动态链接库(Dynamic Link Library,DLL)或者说共享库(Shared Library),是现代操作系统和应用软件的重要组成部分。它允许多个程序共享同一份代码,有效节约了内存和磁盘空间。但你是否想过,它是如何做到“共享”的同时,又能让每个程序正确调用属于自己的函数和变量的?今天,我们就来深入探讨其背后的实现原理。
从静态链接说起:符号解析与重定位
理解动态链接,不妨先从更基础的静态链接过程入手。
假设有这样两段代码:
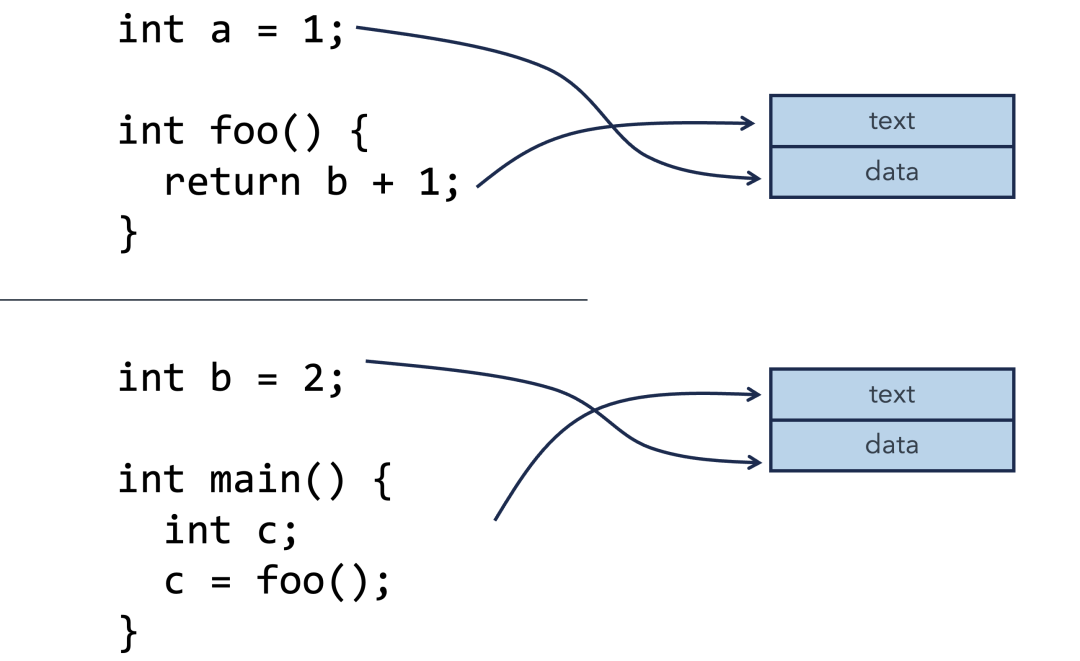
第一段代码定义了一个全局变量 a 以及函数 foo,但函数 foo 中引用了一个尚未在本模块定义的全局变量 b。

第二段代码定义了那个缺失的全局变量 b 以及 main 函数,并在 main 函数中调用了第一段代码定义的函数 foo。
编译器会将这两个源文件编译成对应的目标文件(.o文件)。每个目标文件主要包含两部分:代码段(text,存放编译后的二进制指令)和数据段(data,存放已初始化的全局变量等)。每个模块引用或定义的函数、变量信息,会记录在各自的符号表中。
