最近,一篇由 Tw93 分享的文章《你不知道的 Claude Code:架构、治理与工程实践》引起了我的注意。
通读全文后,我最强烈的感受是:这并非一篇鼓吹“安装即起飞”的体验文,而是一篇真正深入剖析 Claude Code 底层逻辑与工程化应用方法的深度技术文档。如果你正在使用 Claude Code,或是在折腾类似的 CLI Agent,这篇文章绝对值得你仔细研读。
它探讨的不是浅层的提示词技巧,而是更为根本的四个核心议题:
- Claude Code 的底层运作机制
- 上下文混乱的成因与治理策略
- Skills 与 Hooks 的合理设计
- 如何有效使用 Agents 以避免系统陷入混乱
首先需要明确一点:不要被“Claude Code”这个名字所迷惑。 它当然擅长编码,但其本质并非一个“仅会写代码的工具”,而是一个运行在终端内的通用型 Agent。只要为其提供文件、命令、工具和上下文,它能胜任的任务范畴实际上非常广泛。
为什么说这篇文章质量出众?
网络上关于 Claude Code 的文章不少,但多数停留在两个层面:展示几个炫酷的 Demo,或是分享几条 Prompt 模板。这类内容并非全无价值,但它们存在一个通病:读完后你会觉得工具很强大,但一旦进入深度使用阶段,依然会踩入无数陷阱。
Tw93 的这篇文章则截然不同。
它基于作者近半年的深度使用经验,最初在团队内部进行分享,随后整理成文。因此,你能清晰地感受到,文章的焦点并非“能不能用”,而是:
- 为什么它在某些时候表现卓越?
- 又为何会在某些时刻突然“变笨”?
- 如何使其表现更稳定?
- 如何将其真正工程化为可靠的工具?
简而言之,入门文章解决的是“会不会用”的问题,而此文解决的是“如何长期、稳定、专业地使用”。
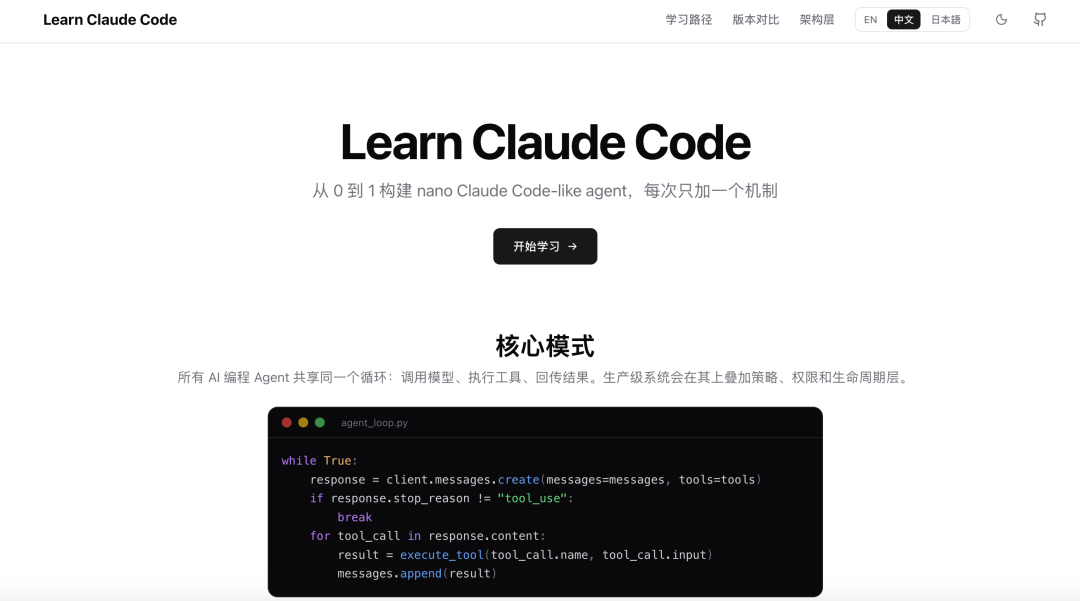
1. 底层逻辑:“上下文 + 工具 + 循环”
这是全文最关键的认知转折点。许多人误以为自己在使用 Claude Code 时,只是在“与 AI 对话”。但实际上,Claude Code 更像一个具备工具调用能力的执行循环。
当你输入一项任务后,Claude Code 接收到的并非仅仅是一句 Prompt,而是一个完整的上下文包,其中通常包含:
- 当前的任务描述
- 对话历史记录
CLAUDE.md 中定义的项目规则- 主动喂入的文档和文件
- MCP 工具的描述说明
- 终端命令的输出结果
- Git diff、错误信息、测试结果等
随后,Claude Code 会进入一个典型的 Agent 循环:
- 理解任务目标
- 判断是否需要调用工具
- 执行文件读取、内容搜索、命令执行等操作
- 根据执行结果更新判断
- 继续下一步,直至任务完成
这个认知至关重要。此外,还有一个极易被忽略但严重影响体验的特性:Prompt Caching(提示词缓存)。简单来说,Claude Code 会对长前缀上下文进行缓存。如果你复用相同的规则、文档和固定上下文,后续许多请求的成本会更低、速度也更稳定。然而,一旦前缀发生较大变动,缓存命中率就会显著下降。
当你将 Claude Code 视为一个“持续吸收新信息并做出决策的系统”时,许多现象就变得合理了:
- 为何新建一个会话时,效果往往更好?
