“MMU”是内存管理的核心硬件,是CPU能顺畅访问内存的“幕后功臣”,更是理解Linux内核内存机制的关键。很多人觉得MMU晦涩难懂,其实只要抓准“虚拟地址→物理地址”的核心逻辑,再拆解清楚每个组件的作用,就能轻松吃透。
一、MMU是什么?
如果把计算机的物理内存比作“真实的仓库”,CPU比作“取货员”,那MMU就是“仓库管理员+导航员”——既要帮取货员找到货物的真实位置,还要管好仓库的访问权限,防止取错货、乱拿货。
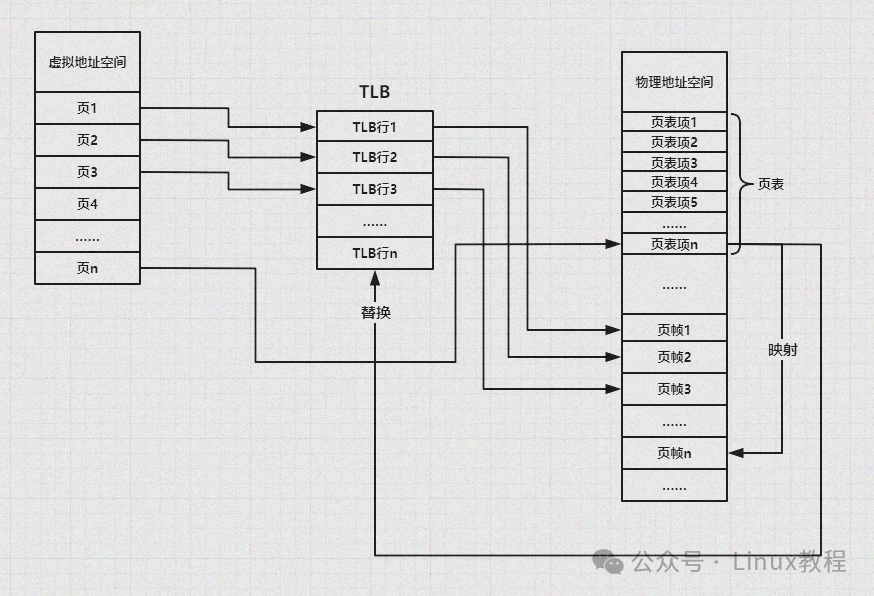
1.1.1 什么是 MMU
MMU,全称Memory Management Unit(内存管理单元),是集成在CPU内部的专用硬件组件,也常被称为分页内存管理单元(PMMU)。它的核心使命很简单:接收CPU发出的内存访问请求,完成“虚拟地址”到“物理地址”的转换,同时管控内存访问权限,确保系统稳定、安全运行。
这里要注意一个关键细节:MMU是硬件组件,不是软件程序——它由逻辑电路构成,能以极高的速度完成地址转换,这也是它能支撑CPU高速运行的核心原因。如果没有MMU,CPU只能直接访问物理内存,不仅会导致进程之间相互干扰,还会让内存利用率极低。

1.1.2 MMU 的核心功能
MMU的功能不止“地址转换”,还有两个隐藏但至关重要的作用,我们逐一拆解,结合实际场景讲明白:
① 核心功能一:虚拟地址→物理地址的映射(最核心)
现代操作系统(包括Linux)都会给每个进程分配“独立的虚拟地址空间”——简单说,每个进程都以为自己独占了整个内存(比如32位进程以为自己有4GB内存),但实际上,物理内存是有限的,多个进程会共享物理内存。
举个具体例子:进程A和进程B都用虚拟地址0x1000访问数据,MMU会将进程A的0x1000映射到物理地址0x80000000,将进程B的0x1000映射到物理地址0x90000000。这样一来,两个进程看似访问同一个地址,实则操作不同的物理内存,互不干扰——这就是MMU映射功能的核心价值,也是进程隔离的基础。
② 核心功能二:内存访问权限管控(保障系统安全)
MMU会给每个内存区域设置“访问权限”,比如“只读”“可读写”“可执行”,就像给仓库的不同区域贴上门禁标签,只有拥有对应权限的进程才能操作。
最典型的场景:Linux内核所在的内存区域,会被MMU设置为“仅内核态可访问”——如果用户态进程(比如我们平时运行的终端、浏览器)试图修改内核内存,MMU会直接拦截,触发“权限异常”,终止该进程。这就避免了恶意程序或错误程序破坏内核,保障了系统的稳定性。
③ 功能三:辅助内存分页管理
MMU会配合Linux内核的分页机制,将虚拟内存和物理内存划分为固定大小的“页”,通过页表记录映射关系,从而减少内存碎片,提高内存利用率——这一点我们后面会详细拆解。
二、前置知识
想要彻底搞懂MMU,需先掌握3个基础概念:虚拟内存、核心术语、TLB。
这三个是理解后续地址转换、缺页异常的前提,缺一不可。
2.2 虚拟内存
很多人疑惑:为什么我的电脑只有8GB物理内存,却能运行需要16GB内存的程序?答案就是虚拟内存——它相当于“物理内存的扩展包”,用硬盘空间模拟内存,帮我们突破物理内存的限制。
2.2.1 什么是虚拟内存
虚拟内存是Linux内核实现的一种内存管理技术,它给每个进程提供了一个“连续、完整、独立”的抽象地址空间(虚拟地址空间)。这个空间不是真实的内存,而是内核通过软件模拟出来的——一部分对应物理内存,另一部分对应硬盘上的“交换空间”(Swap空间)。
简单说:进程访问的所有内存地址,都是“虚拟地址”,不是物理内存的真实地址;只有经过MMU转换,虚拟地址才能对应到物理内存或Swap空间的真实位置。进程无需关心物理内存的实际大小和分布,只需要专注于自己的虚拟地址空间即可。
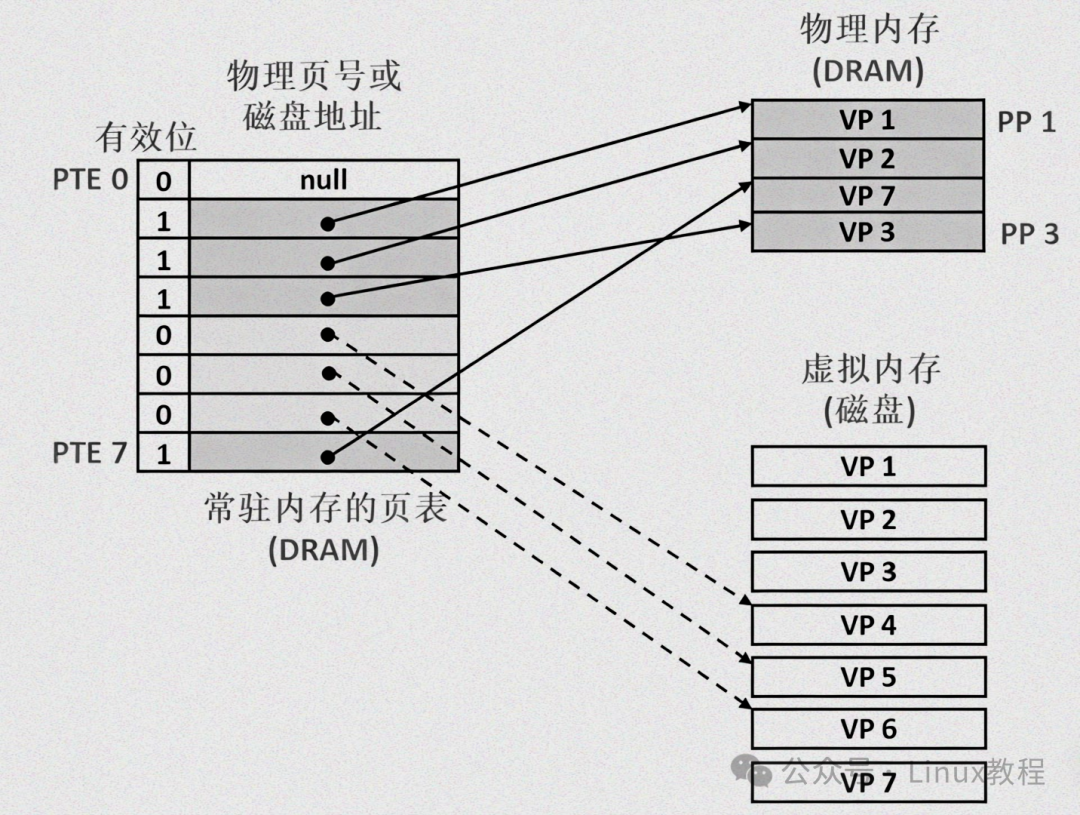
2.2.2 虚拟内存的核心作用
虚拟内存的作用不止“扩展内存”,还有一个更关键的作用是“进程隔离”,我们结合实际场景拆解:
① 突破物理内存限制,让大程序能运行
假设你的电脑有8GB物理内存,要运行一个需要12GB内存的程序——没有虚拟内存的话,程序会直接报错“内存不足”;有了虚拟内存,内核会把程序中暂时不用的数据,从物理内存转移到硬盘的Swap空间,腾出物理内存给当前需要运行的部分;等需要用到那些数据时,再从Swap空间读回物理内存。
这里要补充一个细节:Swap空间的读写速度远低于物理内存(硬盘读写速度≈100MB/s,物理内存读写速度≈10GB/s),所以如果程序频繁在物理内存和Swap之间切换(也就是“换页”),会导致程序运行变慢(比如电脑卡顿)——这就是“内存不足导致卡顿”的核心原因。
② 实现进程隔离,保障系统稳定
每个进程的虚拟地址空间都是独立的,不同进程的虚拟地址互不干扰。比如进程A的虚拟地址0x1000和进程B的虚拟地址0x1000,会被MMU映射到不同的物理地址——即使进程A崩溃(比如内存溢出),也不会影响进程B的运行,更不会破坏内核内存。
举个生活中的例子:虚拟地址空间就像每个租客的“独立房间”,物理内存和Swap空间就是“公寓的公共区域”;租客只需要管好自己的房间,不用关心其他租客的房间,也不会因为自己房间乱,影响其他租客——这就是进程隔离的好处。
2.2.3 虚拟内存与物理内存的关系