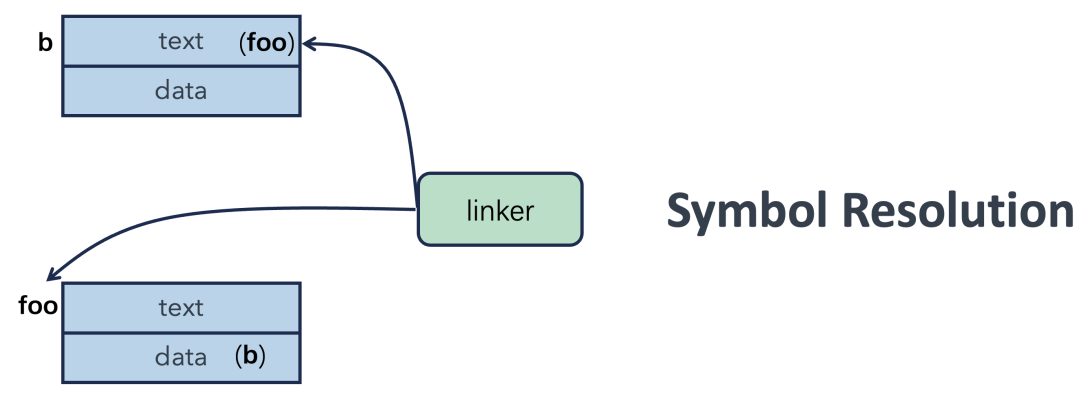
接下来,链接器(Linker)登场,它开始玩一个“连连看”游戏。第一个模块的符号表记录着“我需要变量b”,第二个模块的符号表记录着“我定义了变量b”——匹配成功!同样,第二个模块“需要函数foo”,也能在第一个模块找到定义。这个过程就是符号解析(Symbol Resolution)。
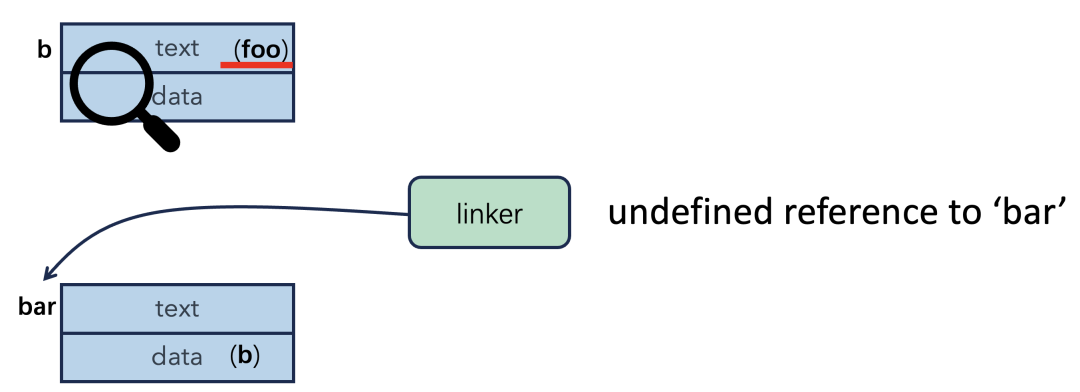
如果某个需要的符号(比如 bar)在所有模块中都找不到定义,链接器就会报出经典的“undefined reference to bar”错误,这对C/C++开发者来说再熟悉不过。
符号解析成功后,链接器会将所有模块的数据段合并、代码段合并,并为每个符号(函数和变量)分配最终的内存地址。接着,它需要修改代码段中那些引用外部符号的指令(比如 call 指令后的地址),让它们指向正确的地址。这个过程称为重定位(Relocation)。
