这周ODCC的ScaleUP会议中,除了讨论某公司DPU的安全缺陷外,一个更重要的议题是探讨ICMS等在推理场景下接入存储的解决方案。当前也有一些基于CXL的方案,但多属于短期修补。从长期来看,一个实质性的话题是:“伴随着Agent的大量部署,今年将成为真正的推理基础设施元年”。
昨天在Linkedin上看到Rakesh Cheerla的一个帖子,也指向了这个话题中很关键的一环——存储网络与ScaleUP网络的融合。更广义地说,这其实是 “FrontEnd(包含VPC和存储)、ScaleOut和ScaleUP如何实现三网融合” 的问题。
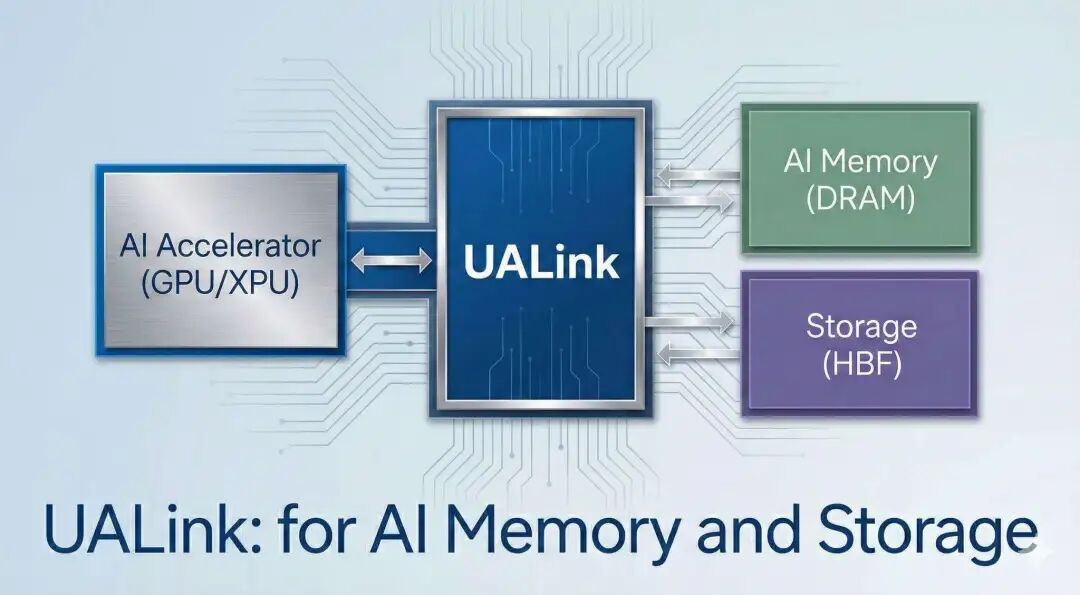
他大致的观点是,基于CXL的方案存在“主机税(Host Tax)”,这个词用得很形象。它受限于PCIe物理层限制,尽管未来有PCIe Gen7的路线图,但PCIe协议本身也存在很大约束。在ScaleOut上支持CXL也有不少问题,至少目前没人愿意做支持CXL的GPU。
另一方面,Rakesh对NVLink生态的封闭性提出质疑,希望其能更开放;同时,CXL也有转向UALink的趋势,希望构建一些相对偏小Radix的UALink Switch来连接存储。
他最后还有一个观点,认为这样的开放可以挑战基于以太网的方案。对此我并不完全认同,因为生态和规模的问题不完全是一个技术层面上的问题,还涉及大量的商业博弈。
本文的结论是:GPU作为数据中心的一等公民,应以GPU为中心重构服务器,在ScaleUP上扩展内存、存储和IO。
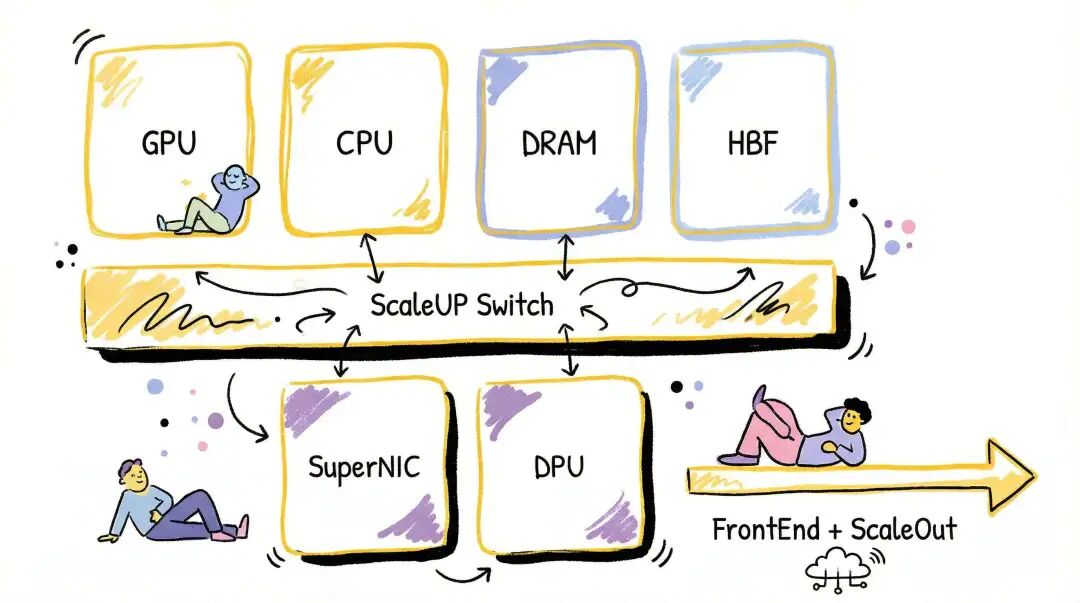
1. 为什么需要三网融合?