虚拟内存和物理内存是“协同工作”的关系,核心是“按需映射、动态切换”,举个“图书馆”的例子:
- 物理内存:相当于图书馆的“书架”,读写速度快,能直接被CPU访问,但空间有限(比如书架只有100个格子);
- 虚拟内存:相当于图书馆的“仓库”(对应硬盘Swap空间),空间大(比如仓库有1000个格子),但读写速度慢;
- 内核(管理员):负责将“热门书籍”(进程当前需要的数据)放在书架(物理内存),将“冷门书籍”(暂时不用的数据)转移到仓库(虚拟内存);当需要“冷门书籍”时,再从仓库取回到书架。
关键规则:
- 程序运行时,内核优先将数据加载到物理内存,只有物理内存不足时,才会使用虚拟内存;
- 虚拟内存和物理内存的“最小单位”都是“页”(Linux中默认4KB),数据的转移都是“按页转移”,不是按字节;
- 虚拟地址空间的大小,由CPU位数决定(32位CPU最大虚拟地址空间是4GB,64位CPU最大虚拟地址空间是16EB),和物理内存大小无关。
2.2.4 CPU 存取内存数据的基本流程
CPU不能直接访问虚拟内存,也不能直接访问硬盘的Swap空间,所有内存访问都要经过“虚拟地址→物理地址”的转换,全程分为4个步骤:
步骤1:CPU生成虚拟地址
当进程执行指令(比如“读取内存地址0x00401234的数据”)时,CPU会生成一个“虚拟地址”——这个地址只是一个“逻辑地址”,不是物理内存的真实地址,相当于一个“快递单号”。
步骤2:虚拟地址发送给MMU
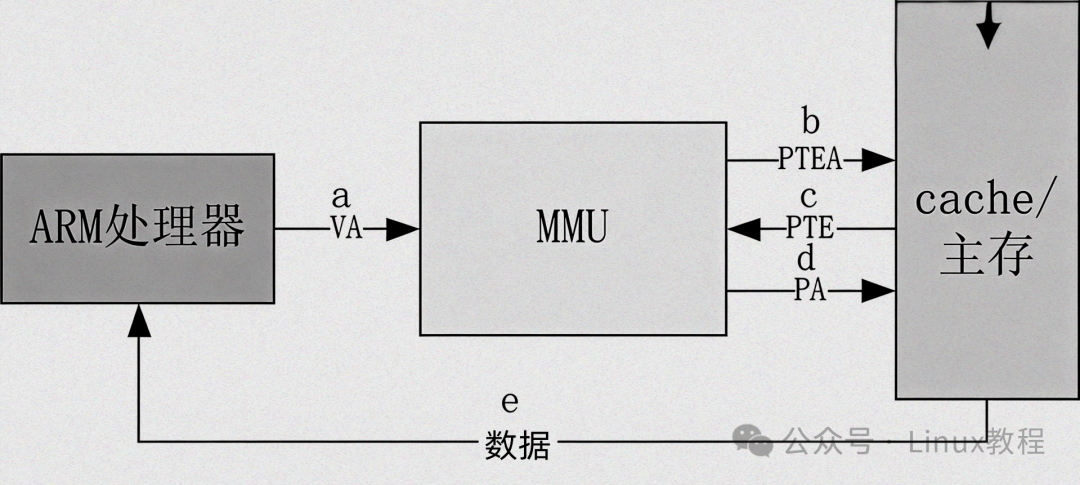
CPU不会直接去访问内存,而是将虚拟地址发送给内部的MMU,让MMU完成“地址转换”——因为CPU不知道虚拟地址对应的物理地址在哪里,只有MMU能通过“页表”找到对应关系。
步骤3:MMU转换虚拟地址为物理地址
MMU会根据“页表”(后面会讲),将虚拟地址拆解为“页号”和“页内偏移”,通过页号查找对应的物理页框号,再结合页内偏移,生成物理地址——相当于根据“快递单号”找到快递的真实存放位置。
步骤4:CPU访问物理内存(或触发缺页异常)
如果MMU转换后,发现对应的物理页在物理内存中,CPU就会根据物理地址,直接访问物理内存,读取或写入数据;
如果对应的物理页不在物理内存中(比如被转移到了Swap空间),MMU会触发“缺页异常”,让内核去处理(后面会详细讲缺页异常的处理流程)。
2.3 核心术语
每次聊MMU,都会涉及很多专业术语,很多人因为术语混淆,越看越懵。这里统一再给大家整理一下:
2.3.1 物理地址相关
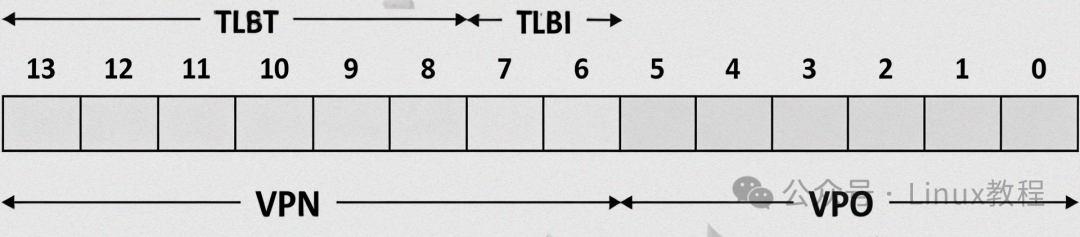
- 物理地址(Physical Address):内存芯片上的真实地址,对应内存的实际存储单元,是硬件(CPU、内存控制器)直接使用的地址,相当于“房子的实际门牌号”。
物理地址的范围由物理内存大小决定,比如8GB物理内存,物理地址范围是0x00000000~0x1FFFFFFF(十六进制);物理地址不能被进程直接访问,只能由MMU转换后使用。
- 物理页框(Physical Page Frame):物理内存被划分成的固定大小的块,简称“页框”,大小和虚拟内存的“页”一致(Linux默认4KB)。每个页框都有一个唯一的“页框号”,用于标识其在物理内存中的位置。
2.3.2 虚拟地址相关
- 虚拟地址(Virtual Address):进程生成的抽象地址,不直接对应物理内存,每个进程都有自己独立的虚拟地址空间,相当于“进程自己给内存编的门牌号”。
32位Linux进程的虚拟地址空间分为两部分:0~3GB是用户态虚拟地址空间(进程可直接访问),3~4GB是内核态虚拟地址空间(只有内核能访问);64位Linux进程的虚拟地址空间更大,分为用户态和内核态两部分,具体划分因架构而异。
- 虚拟页(Virtual Page):虚拟内存被划分成的固定大小的块,简称“页”,大小和物理页框一致(Linux默认4KB)。每个虚拟页都有一个唯一的“页号”,用于在页表中查找对应的物理页框号。
- 页内偏移(Offset):虚拟地址或物理地址中,“页号”之后的部分,用于定位“页”或“页框”内的具体数据位置。
页内偏移的位数由页大小决定,比如4KB($2^{12}$字节)的页,页内偏移是12位,范围是0~4095。
2.3.3 页表相关

- 页表(Page Table):虚拟地址到物理地址的“映射字典”,是内核维护的核心数据结构,用于记录虚拟页和物理页框的对应关系,相当于“快递单号→真实地址”的对照表。
每个进程都有自己独立的页表,因为每个进程的虚拟地址空间是独立的;页表本身存储在物理内存中(内核空间),用户态进程无法直接访问和修改。
- 页表项(Page Table Entry,PTE):页表中的每一条记录,对应一个虚拟页和物理页框的映射关系。每个页表项不仅包含“物理页框号”,还有多个“标志位”(后面会讲),用于控制内存访问权限和状态。
- 多级页表(Multi-level Page Table):Linux内核采用的页表结构(32位用两级,64位用四级),用于减少页表占用的物理内存空间。
单级页表会占用大量物理内存(比如32位系统单级页表需要4MB),多级页表只创建进程实际使用的页表,大幅节省内存。
2.3.4 页命中与缺页的定义