- 为何工具越多,有时反而越混乱?
- 为何前期像专家,后期却开始偏离方向?
这并非它突然“失忆”,而是上下文系统变得过于臃肿了。
2. 上下文混乱的根源:噪声污染,而非模型退化
这是文章中极具价值的一部分。许多 Claude Code 用户都会遭遇一个现实困境:前20分钟像资深工程师,后20分钟却像刚入职的新手。
根本原因通常不是模型突然变“蠢”了,而是上下文遭到了污染。文章中指出了一些典型的污染源:
- 聊天历史越积越长,旧任务信息混杂其中
- 日志、命令输出、代码差异过多,挤占了宝贵的上下文空间
- MCP 工具描述本身过长,消耗了大量 Token
CLAUDE.md 写得过于冗杂,试图塞入所有规则- 在单一会话中同时进行问题排查、代码修改、文档编写、总结汇报,导致任务边界模糊
说白了,Claude Code 并非不知道答案,而是在一大堆信息中,难以定位当前最关键的内容。
那么,如何有效治理上下文?我们可以将文章的思路提炼为四条可直接落地的建议:
第一,CLAUDE.md 只应包含稳定的全局规则
许多人一开始就将所有规范、背景、注意事项全部塞进 CLAUDE.md。这看似周全,实则往往适得其反。更合理的做法是:
- 在项目根目录仅放置最核心、最稳定的全局规则。
- 将具体细节拆分为独立的文档。
- 在需要时,再通过指令或引用将其引入上下文。
这样做的好处显而易见:上下文更干净,规则意图也更清晰。
第二,任务变更时,应考虑开启新会话
不要指望一个会话能从修复 Bug 开始,一路完成架构修改、文档编写、测试补充和总结汇报。一旦任务领域发生变化,Claude Code 需要关注的信息焦点也随之改变。强行将所有事务塞入同一个上下文,最终很可能哪件事都做不好。关键在于,别把 Claude Code 当作一个“可以无限聊下去的窗口”,它更像一个需要你主动管理其“工作内存”的协作者。如果只是同一任务聊得过长、材料过多,也可以考虑使用 /compact 命令先进行一轮压缩,再继续推进。核心原则只有一个:让上下文中保留结论,而非无限堆积原始噪声。
第三,利用子代理(Subagents)进行上下文压缩
对于信息量需求特别大的工作,例如:
- 阅读大量文档
- 扫描冗长日志
- 在大型代码仓库中寻找线索
- 并行调研多个方向
更好的方式不是将所有原始材料都塞进主会话,而是派遣子 Agent 去执行局部任务,最终只返回结论、摘要和建议。这本质上是在做一件事:将原始噪声留在局部,把高价值的结论带回主上下文。
第四,MCP 工具并非越多越好
这是一个非常现实的建议。许多人在初玩 Claude Code 时,最容易上头的就是“先接入十几个工具再说”。但工具并非免费的午餐。每增加一个 MCP,实质上都在增加:
- 上下文的负担(工具描述占用 Token)
- 决策的分叉点(模型需要判断使用哪个工具)
- 出错的概率
因此,文章给出的建议非常中肯:只接入真正高频、真正有价值、且描述清晰的工具。 Claude Code 的核心竞争力不在于“接入了多少工具”,而在于“针对当前任务,能否稳定地做出正确决策”。
3. Skills 与 Hooks:厘清边界,避免混乱
这部分内容非常适合已经开始进阶配置的用户。许多人安装了一堆 Skills、配置了大量 Hooks,最后却发现系统不是更强了,而是更乱了。问题不在于功能不够多,而在于边界没有设计好。
Skills:应是模块化的经验包,而非巨无霸说明书
Skill 的核心作用,是将处理某类任务的最佳实践沉淀下来。例如:
- 撰写文章时,先明确受众,再确定结构,最后调整语气。
- 修改代码时,先理解约束条件,再评估影响范围,最后动手实施。
- 排查问题时,先收集证据,再提出假设,最后进行验证。
也就是说,Skill 解决的是 “这类事情应该如何做,才能更像专家” 的问题。
但文章中有一个重要观点:Skill 必须模块化、按需加载、职责单一。 原因在于,一旦 Skill 写得过于冗长、宽泛,试图包揽一切,模型就会被多条同时生效的指令拉扯,最终结果不是更专业,而是更混乱。一个 Skill 最好只解决一类特定问题,而不是既想管调研,又想管写作,还想管测试和 PR 规范。将其设计成“大而全”,最终基本无法稳定复用。因此,Skill 的设计原则可以总结为:小巧、清晰、可组合。
Hooks:应是刚性的护栏,而非提供情绪价值
