今天想和大家深入聊聊一个让很多开发者感到困惑的领域:日志系统。在工作中,你是否也曾在面对 Logback、Log4j2、SLF4J、ELK、EFK、Loki 这一长串名词时感到迷茫?尤其在需要排查线上问题时,这种困惑可能会被放大——是该登录服务器用 tail -f 看本地文件,还是去 Kibana 里搜索?或者,你是否也曾被控制台一片“SLF4J: No binding found”的警告弄得不知所措?
这背后,通常是因为对 应用级日志记录 和 系统级日志管理 这两大体系的理解出现了混淆。本文旨在帮你理清这些技术的关系、差异与选型思路。
从一个线上事故说起:混乱的日志之痛
一个真实的案例:某电商公司的核心交易系统在“双11”大促期间出现间歇性超时。开发团队第一时间想查日志定位问题,却陷入了困境。他们的系统混合了多种日志方式:部分老服务使用 System.out.println,一些服务使用 Log4j 1.x,而新服务则使用 Logback。
更麻烦的是,这些日志分散在几十台服务器上,没有统一的收集和检索系统。为了拼凑出完整的调用链,运维不得不逐台登录服务器,使用 grep 命令筛选日志。等他们终于定位到问题时,流量高峰早已过去,直接经济损失超过百万。
这个案例集中暴露了日志管理的三个核心痛点:
- 应用内如何规范、高效地记录日志?
- 如何统一不同技术栈的日志API?
- 如何集中管理和分析分布式的日志?
这正是我们今天要系统解答的问题。
应用级日志框架:SLF4J的门面模式智慧
首先,我们来解决应用内部的问题。在Java生态中,日志框架的发展经历了从各自为政到逐渐统一的过程。
SLF4J(Simple Logging Facade for Java)是这个统一过程的关键产物。它本身并不是一个具体的日志实现,而是一个 门面(Facade) ,定义了一套统一的日志API。
// 这是使用SLF4J API的典型方式
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class OrderService {
// 关键点1:通过SLF4J的工厂获取Logger
private static final Logger logger = LoggerFactory.getLogger(OrderService.class);
public void createOrder(OrderRequest request) {
// 关键点2:使用参数化日志,避免字符串拼接的性能开销
logger.info("开始创建订单,用户ID: {}, 商品ID: {}",
request.getUserId(), request.getProductId());
try {
// 业务逻辑处理
Order order = processOrder(request);
// 关键点3:使用占位符,而不是字符串连接
logger.debug("订单处理详情: {}", order);
} catch (BusinessException e) {
// 关键点4:错误日志记录异常堆栈
logger.error("创建订单失败,请求参数: {}", request, e);
throw e;
}
}
}
SLF4J的门面模式设计精妙之处:
- 解耦:业务代码只依赖SLF4J的API,不关心底层具体是Logback还是Log4j2。
- 性能优化:参数化日志
logger.debug("Value: {}", arg) 在日志级别关闭时,避免了不必要的字符串拼接开销。
- 兼容性:通过桥接器(Bridge)可以兼容老项目的Log4j、JUL(java.util.logging)等API。
这种设计的背后是 面向接口编程 思想的典型应用。就像JDBC定义了数据库操作的接口,让各家数据库提供具体实现一样,SLF4J定义了日志操作的接口,而让Logback、Log4j2等去具体实现。
Logback vs Log4j2:实现者的较量
有了统一的门面,我们再来看看两大主流的具体实现:Logback和Log4j2。
Logback:Spring Boot的默认选择
Logback由Log4j创始人开发,是SLF4J的 原生实现。它被Spring Boot选为默认日志框架,有其必然性。
Logback的优势:
- 零依赖:与SLF4J天然集成,无需额外的适配层。
- 配置灵活:支持XML和Groovy配置,具备强大的条件化配置能力。
- 自动重载:配置文件修改后可以自动重新加载,无需重启应用。
<!-- logback-spring.xml 配置文件示例 -->
<configuration scan="true" scanPeriod="30 seconds">