- 页命中(Page Hit):CPU访问内存时,所需数据所在的虚拟页,已经被映射到物理页框,且该物理页框在物理内存中——相当于“在书架上直接找到想要的书”,访问速度极快(通常只需1~2个CPU时钟周期)。
进程频繁访问的内存区域(比如循环变量),会一直保存在物理内存中,大概率会触发页命中。
- 缺页(Page Fault):CPU访问内存时,所需数据所在的虚拟页,要么没有映射到物理页框,要么对应的物理页框不在物理内存中(被转移到Swap空间)——相当于“在书架上找不到想要的书,需要去仓库取”。

缺页不是“错误”,而是正常的内存管理机制;但频繁缺页(比如物理内存不足)会导致大量磁盘I/O操作,拖慢系统速度。
2.4 地址转换核心硬件组件:TLB
我们知道,页表存储在物理内存中,每次地址转换都要访问物理内存中的页表——而物理内存的访问速度比CPU慢很多(CPU时钟周期≈1ns,物理内存访问≈100ns)。如果每次地址转换都要访问页表,会严重拖慢CPU速度,这时候TLB就登场了。

2.4.1 TLB 的核心作用
TLB,全称Translation Lookaside Buffer(地址转换后备缓冲器),是集成在CPU内部的“高速缓存”,专门用于缓存“近期最常访问的页表项”(虚拟页→物理页框的映射关系)。
核心作用就是让MMU在地址转换时,不用每次都去物理内存中查找页表,而是先在TLB中查找——TLB的访问速度和CPU几乎一致(≈1ns),能大幅加速地址转换过程,提升系统性能。
TLB就像是你“常用单词本”——平时查字典(页表)很慢,但把常用的单词(常用页表项)抄在小本子上(TLB),下次查的时候直接看小本子,不用再翻厚厚的字典,节省大量时间。
TLB的容量很小(通常只有几十到几百个页表项),只能缓存少量常用的映射关系;但正因为容量小,访问速度才快——这是“速度与容量”的trade-off(权衡)。
2.4.2 TLB 的工作原理
TLB的工作流程很简单,核心是“先查缓存,再查页表”,分为4个步骤,结合实际例子讲透:
假设:CPU生成虚拟地址0x00401234,页大小4KB,虚拟页号0x00401,页内偏移0x234。
步骤1:CPU提取虚拟页号,发送到TLB
MMU收到虚拟地址后,会先提取出“虚拟页号”(0x00401),然后拿着这个页号去TLB中查找,看是否缓存了该页号对应的物理页框号。
步骤2:TLB命中(理想情况)
如果TLB中已经缓存了“虚拟页号0x00401→物理页框号0x00800”的映射关系,就是“TLB命中”。此时,MMU直接从TLB中获取物理页框号,不用访问物理内存中的页表,然后结合页内偏移0x234,生成物理地址0x00800234——整个过程只需1个CPU时钟周期,速度极快。
步骤3:TLB未命中(常见情况)
如果TLB中没有缓存该虚拟页号的映射关系(比如第一次访问这个虚拟页),就是“TLB未命中”。此时,MMU会去物理内存中查找页表,通过页号找到对应的物理页框号(比如0x00800)。
TLB未命中时,地址转换的速度会变慢(需要访问物理内存中的页表,耗时≈100ns),但这是正常情况——毕竟TLB容量有限,不可能缓存所有页表项。
步骤4:更新TLB,为下次访问加速
MMU从页表中找到物理页框号后,会将“虚拟页号0x00401→物理页框号0x00800”的映射关系,加载到TLB中,以便下次访问该虚拟页时,能直接命中TLB。
如果TLB已满,无法加载新的映射关系,会采用“替换策略”——最常用的是LRU(最近最少使用)算法,将TLB中最久未使用的映射关系替换出去,为新的映射关系腾出空间。
三、分页管理核心机制
MMU的地址转换,依赖于Linux内核的“分页管理机制”——简单说,就是将虚拟内存和物理内存“化整为零”,分成固定大小的页,再通过页表建立映射。为什么要分页?分页的设计逻辑是什么?我们逐一拆解。
3.1 分页机制的核心思想与设计意义
在分页机制出现之前,操作系统采用“连续分配”的内存管理方式——给每个进程分配一块连续的物理内存。这种方式有两个致命问题:
- 内存碎片严重:当进程频繁申请和释放内存时,会产生很多“零散的空闲内存块”(外部碎片)——这些碎片总容量足够,但单个碎片太小,无法满足大进程的内存需求,导致内存浪费;
- 内存利用率低:如果一个进程需要100MB内存,必须找到一块连续的100MB物理内存,即使物理内存总空闲量超过100MB,只要没有连续的块,进程就无法运行。
分页机制的核心思想,就是“解决这两个问题”:
将虚拟内存和物理内存,都划分为固定大小的“页”(Linux默认4KB),进程不再需要连续的物理内存,而是可以将数据分散存储在不同的物理页框中——相当于“把一本书的不同章节,分散放在书架的不同格子里”,不用占用连续的格子。
分页机制的设计意义:
① 减少内存碎片:分页后,物理内存的空闲空间被划分为固定大小的页框,不会产生“外部碎片”,只有“内碎片”(页内未使用的空间,比如一个页4KB,进程只使用1KB,会产生3KB内碎片)——内碎片的影响远小于外部碎片;
② 提高内存利用率:多个进程的页可以交错存储在物理内存中,充分利用每一个页框;即使进程需要的内存很大,只要有足够的空闲页框,就能运行,不用依赖连续的物理内存;
③ 简化地址转换:通过页表记录虚拟页和物理页框的映射,MMU只需通过页号查找页表,就能完成地址转换,逻辑清晰、易于实现。
3.2 Linux 内核的分页模型
Linux内核的分页模型,会根据CPU架构(32位、64位)的不同,采用不同的页表层级——核心原则是“兼顾内存占用和转换效率”:
