在高并发网络应用开发中,传统方案面临着双重困境:多线程模型因上下文切换导致性能瓶颈,而回调式异步编程又让代码陷入“回调地狱”的泥潭。C++20引入的原生协程为这一困局提供了优雅的解决方案——它能让我们用同步风格的代码,实现异步的高性能执行。
现代C++特性应用
协程在异步处理中的实现
协程让异步代码如流水般自然,其核心在于三个关键要素:promise_type、coroutine_handle 和 Awaitable 对象。让我们看看如何利用这些现代 C++特性 来简化网络处理。
// Awaitable对象定义协程的挂起与恢复行为
struct SocketAwaiter {
Socket& sock;
bool await_ready() { return false; }
void await_suspend(std::coroutine_handle<> h) {
EventLoop::get().register_fd(sock.fd(), h);
}
auto await_resume() { return sock.get_result(); }
};
// 协程函数:用同步风格写异步逻辑
Task<void> handle_connection(int client_fd) {
char buffer[4096];
while (true) {
auto n = co_await SocketAwaiter{client_fd};
if (n <= 0) break;
co_await process_data(buffer, n);
}
close(client_fd);
}
关键设计要点:
- Task类型:自定义协程返回类型,支持
co_return 传递结果。
- 事件循环驱动:epoll_wait 检测到 IO 就绪时,调用
handle.resume() 恢复协程。这需要协程调度器进行统一管理。
- 异常传播:协程内异常可自然传播,避免回调地狱的错误处理复杂度。
std::span在内存安全与效率提升中的应用
std::span 作为轻量级的非拥有视图,在网络协议解析中展现出独特优势,实现了零拷贝操作。
// 零拷贝协议解析
void parse_http_request(std::span<const char> buffer) {
// 提取请求行
auto header_line = buffer.first(buffer.find('\r\n'));
// 提取头部
auto headers = buffer.subspan(header_line.size() + 2);
// 提取Body
auto body_start = buffer.find(“\r\n\r\n“);
auto body = buffer.subspan(body_start + 4);
}
性能优势:
- 零拷贝:仅持有指针和长度,不进行数据复制。
- 边界安全:可选运行时边界检查,避免缓冲区溢出。
- 接口统一:兼容数组、vector、string 等所有连续容器。
- 子视图操作:
first()、last()、subspan() 实现高效切片。
核心模块设计
事件循环与IO多路复用
我们采用 epoll 作为底层 IO 多路复用机制,配合协程调度器实现高效的事件驱动模型。
class EpollLoop {
int epoll_fd;
std::unordered_map<int, std::coroutine_handle<>> waiters;
public:
void add(int fd, uint32_t events, std::coroutine_handle<> h) {
epoll_event ev{events, {.fd = fd}};
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, fd, &ev);
waiters[fd] = h;
}
void run() {
epoll_event events[64];
int n = epoll_wait(epoll_fd, events, 64, -1);