<!-- 根据不同环境使用不同配置 -->
<springProfile name="dev">
<root level="DEBUG">
<appender-ref ref="CONSOLE" />
</root>
</springProfile>
<springProfile name="prod">
<root level="INFO">
<appender-ref ref="ROLLING_FILE" />
<appender-ref ref="ERROR_FILE" />
</root>
</springProfile>
<!-- 控制台输出 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- 彩色日志输出,便于开发调试 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss} %highlight(%-5level) [%thread] %cyan(%logger{36}) - %msg%n</pattern>
</encoder>
</appender>
<!-- 滚动文件输出 -->
<appender name="ROLLING_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/app/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 按天归档,压缩旧日志 -->
<fileNamePattern>/var/log/app/app.%d{yyyy-MM-dd}.%i.log.gz</fileNamePattern>
<maxHistory>30</maxHistory>
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
</configuration>
Log4j2:性能的极致追求者
Log4j2是Apache对经典Log4j的完全重写,旨在解决Log4j 1.x和Logback存在的一些架构缺陷。
Log4j2的核心优势:
- 异步日志性能:基于LMAX Disruptor环形队列,其异步日志性能比Logback高出10倍以上,在高并发场景下优势明显。
- 无垃圾回收压力:在垃圾收集(GC)敏感的系统(如低延迟交易系统)中表现优异。
- 插件化架构:扩展性更好,允许开发者自定义组件。
<!-- log4j2.xml 配置文件示例 -->
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN" monitorInterval="30">
<Appenders>
<!-- 异步文件Appender -->
<RandomAccessFile name="ASYNC_FILE" fileName="logs/app.log" immediateFlush="false">
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</RandomAccessFile>
<!-- 异步日志器,核心性能优势 -->
<Async name="ASYNC" bufferSize="1024">
<AppenderRef ref="ASYNC_FILE"/>
</Async>
</Appenders>
<Loggers>
<!-- 自定义Logger配置 -->
<Logger name="com.example.service" level="DEBUG" additivity="false">
<AppenderRef ref="ASYNC"/>
</Logger>
<Root level="INFO">
<AppenderRef ref="ASYNC"/>
</Root>
</Loggers>
</Configuration>
性能对比测试数据
在压测环境中的对比(单线程,输出100万条日志)结果如下:
| 测试场景 |
Logback同步 |
Logback异步 |
Log4j2同步 |
Log4j2异步 |
| INFO级别输出到文件 |
4.2秒 |
2.1秒 |
3.8秒 |
0.8秒 |
| DEBUG级别(不输出) |
1.8秒 |
0.9秒 |
0.5秒 |
0.1秒 |
| 内存占用 |
中等 |
中等 |
较低 |
最低 |
从数据可以看出,Log4j2的异步日志在性能上有压倒性优势,特别是在高并发、高频日志的生产环境中。
桥接器的魔法:统一历史遗留系统