① 32位Linux系统(比如x86架构):两级页表
虚拟地址(32位)被划分为3部分,总大小4GB:
- 页目录索引(最高10位):用于查找“页目录”(一级页表);
- 页表索引(中间10位):用于查找“页表”(二级页表);
- 页内偏移(最低12位):用于定位页内具体数据(4KB=$2^{12}$字节)。
页目录大小4KB,包含1024个页目录项(PDE),每个PDE指向一个页表;页表大小4KB,包含1024个页表项(PTE),每个PTE指向一个4KB的物理页框;两级页表总共能管理4GB虚拟地址空间(1024×1024×4KB=4GB)。
② 64位Linux系统(比如x86_64、ARM64架构):四级页表
64位虚拟地址空间极大(理论上16EB),但实际Linux只使用其中的48位(不同架构略有差异),被划分为5部分:
- 页全局目录索引(PGD Index,9位):查找页全局目录(一级页表);
- 页上级目录索引(PUD Index,9位):查找页上级目录(二级页表);
- 页中间目录索引(PMD Index,9位):查找页中间目录(三级页表);
- 页表索引(PTE Index,9位):查找页表(四级页表);
- 页内偏移(12位):定位页内具体数据。
四级页表的层级更多,能管理更大的虚拟地址空间;同时,只有进程实际使用的内存区域,才会创建对应的页表层级,大幅节省物理内存(比如进程只使用100MB内存,只需创建少量页表,不用创建完整的四级页表)。
3.3 页表的核心构成与基础规则
页表的核心是“页表项(PTE)”,每个页表项对应一个虚拟页和物理页框的映射关系,除了映射功能,还包含很多关键标志位,用于控制内存访问和状态——这些标志位是MMU工作的关键:
① 页表的核心构成
每个页表都是由多个页表项(PTE)组成,页表的大小由页表项数量和页表项长度决定(比如32位系统,页表项长度4字节,1024个页表项组成一个4KB的页表)。
页表项的核心内容:
- 物理页框号(PFN):占页表项的大部分位数,用于标识虚拟页对应的物理页框在物理内存中的位置;
- 标志位:用于控制内存访问权限和状态,下面重点讲解常用标志位。
② 页表项的关键标志位(Linux实战常用)
- 存在位(Present Bit,P位):最关键的标志位,P=1表示该虚拟页对应的物理页框在物理内存中,CPU可以直接访问;P=0表示该虚拟页对应的物理页框不在物理内存中(可能在Swap空间),访问会触发缺页异常。
- 读写位(Read/Write Bit,R/W位):控制内存访问权限,R/W=1表示该页可读写,R/W=0表示该页只读;如果进程试图写入只读页,MMU会触发权限异常。
- 可执行位(Executable Bit,X位):控制该页是否可执行,X=1表示该页是代码页,可以被CPU执行;X=0表示该页是数据页,不能被执行(防止数据被当作代码执行,引发安全问题)。
- 脏位(Dirty Bit,D位):标识该页是否被修改过,D=1表示该页被修改过(脏页),D=0表示该页未被修改过(干净页);当需要置换页面时,脏页需要写回磁盘,干净页可以直接丢弃,节省I/O时间。
- 访问位(Accessed Bit,A位):标识该页是否被访问过,A=1表示该页近期被访问过,A=0表示该页近期未被访问过;用于页面置换算法(比如LRU),优先置换未被访问过的页面。
③ 页表的基础规则
- 每个进程有独立的页表,由内核维护,用户态进程无法直接修改;
- 页表存储在物理内存的内核空间,MMU访问页表时,需要使用物理地址;
- 页表的层级由CPU架构和Linux内核版本决定,32位通常两级,64位通常四级;
- 只有虚拟页被访问时,内核才会创建对应的页表项,未被访问的虚拟页,不会创建页表项(节省内存)。
四、页表的存储与 MMU 寻址规则
页表是MMU地址转换的核心,它本身存储在哪里?MMU如何快速找到页表?Linux内核如何管理页表基址?这些问题看似简单,却是理解MMU工作原理的关键,接下来我们逐一拆解。
4.1 页表的存储位置
核心结论:页表存储在物理内存的内核空间,不是虚拟内存,也不是硬盘——这是由MMU的工作机制决定的,具体原因有3点:
① 保证访问速度:MMU进行地址转换时,需要频繁访问页表;物理内存的访问速度远快于硬盘,将页表存储在物理内存中,能确保MMU快速读取页表项,提升地址转换效率。
② 保证数据安全:页表是虚拟地址到物理地址的映射核心,一旦被篡改,会导致地址转换错误,甚至破坏系统内存。将页表存储在 kernel 空间,用户态进程无法直接访问和修改,只能通过内核提供的接口操作,保障了页表的安全性。
③ 硬件兼容性要求:MMU是硬件组件,只能直接访问物理内存,无法直接访问虚拟内存或硬盘;如果页表存储在虚拟内存或硬盘中,MMU无法直接读取,无法完成地址转换。
每个进程的页表,由内核的mm_struct结构体管理(mm_struct是进程的内存描述符),其中pgd指针指向进程的顶级页表(比如32位的页目录,64位的页全局目录);
页表占用的物理内存,属于内核内存,会被计入“内核占用内存”,用户态进程无法使用;
当进程终止时,内核会释放该进程的所有页表,回收其占用的物理内存。
4.2 MMU 定位页表的核心:页表基址寄存器
页表存储在物理内存中,MMU如何快速找到页表的起始位置?