以Nvidia为例,对于GPU而言需要同时考虑ScaleUP、ScaleOut以及连接内存扩展的NVLink C2C。
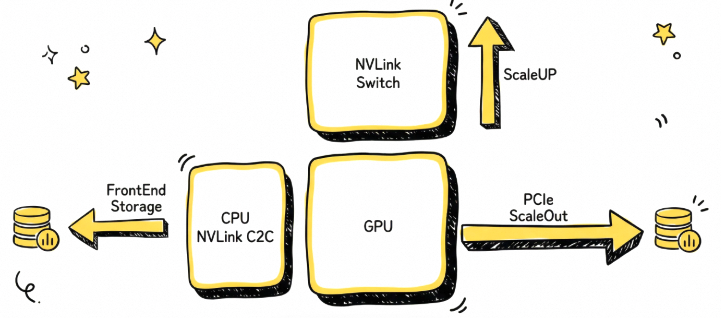
这三种独立的数据路径使得编程复杂度提升,数据搬运成本增高,并且无法根据实际工作负载进行动态的带宽配比。
当然,三网分离也有好处,例如Nvidia常说的“买的越多,省的越多”。特别是当它们相互通信存在干扰时,只要这个技术假设存在或未被解决,三网独立的架构就会延续下去。核心前提是如何解决通信干扰。
在训练场景下,大家争分夺秒抢时间,多花一点钱多建几套网成本占比并不突出。但在推理场景下,毕竟是按照Token进行商业化竞争,特别是未来推理规模远大于训练时,成本中1%的绝对金额都是一个巨大的数字。如果一家MaaS服务商能通过基础设施优化,将推理成本比对手降低10%以上,即使使用相同的GPU和相似的推理速度,也会带来极大的竞争优势。
结论:三网融合的考虑更多是从推理基础设施的角度出发,旨在进一步降低成本。但难点在于如何解决通信的相互干扰,例如EP(Expert Parallel)的通信流量与KVCache/存储等流量混合时如何管理。
2. 未来AI基础设施的演进
2.1 前置技术背景
关于GPGPU的路线,以Nvidia为代表的进展已有详细分析。对于TPU/Trn这类ASIC架构也有相应探讨。ScaleUP和ScaleOut互连的技术细节可参考相关文章。
2.2 从业务的视角分析
从业务视角来看,我们首先需要找准AI下一步Scaling的方向,如下图所示:
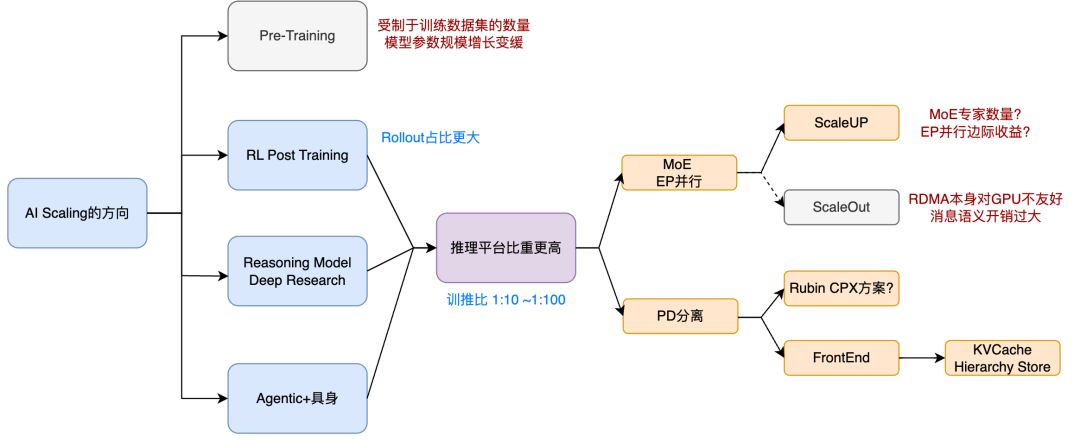
整个AI Scaling的重心正逐渐转向RL后训练、Reasoning模型及相应的深入研究,以及Agentic+具身智能的路线。对于RL后训练,Rollout(推理)占比更大;而后两者也以推理为主。AWS Re:invent也提出了类似的业务视角:
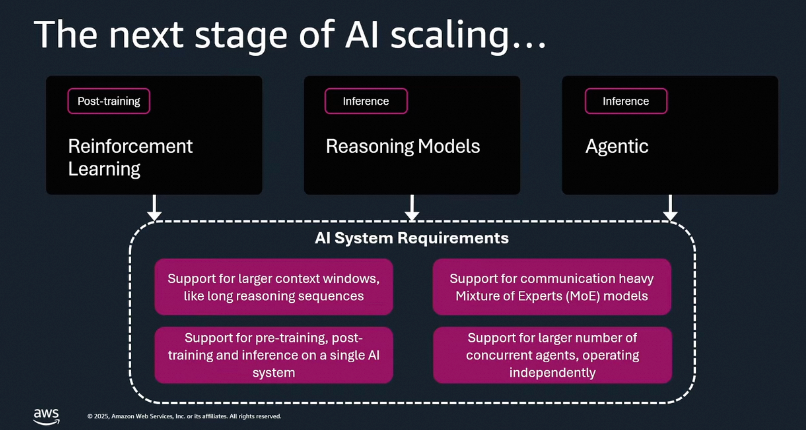
AWS得出的结论对AI基础设施的需求有4点:
- Reasoning模型和Agentic需要更长的上下文,这需要新的注意力算法,同时也催生了PD(Prefill-Decode)分离以及超长上下文KVCache存储的需求。
- 支持对于MoE(混合专家)模型这类通信密集型模型的需求。
- 训推一体,支持预训练、后训练和推理在同一个系统上运行。
- 支持超大规模并发的Agent执行和独立操作,这需要租户间隔离,并要求AI基础设施与通用CPU计算集群更好地互联和弹性配合。
2.2.1 预训练业务
首先对于预训练阶段,当前模型参数规模的增长受制于训练数据量的约束正在放缓。从一个粗略的信息压缩视角看,人类数据规模约30T Tokens,若信息压缩比做到10:1,模型总参数规模的上限粗略估计在3T左右。因此,整体模型参数规模的增速在放缓。
当采用超节点机型后,我们可以将TP和EP的流量尽量限制在ScaleUp域内,ScaleOut仅承载PP和DP的流量(这些流量通常也能很好地被Overlap)。这就引出一个问题:是否可以适当缩减ScaleOut带宽,或者直接将其并入FrontEnd网络?
