepage_sz);
if (vma_addr == NULL)
vma_len = hugepage_sz;
}
// 打开大页文件
/* try to create hugepage file */
fd = open(hugepg_tbl[i].filepath, O_CREAT | O_RDWR, 0600);
if (fd < 0) {
RTE_LOG(DEBUG, EAL, "%s(): open failed: %s\n", __func__,
strerror(errno));
goto out;
}
// 第一次映射,vma_addr为NULL,让kernel返回合适的虚拟地址
/* map the segment, and populate page tables,
* the kernel fills this segment with zeros */
virtaddr = mmap(vma_addr, hugepage_sz, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_POPULATE, fd, 0);
if (virtaddr == MAP_FAILED) {
RTE_LOG(DEBUG, EAL, "%s(): mmap failed: %s\n", __func__,
strerror(errno));
close(fd);
goto out;
}
// 第一次映射,将返回的虚拟地址保存到 orig_va
if (orig) {
hugepg_tbl[i].orig_va = virtaddr;
}
else {// 第二次映射,将返回的虚拟地址保存到 final_va
hugepg_tbl[i].final_va = virtaddr;
}
/* set shared flock on the file. */
if (flock(fd, LOCK_SH | LOCK_NB) == -1) {
RTE_LOG(DEBUG, EAL, "%s(): Locking file failed:%s \n",
__func__, strerror(errno));
close(fd);
goto out;
}
close(fd);
// 下一个大页映射的虚拟地址为当前虚拟地址加大页大小,保证
// 所有大页的虚拟地址连续
vma_addr = (char *)vma_addr + hugepage_sz;
vma_len -= hugepage_sz;
}
out:
return i;
}
从进程调用 rte_eal_hugepage_attach 映射与主进程相同的虚拟地址
从进程读取主进程生成的信息文件,并尝试按照完全相同的虚拟地址映射大页内存,这是实现零拷贝的基础。
/*
* This creates the memory mappings in the secondary process to match that of
* the server process. It goes through each memory segment in the DPDK runtime
* configuration and finds the hugepages which form that segment, mapping them
* in order to form a contiguous block in the virtual memory space
*/
int
rte_eal_hugepage_attach(void)
{
// 获取全局共享内存配置
const struct rte_mem_config *mcfg = rte_eal_get_configuration()->mem_config;
struct hugepage_file *hp = NULL;
unsigned num_hp = 0;
unsigned i, s = 0; /* s used to track the segment number */
unsigned max_seg = RTE_MAX_MEMSEG;
off_t size = 0;
int fd, fd_zero = -1, fd_hugepage = -1;
if (aslr_enabled() > 0) {
RTE_LOG(WARNING, EAL, "WARNING: Address Space Layout Randomization "
"(ASLR) is enabled in the kernel.\n");
RTE_LOG(WARNING, EAL, " This may cause issues with mapping memory "
"into secondary processes\n");
}
test_phys_addrs_available();
// 打开 /dev/zero,用来测试虚拟地址是否可用
fd_zero = open("/dev/zero", O_RDONLY);
if (fd_zero < 0) {
RTE_LOG(ERR, EAL, "Could not open /dev/zero\n");
goto error;
}
// 打开文件 /var/run/.rte_hugepage_info
fd_hugepage = open(eal_hugepage_info_path(), O_RDONLY);
if (fd_hugepage < 0) {
RTE_LOG(ERR, EAL, "Could not open %s\n", eal_hugepage_info_path());
goto error;
}
// 主进程已经将需要的大页进行映射,并保存到了 mem_config->memseg[]中,
// 遍历memseg,将主进程保存到memseg的虚拟地址在从进程映射,查看是否能
// 映射成功,如果不能成功,则报错返回,说明不能和主进程使用相同的地址。
/* map all segments into memory to make sure we get the addrs */
for (s = 0; s < RTE_MAX_MEMSEG; ++s) {
void *base_addr;
/*
* the first memory segment with len==0 is the one that
* follows the last valid segment.