答案是“页表基址寄存器(PTBR)”——它是CPU内部的专用寄存器,专门用于存储“当前进程页表的物理基地址”,相当于MMU的“导航仪”。
核心作用:MMU进行地址转换时,首先从页表基址寄存器中读取页表的起始物理地址,然后根据虚拟地址中的页表索引,逐层查找页表,最终找到对应的物理页框号。
硬件架构啰嗦几句(实战常用):
① x86架构:使用CR3寄存器作为页表基址寄存器,存储的是页目录表(32位)或页全局目录(64位)的物理基地址;当进行地址转换时,MMU首先从CR3寄存器中读取页表基地址,再根据虚拟地址的索引,逐层查找。
② ARM/ARM64架构:使用TTBR0_EL1和TTBR1_EL1两个寄存器作为页表基址寄存器:
- TTBR0_EL1:存储用户空间页表的物理基地址,用于转换用户态虚拟地址;
- TTBR1_EL1:存储内核空间页表的物理基地址,用于转换内核态虚拟地址;
这种设计的优势:用户态和内核态的页表分开管理,地址转换时可以快速切换,提升效率。
4.3 Linux 内核对页表基址的管理与配置
Linux内核需要管理所有进程的页表基址,确保进程切换时,MMU能正确找到当前进程的页表——核心流程分为“系统启动初始化”“进程切换更新”“动态优化配置”三个阶段:
① 系统启动阶段:页表基址的初始化
Linux系统启动时,内核会先初始化自身的页表(内核页表),然后将内核页表的物理基地址,写入页表基址寄存器(比如ARM64架构写入TTBR1_EL1)。
在ARM64架构中,内核启动的汇编阶段,会通过“mcr p15,0, pgd, c2, c0, 0”指令(不同版本略有差异),将内核页表的物理基地址写入TTBR1_EL1,完成内核页表基址的初始化;之后,内核再为用户态进程创建页表,并初始化TTBR0_EL1。
② 进程切换时:页表基址的更新
当Linux内核进行进程切换(比如从进程A切换到进程B)时,必须更新页表基址寄存器,否则MMU会继续使用进程A的页表,导致进程B的地址转换错误。
具体流程(实战核心):
- 内核保存当前进程(进程A)的页表基址(从页表基址寄存器中读取,保存到进程A的task_struct结构体中);
- 内核从新进程(进程B)的task_struct结构体中,读取其页表基址(task_struct->mm->pgd);
- 内核将新进程的页表基址,写入页表基址寄存器(比如ARM64写入TTBR0_EL1);
- 完成进程切换,MMU开始使用新进程的页表,进行地址转换。
③ 运行过程中:页表基址的动态优化
Linux内核会根据系统的运行状态(比如内存使用情况、进程访问频率),动态调整页表基址的配置,优化地址转换效率:
- 内存紧张时:内核会合并冗余的页表(比如多个进程共享的内存区域,共用一个页表),同时更新页表基址寄存器,减少页表占用的物理内存;
- 进程访问频繁时:内核会将进程的页表基址,优先缓存到CPU的高速缓存中,减少MMU读取页表基址的时间,提升地址转换速度。
五、虚拟地址到物理地址的完整转换流程
前面我们讲解了虚拟内存、页表、TLB的基础,现在终于到了核心:虚拟地址如何一步步转换成物理地址?
5.1 地址转换的前置准备工作
在进行地址转换之前,内核和硬件必须完成一系列准备工作,否则地址转换无法正常进行——核心准备工作分为“硬件准备”和“页表初始化”两部分:
5.1.1 内存系统的基础运行条件
硬件层面必须满足3个条件,否则内存系统无法正常工作:
- CPU、MMU、内存控制器、物理内存等硬件组件正常工作,通信链路畅通(比如CPU和MMU的内部总线正常,内存控制器和物理内存的连接正常);
- 物理内存被正确初始化:内核启动时,会检测物理内存的大小、布局,设置内存的工作频率、时序等参数,确保物理内存能稳定、高速运行;
- MMU被正确启用:内核启动时,会通过硬件指令(比如x86的CR0寄存器PG位,ARM的SCTLR_EL1寄存器M位)启用MMU——如果MMU未启用,CPU会直接访问物理内存,无法进行虚拟地址转换。
5.1.2 页表的初始化与配置
页表的初始化是地址转换的核心准备工作,分为“内核页表初始化”和“用户进程页表初始化”,我们以32位Linux系统(两级页表)为例:
① 内核页表初始化(系统启动阶段)
- 内核分配4KB物理内存,作为页目录(一级页表),初始化所有页目录项(PDE),将内核占用的虚拟地址区域,映射到对应的物理内存区域(比如内核虚拟地址3~4GB,映射到物理内存0~1GB);
- 内核为每个内核虚拟地址区域,分配对应的页表(二级页表),初始化页表项(PTE),设置标志位(比如内核页的R/W=1、X=1、P=1);
- 内核将页目录的物理基地址,写入页表基址寄存器(CR3),完成内核页表的初始化。
② 用户进程页表初始化(进程创建阶段)
当用户通过fork()函数创建新进程时,内核会为新进程创建并初始化页表:
- 内核分配4KB物理内存,作为新进程的页目录,复制父进程的页目录项(实现“写时复制”,节省内存);
- 根据新进程的内存需求(比如进程申请的堆、栈内存),分配对应的页表,初始化页表项,建立虚拟页到物理页框的映射;
- 设置页表项的标志位(比如用户态页的R/W=1、X=0,内核态页的访问权限限制);
- 将新进程的页目录物理基地址,存储到新进程的mm_struct结构体中,等待进程切换时写入页表基址寄存器。
5.2 单级页表的基础地址转换逻辑
单级页表是最基础的地址转换方式,虽然Linux内核不使用单级页表(32位用两级,64位用四级),但它是理解多级页表的基础:
假设:系统页大小4KB(12位页内偏移),虚拟地址32位,单级页表包含1024×1024=1048576个页表项(每个页表项4字节,占用4MB物理内存)。
转换流程(4步):
步骤1:拆分虚拟地址
CPU生成虚拟地址(比如0x00401234),MMU将其拆分为“页号”和“页内偏移”:
- 页内偏移:虚拟地址低12位(0x234),用于定位页内具体数据;
- 页号:虚拟地址高20位(0x00401),用于在单级页表中查找对应的页表项。
步骤2:查找单级页表
MMU从页表基址寄存器中,读取单级页表的物理基地址(比如0x80000000),然后以“页号0x00401”作为索引,在页表中查找对应的页表项:
页表项的物理地址 = 页表基地址 + 页号 × 页表项长度 = 0x80000000 + 0x00401 × 4 = 0x80001004。
步骤3:获取物理页框号
MMU读取该页表项(0x80001004),从中提取物理页框号(比如0x00800),同时检查页表项的存在位(P位)——如果P=1,说明该物理页框在物理内存中;如果P=0,触发缺页异常。
步骤4:构造物理地址,访问内存
MMU将物理页框号(0x00800)与页内偏移(0x234)组合,生成物理地址:
物理地址 = 物理页框号 × 页大小 + 页内偏移 = 0x00800 × 4096 + 0x234 = 0x00800234。
CPU根据物理地址,访问物理内存,读取或写入数据,完成地址转换。
为什么Linux不用呢?