如果你接手的老项目中混杂着各种日志API,SLF4J的桥接器就能大显身手。它允许你将旧的日志API调用,统一路由到SLF4J门面下,进而由你选择的实现(如Logback或Log4j2)处理。
<!-- 在pom.xml中配置桥接器,统一日志门面 -->
<dependencies>
<!-- 1. SLF4J API -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.7</version>
</dependency>
<!-- 2. 选择一种实现:Logback -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.4.7</version>
</dependency>
<!-- 3. 桥接Log4j 1.x -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>2.0.7</version>
</dependency>
<!-- 4. 桥接JUL (java.util.logging) -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jul-to-slf4j</artifactId>
<version>2.0.7</version>
</dependency>
<!-- 5. 桥接Apache Commons Logging -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>2.0.7</version>
</dependency>
</dependencies>
桥接器的工作原理很有趣:它通过提供与旧日志API完全相同的包和类名,“劫持” 了这些API的调用,并将其转发给SLF4J。例如,log4j-over-slf4j 提供的 org.apache.log4j.Logger 类,其内部实现实际上是调用SLF4J的接口。
系统级日志方案:从ELK到Loki的演进
解决了单个应用内部的日志问题,我们再来看看系统层面。当架构从单体演进到微服务,成百上千个服务实例分散在各处,集中式的日志收集、存储与分析系统就成为运维和开发的刚需。
ELK Stack:经典的三剑客
ELK是Elasticsearch、Logstash、Kibana三个开源产品的首字母缩写,它们分工明确,构成了一个完整的日志管道。
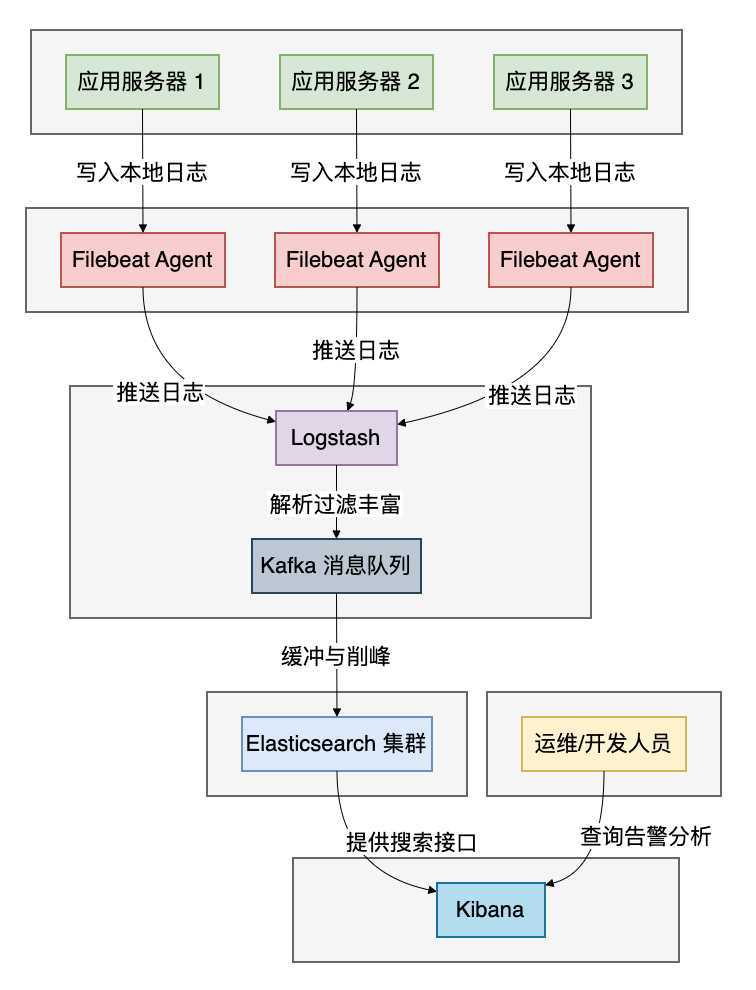
各组件的职责:
- Logstash:数据收集、解析和转发引擎。它支持丰富的输入源和过滤插件,功能强大但资源消耗也相对较高(基于JVM)。
- Elasticsearch:分布式搜索和分析引擎。负责存储由Logstash处理后的日志数据,并提供强大的全文检索和聚合分析能力。
- Kibana:数据可视化平台。为存储在Elasticsearch中的数据提供搜索界面、图表仪表盘和图形化分析工具。
ELK的典型配置:
# Logstash配置文件 logstash.conf
input {
# 从Filebeat接收日志
beats {
port => 5044
}
}
filter {
# 解析JSON格式的日志
if [message] =~ /^{.*}$/ {
json {
source => "message"
target => "log_content"
}
}
# 提取时间戳
date {
match => [ "timestamp", "ISO8601" ]
target => "@timestamp"
}
# 添加业务标签
if [log_content][service] == "order" {
mutate {
add_tag => [ "order_service" ]
}
}
}
output {
# 输出到Elasticsearch
elasticsearch {
hosts => [ "es-node1:9200", "es-node2:9200" ]
index => "app-logs-%{+YYYY.MM.dd}"
}
# 同时输出到监控系统
if "_grokparsefailure" in [tags] {
exec {
command => "echo 'Parse failed: %{message}' >> /tmp/failed.log"
}
}
}
EFK Stack:云原生时代的进化
随着Docker和Kubernetes的流行,ELK的一个变种——EFK Stack(Elasticsearch + Fluentd/Fluent Bit + Kibana) 成为了云原生环境下的主流选择。
为什么用Fluentd替代Logstash?
