你是否遇到过这样的场景:一个看似简单的查询,在数据库中运行了几百秒,而关闭某个连接方式后,性能却提升了近千倍?这种“执行计划跑偏”的问题,其根源往往不在于最终的总代价(total_cost)估算,而潜藏在查询优化器构建路径的中间环节。今天,我们就从一个真实的案例出发,通过解读 PostgreSQL 源码,来揭示导致计划选择失误的根本原因。
问题现象
一个包含子查询的统计语句,实际执行时间长达 240 秒。通过 EXPLAIN ANALYZE 查看其执行计划,发现耗时主要集中在 Nested Loop Join 上:外表扫描了2293行,内表则被循环扫描了2293次,单次内表扫描耗时约103毫秒,累计耗时极为可观。
test=> explain analyze select count(*),zone_id from instance_info where instanceid in (SELECT instanceid
FROM
instance_info
where visible = 1
GROUP BY
instanceid
HAVING
COUNT(DISTINCT zone_id) > 1) and visible = 1 group by zone_id;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------
GroupAggregate (cost=232.45..232.47 rows=1 width=12) (actual time=244941.317..244942.725 rows=4.00 loops=1)
Group Key: instance_info.zone_id
Buffers: shared hit=3
-> Sort (cost=232.45..232.45 rows=1 width=4) (actual time=244940.890..244941.590 rows=4588.00 loops=1)
Sort Key: instance_info.zone_id
Sort Method: quicksort Memory: 193kB
Buffers: shared hit=3
-> Nested Loop (cost=200.01..232.44 rows=1 width=4) (actual time=124.292..244935.769 rows=4588.00 loops=1)
Join Filter: ((instance_info.instanceid)::text = (instance_info_1.instanceid)::text)
Rows Removed by Join Filter: 20185277
-> Foreign Scan (cost=100.01..116.12 rows=1 width=146) (actual time=25.421..137.939 rows=2293.00 loops=1)
Relations: Aggregate on (instance_info instance_info_1)
-> Foreign Scan on instance_info (cost=100.00..116.30 rows=2 width=150) (actual time=1.290..103.183 rows=8805.00 loops=2293)
Planning:
Buffers: shared hit=173
Planning Time: 1.516 ms
Execution Time: 244953.762 ms
(17 rows)
通常遇到这种情况,我们会尝试干预优化器的选择。例如,通过 SET enable_nestloop TO off; 强制禁用嵌套循环连接。更改后,优化器选择了 Hash Join,整个查询的执行时间骤降至 287 毫秒,性能提升了近 1000 倍。
test=> set enable_nestloop to off;
SET
test=> explain analyze select count(*),zone_id from instance_info where instanceid in (SELECT instanceid
FROM
instance_info
where visible = 1
GROUP BY
instanceid
HAVING
COUNT(DISTINCT zone_id) > 1) and visible = 1 group by zone_id;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
GroupAggregate (cost=232.44..232.46 rows=1 width=12) (actual time=273.475..274.907 rows=4.00 loops=1)
Group Key: instance_info.zone_id
Buffers: shared hit=3
-> Sort (cost=232.44..232.45 rows=1 width=4) (actual time=273.006..273.722 rows=4588.00 loops=1)
Sort Key: instance_info.zone_id
Sort Method: quicksort Memory: 193kB
Buffers: shared hit=3
-> Hash Join (cost=216.13..232.43 rows=1 width=4) (actual time=160.901..271.843 rows=4588.00 loops=1)
Hash Cond: ((instance_info.instanceid)::text = (instance_info_1.instanceid)::text)
-> Foreign Scan on instance_info (cost=100.00..116.30 rows=2 width=150) (actual time=4.691..109.722 rows=8805.00 loops=1)
-> Hash (cost=116.12..116.12 rows=1 width=146) (actual time=156.185..156.186 rows=2293.00 loops=1)
Buckets: 4096 (originally 1024) Batches: 1 (originally 1) Memory Usage: 144kB
-> Foreign Scan (cost=100.01..116.12 rows=1 width=146) (actual time=21.939..155.037 rows=2293.00 loops=1)
Relations: Aggregate on (instance_info instance_info_1)
Planning Time: 0.242 ms
Execution Time: 287.414 ms
(16 rows)
那么,核心问题就来了:为什么优化器最初会选择那个效率低下的 Nested Loop 计划? 是统计信息不准,还是代价计算模型存在偏差?