至此,一个完整的可执行文件就诞生了。但这只是静态链接,所有代码和数据在程序启动前就已“焊接”在一起。
动态链接的核心挑战:共享与独立的矛盾
动态库(如 Linux 下的 .so 或 Windows 下的 .dll)的目标是代码共享,数据独立。这带来了两个核心矛盾:
-
数据独立性问题:如果两个进程(程序1和程序2)共享同一个动态库的数据段,那么程序1将库中的全局变量 a 改为10,程序2将其改为20后,程序1再读取 a,得到的将是20,这显然不符合预期。
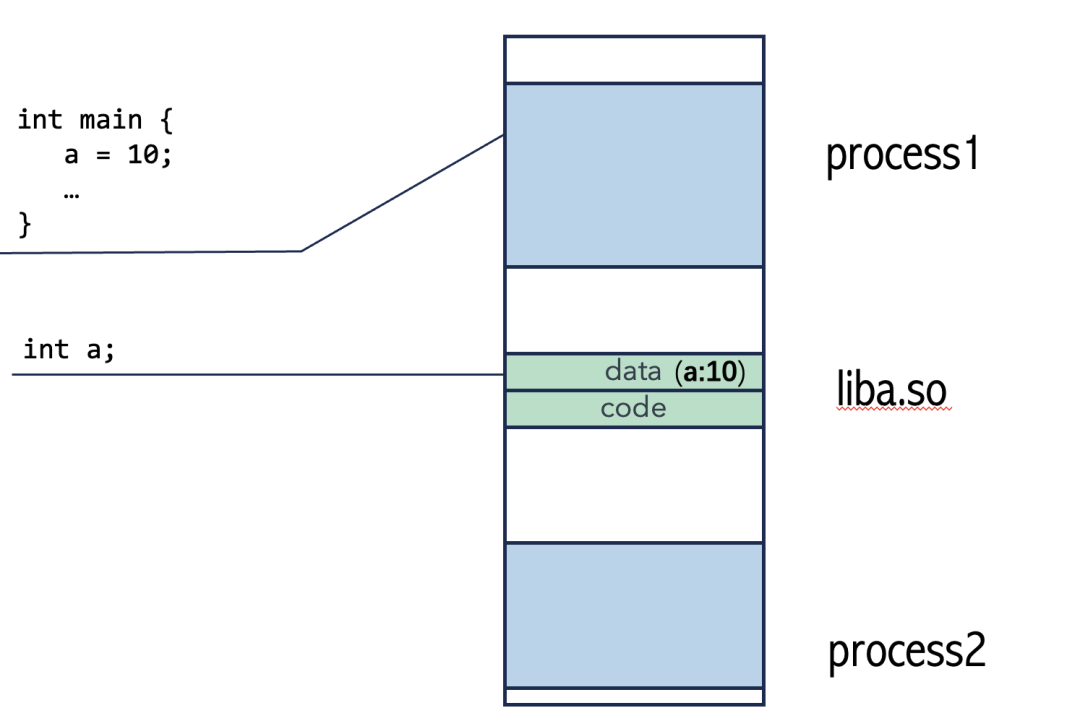
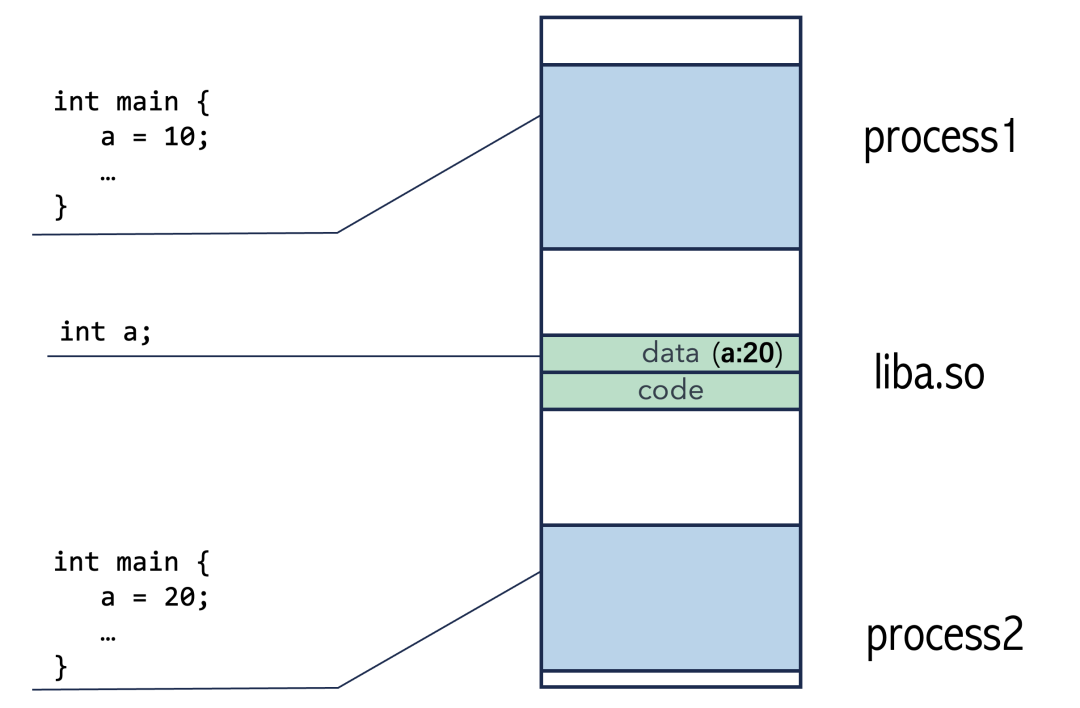
因此,动态库的数据段必须是每个进程私有的副本,不能共享。
-
代码地址不确定性问题:假设动态库中的代码要调用一个外部函数 foo。在静态链接中,foo 的地址在链接时就能确定并直接写死在 call 指令里。但在动态链接中,foo 函数可能定义在主程序或其他库中,其加载地址在每次程序运行时都可能不同。