正方的观点
从业务视角看,FrontEnd配合一些分层的集合通信和基础设施Overlap,并适当扩大FrontEnd域的带宽,或许就能满足需求。避免使用独立的ScaleOut网络可将整体成本降低10%~20%,电力开销也会相应降低。
但是,FrontEnd承载RDMA业务本身难度很大,特别是在与VPC内其他TCP流量和存储流量混合运行,以及处理网络Hash冲突/拥塞控制等问题上,Nvidia的RoCE网卡有很大的局限性。这也是Nvidia一直宣传FrontEnd承载N-W流量、ScaleOut承载E-W流量,且存储也需要独立组网方案的原因。
事实上,工业界能够完全解决这个问题的公司很少。AWS SRD不支持标准RDMA Verbs接口,Google Falcon在多路径算法上存在缺陷且无法支持跨Scale域的长传输。真正能做的可能屈指可数。
我们看到AWS在Trn3 Gen2上已经提出了融合FrontEnd和ScaleOut的解决方案,并提供了相对低带宽版本(每卡200Gbps)的实例。
反方的观点
对于算法和基础设施工程师而言,一个简单的逻辑是:只要提供了足够的带宽,就一定会想尽办法调度通信将其打满。另一个观点来自CSP(云服务提供商):我们并不希望训练和推理完全分池。当训推比大于1:5时,省去ScaleOut的成本可能很吸引人,但这可能导致训练集群资源不足,影响整体售卖率。
此外,通常会用最新的卡做训练,老一点的卡做推理。因此,ScaleOut网络的成本摊销不能简单地按整生命周期计算。对于一个生命周期5年的集群,ScaleOut网络的成本摊销到推理业务时,应以某种残值计算。
另外,对于生命周期早期的新卡,其溢价较高。如果一个没有ScaleOut网络的集群,其早期收入与竞争对手相比的折扣,是否会导致节省ScaleOut网络带来的成本优势丧失,也需要仔细核算。
从GB200开始,Nvidia的叙事逻辑已演进到推理。未来新部署的卡中,用于推理的比例是否会超过70%?这又将需要重新评估整体的ROI模型。从一些分析口径看,明年美国的新建卡总规模已接近1600万卡,新卡的训推比分布,以及一些新型云服务商或CSP是否会构建无需ScaleOut的实例,可能很快就会有答案。
2.2.2 RL后训练
对于RL后训练而言,Rollout(推理)的时间占比远高于参数更新训练,因此它是一个非常重推理的业务。推理本身可能更关注EP的通信流量,因此构建超节点在某种意义上成了刚需。在一些超节点集群上,训练参数的更新等操作可以在ScaleUP上完成,或构建一个分层的集合通信。理论上,省掉ScaleOut网络对端到端性能的影响会非常小。
2.2.3 Reasoning模型和Agentic
对于大量的Reasoning模型,特别是配合进行的一些深度研究任务,通常还需要调用外部工具和并发Agent执行。另一方面,大规模的Agent并发执行和多租户服务的要求,使得客户很可能将这些Agent放在自己的VPC内与已有系统融合。
这就对FrontEnd网络的高并发需求提出了更高要求。此外,这类工作负载通常需要更长的上下文,因此对PD分离和KVCache存储提出了更高需求,层次化的KVCache逐渐会成为刚需。
最后,Agentic也对通用计算提出了更高的弹性需求。通常一个复杂的Agent任务涉及多步业务调用,且对某些应用的延迟有非常严苛的要求。整个链路上的长尾延迟将对SLA产生巨大影响。因此,对Agent执行环境的安全隔离、快速拉起以及高并发能力提出了新挑战。
简单估算,一个日活2000万的Agentic业务,可能需要的存储规模为每日写入超过200PB数据,并发的Agent执行环境可能需要数百万台VM。
2.2.4 小结
总体来看,对于纯推理平台(Reasoning+Agentic)和RL后训练,对ScaleOut这个后端孤岛的需求似乎不那么强烈。但对于预训练场景,还存在业务争议和不确定性。这部分内容我们暂且搁置,主要关注其他两个方面的问题。
- EP并行:基本确定需要支持基于内存语义的ScaleUP网络构建超节点,唯一不确定的是EP的规模和超节点的规模。
- FrontEnd网络需求:主要是模型推理的结果需要传输到Agent节点运行,而Agent大量部署在用户的VPC内。
- PD分离:EP这类业务在ScaleOut RDMA的消息语义上本就不友好,即便与PD混合运行也存在很大干扰。而KVCache也有接入存储构建分层缓存的需求,通常会将其放入FrontEnd网络中。FrontEnd和ScaleOut融合还可以进一步将KVCache传输通过GDA/GDS直接加载到GPU显存内。
至于某些宣传过度的分离方案,其开局就面临与EP同样的问题。实际上,我自己年初分析后认为没有收益就无视了。后来有厂商跟进,前几天公开测试结果显示,在50ms SLO下性能下降1%,100ms TPOT下才有19%性能收益。这个SLO已非可用级别,此处不再赘述。
2.3 算法演进
首先,我们需要从算法最基础的点来阐述:智能是什么?一个简单的观点是:它是一个在超高维度空间内,按照某种结构压缩而成的低维流形。
2.3.1 从物理的视角
从物理世界看,Demis Hassabis有一个假设:自然界的很多规律无需写出显式方程,而是可以通过在图灵机上以数据压缩的方式学习出来。例如,AlphaFold预测了原本需要数月甚至数年才能解析的蛋白质折叠结构。从蛋白质的理论来看,这是一个10^300量级的空间,无法穷举或物理模拟,但自然界中的蛋白质能在毫秒级自动完成折叠。这本质上就是在超高维空间中,按照某种结构压缩而成的低维流形。因此,自然的行为模式在高维空间中稀疏分布、结构清晰、路径稳定——它们集中在一种可压缩、可调度的结构空间中,构成了低维流形。AlphaFold的本质也是如此。