问题分析
对比两个执行计划的顶层代价(GroupAggregate 的 cost):
- Nested Loop 路径:
(cost=232.45..232.47)
- Hash Join 路径:
(cost=232.44..232.46)
显然,Hash Join 路径的启动代价(startup_cost)和总代价(total_cost)都更小。既然如此,优化器为什么不选择它呢?
这里存在一个普遍的认知误区:我们可能认为优化器先生成所有可能的执行路径,然后简单地比较它们的最终代价,并选择代价最小的那一个作为最优计划。
但实际上,在 add_path 函数动态构建路径树的过程中,每个关系(Rel)的路径列表(pathlist)都在实时更新。当为某个连接关系生成一种新的连接路径(如 Hash Join)时,它会立即与现有的路径(如 Nested Loop)进行比较,根据一系列规则决定是采纳新路径、保留旧路径,还是两者都保留。很可能在连接路径生成的环节,性能更好的 Hash Join 路径就已经被“淘汰”了,根本无缘进入后续的排序(Sort)和聚合(Aggregate)节点评估。
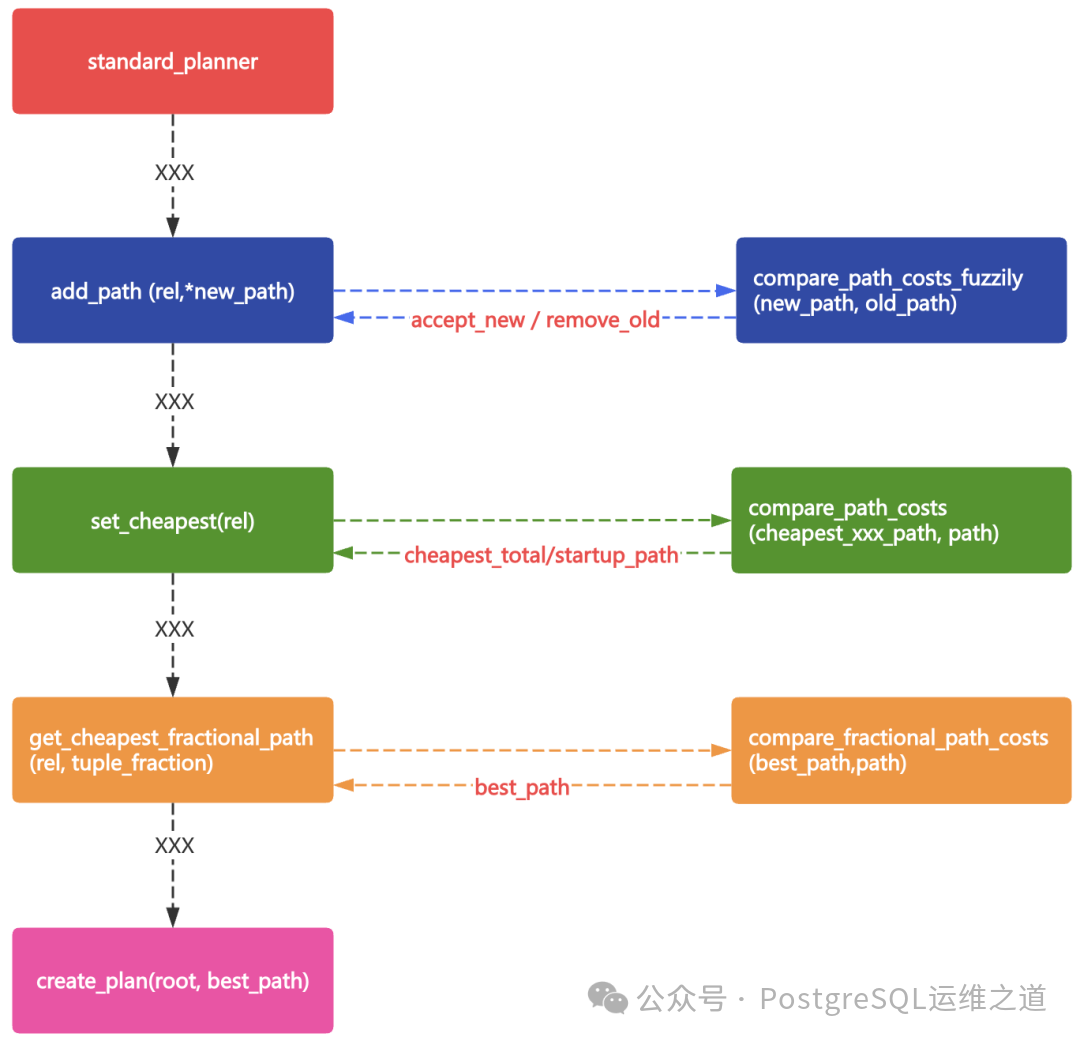
在这个案例中,这种猜测是否成立呢?我们看连接节点本身的代价:
- Nested Loop:
(cost=200.01..232.44)
- Hash Join:
(cost=216.13..232.43)
两条路径的总代价非常接近。结合对源码的研究,问题的原因已经呼之欲出。
在 add_path 函数中,决定新路径(new_path)去留的第一步,是使用一个模糊代价比较函数 compare_path_costs_fuzzily [1] 来评估新路径与旧路径(old_path)的优劣。
在这个案例中,path1(新路径)是 HashPath,path2(旧路径)是 NestPath。该函数的比较逻辑遵循一个严格的顺序:
- 首先比较
disabled_nodes。由于 enable_nestloop 和 enable_hashjoin 均为 on,所以两者 disabled_nodes 均为 0,未决出胜负。
- 接着比较