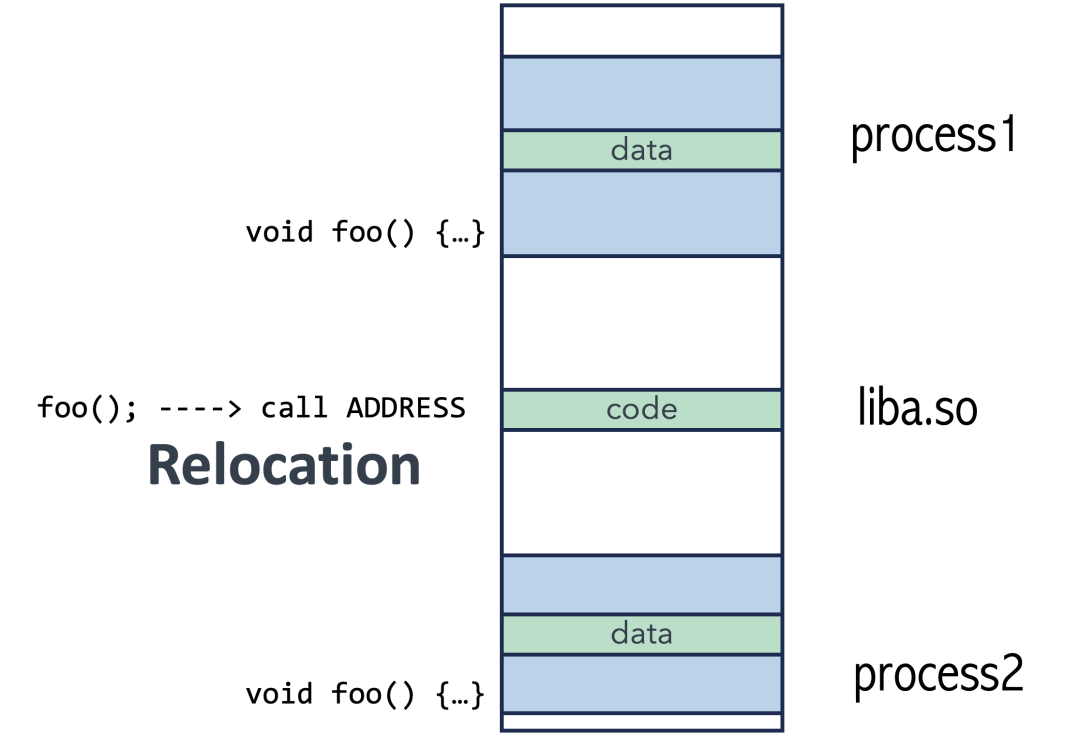
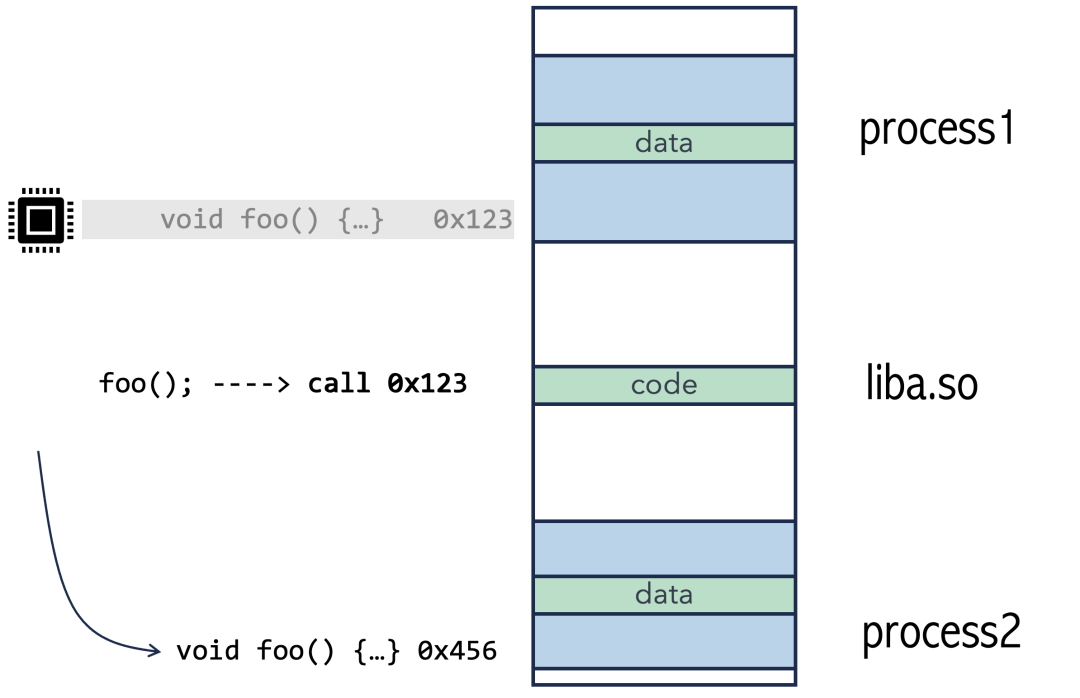
如果库里的 call 指令硬编码了程序1中 foo 的地址(0x123),那么当程序2加载同一份库代码时,执行 call 指令仍然会跳转到0x123,这很可能不是程序2中 foo 的位置(0x456),导致错误。
解决方案:间接引用与全局偏移表(GOT)
计算机领域有句名言:“所有问题都可以通过增加一个中间层来解决。” 动态链接库的地址问题正是如此。我们放弃直接引用(call 绝对地址),改为间接引用。
这个关键的中间层就是全局偏移表(Global Offset Table, GOT)。GOT 是动态库数据段(即私有数据区)中的一张表,专门用来存储需要动态确定的地址,比如外部函数的地址和外部全局变量的地址。
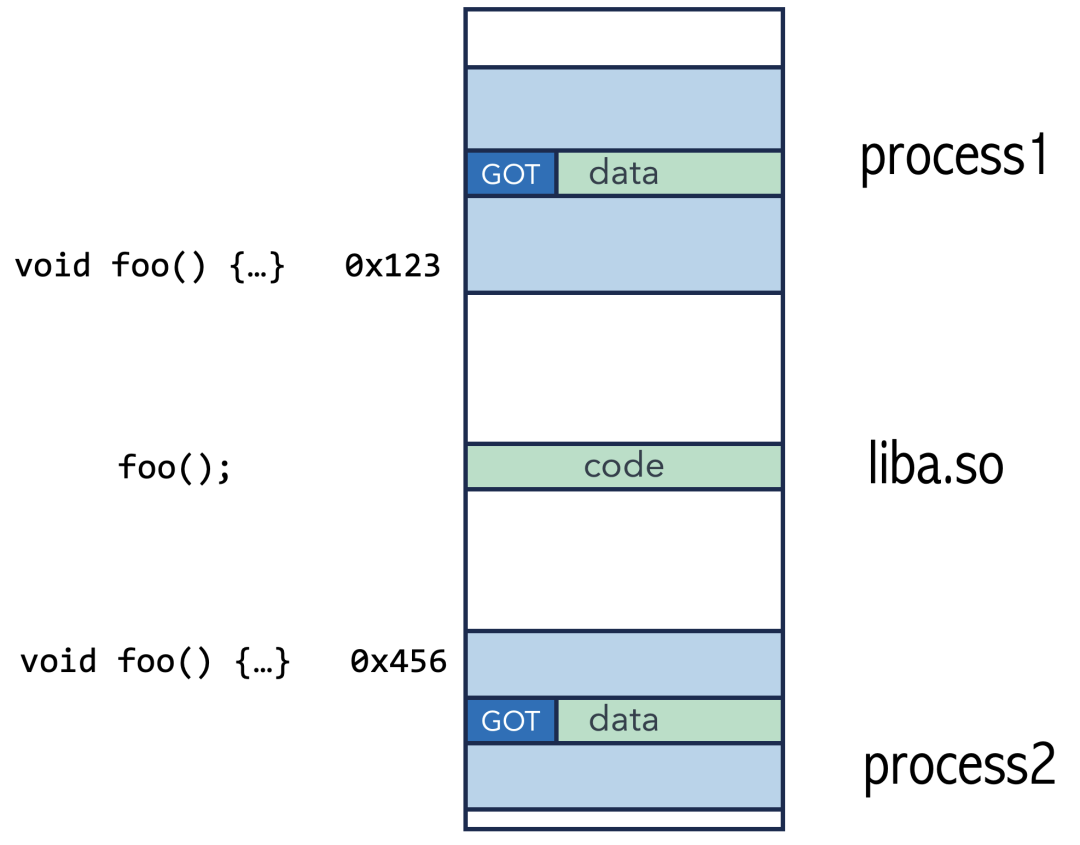