2.3.2 从数学的视角
从数学角度看,相关工作一直在进行。一个简单的结论是:这一次人工智能革命的数学基础是:范畴论、代数拓扑、代数几何这些二十世纪的数学首次登上商用计算的舞台。
正如前一节的观点,智能是超高维空间内压缩的低维流形。那么,代数拓扑/代数几何则是对这种结构化压缩进行良好描述的工具。例如,代数拓扑通过一些代数不变量来区分和分类不同的拓扑空间,从而在算法层面描述低维流形上“自然允许走的那些路径”。
另一个更基础的研究是在范畴论的基础上展开,探讨如何在计算范式上构造一个合理的代数系统,并在算法研究中从代数结构上排除一些不必要的探索。一个简单的做法就是把Attention看作是范畴论中的态射,而预训练的实质是在构造一个Presheaf。其核心结论来自于Yoneda Lemma:你不需要知道一个对象的“内部构造”,只需要知道它如何与外界“交互”,就能完全理解它。这种描述与“超高维空间内压缩的低维流形”的实质是一样的。
2.3.3 从计算机体系结构的视角
从计算机体系结构的视角来看,算力是很容易扩展的,而访问内存则很难扩展。因此,整体算法路径上需要一个合理的、可训练的稀疏化方式。
另一方面,如果低维流形的实质是在经典图灵机上通过数据压缩学习出来的,那么如何让模型结构本身构成一个高并行的图灵机结构?这个视角解释了Transformer架构的有效性。如果说最早的Token-by-Token推理是一个顺序纸带的图灵机,那么Reasoning模型的出现本质更像一个比较完备的图灵机了,但似乎缺少一些纸带回退和擦除的能力。这些回退和擦除或许是推理阶段节省复杂度的一个好方法。
当试图通过大模型架构构造一个能够自己产生代码运行的通用计算机架构时(即Token as Instruction),思路就豁然开朗了。大模型可能真的要从自回归走向自生成指令了。那么,构造一个大模型的冯·诺伊曼架构大概如下:
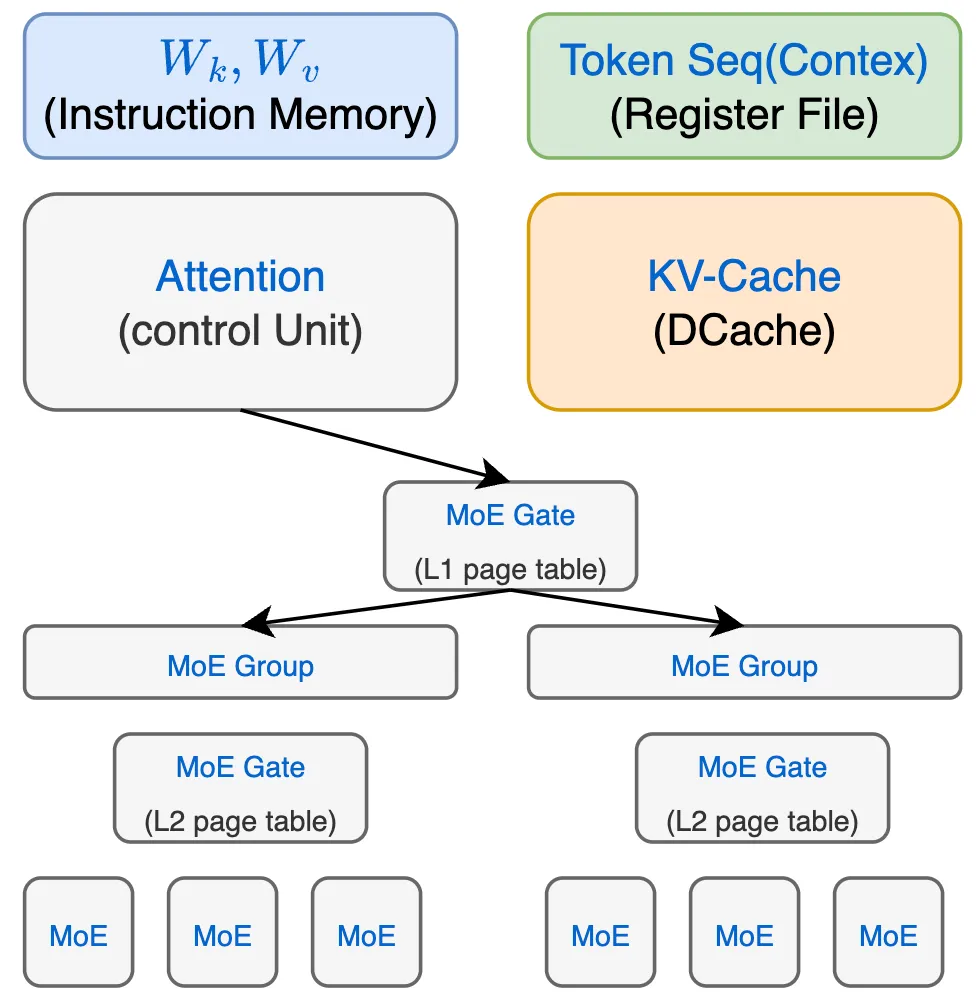
即以Attention作为图灵机的计算控制单元,MoE作为存储器。
2.3.4 Attention
关于Attention的演进,实质性问题仍是继续进行稀疏化处理。从自然选择角度看,Sparse Attention中按Block处理对于很多Agent任务拼接上下文也可以节省大量Prefill算力,这方面比Linear Attention有优势。
当然,Linear Attention某些类似于RNN的属性仍很有价值,但不妨碍我们在Sparse Attention中引入一些递归循环处理,在内存访问不显著增加的情况下增加计算规模是可行的。
2.3.5 MoE
另一个值得关注的问题是MoE的未来规模。部分网络背景的厂商认为需要“一卡一专家”,因此将超节点规模维持得很大。但我们看到Nvidia Rubin最大规模为144卡,Trn3实际的EP并行单柜为72卡。对于当前256个Expert、Topk=8的常见MoE模型,通常在GB200上EP32就够了。
那么,关键问题是Expert数量是否会超过256/384,达到1024/2048,TopK达到64?答案是否定的。这一点在相关文章中有详细阐述。实际决策流程如下:
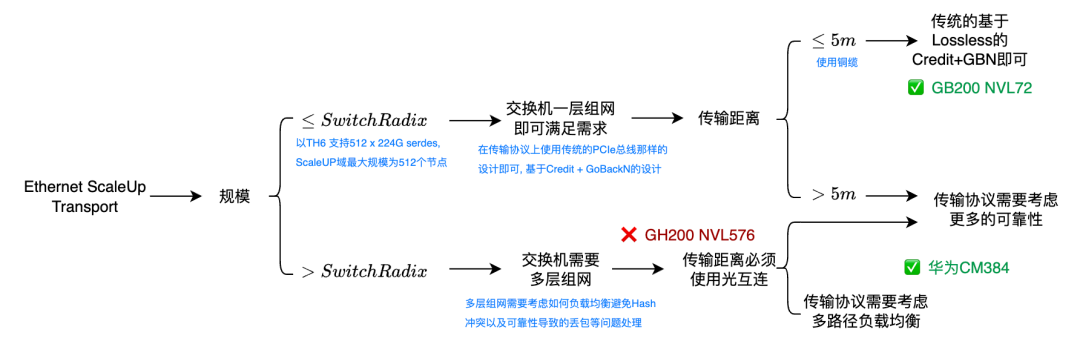
首先,从模型训练角度看,专家数进一步提升稀疏性会导致训练崩塌,以及后训练任务中训推不一致的问题加剧。因此,单层的专家总数最大可能会维持在512以内。
假设一个极限稀疏情况:专家数M=512,K=8,batchsize N=32,需要访问的专家数为202个。当专家数扩展到1024时,需要访问的专家数为227个。这带来了巨大的内存访问瓶颈。通过EP并行,例如每卡8个专家,访问专家参数的带宽可以下降到原来的3%。此时,EP的规模为128卡。
结论:从并行策略分析,满足交换机单层组网的Radix规模(如最大512卡)即可。实际部署时,考虑弹性伸缩需求,ScaleUP的规模可能还会进一步降低。可以看到,即便是Rubin Ultra的NVL576,其单个ScaleUP域也只有144卡的规模,并且Nvidia仍选择铜互连。同样,AWS Trn3服务器、AMD MI450x都在做类似决策。
即便是Google号称通过OCS连接了一个9216卡的ScaleUP域,它也仅是一个调度域,实际单个实例的规格也是8x8x8=512卡。对于Google而言,未来是否还会维持3D-Torus拓扑也是一个变数。
2.4 从商业模式的视角分析
对于新型GPU云服务商的业务模式,其存在的风险已有详细阐述。实质性的问题是计算资源的弹性供给和流动性管理。最近几个月,几家新型云服务商和Oracle已逐渐陷入流动性风险。未来一年,北美账面新建规模达1600万卡,充足的供应下,流动性风险将进一步凸显。
对于CSP而言,弹性的训练和推理业务模式将在GPU资源池规模足够大时变为刚需。例如,AWS在最近的Re:invent上也讨论了Checkpointless和弹性训练。
而对于推理业务,其峰谷效应更明显,构建更具弹性的推理平台对于MaaS服务商的成本管理具有极大优势。实质性的技术问题就是:存算分离和多租户隔离。支持存算分离和多租户隔离的GPU实例,实质上是完成了算力的“证券化”过程。
2.5 从基础设施视角分析
前面几节从应用、算法再到经营的角度分析了一系列需求,最终需要落在基础设施的实现上。
2.5.1 算力芯片微架构
需要回答的问题是:选择DSA还是GPGPU路线?