- 内存占用大:32位系统中,一个进程的单级页表需要4MB物理内存,多进程场景下(比如100个进程),页表会占用400MB物理内存,浪费严重;
- 效率低:单级页表的页表项数量多,MMU查找页表项的时间长,尤其是进程只使用少量内存时,大部分页表项都是空闲的,查找效率极低。
5.3 多级页表的完整转换过程
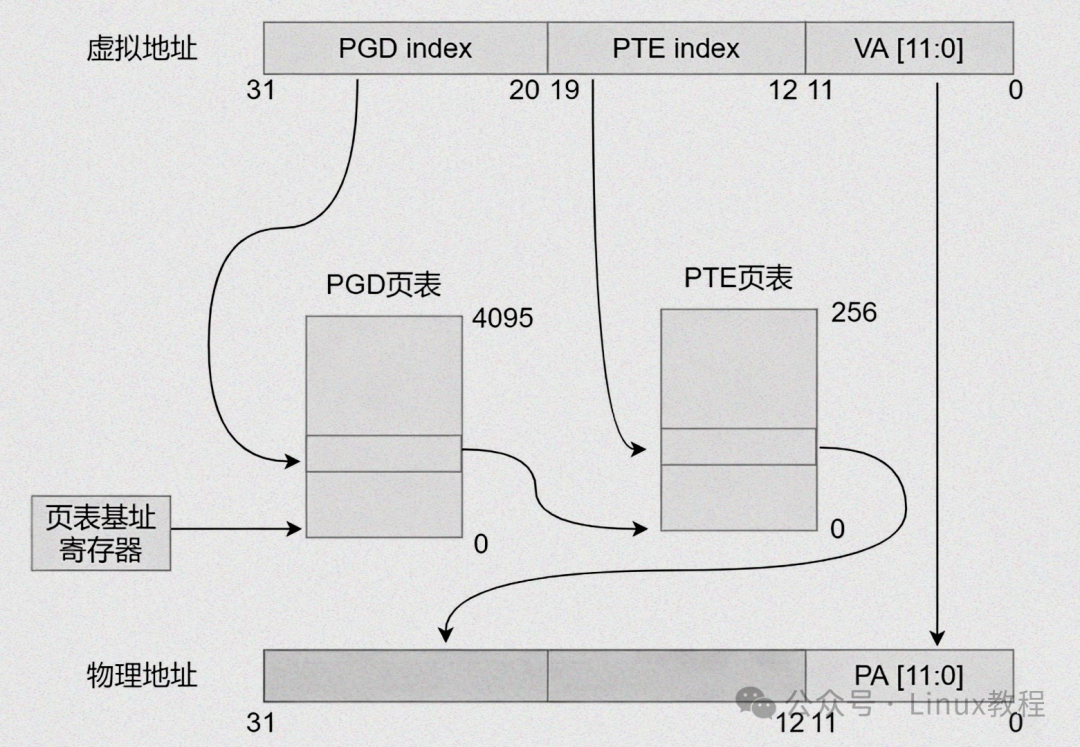
为了解决单级页表的局限性,Linux内核采用多级页表——我们以64位Linux系统(x86_64架构,四级页表)为例。
假设:系统页大小4KB(12位页内偏移),虚拟地址48位(实际使用),四级页表(PGD→PUD→PMD→PTE),虚拟地址0x00007F0000001234。
步骤1:拆分虚拟地址(48位)
将48位虚拟地址拆分为5部分(每部分9位,最后12位为页内偏移):
- PGD索引(第47~39位):0x000(9位),用于查找页全局目录(PGD);
- PUD索引(第38~30位):0x000(9位),用于查找页上级目录(PUD);
- PMD索引(第29~21位):0x07F(9位),用于查找页中间目录(PMD);
- PTE索引(第20~12位):0x000(9位),用于查找页表(PTE);
- 页内偏移(第11~0位):0x1234(12位),用于定位页内具体数据。
步骤2:查找页全局目录(PGD)
- MMU从页表基址寄存器(CR3)中,读取PGD的物理基地址(比如0x800000000000);
- 以PGD索引(0x000)作为索引,查找PGD中的页全局目录项(PGDE):
PGDE物理地址 = PGD基地址 + PGD索引 × 8字节(64位系统页表项长度8字节) = 0x800000000000 + 0x000 × 8 = 0x800000000000;
- 读取PGDE,从中提取PUD的物理基地址(比如0x800000010000),检查存在位(P=1),确认PUD存在。
步骤3:查找页上级目录(PUD)
- 以PUD索引(0x000)作为索引,查找PUD中的页上级目录项(PUDE):
PUDE物理地址 = PUD基地址 + PUD索引 × 8字节 = 0x800000010000 + 0x000 × 8 = 0x800000010000;
- 读取PUDE,从中提取PMD的物理基地址(比如0x800000020000),检查存在位(P=1),确认PMD存在。
步骤4:查找页中间目录(PMD)
- 以PMD索引(0x07F)作为索引,查找PMD中的页中间目录项(PMDE):
PMDE物理地址 = PMD基地址 + PMD索引 × 8字节 = 0x800000020000 + 0x07F × 8 = 0x8000000203F8;
- 读取PMDE,从中提取PTE的物理基地址(比如0x800000030000),检查存在位(P=1),确认PTE存在。
步骤5:查找页表(PTE)
- 以PTE索引(0x000)作为索引,查找PTE中的页表项(PTE):
PTE物理地址 = PTE基地址 + PTE索引 × 8字节 = 0x800000030000 + 0x000 × 8 = 0x800000030000;
- 读取PTE,从中提取物理页框号(比如0x00A00),同时检查存在位(P=1)、访问权限(比如R/W=1、X=0),确认该物理页框可正常访问。
步骤6:构造物理地址,完成访问
MMU将提取到的物理页框号(0x00A00)与页内偏移(0x1234)组合,生成最终的物理地址:
物理地址 = 物理页框号 × 页大小 + 页内偏移 = 0x00A00 × 4096 + 0x1234 = 0x00A01234。
CPU根据这个物理地址,直接访问物理内存,读取或写入对应数据,至此,64位四级页表的地址转换流程全部完成。
多级页表的“逐级查找”看似繁琐,但每一级都只需要查找9位索引(x86_64架构),对应512个目录项,查找效率远高于单级页表;只有进程实际使用的内存区域,才会创建完整的PGD→PUD→PMD→PTE层级,未使用的虚拟地址区域,不会创建对应的目录项和页表,大幅节省物理内存;
5.4 TLB加速下的地址转换全流程
前面我们分别讲了多级页表转换和TLB的工作原理,实际Linux系统中,MMU会结合TLB加速地址转换,形成“TLB优先、页表兜底”的完整流程。
假设:64位Linux系统(x86_64架构),页大小4KB,四级页表,TLB缓存容量64个页表项,采用LRU替换策略,CPU生成虚拟地址0x00007F0000001234(与5.3节示例一致)。
完整流程(6步,含TLB命中/未命中处理):
步骤1:CPU生成虚拟地址,触发内存访问请求
进程执行指令(比如“读取内存地址0x00007F0000001234的数据”),CPU根据指令生成对应的虚拟地址,同时将该虚拟地址发送给内部的MMU,触发内存访问请求。
CPU生成的虚拟地址,属于用户态虚拟地址(0x00007F开头),MMU会自动选择TTBR0_EL1(x86_64对应CR3)中的页表基地址,进行后续转换。
步骤2:MMU提取虚拟页号,查询TLB缓存
MMU收到虚拟地址后,首先拆分出“虚拟页号”和“页内偏移”:虚拟页号为0x00007F0000001(48位虚拟地址去掉低12位页内偏移),页内偏移为0x1234。