total_cost,并引入一个模糊系数(默认 1.01,即 1%)。计算 232.43 > 232.44 * 1.01 和 232.44 > 232.43 * 1.01,两者均不成立。因此,判定两条路径的总代价“模糊相等”。
- 最后比较
startup_cost,同样引入 1% 的模糊系数。计算 216.13 > 200.01 * 1.01,结果为真。因此,函数返回 COSTS_BETTER2,意味着旧路径(NestPath)在模糊比较中胜出。
经过这一轮比较,优化器认为 HashPath 不优于现有的 NestPath,因此 HashPath 在连接路径生成阶段就被淘汰了。随后,优化器仅基于胜出的 NestPath 继续生成后续的 SORT 和 AGG 节点路径。
下面是 compare_path_costs_fuzzily 函数的核心代码逻辑:
static PathCostComparison
compare_path_costs_fuzzily(Path *path1, Path *path2, double fuzz_factor)
{
#define CONSIDER_PATH_STARTUP_COST(p) \
((p)->param_info == NULL ? (p)->parent->consider_startup : (p)->parent->consider_param_startup)
/* Number of disabled nodes, if different, trumps all else. */
if (unlikely(path1->disabled_nodes != path2->disabled_nodes))
{
if (path1->disabled_nodes < path2->disabled_nodes)
return COSTS_BETTER1;
else
return COSTS_BETTER2;
}
/*
* Check total cost first since it's more likely to be different; many
* paths have zero startup cost.