从体系结构视角看,通常的解决办法分为4个方向:
- 提高并行性
- 降低数值精度
- 更好的数据局部性(DataLocality)
- 领域特定语言(DSL)
对于提高并行性,无论DSA还是GPGPU都在演进到Tensor Core + Vector Core + Scalar Core的架构。对于数值精度,基于块缩放的低精度压缩格式也都在支持。
本质的区别在最后两点。在数据局部性的处理上,DSA需要更底层地管理内存和排布流水,对编译器的要求比GPGPU更高。而DSL则是在易用性上解决数据局部性复杂的问题,这是最近几个月的一个竞争热点。
此前有一个关于数据局部性的对比:DSA通常是一块很大的SRAM,而GPGPU通常有更深的内存层次化结构。
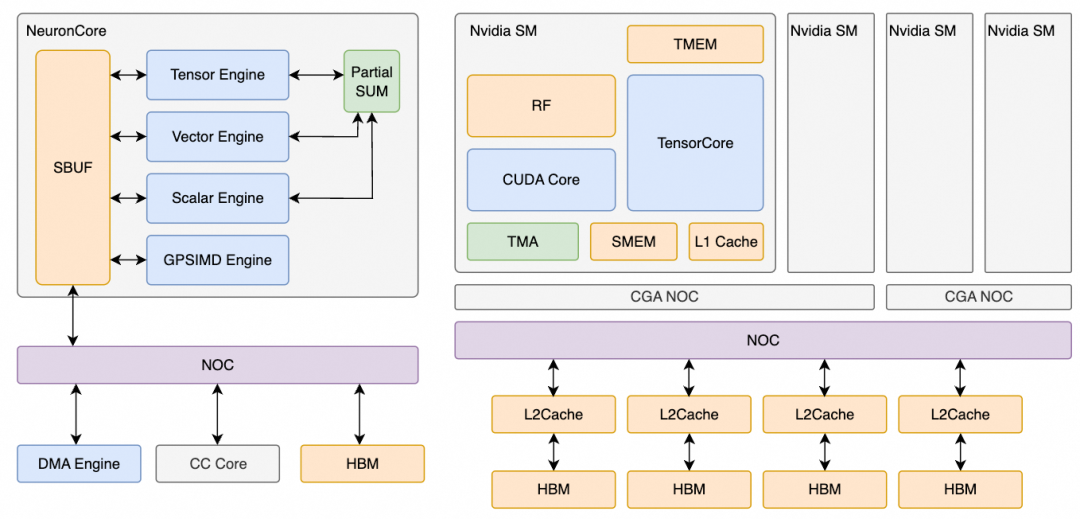
实际上,追求极致性能的基础设施工程师对DSL的依赖可能并不大,有时不如内联一些指令方便。在Tile-Based DSL架构下,受众是配合算法开发的基础设施工程师,他们有提高数据局部性的需求,但又不极致追求性能。通常一个实验需要跑半个月,算法研究员不会给配合的基础设施工程师长达一个月的算子开发时间。开发周期可能少于几天,这时DSL便是一个很好的选择,即使无法打满峰值性能,获得70%左右也很有价值。
那么,唯一的区别就在内存子系统设计上了。实际上,针对CUDA编程,伴随着Tensor Core的引入,对于SMEM/TMEM的内存分配管理访问,即使在Hopper/Blackwell上有更好的异步MBarrier处理能力,但整体编程复杂度和对用户心智的影响仍然很大。特别是在Blackwell上,跨物理Die引入了接近400个时钟周期的延迟差异,对一些较小的Kernel运算也有显著影响。
在Tile-Based DSL下,DSA架构和GPGPU架构对于内存管理的复杂度实际上都有显著降低。因此,DSA和GPGPU的区别正在逐渐模糊化。唯一的区别可能在一些算力调度上:GPGPU的指令发射/Warp调度通常在加速器内部实现,但也逐渐面临问题。例如,TMA/Tensor Core的异步指令发射仅需一个线程,但通常又不得不调度到一个CUDA Core的Warp上执行。而Warp执行时为了保证吞吐,很多指令发射又带有Stall Control-bits。因此,对于低延迟业务存在显著缺陷。
这也是RDMA不适合GPU微架构的根本原因,主要包含几个方面:RDMA通信需要构造WQE,这对SIMT CUDA Core是低效且延迟较大的;在完成事件通知机制上,RDMA无法直接通知并更新SMEM中的MBarrier,而是需要CUDA Core轮询GMEM,每次轮询会带来极大延迟和Warp调度开销;更进一步,完成队列的数据结构对GPU处理也是消耗巨大的。当然,RDMA对于DSA架构也有同样的问题。
这也就是为什么在MoE这样的EP并行处理上,需要采用ScaleUP总线的原因。实质性的需求是使用对GPU和DSA微架构友好的内存语义。
2.5.2 系统互连架构
先给出一个最直接的结论:GPGPU/DSA这些算力芯片需要在整个系统互连体系中成为一等公民。 简而言之,就是要构建GPU Direct Everything。