for (int i = 0; i < n; ++i) {
int fd = events[i].data.fd;
if (waiters.count(fd)) {
waiters[fd].resume();
waiters.erase(fd);
}
}
}
};
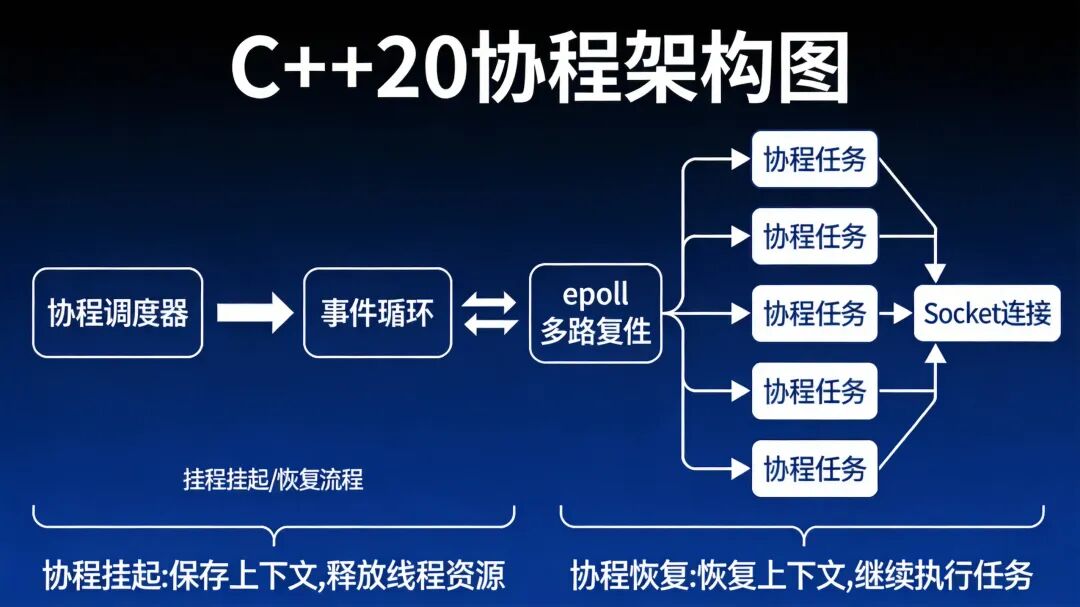
上图展示了协程、事件循环与 epoll多路复用 之间如何协同工作,实现高效的Socket连接管理。
连接管理与状态维护
每个连接对应一个独立的协程,使得其生命周期变得异常清晰和可控。
Task<void> connection_lifecycle(Socket sock) {
co_await sock.connect();
// 主动探测:发送ping包
co_await sock.send(“PING“);
auto pong = co_await sock.recv();
if (pong != “PONG“) co_return; // 连接异常,直接退出
// 心跳循环
while (true) {
co_await sock.wait_for(std::chrono::seconds(30));
co_await sock.send(“HEARTBEAT“);
}
}
内存池与对象生命周期管理
动态内存分配往往是性能瓶颈。为此,我们设计了一个三级架构的内存池来彻底解决这个问题。
class MemoryPool {
// 线程私有缓存:无锁访问
thread_local static std::vector<void*> thread_cache;
// 中心缓存:所有线程共享
std::mutex center_mutex;
std::unordered_map<size_t, std::vector<void*>> center_cache;
// 页堆:向系统申请大块内存
void* allocate_from_system(size_t size);
public:
void* allocate(size_t size) {
if (!thread_cache.empty()) {
auto ptr = thread_cache.back();
thread_cache.pop_back();
return ptr;
}
// 从中心缓存批量获取
return fetch_from_center(size);
}
void deallocate(void* ptr) {
thread_cache.push_back(ptr);
if (thread_cache.size() > 1024) {
return_to_center(ptr);
}
}
};
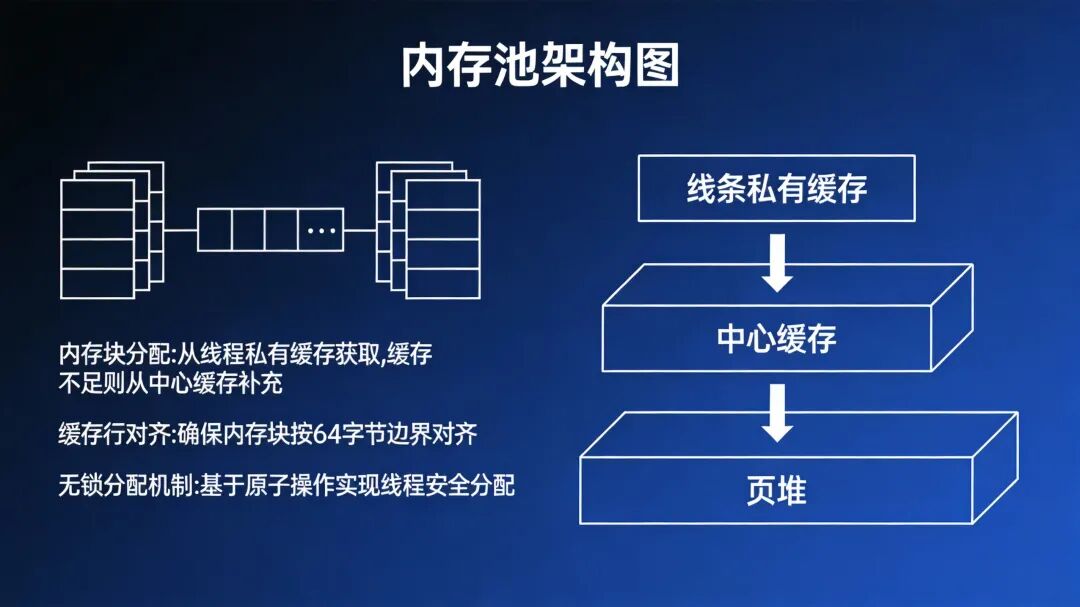
内存池采用“线程私有缓存 -> 中心缓存 -> 页堆”三级结构,配合无锁机制,显著提升了小对象频繁分配的效率。
典型问题与解决方案
问题1:协程生命周期与内存安全
问题描述:协程挂起后,其栈上或所引用的外部对象可能被提前销毁,导致悬垂指针,引发难以调试的内存错误。
解决方案:使用 std::shared_ptr 等智能指针管理协程所依赖的关键对象,确保其在协程运行期间始终保持有效。
Task<void> safe_connection(std::shared_ptr<Connection> conn) {
while (conn->is_active()) {
co_await conn->read();
// conn对象生命周期由shared_ptr保证
}
}
经验教训:在协程内引用外部对象时,必须仔细审视并确保对象生命周期长于协程的执行周期,这是编写健壮协程代码的首要原则。
问题2:信号处理与优雅退出
问题描述:传统的 Ctrl+C (SIGINT) 信号会直接终止进程,导致连接未关闭、资源未释放,无法实现服务的优雅下线。
解决方案:通过 signalfd 将信号转化为文件描述符上的可读事件,从而统一交由 epoll 事件循环处理,实现受控的清理流程。