- 资源效率:Fluentd用C和Ruby编写,内存占用约40MB,而基于JVM的Logstash通常需要500MB或更多。
- 部署友好:Fluentd拥有丰富的Kubernetes元数据插件,能自动为容器日志添加Pod名称、命名空间等标签,天生适合容器环境。
- 可靠性:内置更健壮的缓冲和重试机制,能更好地应对网络波动或下游存储服务短暂不可用的情况。
# Fluentd在K8s中的配置示例
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluent.conf: |
<source>
@type tail
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
tag kubernetes.*
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match kubernetes.**>
@type elasticsearch
host elasticsearch
port 9200
logstash_format true
logstash_prefix fluentd
buffer_chunk_limit 2M
buffer_queue_limit 32
flush_interval 5s
max_retry_wait 30
disable_retry_limit
num_threads 8
</match>
Loki:日志管理的新哲学
Loki由Grafana Labs开发,其设计哲学与ELK/EFK截然不同:只索引日志的元数据(标签),而不索引日志内容本身。
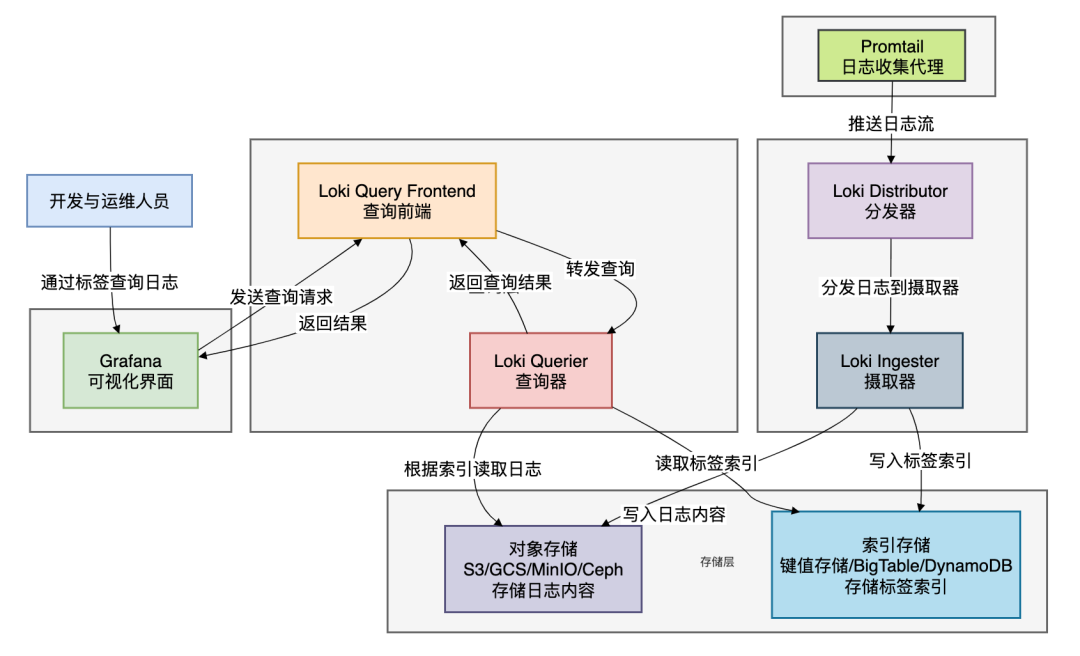
Loki的核心特点:
- 成本效益:存储成本约为ELK的1/10甚至更低,因为它不为日志内容建立庞大的倒排索引。
- 云原生友好:原生支持对象存储(如AWS S3、Google GCS、MinIO),存储扩展性和成本优势明显。
- Grafana原生集成:查询界面与Prometheus监控数据无缝集成,可以在同一个Grafana面板中查看指标和日志,实现真正的可观测性。
全方位对比:如何根据场景选择
现在我们对各个技术都有了深入了解,下面通过两个对比表格来帮大家做出更清晰的选择。
应用级日志框架对比
| 特性维度 |
SLF4J |
Logback |
Log4j2 |
| 定位 |
日志门面/抽象层 |
具体实现 |
具体实现 |
| 性能 |
N/A(接口层) |
良好 |
卓越(特别是异步) |
| 内存管理 |
N/A |
一般 |
优秀(GC友好) |
| 配置方式 |
N/A |
XML/Groovy |
XML/JSON/YAML |
| 自动重载 |
N/A |
支持 |
支持 |
| Spring Boot默认 |
是(通过接口) |
是(2.x之前) |
是(2.x之后可选) |
| 最佳适用场景 |
所有Java项目 |
Spring Boot传统项目 |
高性能、高并发系统 |
系统级日志方案对比
| 特性维度 |
ELK Stack |
EFK Stack |
Loki |
| 核心组件 |
Logstash+ES+Kibana |
Fluentd/Fluent Bit+ES+Kibana |
Loki+Grafana |
| 设计哲学 |
全文索引,强大搜索 |
全文索引,云原生优化 |
标签索引,成本优先 |
| 存储成本 |