一个朴素的观点是:GPU作为算力芯片,正在替代CPU成为新一代的算力中心,那么它理应成为整个数据中心的一等公民。紧接着,作为一等公民需要直接访问数据中心内的一切资源,避免额外的开销。例如,直接访问KVCache存储,直接控制CPU-Agent实例,直接访问EBS/OSS等云存储处理数据和存储Checkpoint等。因此,GPU Direct Everything成为刚需。最后,云的弹性经营逻辑推导出云需要多租户安全隔离和存算分离来实现弹性调度。
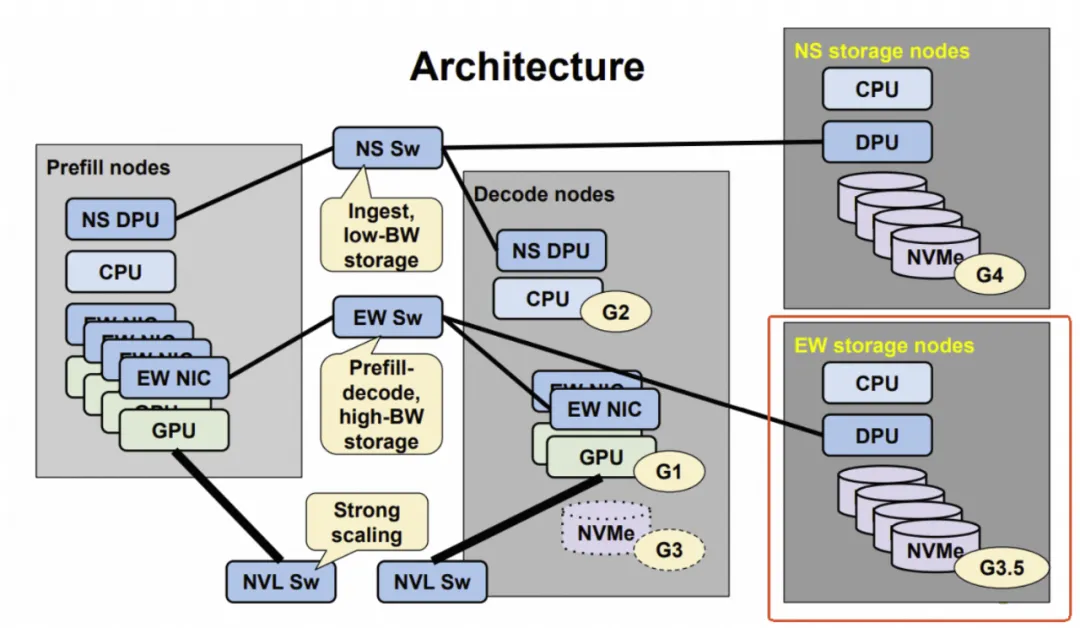
从当前的GPU架构来看,通常由三张网络构建,如下图所示:
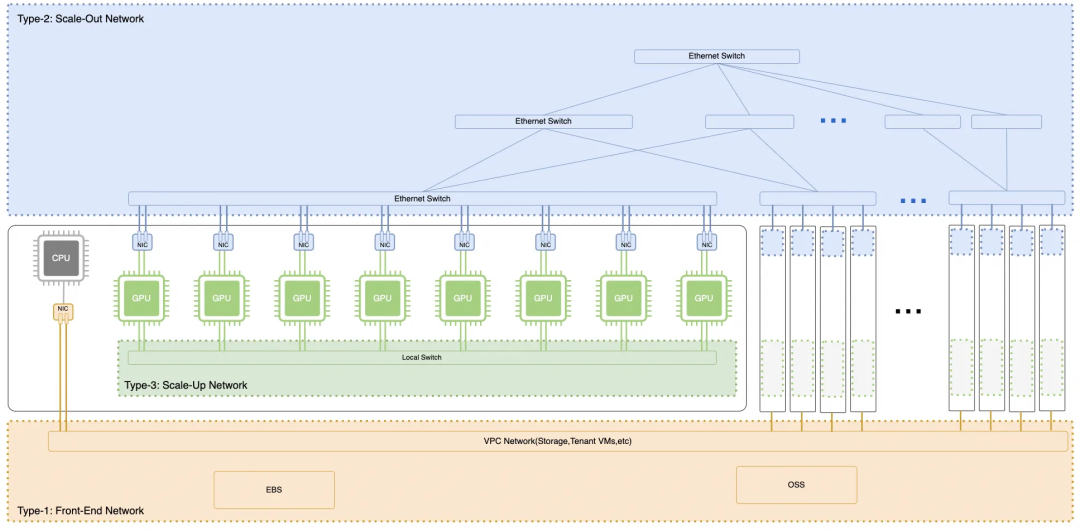
- Type1: Front-End Network:用于VPC互联和访问EBS/OSS存储业务。
- Type2: Scale-Out Network:基于RDMA网卡的多机扩展互联网络。
- Type3: Scale-Up Network:基于NVLink私有总线构建的多GPU机内互联网络。
从整个云基础设施和弹性调度的视角来看,GPU在FrontEnd中作为加速器模式挂载到CPU下,是二等公民。从经营的弹性调度视角看,GPU需要接入存储并支持多租户连接。从业务视角看,Agentic/RL等业务也需要更大的FrontEnd带宽,以及更长的上下文也需要GPU连接到一个分层的KV-Cache池中,并且这个HiCache池也是一个弹性多租的业务模式,以提升整体资源利用率。同时,对于弹性部署还需要更快的模型加载速度。
实质性的结论也是:GPU需要接入存储,成为一等公民。
关于EP并行
当前的一些变化是,对于EP一类的流量需要支持内存语义的超节点,ScaleOut承载EP并行仍存在限制。在超节点的演进过程中,单个超节点通常包含64~144卡,实际上我们可以看作是GPU已经在单机柜内完成了基于内存语义的ScaleOut从8卡扩展到了64~144卡。对于一个GPU而言,算力所需要的网络带宽是有上限的,它毕竟不是一个网络交换芯片,大量的计算和访问内存瓶颈决定了这个上限。因此,在超节点机型上,ScaleOut是否还需要如此大的带宽是一个有争议的话题。相反,对于那些依旧维持8卡架构的B200/B300服务器,随着算力提升,对ScaleOut的带宽需求仍在增加,这部分实例中ScaleOut是刚需。
关于PD分离
从业务视角上,我们还需要考虑PD分离部署下的技术选择。对于Rubin CPX方案,它分为两种部署:一种直接在NVL144机柜内将Rubin CPX串接在ScaleOut网卡和Vera CPU之间。

另一种做法是采用VR CPX + VR NVL144双机柜部署,利用ScaleOut网络互连。
官方的两种方案各有优劣。VR CPX NVL144采用固定配比,并且丧失了ScaleOut GDR的能力;而双机柜方案虽然天然支持xPyD,但又会导致在ScaleOut上同时进行KVCache传输和EP并行流量相互干扰的问题,同时增加了许多Vera CPU和CX9网卡。通常一张CX9网卡售价约2000美元,一张Rubin CPX估计在3000~5000美元附近,再摊销ScaleOut光纤和交换网络的成本到Rubin CPX上,Nvidia那句“Buy More,Save More”是否成立?