EpollScheduler sched(SIGINT);
void run() {
while (true) {
epoll_event events[MAX_EVENTS];
int n = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
for (int i = 0; i < n; ++i) {
if (events[i].data.fd == signal_fd) {
// 收到SIGINT,执行优雅退出流程
cleanup_resources();
return;
}
}
}
}
问题3:边缘触发(ET)模式下的数据读取
问题描述:在 epoll 的 ET 模式下,一个 socket 就绪事件只会通知一次。如果未能一次性读取完所有数据,剩余数据将无法触发新事件,导致数据滞留。
解决方案:采用循环读取的方式,直到 read 系统调用返回 EAGAIN 错误码,表示本次内核缓冲区中的数据已全部取完。
Task<void> et_read_loop(int fd) {
char buffer[4096];
while (true) {
ssize_t total = 0;
while (true) {
ssize_t n = read(fd, buffer + total, sizeof(buffer) - total);
if (n < 0) {
if (errno == EAGAIN) break;
throw std::system_error(errno, std::generic_category());
}
total += n;
}
co_await process_data(buffer, total);
co_await wait_readable(fd); // 等待下次可读事件
}
}
性能优化策略
内存管理优化
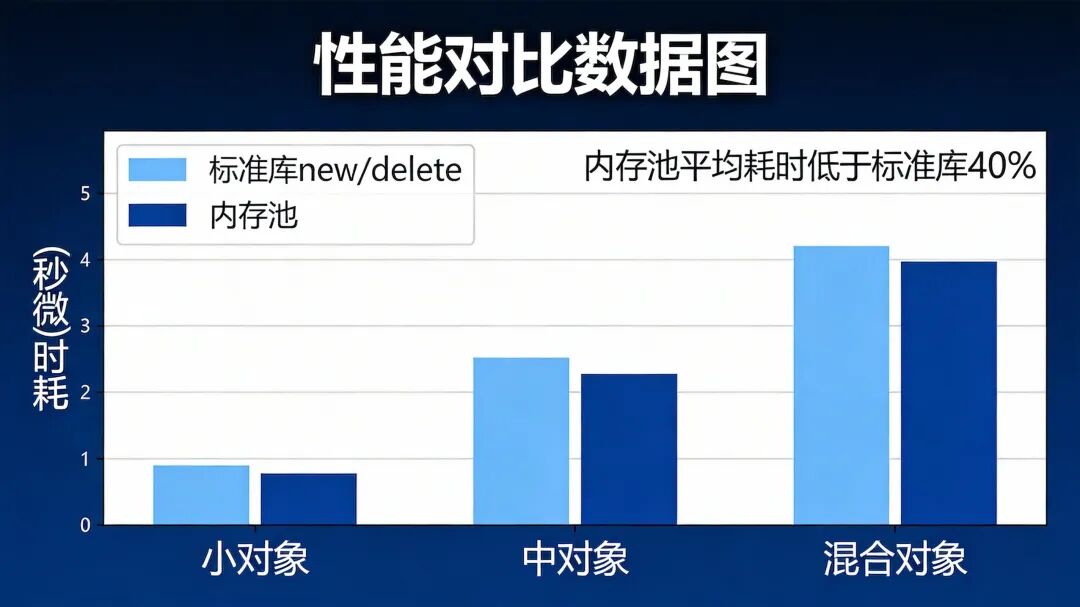
测试数据显示,针对网络库常见的小对象分配场景,自定义内存池相比标准库 new/delete 有显著性能优势。
内存池带来的性能提升非常显著:
- 小对象(32B):性能提升约400%
- 中对象(4KB):性能提升约200%
- 混合对象:性能提升约250%
零拷贝技术的广泛应用也是关键。在网络转发等场景,直接传递数据的视图而非拷贝数据本身。
// 直接使用std::span转发数据,避免复制
Task<void> forward_data(std::span<const char> data) {
co_await socket.send(data); // 零拷贝发送
}
异步IO处理优化
- 批量处理:一次
epoll_wait 批量唤醒多个就绪的协程,减少系统调用开销。
- 优先级调度:为不同业务类型的协程设置优先级,确保关键请求获得快速响应。
- 任务窃取:当某个线程的任务队列为空时,可以从其他忙碌线程的队列尾部“窃取”任务执行,实现更好的负载均衡。
并发控制与线程模型
我们采用“IO线程 + 工作线程池 + 协程”的混合模型来充分利用多核资源。
- IO线程:专门处理所有网络
Socket IO 事件,通过 epoll 驱动协程的挂起与恢复。
- 工作线程:处理解码、业务逻辑等计算密集型任务。
- 任务队列:使用无锁环形缓冲区作为任务队列,极大减少线程间竞争。
ThreadPool pool(4);
EventLoop io_loop;
io_loop.on_new_connection([&](int fd) {
pool.submit([fd]() {
auto coro = handle_connection(fd);
coro.start();
});
});
希望通过这篇从设计到实战的探讨,能为你构建自己的高性能网络组件带来启发。网络编程的世界深邃而有趣,持续探索云栈社区中的相关技术讨论,或许能让你发现更多精妙的解决方案。
 发表于 2026-1-28 04:03:11
|
查看: 139|
回复: 0
发表于 2026-1-28 04:03:11
|
查看: 139|
回复: 0