随后,MMU将虚拟页号发送给TLB,查询TLB中是否缓存了该虚拟页号对应的物理页框号映射关系——这一步是TLB加速的核心,耗时仅1ns左右。
步骤3:TLB命中(理想场景,占比90%以上)
如果TLB中已经缓存了“虚拟页号0x00007F0000001→物理页框号0x00A00”的映射关系(比如该虚拟页近期被访问过),则属于TLB命中。
此时,MMU直接从TLB中提取物理页框号,无需访问物理内存中的四级页表,直接进入步骤6,构造物理地址并访问内存——整个过程仅需2~3个CPU时钟周期,速度极快。
TLB命中时,MMU会同时检查TLB中缓存的访问权限(与页表项中的R/W、X位一致),如果权限不匹配(比如进程试图写入只读页),会直接触发权限异常,终止内存访问。
步骤4:TLB未命中(正常场景,占比低于10%)
如果TLB中没有缓存该虚拟页号的映射关系(比如第一次访问该虚拟页,或该映射关系被LRU策略替换出TLB),则属于TLB未命中。
此时,MMU会启动“页表兜底”机制,按照5.3节讲解的四级页表转换流程,逐级查找PGD→PUD→PMD→PTE,最终找到对应的物理页框号(0x00A00)——这一步需要访问4次物理内存,耗时约400ns(每次物理内存访问约100ns)。
TLB未命中不会影响进程运行,只是地址转换速度变慢;如果频繁出现TLB未命中(比如进程频繁访问大量不同的虚拟页),会导致系统性能下降,这种情况称为“TLB抖动”,Linux内核会通过优化页大小(比如使用大页)来缓解。
步骤5:更新TLB缓存,为下次访问加速
MMU从页表中找到物理页框号后,会将“虚拟页号0x00007F0000001→物理页框号0x00A00”的映射关系,加载到TLB中,同时缓存对应的访问权限标志位。
如果TLB已满(比如64个缓存项全部用完),MMU会采用LRU(最近最少使用)算法,将TLB中最久未被访问的映射关系替换出去,为新的映射关系腾出空间——这一步由MMU硬件自动完成,无需内核干预。
步骤6:构造物理地址,访问物理内存并返回结果
MMU将物理页框号(0x00A00)与页内偏移(0x1234)组合,生成物理地址0x00A01234,然后将该物理地址发送给内存控制器。
内存控制器根据物理地址,访问对应的物理内存单元,读取数据后,通过总线返回给CPU;CPU收到数据后,继续执行后续指令,完成一次完整的内存访问。
TLB的核心价值在于“缓存常用映射关系”,将地址转换的平均耗时从几百ns降低到几ns,大幅提升系统性能;而多级页表的价值是“节省物理内存”,两者结合,既保证了效率,又控制了内存占用,这也是Linux内核内存管理的核心设计思路。
六、缺页异常处理
在地址转换过程中,我们经常会遇到“缺页异常”——它不是系统错误,而是Linux内核和MMU协同工作的正常机制,相当于“内存访问时的小插曲”。很多人误以为缺页异常是故障,其实只要搞懂它的触发场景和处理流程,就能明白它的核心作用。
6.1 缺页异常的场景
缺页异常的核心触发条件是:MMU在地址转换时,发现虚拟页对应的物理页框不在物理内存中(页表项P位=0),此时MMU会触发硬件中断,通知内核处理——这种中断就是“缺页异常”(Page Fault Exception)。
常见的触发场景有3种:
① 场景1:进程首次访问虚拟页(最常见)
当进程创建后,内核会为其分配虚拟地址空间,但不会立即将所有虚拟页映射到物理页框,也不会立即分配物理内存——只有当进程首次访问某个虚拟页时,MMU查找页表发现该页表项P位=0(未映射物理页框),会触发缺页异常,内核再为其分配物理页框并建立映射。
比如:我们用C语言编写一个简单程序,申请100MB内存(malloc(100*1024*1024)),此时内核只会为进程分配虚拟地址空间,不会分配物理内存;当程序首次写入数据(比如*ptr = 1)时,会触发缺页异常,内核才会分配物理页框,完成映射。
② 场景2:物理内存不足,页面被置换到Swap空间
当系统物理内存不足时,Linux内核会启动“页面置换算法”(比如LRU),将物理内存中“近期最少使用”的物理页框,写入硬盘的Swap空间,回收物理内存,用于满足当前进程的内存需求。
此时,被置换到Swap空间的物理页框,其对应的页表项P位会被置为0;当进程再次访问该虚拟页时,MMU发现P位=0,会触发缺页异常,内核再将该页从Swap空间读回物理内存。
比如:电脑同时运行多个大型程序(比如浏览器、IDE、虚拟机),物理内存占用率达到95%以上,此时内核会将部分程序的后台数据页置换到Swap空间;当切换回该程序时,会出现短暂卡顿,就是因为触发了缺页异常,内核正在将Swap空间的数据读回物理内存。
③ 场景3:虚拟页未被映射(非法访问前兆)
如果进程访问的虚拟地址,没有对应的页表项(比如访问未申请的虚拟内存,或野指针访问),MMU会触发“无效缺页异常”——这种情况属于非法访问,内核会终止该进程(比如Linux中的Segmentation Fault,段错误)。
缺页异常分为“可恢复缺页”和“不可恢复缺页”:场景1、2属于可恢复缺页,内核处理后,进程可继续运行;场景3属于不可恢复缺页,内核会终止进程,避免破坏系统。
6.2 Linux内核缺页异常的处理流程
当MMU触发缺页异常后,CPU会暂停当前进程的执行,切换到内核态,执行缺页异常处理程序(do_page_fault(),Linux内核核心函数)。整个处理流程分为6步:
步骤1:保存现场,判断异常类型