另一种成本核算视角是采用FrontEnd承载PD分离的流量,并引入层级化的KVCache缓存。但对于PD分离的流量,GPU需要通过PCIe Switch连接到CPU,然后再通过CPU直连的DPU传输KVCache。这样的路径下,PCIe Switch有天然的收敛比,同时CPU的内存子系统也会受到大带宽冲击。
那么,接下来FrontEnd和ScaleOut融合,直接将GPU作为一等公民,是否可以避免这样的问题呢?
FrontEnd和ScaleOut融合
一个简单的权衡是:对于超节点集群,适当提升FrontEnd带宽能否承载ScaleOut的流量?实质性的目的是把GPU提升成为一等公民,这符合业务演进的逻辑。
业务逻辑非常朴素,但技术挑战巨大。特别是RDMA/RoCE本身就是一个不完善的可靠传输协议。对于商用RDMA/RoCE,当它与其他流量混合运行时,相互干扰带来的性能下降非常明显。因此,独立构建一个RDMA专用的ScaleOut网络是有业务收益的。
但是这个技术挑战已经被解决了。无论是AWS SRD还是Google Falcon,都有完善的解决方案。而阿里云CIPU eRDMA更是在所有的8代以上通用计算实例上,基于VPC构建了RDMA能力。对于RDMA和TCP混跑甚至与存储流量并网,在技术上已经可行。因此,将GPU作为一等公民在技术上是成立的,相关的智能 & 数据 & 云技术也在快速发展。
3. 为什么三网融合很难构建?
3.1 生态和利益的原因
一个简单的利益相关逻辑是:计算总线和互联网络在过去几十年一直是相对独立发展的两个领域,也就是“计党”和“网党”之间有泾渭分明的分割点。并且,通用网络的带宽演进比计算总线慢很多。但最近十年发生了一些变化。
一方面是Intel在利益捆绑下缓慢更新PCIe总线标准,并且PCIe自身的控制权需要在一个树状拓扑下被CPU RC控制。这使得PCIe总线演进非常缓慢。相反,互联网的崛起使得数据中心以太网带宽基本上保持了两年翻倍的节奏,持续了十年。现在以太网的带宽已经远超PCIe的演进速度。
另一方面是商业利益的驱使。就像Intel时代不会轻易开放UPI一样,只会在面临极大竞争压力时,才会逐渐接受CXL,但依旧不愿给CXL更大的带宽,最终CXL发展多年仍不温不火。
同理,NVLink当年出现的目的就是为了挑战Intel控制的PCIe带宽约束。可惜当年的屠龙少年如今也成了“恶龙”。虽然NVLink可以授权了,但在很多系统设计上还有不少约束,这些约束或多或少也是商业决策导致的。
当然,AMD想成为新一代的挑战者,或许还需要一把利刃来配合UALink。AMD GPU本身的竞争力才是最关键的。同理,对于SUE/ESUN也是如此,它需要一个极强的XPU为它站台。
当然,也有人反驳:为什么需要一个跨厂商的ScaleUP标准?如果ScaleUP只连接各种GPU,根本不需要开放,每家自己搞一套就行了。背后有一些潜在的约束:作为整个行业挑战者身份存在的非Nvidia GPU/NPU厂商,做一款好的计算芯片已经非常困难,还要继续花精力去做交换芯片和互连芯片将是更大的挑战。从资金、技术等多个维度考虑,很难有一家厂商能够像Nvidia那样在整个系统中构建六颗芯片(GPU/CPU/NIC/DPU/ScaleUP Switch/ScaleOut Switch)。
那么,从生态利益的角度来看,AMD构建CPU/GPU,博通在Switch上提供支持,然后在DPU/NIC上引入其他厂商参与竞争,是一个不错的选择。况且,NIC和DPU本就是Nvidia的一大软肋。同时,整个系统也需要多厂商接入计算总线,例如DRAM、HBF、NVMe存储等。
但是,开放性的协议组织若没有一个绝对强势的领导者,或许就会像现在的UEC一样成为一盘散沙。这也是导致国内外在ScaleUP标准上展开激烈竞争的根源。背后又掺杂着计党/网党博弈,以及两波人认知上的差异。
3.2 技术上的约束
有一个问题不知大家深思过没有:为什么Nvidia提到的ICMS系统中,基于BF4的存储节点是机柜级的,并且还需要绕过FrontEnd,经过CPU再转到GPU上?
虽然层次化的结构看上去挺有道理:
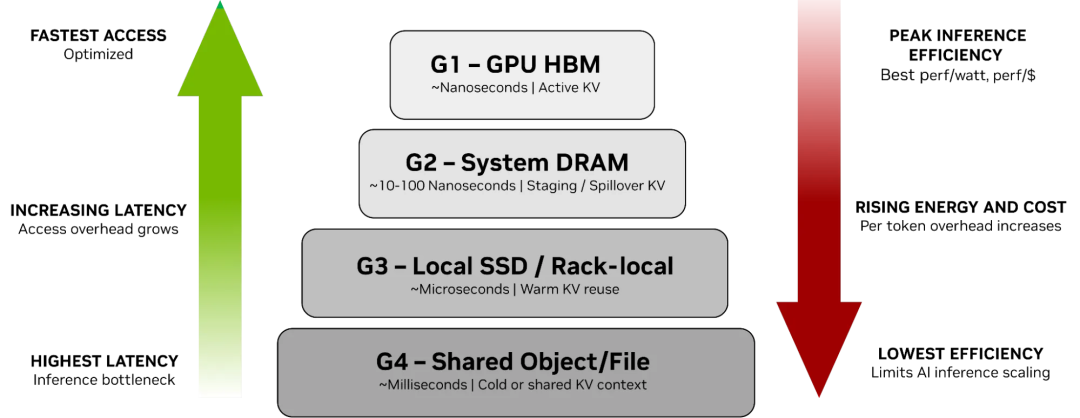
但是,通过GPU Direct Storage直接把存储节点挂载到ScaleOut上不是更好吗?通过GPU直接访问G3/G4不行吗?Nvidia其实自己也在推GPU Direct S3这样的接口,难点在哪?