高(索引所有内容) |
高 |
低(仅索引标签) |
| 查询能力 |
强大(全文搜索+聚合) |
强大 |
良好(基于标签筛选+LogQL) |
| 部署复杂度 |
高 |
中 |
低 |
| 学习曲线 |
陡峭 |
中等 |
平缓(尤其熟悉Grafana的话) |
| 云原生适配 |
中等 |
优秀 |
优秀 |
| 实时性 |
近实时(秒级) |
近实时(秒级) |
近实时(秒级) |
| 最佳适用场景 |
大型企业,有复杂分析需求 |
容器化环境,云原生架构 |
云原生,成本敏感,已用Grafana |
实战选型指南
基于不同场景和阶段,以下是一些实用的选型建议:
场景一:初创公司,快速启动
- 应用日志:直接采用Spring Boot默认的Logback + SLF4J。
- 集中日志:优先考虑SaaS服务(如Logz.io, Datadog, Sumo Logic),避免早期在运维和基础设施上的投入。
- 理由:最大程度降低启动成本,让团队专注于核心业务开发。
场景二:中型企业,微服务转型
- 应用日志:新项目采用Log4j2(特别是核心交易服务),老项目通过桥接器逐步统一到SLF4J门面下。
- 集中日志:如果已在Kubernetes环境中,选择EFK Stack;如果仍是传统虚拟机环境,则选择ELK Stack。
- 理由:在功能、性能和成本间取得平衡,为业务增长预留技术空间。
场景三:大型互联网公司,海量日志
- 应用日志:全栈推广Log4j2异步日志,并在关键服务链路中集成TraceID,便于分布式追踪。
- 集中日志:采用分层架构。
- 实时分析层:使用ELK/EFK,仅保留最近7-30天的热数据,用于快速查询和实时告警。
- 长期归档层:使用Loki + 对象存储(如S3),存储全量日志,用于历史查询和审计,成本极低。
- 理由:通过分层策略,兼顾查询性能与长期存储的经济性。
场景四:金融/电信行业,强合规要求
- 应用日志:必须使用Log4j2,并配置满足审计要求的日志策略(如操作留痕、不可篡改)。
- 集中日志:部署双ELK集群。一个用于生产环境实时监控,另一个独立的、访问严格受限的集群用于审计和合规检查,确保日志的完整性和不可否认性。
- 理由:首要满足行业监管和合规性要求,功能与可靠性优先于成本。
总结
看似繁杂的日志技术栈,其核心是分层设计的思路:
- 应用层:
SLF4J 是必须采用的统一门面。Logback 满足大多数常规场景,与Spring Boot集成友好;而 Log4j2 则在性能敏感、高并发的系统中成为首选。
- 系统层:
ELK 功能全面但资源和运维成本高;EFK 是云原生环境下的优化版本;Loki 以其独特的标签索引设计和低廉的存储成本,成为云原生和成本敏感场景的新兴选择。
- 核心原则:无论选择哪种技术,都应遵循统一门面、异步写入、结构化输出、集中管理的原则。
技术选型没有绝对的“最佳”,只有最“合适”。我们需要在功能、性能、成本、团队技能和运维复杂度之间做出权衡。
记住,一个好的日志系统,其终极目标不是技术栈有多炫酷,而是能否在关键时刻帮助团队快速定位和解决问题。日志是系统运行时最忠实的记录者,理解并驾驭好这些工具,是你与复杂系统对话的关键。
希望这篇梳理能帮你拨开迷雾。如果你想了解更多关于Java技术栈或DevOps实践的深度讨论,欢迎到云栈社区与更多开发者交流。
 发表于 2026-1-27 05:41:10
|
查看: 179|
回复: 0
发表于 2026-1-27 05:41:10
|
查看: 179|
回复: 0