- 内核首先保存当前进程的上下文(比如CPU寄存器值、程序计数器PC),确保异常处理完成后,进程能恢复正常执行;
- 内核读取MMU发送的异常信息(比如触发异常的虚拟地址、异常原因),判断缺页异常的类型:是“可恢复缺页”(场景1、2),还是“不可恢复缺页”(场景3)。
内核通过检查“虚拟地址是否在进程的虚拟地址空间内”,判断异常类型——如果虚拟地址不在进程的虚拟地址空间内,属于不可恢复缺页,直接终止进程;如果在,则属于可恢复缺页,进入后续处理。
步骤2:查找页表,确认缺页原因
内核通过触发异常的虚拟地址,查找该进程的页表(从页表基址寄存器读取页表基地址,逐级查找PGD→PUD→PMD→PTE),确认缺页原因:
- 原因1:虚拟页已映射,但物理页框被置换到Swap空间(页表项P=0,且存在Swap空间地址);
- 原因2:虚拟页未映射物理页框(页表项不存在,或页表项P=0,且无Swap空间地址)。
步骤3:分配物理页框(按需分配)
如果是原因2(虚拟页未映射),内核会从物理内存的空闲页框链表中,分配一个空闲的物理页框(大小4KB),并标记该页框为“已使用”;
如果是原因1(物理页框被置换到Swap),内核会先分配一个空闲物理页框,用于存放从Swap空间读回的数据。
Linux内核通过“伙伴系统”管理空闲物理页框,分配时优先分配连续的页框;如果物理内存没有空闲页框,内核会再次触发页面置换,回收更多物理内存,再进行分配。
步骤4:数据加载(从Swap空间或磁盘加载)
- 若为原因2(未映射):如果该虚拟页对应的数据是程序代码或初始化数据(比如程序的.text段、.data段),内核会从磁盘的可执行文件中,将对应的数据加载到分配的物理页框中;如果是未初始化的数据(比如堆内存),内核会将该物理页框初始化为0,确保数据安全。
- 若为原因1(Swap置换):内核会从硬盘的Swap空间中,将该虚拟页对应的数据流,读回分配的物理页框中——这一步是缺页处理中最耗时的环节(磁盘I/O速度慢),也是导致系统卡顿的主要原因。
步骤5:更新页表,标记页表项状态
数据加载完成后,内核会更新该虚拟页对应的页表项(PTE):
- 将分配的物理页框号,写入页表项的“物理页框号(PFN)”字段;
- 将页表项的存在位(P位)置为1,表示该虚拟页已映射到物理内存;
- 设置页表项的访问权限标志位(R/W、X位),以及访问位(A位=1)、脏位(D位=0,若从磁盘加载,未被修改);
- 如果是从Swap空间读回的数据,内核会删除该虚拟页在Swap空间的映射记录,释放Swap空间。
步骤6:恢复现场,继续执行进程
内核恢复之前保存的进程上下文(寄存器值、程序计数器),切换回用户态,让进程继续执行——此时,进程再次访问该虚拟地址时,MMU会找到对应的页表项(P=1),顺利完成地址转换,访问物理内存。
缺页异常的处理流程,核心是“按需分配物理内存、动态加载数据”,既节省了物理内存(不用一次性分配所有虚拟页对应的物理内存),又实现了虚拟内存的扩展,是Linux内核内存管理的核心机制之一。
6.3 缺页处理后的地址重转换
很多人会有疑问:缺页异常处理完成后,进程之前的内存访问请求,还需要重新进行地址转换吗?
答案是:需要,但会优先命中TLB,无需再次走完整的页表查找流程。
具体流程:
- 缺页异常处理完成后,内核更新了页表项,同时会将“虚拟页号→物理页框号”的映射关系,加载到TLB中(相当于提前缓存,避免下次再触发缺页异常);
- 进程恢复执行后,会重新发起之前的内存访问请求,CPU再次生成对应的虚拟地址,发送给MMU;
- MMU提取虚拟页号,查询TLB——此时TLB中已缓存该映射关系,TLB命中,直接提取物理页框号,构造物理地址,访问物理内存;
- 整个重转换过程,无需再次查找四级页表,速度极快,不会对进程执行效率造成明显影响。
如果缺页处理完成后,该映射关系被TLB替换出去,再次访问时会触发TLB未命中,但不会再次触发缺页异常(因为页表项已更新,P=1),MMU会走页表查找流程,之后再更新TLB。
总结
看到这里,相信你已经吃透了Linux内核MMU的工作原理——其实核心逻辑很简单:MMU作为CPU的“内存导航员”,通过页表完成“虚拟地址→物理地址”的转换,借助TLB加速转换效率,通过缺页异常实现虚拟内存的动态扩展,而这一切,都是为了“高效利用物理内存、保障系统稳定安全”。
回顾一下核心重点:
- 核心组件:MMU(硬件,负责地址转换+权限管控)、页表(内核维护的映射字典,分多级,节省内存)、TLB(CPU高速缓存,加速地址转换)、虚拟内存(软件模拟,突破物理内存限制);
- 核心流程:虚拟地址生成→TLB查询→(命中则直接转换,未命中则走多级页表查找)→生成物理地址→访问内存;若页表项P=0,触发缺页异常,内核处理后重转换;
- 实战:多级页表解决单级页表内存占用大的问题,TLB解决页表查找效率低的问题,缺页异常解决物理内存不足的问题,三者协同,构成Linux内核内存管理的核心;
- 易错点:缺页异常不是错误,是正常机制;MMU是硬件,页表存储在物理内存内核空间;TLB容量小,依赖LRU策略替换。
希望这篇深度解析能帮助你彻底理解Linux内存管理的基石。如果你对内核其他机制感兴趣,欢迎在云栈社区与我们继续交流探讨。
 发表于 2026-3-17 03:54:03
|
查看: 245|
回复: 0
发表于 2026-3-17 03:54:03
|
查看: 245|
回复: 0