3.2.1 为什么存储节点无法挂载到ScaleOut网络?
如果需要构建Pod Level的存储池,网络传输延迟相对于SSD自身的延迟是能够满足业务需求的。并且,Pod Level的共享存储池对于MaaS/AI工厂来说,存储的池化共享更具成本优势。甚至某些场景还需要跨数据中心的KVCache传输,以解决一些长尾场景和提高资源碎片利用率。
但是,当前多轨道和多平面的部署,以及RDMA多路径能力的缺陷导致了一个核心难题:存储节点挂载到哪个轨道或者哪个平面上?在基于训练的Infra中,ScaleOut网络作为孤岛存在是可行的,并且伴随着多轨道部署解决了不少通信难题。
但在推理场景中,当需要Pod Level的存储池接入ScaleOut网络时,流量不可避免地会穿越ToR/Leaf/Spine。受成本约束,接入存储的链路必定会存在一定的收敛比。
另一方面是KVCache的传输,会和GPU本身的一些推理相关通信流量产生干扰。而Nvidia(Mellanox)网卡并不支持很好的QoS隔离和优先级调度特性。
3.2.2 为什么存储节点无法以Pod Level形式挂载到FrontEnd网络?
那么,既然在ScaleOut网络上接入有约束,为什么Nvidia不在FrontEnd提供Pod Level存储,而是局限在机柜级呢?同样的问题:当需要Pod Level的存储池接入时,流量不可避免会穿越ToR/Leaf/Spine。在一个带收敛比的网络中,同时又要面对Hash冲突等影响。当前Spectrum-X的自适应路由需要在无损网络环境下开启PFC,这在FrontEnd VPC环境中无法实现。同时,与VPC TCP流量混合运行带来的拥塞控制难度也是巨大的。
退而求其次,在机柜级构建G3/G3.5层是一个迫不得已的妥协。
4. 三网融合其实并不难
抛开商业上的争议和利益冲突,实现三网融合有一定的技术难度,但实际上是能克服的。
4.1 ScaleUP和ScaleOut的融合
其实在两年前推测VR200互连时,就在相关文章中推测过一种方式:将CX系列网卡挂载到NVLink上。
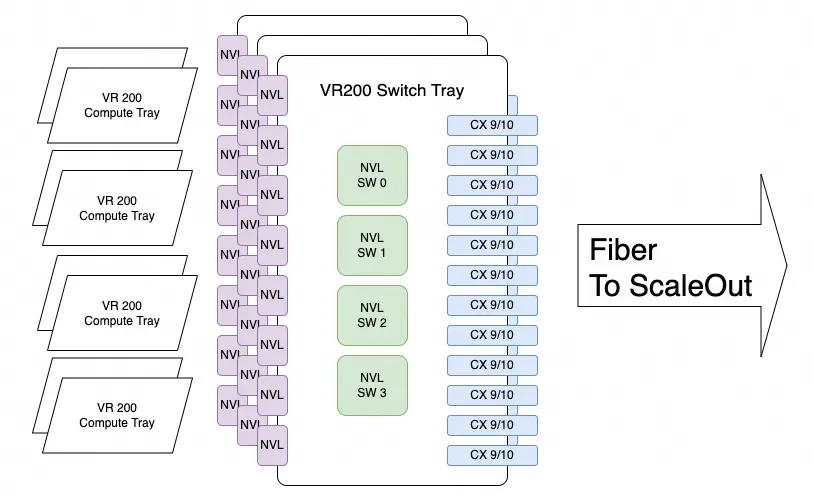
所幸Nvidia最近似乎想清楚了,有传言CX10后面的某个版本会直接通过NVLink连接到GPU。当然,内部还涉及大量安全相关以及通信语义的问题。能做到安全、稳定、性能、成本、弹性这五大条件的,凤毛麟角。Nvidia在这一点上还缺少太多常识性的东西。
4.2 ScaleOut和FrontEnd的融合
至今为止,能在FrontEnd大规模商用RDMA的只有少数几家。基于AWS的SRD还不是一个标准的RDMA Verbs兼容平台,而Google Falcon因为一些算法缺陷,在一些GPU推理实例上还处于未开启状态。至于某些云基于Nvidia DPU构建的RDMA,测试显示吞吐大概只能维持5秒就开始因为丢包和乱序导致降速。因此,能够大规模为所有计算实例开启RDMA能力的DPU事实上屈指可数。
题外话
上周和某公司的一位Fellow聊过,他的评价是:“只有CIPU eRDMA完整实现了UEC的所有要求,并且他们还实际进行了测试,认可其性能。”
其实我对当前整个工业界和学术界感到挺失望的。OpenAI搞了一套MRC协议,Google搞了Falcon,微软、Meta以及隔壁友商都各有一套。几乎所有的这类协议都有这样那样的缺陷。最核心的原因大家想过没有?实质上,当你在基于Nvidia(Mellanox)的硬件上时,就不可能做出来?或者说,即便是Google这样自己和Intel一起做DPU也做不出来?
我们很早就做完了,在2024年7月看到似乎有一两家快做出来了,才布局了一个专利。没想到如今专利都快满18个月公布了,工业界还有各种各样的问题。即便是Nvidia自己,在多平面/多轨道的CX8上也有大量问题没有解决干净。
答案其实很清楚,方法就是DDP+SACK,但怎么实现都在一系列一环套一环的魔鬼般的细节里。只有站出来,用另外一个视角去看才能得到答案。
4.3 三网融合
其实,无论是华为的UB,还是海外一些在CXL上创业的小公司,包括被Nvidia收购的Enfabrica,实质上大家都是在希望 “以GPU为中心重构服务器”,在ScaleUP上扩展内存、存储和IO。
附录

参考资料
[1] AWS re:Invent 2025 - SageMaker HyperPod: Checkpointless & elastic training for AI models (AIM3338): https://www.youtube.com/watch?v=r9J10L2K0F4&list=PL2yQDdvlhXf-UqnINCmXu-dDZJm_B3bbJ&index=6
后记:技术演进的路径往往伴随着深刻的商业逻辑与生态博弈。三网融合作为AI推理基础设施演进的关键一步,其实现不仅依赖于底层技术的突破,更需要行业在开放标准与协作上达成共识。对于持续关注云原生/IaaS与未来计算架构演进的开发者而言,这是一个充满挑战与机遇的领域。更多深入的技术讨论与实践分享,欢迎访问云栈社区。
 发表于 2026-1-27 11:58:02
|
查看: 181|
回复: 0
发表于 2026-1-27 11:58:02
|
查看: 181|
回复: 0
