在高通于LPC 2025(Linux Plumbers Conference)的演讲中,其工程师Yiwei Huang分享了一个关于利用MPAM技术来协调CPU与系统级缓存(SLC)的有趣主题。

本次演讲的幻灯片可在此下载:
https://lpc.events/event/19/contributions/2121/attachments/1764/3909/Cooperation%20between%20CPU%20and%20system%20level%20cache%20by%20using%20MPAM.pdf
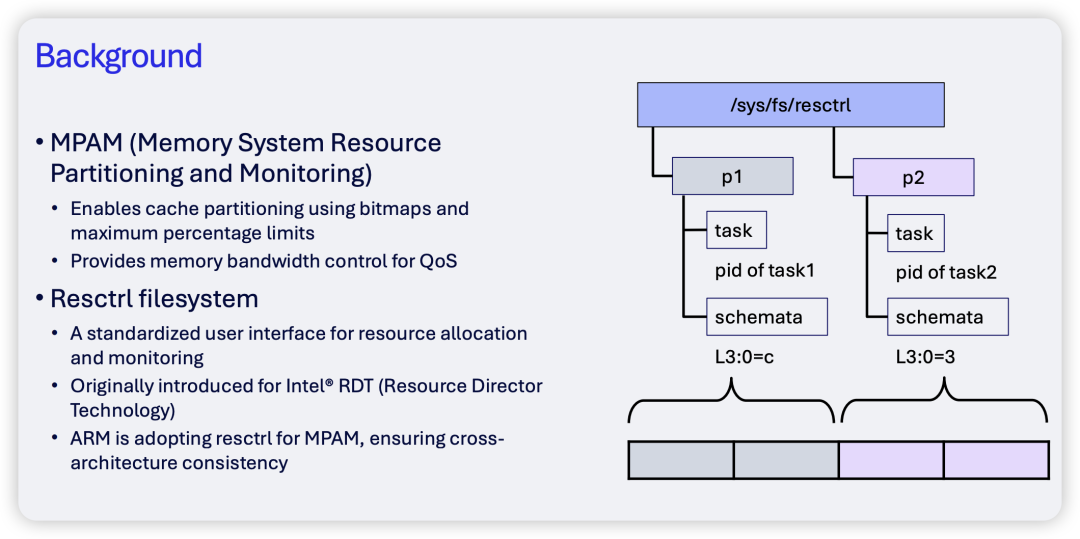
演讲首先阐述了使用MPAM控制SLC的目的:主要在于通过缓存分区来强制限制某些任务的最大缓存用量,并为内存带宽提供服务质量(QoS)保障。在用户接口层面,MPAM沿用了现有的Resctrl文件系统。