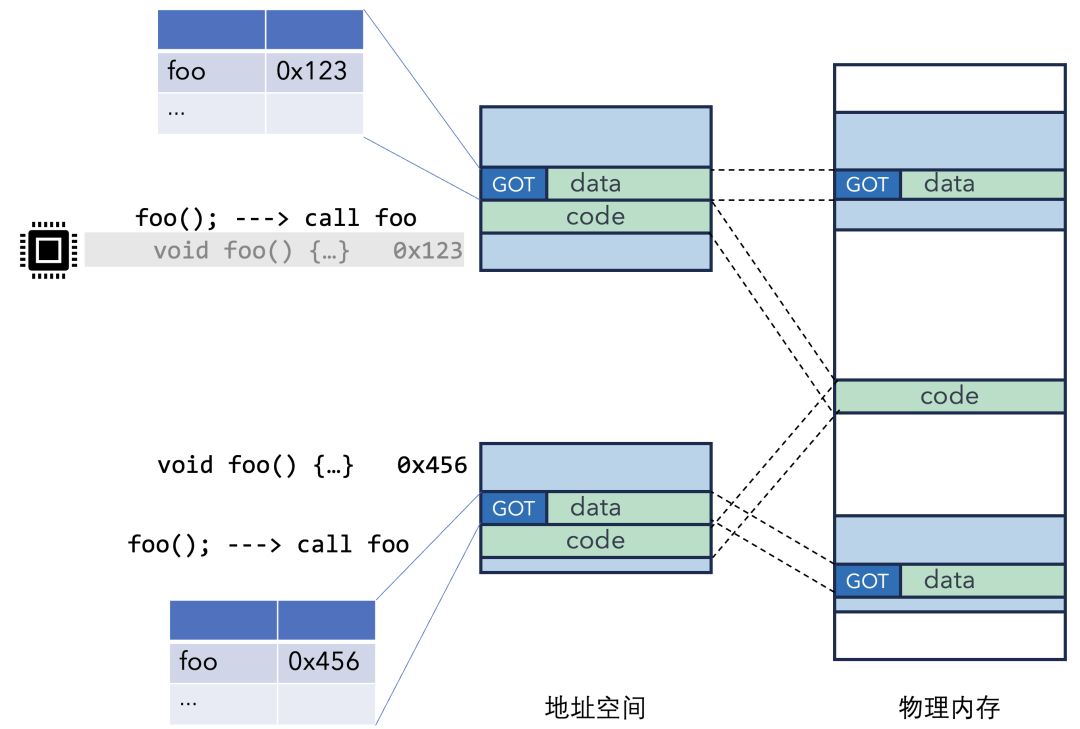
现在,调用流程变成了这样:
- 动态库中的
call 指令不再直接跳转到 foo,而是跳转到一小段固定的、与位置无关的“桩代码”。
- 这段“桩代码”会去查询本进程数据段中的 GOT 表。
- 在程序加载时,动态链接器(
ld.so 或 ld-linux.so)已经将 foo 函数在当前进程中的真实地址填写到了 GOT 表的对应项中。
- “桩代码”从 GOT 表中拿到真实地址,再跳转过去执行。
这样,无论 foo 在进程1中是0x123,还是在进程2中是0x456,GOT 表里存的就是正确的地址。共享的库代码(call 指令和“桩代码”)通过查询各自进程私有的 GOT 表,实现了跳转到正确地址的目的。
关键支撑:位置无关代码(PIC)
上面的方案依赖于一个前提:动态库的代码必须能够被加载到内存的任意地址并正确运行。这就是位置无关代码(Position-Independent Code, PIC)。
