Kafka 是一款具备高吞吐量、低延迟(亚秒级响应)、可扩展性强和高可靠性(副本机制保障数据零丢失)的消息中间件,也是目前市面上主流的消息中间件之一。自 Kafka 2.8 版本后,Kafka 选择放弃对 ZooKeeper 的依赖,这无疑是其发展历程中的一个重要里程碑。那么,Kafka 究竟为何要“抛弃”这位曾经的得力助手呢?
一、Kafka 的核心架构演进
首先,Kafka 本质上是一种消息队列,其核心设计目标就是为了解决大规模数据处理的问题。我们可以从一个最简单的模型开始理解:

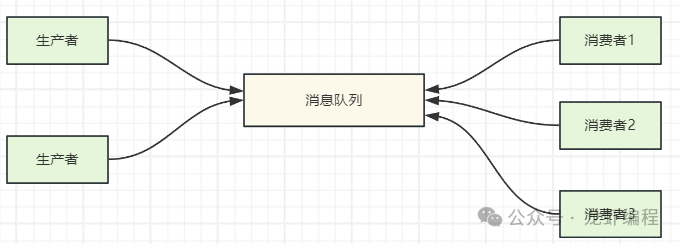
随着业务的发展和复杂度的增加,为了更好支撑业务,Kafka 很自然地引入了多生产者和多消费者的模式,其架构演变为:
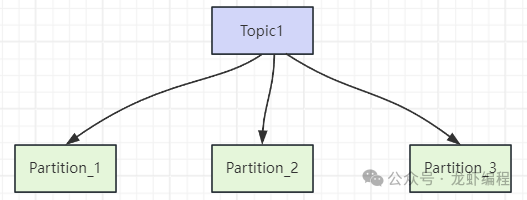
为了提升吞吐量,Kafka 设计了 Topic(主题)来分类不同类型的消息(例如订单消息、日志消息、用户注册消息等)。更重要的是,为了提升消息处理效率,每个 Topic 又被进一步划分成多个 Partition(分区),让不同的消费者可以并行处理不同分区上的消息。
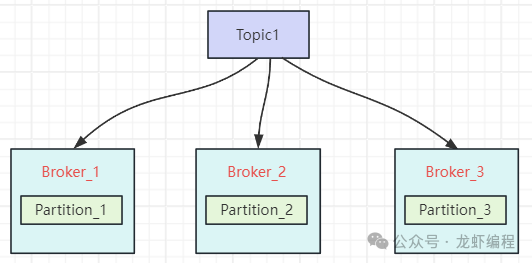
为了实现分布式部署与水平扩展,这些 Partition 会被分散部署到多台服务器上,每台服务器就被称为一个 Broker。
为了确保数据的高可靠性,Kafka 设计了主从复制(Replication)机制。即每个 Partition 都有一个 Leader 节点和多个 Follower 节点。
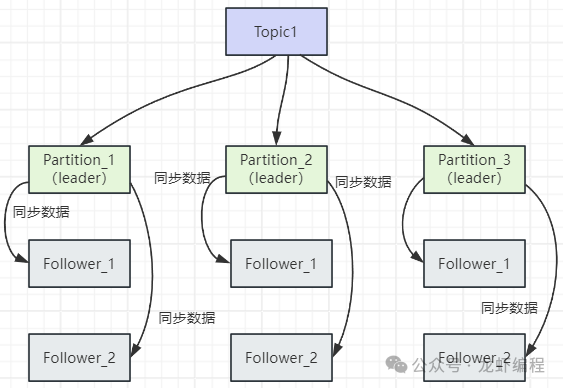
其中,Leader 节点负责处理该 Partition 的所有读写请求,Follower 节点则异步或同步地从 Leader 拉取数据进行备份。这样设计的目的很明确:即使 Leader 节点宕机,Follower 节点也能迅速选举出一个新的 Leader 接替工作,从而确保整个集群服务的高可用性。
二、ZooKeeper 在 Kafka 中扮演的角色
在早期的 Kafka 架构中,ZooKeeper 扮演着至关重要的“集群管家”角色。它主要承担了以下核心工作:
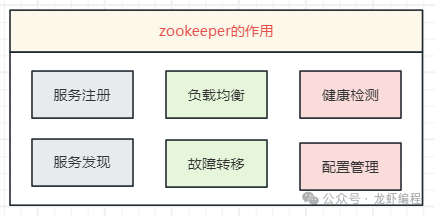
具体到 Kafka 集群中,ZooKeeper 主要负责:
- 元数据管理:存储和维护整个集群的元数据信息,例如所有 Broker 节点信息、Topic 和 Partition 的分布、每个 Partition 的 Leader 和 Follower 列表等。
- 控制器选举:Kafka 集群中需要选举出一个 Broker 作为“控制器”(Controller),负责管理分区和副本的状态。这个选举过程就依赖于 ZooKeeper。
- 消费者组管理:存储消费者组的偏移量(Offset)以及消费者与分区的分配关系。
可以说,没有 ZooKeeper,早期的 Kafka 集群就无法正常启动和运行。虽然 Kafka 发行版通常会自带一个 ZooKeeper,但从生产环境的稳定性和可用性角度考虑,业界通常推荐独立部署一个 ZooKeeper 集群来服务于 Kafka。
三、Kafka 为何决定“抛弃” ZooKeeper?