*/
if (path1->total_cost > path2->total_cost * fuzz_factor)
{
/* path1 fuzzily worse on total cost */
if (CONSIDER_PATH_STARTUP_COST(path1) &&
path2->startup_cost > path1->startup_cost * fuzz_factor)
{
/* ... but path2 fuzzily worse on startup, so DIFFERENT */
return COSTS_DIFFERENT;
}
/* else path2 dominates */
return COSTS_BETTER2;
}
if (path2->total_cost > path1->total_cost * fuzz_factor)
{
/* path2 fuzzily worse on total cost */
if (CONSIDER_PATH_STARTUP_COST(path2) &&
path1->startup_cost > path2->startup_cost * fuzz_factor)
{
/* ... but path1 fuzzily worse on startup, so DIFFERENT */
return COSTS_DIFFERENT;
}
/* else path1 dominates */
return COSTS_BETTER1;
}
/* fuzzily the same on total cost ... */
if (path1->startup_cost > path2->startup_cost * fuzz_factor)
{
/* ... but path1 fuzzily worse on startup, so path2 wins */
return COSTS_BETTER2;
}
if (path2->startup_cost > path1->startup_cost * fuzz_factor)
{
/* ... but path2 fuzzily worse on startup, so path1 wins */
return COSTS_BETTER1;
}
/* fuzzily the same on both costs */
return COSTS_EQUAL;
#undef CONSIDER_PATH_STARTUP_COST
}
我们可以通过调试来验证上述过程。在生成连接路径时,优化器依次尝试 MergePath、NestPath 和 HashPath。假设 NestPath 已作为旧路径存在,当生成 HashPath 作为新路径时,两者进入 compare_path_costs_fuzzily 函数比较。
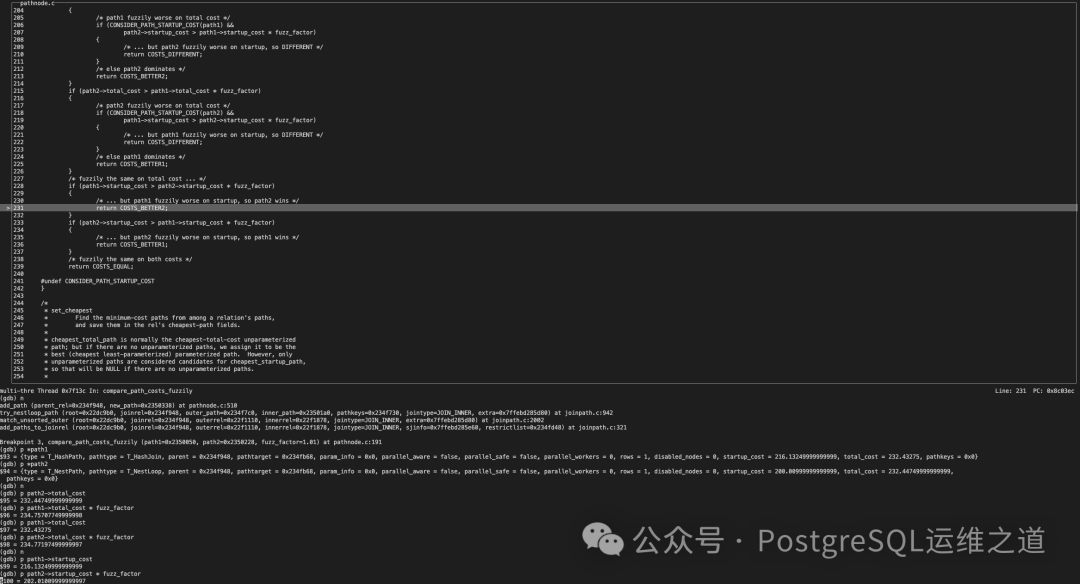
函数比较后发现总代价差异未超过1%,但启动代价差异超过了1%,于是返回 COSTS_BETTER2(NestPath 更优)。在 add_path 函数中,这个返回值会进入相应的处理分支。
当判断结果为 COSTS_BETTER2 时,如果满足一些特定条件(如参数化信息相等),代码会将 accept_new 标志位设为 false。
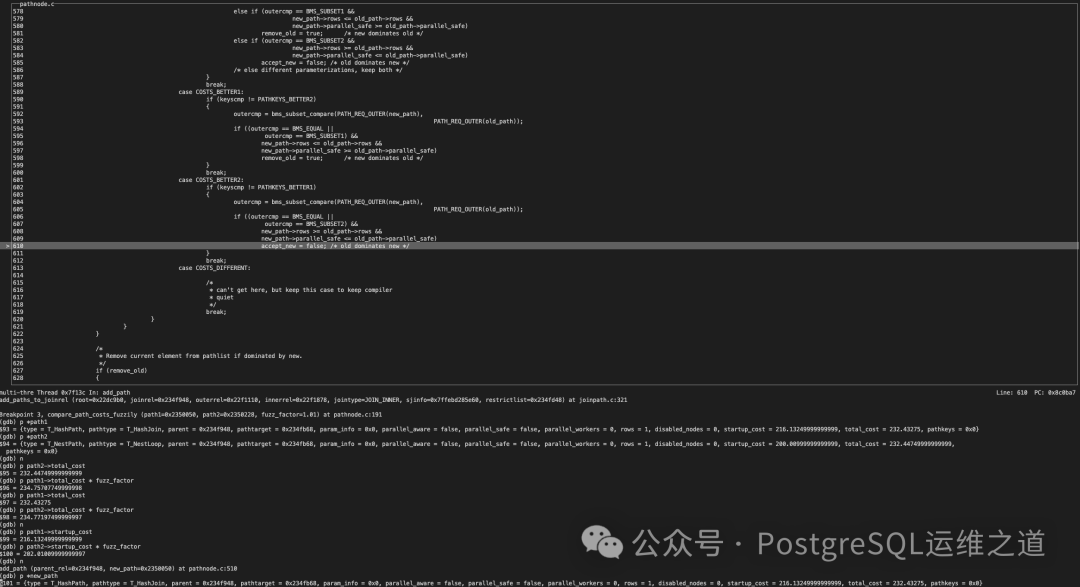
正是因为这个 accept_new 被设为 false,后续逻辑会拒绝并回收新路径(HashPath),导致其被淘汰。
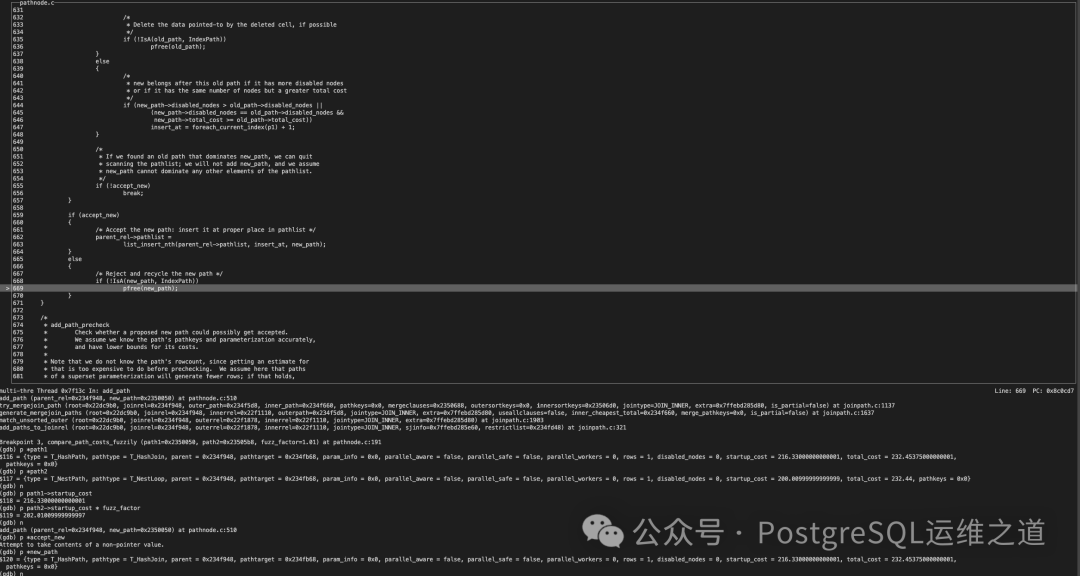