*/
if (mcfg->memseg[s].len == 0)
break;
/*
* fdzero is mmapped to get a contiguous block of virtual
* addresses of the appropriate memseg size.
* use mmap to get identical addresses as the primary process.
*/
base_addr = mmap(mcfg->memseg[s].addr, mcfg->memseg[s].len,
PROT_READ,
MAP_PRIVATE,
fd_zero, 0);
if (base_addr == MAP_FAILED ||
base_addr != mcfg->memseg[s].addr) {
max_seg = s;
if (base_addr != MAP_FAILED) {
/* errno is stale, don't use */
RTE_LOG(ERR, EAL, "Could not mmap %llu bytes "
"in /dev/zero at [%p], got [%p] - "
"please use '--base-virtaddr' option\n",
(unsigned long long)mcfg->memseg[s].len,
mcfg->memseg[s].addr, base_addr);
munmap(base_addr, mcfg->memseg[s].len);
} else {
RTE_LOG(ERR, EAL, "Could not mmap %llu bytes "
"in /dev/zero at [%p]: '%s'\n",
(unsigned long long)mcfg->memseg[s].len,
mcfg->memseg[s].addr, strerror(errno));
}
if (aslr_enabled() > 0) {
RTE_LOG(ERR, EAL, "It is recommended to "
"disable ASLR in the kernel "
"and retry running both primary "
"and secondary processes\n");
}
goto error;
}
}
// 获取文件 /var/run/.rte_hugepage_info 的实际大小
size = getFileSize(fd_hugepage);
// 映射此文件
hp = mmap(NULL, size, PROT_READ, MAP_PRIVATE, fd_hugepage, 0);
if (hp == MAP_FAILED) {
RTE_LOG(ERR, EAL, "Could not mmap %s\n", eal_hugepage_info_path());
goto error;
}
// 计算保存的大页个数
num_hp = size / sizeof(struct hugepage_file);
RTE_LOG(DEBUG, EAL, "Analysing %u files\n", num_hp);
// 再次遍历 memseg
s = 0;
while (s < RTE_MAX_MEMSEG && mcfg->memseg[s].len > 0){
void *addr, *base_addr;
uintptr_t offset = 0;
size_t mapping_size;
/*
* free previously mapped memory so we can map the
* hugepages into the space
*/
// 解除到 /dev/zero 的映射
base_addr = mcfg->memseg[s].addr;
munmap(base_addr, mcfg->memseg[s].len);
// 找到memseg中的大页进行映射
/* find the hugepages for this segment and map them
* we don't need to worry about order, as the server sorted the
* entries before it did the second mmap of them */
for (i = 0; i < num_hp && offset < mcfg->memseg[s].len; i++) {
if (hp[i].memseg_id == (int)s){
fd = open(hp[i].filepath, O_RDWR);
if (fd < 0) {
RTE_LOG(ERR, EAL, "Could not open %s\n",
hp[i].filepath);
goto error;
}
mapping_size = hp[i].size;
addr = mmap(RTE_PTR_ADD(base_addr, offset),
mapping_size, PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
close(fd); /* close file both on success and on failure */
if (addr == MAP_FAILED ||
addr != RTE_PTR_ADD(base_addr, offset)) {
RTE_LOG(ERR, EAL, "Could not mmap %s\n",
hp[i].filepath);
goto error;
}
offset+=mapping_size;
}
}
RTE_LOG(DEBUG, EAL, "Mapped segment %u of size 0x%llx\n", s,
(unsigned long long)mcfg->memseg[s].len);
s++;
}
/* unmap the hugepage config file, since we are done using it */
munmap(hp, size);
close(fd_zero);
close(fd_hugepage);
return 0;
}
rte_eal_memzone_init
虽然函数名为 memzone 初始化,但其更主要的工作是初始化 malloc_heap。
/*
* Init the memzone subsystem
*/
int
rte_eal_memzone_init(void)
{
struct rte_mem_config *mcfg;
const struct rte_memseg *memseg;