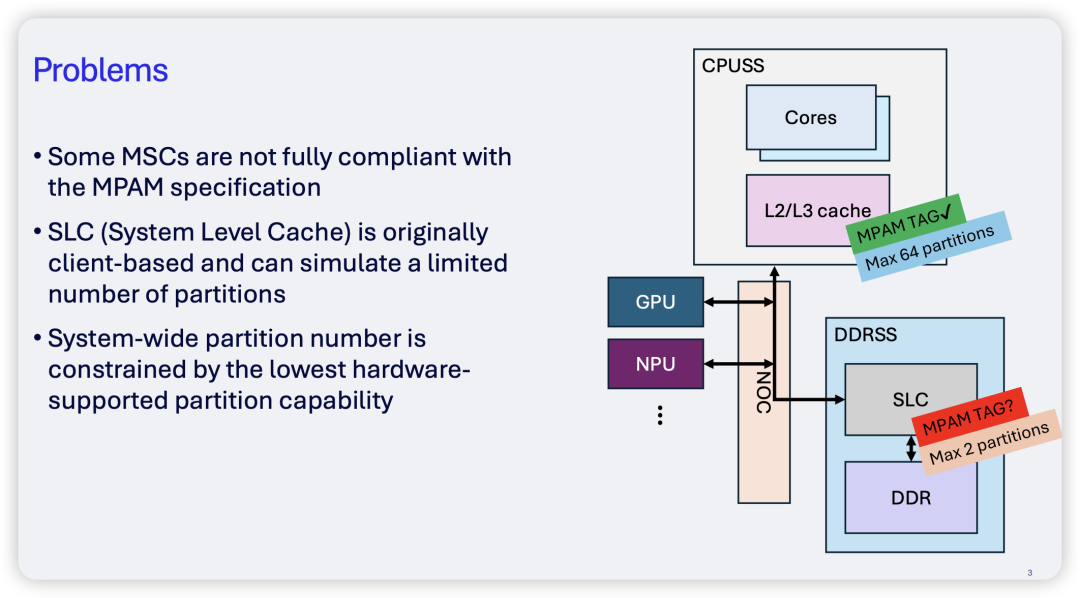
然而,在实际硬件中,并非所有的Memory System Component(MSC)都能很好地支持MPAM标准。CPU缓存(如L2/L3)堪称MPAM的“模范生”,但到了由NOC(片上网络)访问的SLC或DDRSS(DDR子系统)层面,支持就变得很弱,甚至是“假MPAM”。例如,某些硬件只能“模拟”有限的缓存分区,分区数量上限极低(可能只有2个),这严重制约了系统级别的分区灵活性。
为了解决这个问题,高通团队提出了一种解决方案。
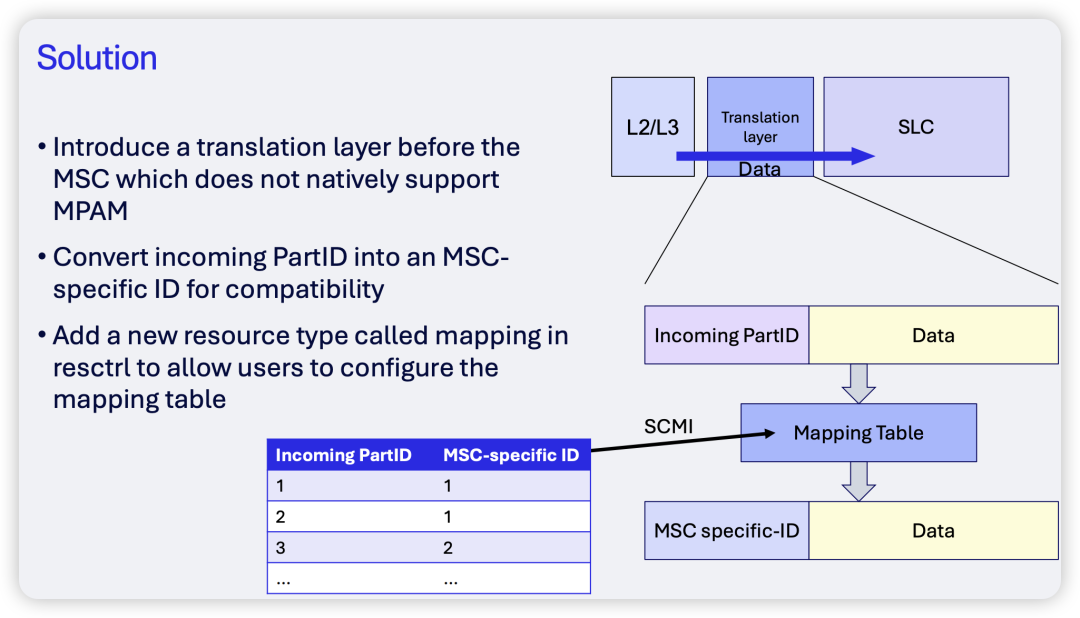
该方案的核心是在支持MPAM的模块(如CPU的L2/L3缓存)与不支持或仅部分支持MPAM的模块(如SLC或DDR)之间,插入一个“翻译层”(Translation Layer)。这个翻译层的功能是将标准的MPAM Partition ID(PartID)转换成下游MSC能够理解的特定ID,并通过一个可配置的映射表(mapping table)来管理这种转换关系。