PIC 的核心在于,代码中不包含任何绝对内存地址。所有对数据和函数地址的引用都是相对于当前指令指针(PC)的偏移量。编译器通过 -fPIC 选项来生成 PIC 代码。
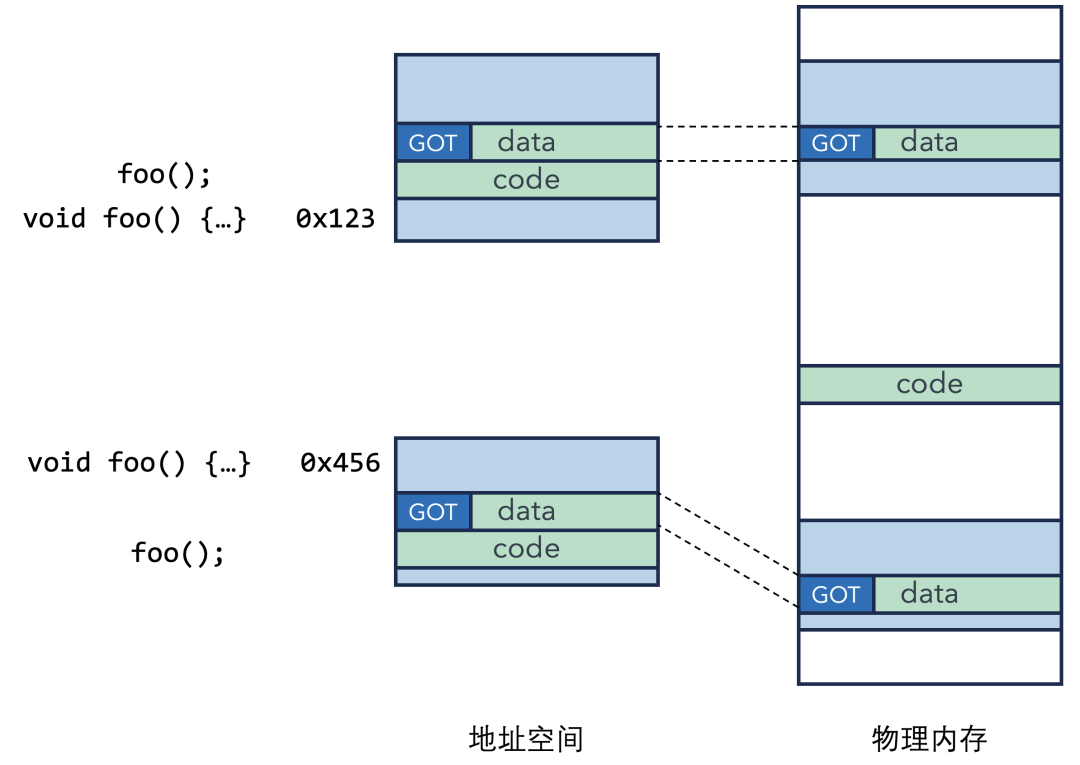
由于代码段和数据段(包含GOT)在内存中的相对位置是固定的(由链接器在创建动态库时决定),因此代码可以通过一个固定的偏移量找到属于自己进程的 GOT。无论动态库被加载到哪个基地址(Base Address),call 指令通过相对跳转总能找到 GOT,进而通过 GOT 找到最终目标。
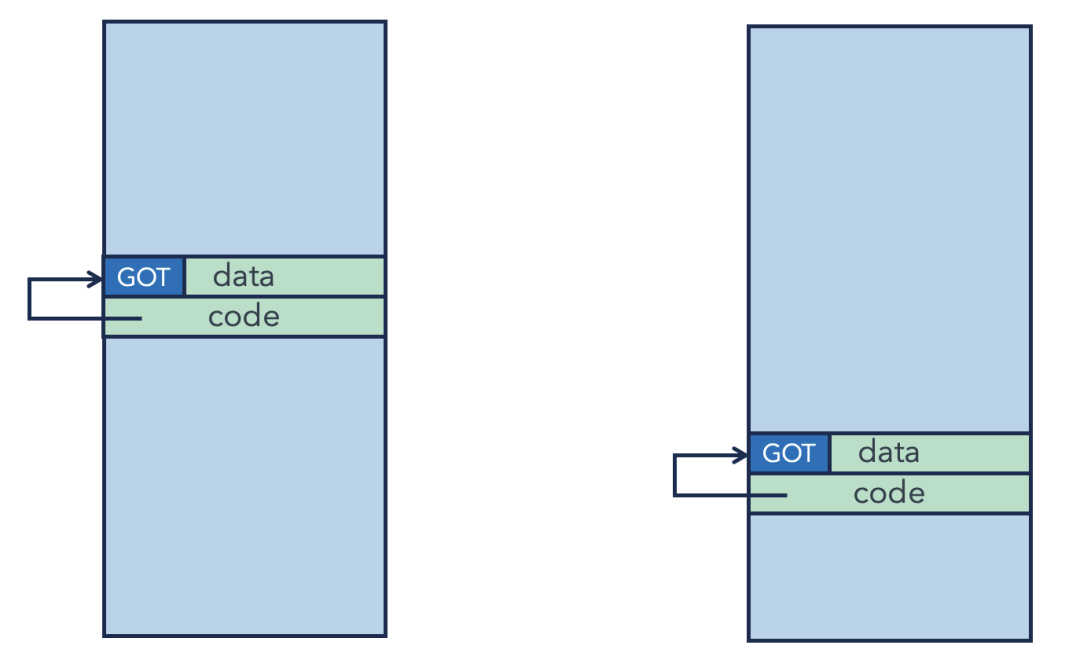
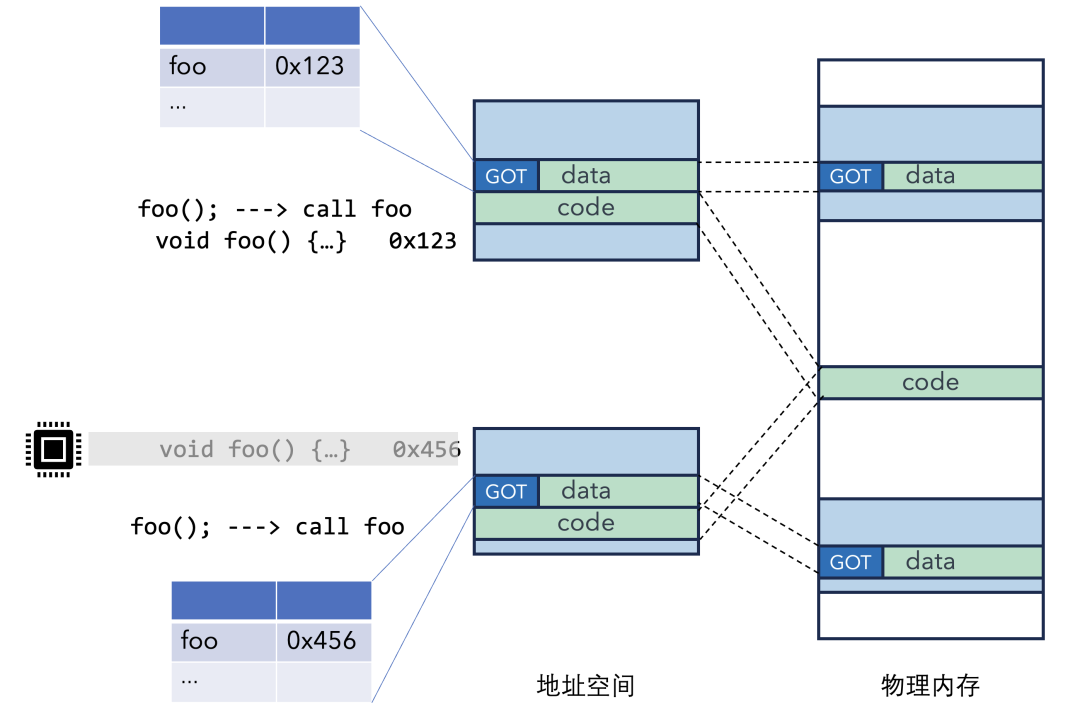
进程1的调用路径:call (相对跳转) -> 进程1的GOT项(存有0x123) -> 执行进程1的foo。
进程2的调用路径:call (相同的相对跳转) -> 进程2的GOT项(存有0x456) -> 执行进程2的foo。