/* get pointer to global configuration */
mcfg = rte_eal_get_configuration()->mem_config;
// 从进程不用执行
/* secondary processes don't need to initialise anything */
if (rte_eal_process_type() == RTE_PROC_SECONDARY)
return 0;
memseg = rte_eal_get_physmem_layout();
if (memseg == NULL) {
RTE_LOG(ERR, EAL, "%s(): Cannot get physical layout\n", __func__);
return -1;
}
rte_rwlock_write_lock(&mcfg->mlock);
// 清空 memzone 个数
/* delete all zones */
mcfg->memzone_cnt = 0;
memset(mcfg->memzone, 0, sizeof(mcfg->memzone));
rte_rwlock_write_unlock(&mcfg->mlock);
// 初始化 heap
return rte_eal_malloc_heap_init();
}
int
rte_eal_malloc_heap_init(void)
{
struct rte_mem_config *mcfg = rte_eal_get_configuration()->mem_config;
unsigned ms_cnt;
struct rte_memseg *ms;
if (mcfg == NULL)
return -1;
// 遍历 memseg,按照memseg中的socket插入malloc_heaps中
for (ms = &mcfg->memseg[0], ms_cnt = 0;
(ms_cnt < RTE_MAX_MEMSEG) && (ms->len > 0);
ms_cnt++, ms++) {
malloc_heap_add_memseg(&mcfg->malloc_heaps[ms->socket_id], ms);
}
return 0;
}
将memseg放入 malloc_heap
此函数在 memseg 的首尾各放置一个 malloc_elem 结构体,将首部的 malloc_elem 标记为 FREE 并插入对应大小的空闲链表,将尾部的标记为 BUSY 以防止被分配,从而初始化一个可供分配的连续内存块。
/*
* Expand the heap with a memseg.
* This reserves the zone and sets a dummy malloc_elem header at the end
* to prevent overflow. The rest of the zone is added to free list as a single
* large free block
*/
static void
malloc_heap_add_memseg(struct malloc_heap *heap, struct rte_memseg *ms)
{
/* allocate the memory block headers, one at end, one at start */
// memseg的首地址作为第一个 malloc_elem
struct malloc_elem *start_elem = (struct malloc_elem *)ms->addr;
// memseg的尾地址减去malloc_elem大小作为最后一个 malloc_elem
struct malloc_elem *end_elem = RTE_PTR_ADD(ms->addr, ms->len - MALLOC_ELEM_OVERHEAD);
end_elem = RTE_PTR_ALIGN_FLOOR(end_elem, RTE_CACHE_LINE_SIZE);
// 首尾malloc_elem相减得出第一个elem的大小
const size_t elem_size = (uintptr_t)end_elem - (uintptr_t)start_elem;
// 初始化第一个 elem,状态为free,表示可以被分配
malloc_elem_init(start_elem, heap, ms, elem_size);
elem->heap = heap;
elem->ms = ms;
elem->prev = NULL;
memset(&elem->free_list, 0, sizeof(elem->free_list));
elem->state = ELEM_FREE;
elem->size = size;
elem->pad = 0;
set_header(elem);
set_trailer(elem);
// 初始化最后一个 elem,并指向前一个elem,状态为busy,表示永远不会被分配走
malloc_elem_mkend(end_elem, start_elem);
malloc_elem_init(elem, prev->heap, prev->ms, 0);
elem->prev = prev;
elem->state = ELEM_BUSY; /* mark busy so its never merged */
// 根据第一个elem的大小插入对应的free_head
malloc_elem_free_list_insert(start_elem);
size_t idx;
// 根据size计算idx
idx = malloc_elem_free_list_index(elem->size - MALLOC_ELEM_HEADER_LEN);
elem->state = ELEM_FREE;
LIST_INSERT_HEAD(&elem->heap->free_head[idx], elem, free_list);
// 保存此heap可分配的总内存大小
heap->total_size += elem_size;
}
内存分配
经过以上初始化,DPDK建立了从底层大页到上层内存池的完整管理体系。现在来看看上层的几种主要内存分配方式。
malloc_heap_alloc
对外提供内存分配API的最底层实现是 malloc_heap,它提供了 malloc_heap_alloc 函数用来从 heap 中分配内存。
/*
* Main function to allocate a block of memory from the heap.