随后,优化器在剩余的路径中进行精确代价比较,确定当前关系(Rel)的 cheapest_total_path 和 cheapest_startup_path,均为 NestPath。
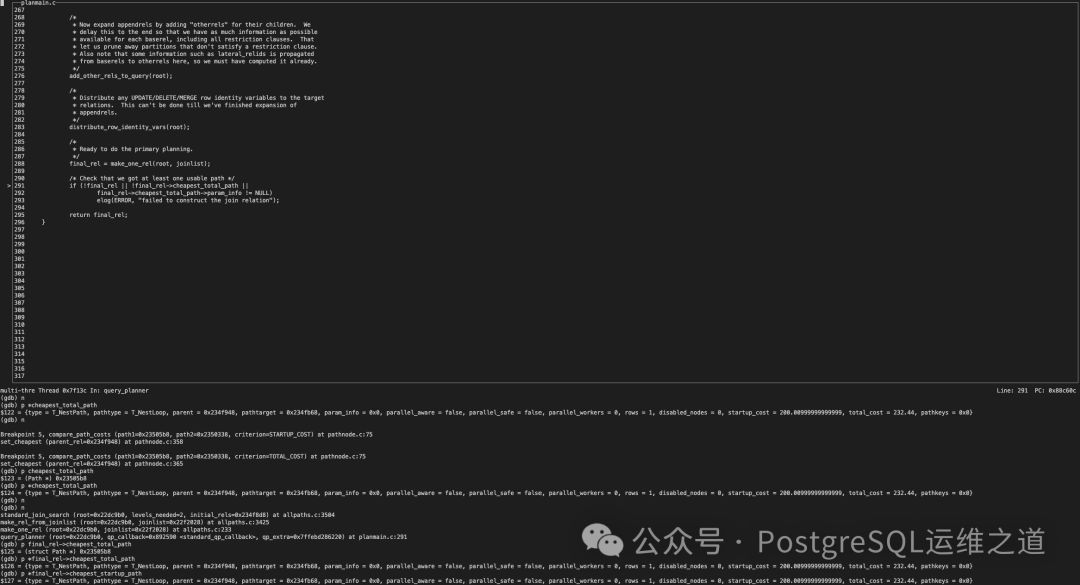
最终,优化器使用这个“最优”路径(best_path)来生成最终的查询执行计划。
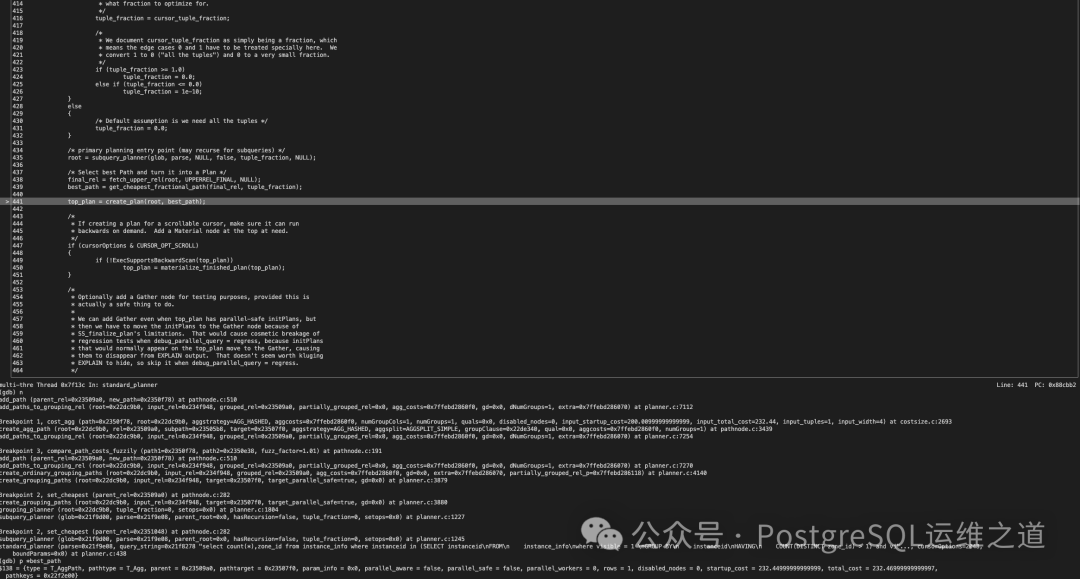
至此,问题的根源已经非常清晰。这个“代价模糊比较”机制在某些场景下可能存在缺陷。特别是当两条路径的代价非常接近,无论是总代价还是启动代价,其差异小于默认的 1% 模糊因子(STD_FUZZ_FACTOR)时,优化器可能会因为启动代价的微小劣势而淘汰掉总代价更优(或实际执行效率更高)的路径,从而选择了一个次优计划。
一个自然的想法是:能否将这个 STD_FUZZ_FACTOR 调得更小(比如 1.001),让比较更“精确”?理论上可以,但必须极其谨慎。这是优化器最核心的决策逻辑之一,修改它可能引发蝴蝶效应,影响无数查询的计划稳定性。目前看来,这个模糊比较逻辑在处理边际案例时显得不够“优雅”,未来版本或许会对其调整甚至移除。当然,如果你有深入的想法,完全可以到 PostgreSQL 社区与 Tom Lane 等核心开发者进行探讨。
我们必须接受一个现实:不能指望查询优化器始终做出百分之百正确的选择。在本案例中,除了模糊比较机制,还有一个辅助问题:Foreign Table(外表)的统计信息。从执行计划看,外表预估扫描1行,实际却扫描了2000多行,这显然是统计信息严重失准。
那么,外表有统计信息吗?答案是肯定的。外表本身是远程表的映射,没有本地物理元组。其统计信息是通过 Foreign Data Wrapper (FDW) 访问远端表来收集的。但关键点在于,这个过程是“手动挡”。因为常规的 VACUUM/AUTOVACUUM 不会对外表触发统计信息收集,必须通过手动执行 ANALYZE 命令来更新。