如果说 Skill 更偏向于方法论,那么 Hook 则更接近于纪律和护栏。它最适合处理那些确定性、重复性、必须被执行的事务。例如:
- 任务结束时自动发送通知。
- 代码修改后自动执行格式化。
- 关键步骤完成后自动运行测试。
- 对高风险操作添加前置校验。
这个思路至关重要:凡是能通过确定规则解决的事情,就不要寄希望于模型“自觉记住去做”。
然而,Hook 也不能滥用。文章指出了一个很现实的问题:如果 Hook 设计得过于繁重、触发过于频繁、且热衷于中途打断,Claude Code 的执行流就会变得支离破碎,反而影响整体效果。更佳的做法通常是:
- 在关键节点进行检查。
- 在结束阶段进行兜底处理。
- 仅对少数高风险操作施加强约束。
简而言之:
- Skill 负责提供方法指导。
- Hook 负责强制执行纪律。
这两者的角色一旦混淆,系统就容易陷入混乱。
4. Agents 的正确用法:关键在于边界设计,而非数量堆砌
当前,很多人一谈到 Agent,就容易陷入一个误区:“是不是 Agent 越多就越厉害?”现实情况是,并非如此。
文章对此阐述得非常清楚:Agent 的价值,不在于数量,而在于清晰的边界。 子代理真正适用的场景通常包括以下几类:
- 对大量信息进行并行调研。
- 处理独立的局部性任务。
- 对长上下文任务进行压缩和总结。
- 从不同角色视角进行分工协作并产出。
例如,让一个 Agent 扫描日志,另一个分析 Git Diff,第三个阅读文档,最后将结论汇总给主 Agent,这种模式是合理的。
但如果任务本身就很微小,或者多个 Agent 之间高度依赖共享的上下文状态,那么随意开启“分身”,往往只会制造更多混乱。
一个好的 Agent 任务,通常具备以下几个特征:
- 目标明确。
- 输入清晰。
- 输出定义清楚。
- 边界划分清晰。
这与管理人类团队协同工作的逻辑并无二致。如果连任务本身都未定义清楚,就想着多开几个 Agent 来“协作”,最终很可能不是提升效率,而是制造混乱。这种对多智能体协作的深入思考,正是开源实战中探索高级应用时常常遇到的核心挑战。
5. 重新定位:Claude Code 是通用型 Agent,而非仅仅是聊天工具
读完这篇文章后,我最想强调的其实是这一点。目前许多人对 Claude Code 的理解,仍然停留在“一个非常强大的代码助手”层面。这当然没错,但若仅止步于此,实则低估了它的潜力。
Claude Code 真正的能力,不仅限于编写代码,更在于其完整的能力链路:
- 理解复杂目标。
- 调用多样化工具。
- 读取与修改文件系统。
- 执行终端命令。
- 根据反馈结果持续迭代。
你会发现,这套链路适用的远不止于编码场景。任何具备“有上下文、有可用工具、有执行步骤、有产出结果”特征的任务,它理论上都能处理。 例如:
- 撰写技术文档。
- 整理知识库。
- 批量分析与处理文件。
- 生成各类内容素材。
- 运行自动化脚本和工作流。
- 进行信息调研与汇总。
所以,不要被它的名字欺骗。Claude Code 的外壳看似一个编程工具,但其内核更像一个能够在终端中工作的通用型 Agent。 这也解释了为何深度使用者之间,最终比拼的早已不是谁会写 Prompt,而是谁更懂得:
- 如何设计高效的上下文。
- 如何合理拆分任务边界。
- 如何为系统添加有效的安全护栏。
- 如何实现长期、稳定的智能协作。
总结
如果你正在深度使用 Claude Code,我强烈建议你认真阅读一遍 Tw93 的这篇原文。因为它探讨的并非零散技巧,而是几个更为底层的系统性认知:
- Claude Code 的本质是上下文驱动的 Agent 执行循环。
- 有效的上下文治理远比玩弄 Prompt 技巧更重要。
- Skills 用于封装方法,Hooks 用于强制执行纪律,二者角色不可混淆。
- Agents 的价值核心在于精心的边界设计,而非简单的数量叠加。
这并非贩卖焦虑。事实是,当许多人还停留在“Claude Code 居然真能写代码,好神奇”的初级阶段时,先行者们已经开始将其视为一个可以长期协作、能够工程化治理、并可复用方法论的智能体系统进行深耕了。不得不说,这其中的认知差距,是巨大的。
来源
 发表于 2026-3-17 14:10:49
|
查看: 138|
回复: 0
发表于 2026-3-17 14:10:49
|
查看: 138|
回复: 0