* It locks the free list, scans it, and adds a new memseg if the
* scan fails. Once the new memseg is added, it re-scans and should return
* the new element after releasing the lock.
*/
void *
malloc_heap_alloc(struct malloc_heap *heap,
const char *type __attribute__((unused)), size_t size, unsigned flags,
size_t align, size_t bound)
{
struct malloc_elem *elem;
size = RTE_CACHE_LINE_ROUNDUP(size);
align = RTE_CACHE_LINE_ROUNDUP(align);
// 分配内存都要先加锁
rte_spinlock_lock(&heap->lock);
// 先根据请求的内存大小判断是否有这么多可用内存
elem = find_suitable_element(heap, size, flags, align, bound);
if (elem != NULL) {
// 有可用内存,则将memseg进行分割
elem = malloc_elem_alloc(elem, size, align, bound);
/* increase heap's count of allocated elements */
heap->alloc_count++;
}
rte_spinlock_unlock(&heap->lock);
return elem == NULL ? NULL : (void *)(&elem[1]);
}
rte_memzone_reserve
rte_memzone_reserve 用来从 heap 中分配一块指定大小和 socket 的连续内存区域。
/*
* Return a pointer to a correctly filled memzone descriptor. If the
* allocation cannot be done, return NULL.
*/
const struct rte_memzone *
rte_memzone_reserve(const char *name, size_t len, int socket_id,
unsigned flags)
{
return rte_memzone_reserve_thread_safe(name, len, socket_id,
flags, RTE_CACHE_LINE_SIZE, 0);
}
rte_mempool_create 与 rte_pktmbuf_pool_create
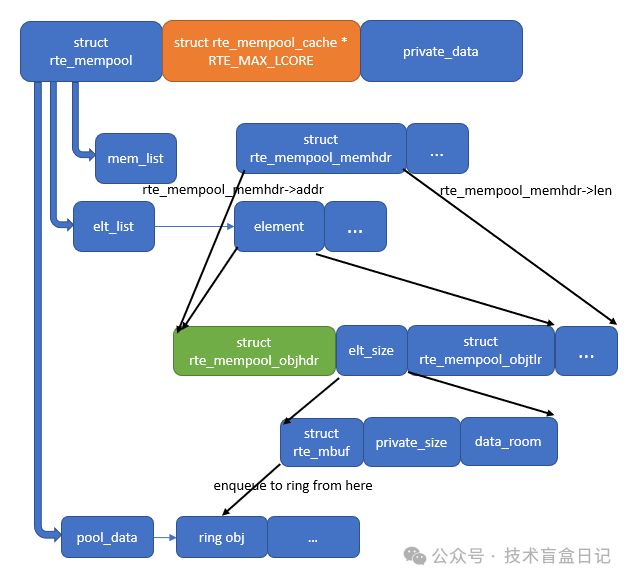
rte_mempool_create 用来创建存储固定大小对象的内存池。它会申请一个或多个 memzone,其中一个用于存放 struct rte_mempool 结构本身,其余的一个或多个 memzone 则存放固定大小的对象。后面介绍的 mbuf 就作为这种固定大小的对象存储在 mempool 中。
rte_pktmbuf_pool_create 专门用于创建存放网络报文(mbuf)的内存池。mbuf 内存是在应用启动前通过此函数预先申请好的,后续的申请和释放只是对池中对象指针的操作。
参数解释:
name: mempool的名字n: mempool中存放的obj(即mbuf)的个数cache_size: 每个CPU核心本地缓存obj的最大个数,用于提升性能priv_size: mbuf 结构体后面预留的内存,可用于存放应用的私有数据data_room_size: mbuf 中用于存放实际报文数据的空间大小
/* helper to create a mbuf pool */
struct rte_mempool *
rte_pktmbuf_pool_create(const char *name, unsigned n,
unsigned cache_size, uint16_t priv_size, uint16_t data_room_size,
int socket_id)