尽管 ZooKeeper 功能强大,但随着 Kafka 应用规模的爆炸式增长,这套架构的局限性也逐渐凸显出来。
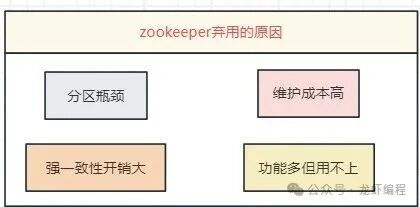
- 性能瓶颈:ZooKeeper 采用强一致性(ZAB协议)设计,这意味着集群内所有节点的数据更新必须同步进行。在大数据量、高并发的场景下,这种同步机制会带来显著的性能开销,成为整个系统的瓶颈。尤其是在 Kafka 分区数量暴涨到数十万甚至百万级别时,ZooKeeper 需要维护的元数据(Watcher监听)会急剧增加,导致监听延迟变大,反过来拖慢 Kafka 自身的性能。
- 运维复杂度高:Kafka 本身已经是一个复杂的分布式系统,再加上一个需要独立部署、监控和运维的 ZooKeeper 集群,无疑大大增加了系统的运维成本和故障排查的难度。两个分布式系统之间任何网络或配置问题都可能导致集群不稳定。
- 功能冗余:对于 Kafka 而言,它实际上只使用了 ZooKeeper 核心功能的一小部分——主要是分布式协调和元数据存储。ZooKeeper 提供的许多其他特性(如顺序节点、临时节点的高级用法等)在 Kafka 中并未被充分利用,这从某种程度上说是一种资源浪费和架构上的“过度设计”。
- 扩展性受限:如上所述,ZooKeeper 的强一致性模型在面对海量分区时存在扩展上限,这限制了 Kafka 集群规模的进一步扩大。
四、新一代架构:KRaft 模式的优势
为了解决上述问题,从 Kafka 2.8 版本开始,社区引入了基于 Raft 共识算法的 KRaft 模式。在这一新架构下,Kafka 彻底移除了对 ZooKeeper 的依赖,将元数据管理、控制器选举等核心功能内化到 Kafka 自身集群中。
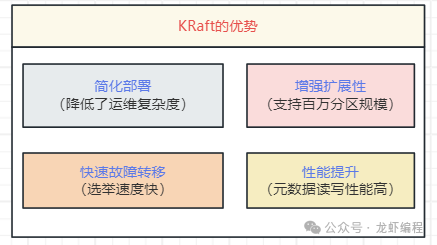
KRaft 模式为 Kafka 带来了显而易见的提升:
- 简化部署与运维:无需再单独部署和维护 ZooKeeper 集群,整个系统的架构大幅简化,降低了运维的复杂度和成本。
- 性能显著提升:元数据的读写不再需要经过外部组件(ZooKeeper),而是在 Kafka Broker 内部直接处理,这极大地提升了元数据操作的性能,特别是控制器故障转移和分区选举的速度。
- 更强的可扩展性:新的架构设计能够更好地支持超大规模的分区(例如数百万级别),为 Kafka 未来的发展扫清了障碍。
- 更快的故障恢复:基于 Raft 协议的控制器选举机制比依赖 ZooKeeper 的选举更快,从而缩短了集群的不可用时间。
总结
综上所述,Kafka 从依赖 ZooKeeper 转向内置的 KRaft 模式,是一次深刻的架构演进。这并非简单地“抛弃”一个组件,而是为了突破性能瓶颈、降低系统复杂度、拥抱更大规模场景所做的必然选择。对于开发者和架构师而言,理解这一变化背后的驱动因素,有助于我们更好地设计和使用 消息队列 等分布式系统组件。如果你想深入了解更多的分布式系统设计原理与实践,欢迎在 云栈社区 与更多开发者交流探讨。 |  发表于 2026-1-27 00:47:55
|
查看: 225|
回复: 0
发表于 2026-1-27 00:47:55
|
查看: 225|
回复: 0