接下来,演讲者列举了两个实际的应用场景。第一个场景是让“噪音邻居”线程完全绕过SLC。
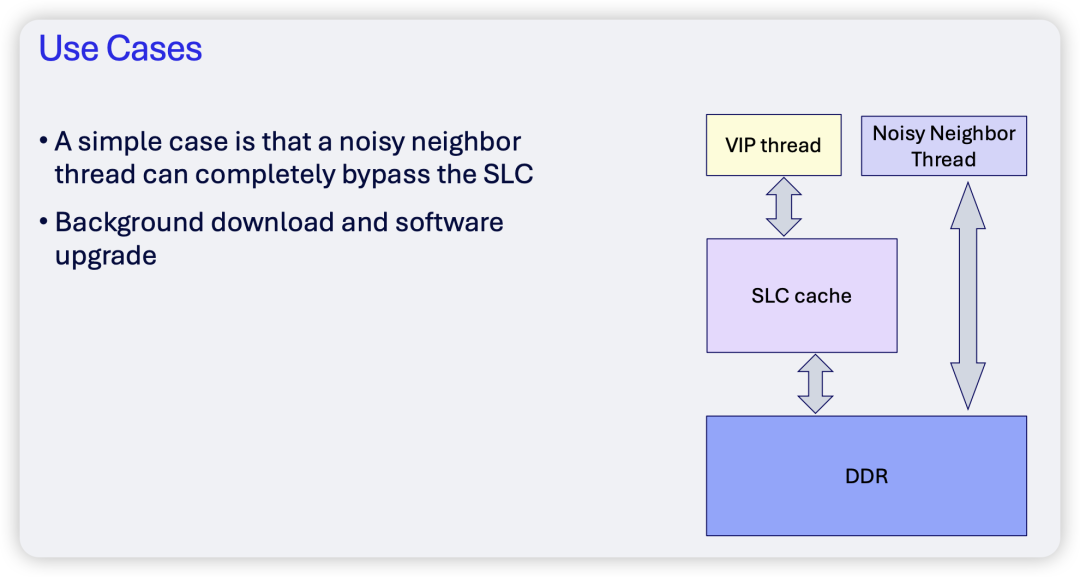
在这个场景中,所谓的VIP线程(如游戏的渲染线程、UI线程、音频线程或前台应用的核心线程)期望获得高SLC命中率、低延迟和稳定的内存带宽。而“噪音”线程(如后台下载、OTA更新、日志压缩或AI批量任务)通常具有大量流式内存访问、缓存局部性差、严重占用DDR带宽的特点。通过MPAM映射,可以将噪音线程的访问限制在DDR,从而为VIP线程腾出纯净的SLC空间。
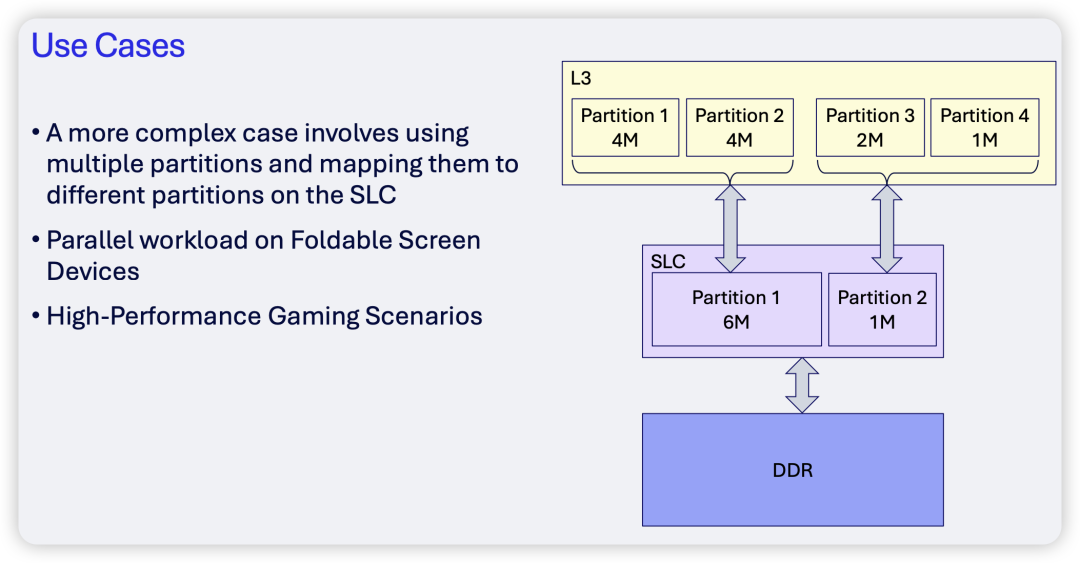