{
struct rte_mempool *mp;
struct rte_pktmbuf_pool_private mbp_priv;
const char *mp_ops_name;
unsigned elt_size;
int ret;
if (RTE_ALIGN(priv_size, RTE_MBUF_PRIV_ALIGN) != priv_size) {
RTE_LOG(ERR, MBUF, "mbuf priv_size=%u is not aligned\n",
priv_size);
rte_errno = EINVAL;
return NULL;
}
// mempool中一个对象(mbuf)的大小
elt_size = sizeof(struct rte_mbuf) + (unsigned)priv_size +
(unsigned)data_room_size;
mbp_priv.mbuf_data_room_size = data_room_size;
mbp_priv.mbuf_priv_size = priv_size;
// 创建mempool结构,并插入共享链表rte_mempool_tailq
mp = rte_mempool_create_empty(name, n, elt_size, cache_size,
sizeof(struct rte_pktmbuf_pool_private), socket_id, 0);
if (mp == NULL)
return NULL;
mp_ops_name = rte_eal_mbuf_default_mempool_ops();
ret = rte_mempool_set_ops_byname(mp, mp_ops_name, NULL);
if (ret != 0) {
RTE_LOG(ERR, MBUF, "error setting mempool handler\n");
rte_mempool_free(mp);
rte_errno = -ret;
return NULL;
}
rte_pktmbuf_pool_init(mp, &mbp_priv);
// 申请n个obj所占内存,如果一个memzone不满足,会申请多个memzone。将申请的memzone信息保存到rte_mempool_memhdr中,并插入mp->mem_list。同时将每个memzone按obj大小分成n份(每份就相当于是一个mbuf),将每份的地址又保存到rte_mempool_objhdr,并插入mp->elt_list,然后将每份的地址入队到mp->pool_data(rte_ring)。
ret = rte_mempool_populate_default(mp);
if (ret < 0) {
rte_mempool_free(mp);
rte_errno = -ret;
return NULL;
}
// 调用rte_pktmbuf_init初始化所有mbuf
rte_mempool_obj_iter(mp, rte_pktmbuf_init, NULL);
return mp;
}
初始化后,一个典型的多内存段 mempool 结构如下图所示:
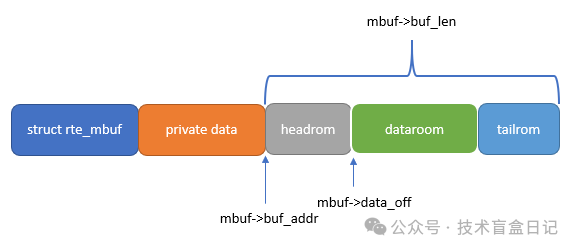
其中 rte_mbuf 的内存布局如下,清晰地展示了元数据、私有数据、报文数据区(含头空间)的关系:
rte_pktmbuf_alloc
最后,当应用需要处理网络报文时,便可以从已创建好的 mempool 中快速分配一个 mbuf。
static inline struct rte_mbuf *rte_pktmbuf_alloc(struct rte_mempool *mp)
{
struct rte_mbuf *m;
if ((m = rte_mbuf_raw_alloc(mp)) != NULL)
rte_pktmbuf_reset(m);
return m;
}
通过以上层层递进的初始化与分配机制,DPDK构建了一套高效、可控、支持多进程零拷贝的内存管理体系,为高性能网络数据包处理奠定了坚实基础。如果你对底层的内存分配策略或网络数据包处理有更深入的兴趣,欢迎在云栈社区与我们交流探讨。
 发表于 2026-1-26 20:08:33
|
查看: 183|
回复: 0
发表于 2026-1-26 20:08:33
|
查看: 183|
回复: 0