在本案例中,对相关外表执行 ANALYZE 更新统计信息后,优化器对各种路径的代价估算差异变得更为显著,默认就选择了更优的 Hash Join 路径。因此,定期为外表收集统计信息是至关重要的运维操作,忽视这一点可能会导致整个实例的性能被个别慢查询拖垮。
总结
本文通过一个真实的性能案例,深入分析了 PostgreSQL 执行计划“跑偏”的一种深层原因:当不同连接路径的估算代价非常接近(差异在1%以内)时,优化器在 add_path 阶段的模糊代价比较机制,可能会因为启动代价的微小劣势而淘汰掉总代价更优或实际性能更好的路径,最终生成一个次优的执行计划。
面对这类问题,我们可以使用诸如 enable_nestloop 这类配置参数或更高级的 pg_hint_plan 扩展来进行人工干预。而更前沿的解决方案,则是探索利用强化学习等AI技术实现执行计划的自动化调优,让数据库具备自我管理和优化的能力。我在之前的文章《AI4DB试玩-Bao/Balsa适配PG18》中研究过相关模型,并在PCC2025大会上做过分享。这项专业的研究正在由我们的好友崔鹏博士持续推进,相关成果将在未来的HOW2026大会上亮相,值得期待。
数据库优化是一门精深的艺术,理解其内核机制是解决问题的关键。欢迎到云栈社区交流更多关于PostgreSQL优化器的问题与心得。
Reference
[1] compare_path_costs_fuzzily 函数源码:https://github.com/postgres/postgres/blob/REL_18_0/src/backend/optimizer/util/pathnode.c#L185
 发表于 2026-1-29 19:26:25
|
查看: 152|
回复: 0
发表于 2026-1-29 19:26:25
|
查看: 152|
回复: 0