另一个复杂场景则适用于折叠屏设备或多任务并行的高性能游戏场景。在这个例子中,SLC被划分为两个区域。可以看到,标准的PartID 1和2被映射到了SLC的Partition 1,而PartID 3和4则被映射到了SLC的Partition 2。
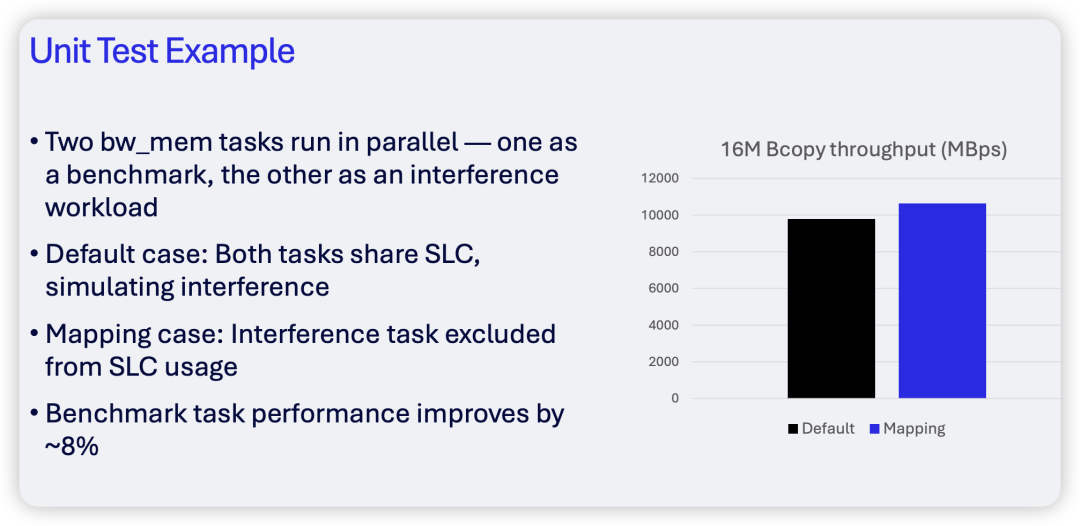
最后,Yiwei Huang展示了一个应用MPAM技术后的性能测试结果。在测试中,他们将bw_mem任务作为VIP任务,同时让干扰任务绕过SLC。结果表明,通过这种隔离,作为基准的bw_mem任务性能提升了约8%。
这些探讨为我们理解如何深度优化Android系统,特别是其Linux内核层的资源调度提供了宝贵思路。如果你对系统级性能调优或底层技术有更多兴趣,欢迎到云栈社区的网络/系统板块与其他开发者交流,或者在计算机基础板块深入探索缓存、内存体系结构等核心原理。 |  发表于 2026-1-27 07:33:02
|
查看: 180|
回复: 0
发表于 2026-1-27 07:33:02
|
查看: 180|
回复: 0