性能优化:延迟绑定与过程链接表(PLT)
如果程序引用的动态库函数很多,那么在启动时,动态链接器需要把所有外部函数的地址都填到 GOT 表中,这个过程会比较耗时。然而,一个程序在运行时可能只会调用其中一小部分函数。
为了优化启动速度,系统引入了延迟绑定(Lazy Binding) 机制,其实现依赖于过程链接表(Procedure Linkage Table, PLT)。
简单来说:
- 最初的 GOT 表项并不直接存放函数地址,而是指向一段特殊的 PLT 桩代码。
- 当函数第一次被调用时,会执行这段 PLT 桩代码。它负责调用动态链接器,解析出函数的真实地址,并将其回填到对应的 GOT 表项中,然后将执行权交给该函数。
- 此后,再次调用该函数时,通过 GOT 表就能直接跳转到真实地址,无需再次解析。
这样就实现了“用时才绑定”,显著加快了程序的启动速度。当然,间接跳转(通过GOT/PLT)会比直接跳转多一两次内存访问和跳转,带来轻微的性能开销,但相比动态链接带来的模块化、易维护、省空间等巨大优势,这点开销通常是完全可以接受的。
总结与实践
动态链接库的实现,核心在于通过全局偏移表(GOT) 这个中间层来解决共享代码与私有地址空间的矛盾,并通过位置无关代码(PIC) 确保代码可被加载到任意位置。延迟绑定(通过PLT实现) 则是对性能的一种优化。
因此,在编译生成动态库时,必须使用 -fPIC 选项来生成位置无关代码:
gcc -shared -fPIC -o libfoo.so foo.c
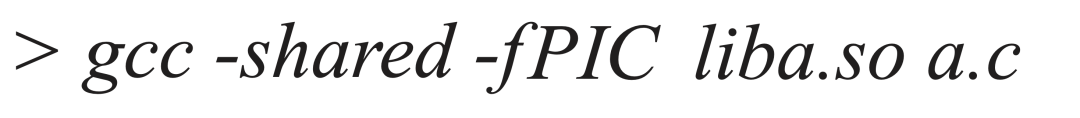
理解这些底层机制,不仅能帮助我们在遇到链接错误、符号冲突等问题时更快地定位原因,也能让我们对程序在操作系统中的加载和运行过程有更深刻的认识。希望这篇解析能帮助你揭开动态链接库的神秘面纱。如果你对更多底层技术细节感兴趣,欢迎在云栈社区交流讨论。
 发表于 2026-3-17 05:57:03
|
查看: 111|
回复: 0
发表于 2026-3-17 05:57:03
|
查看: 111|
回复: 0
