最近,为了响应客户对现有2D数字人实时互动系统中嘴型不真实的反馈,我投入时间研究了几个热门的开源2D视频数字人项目,并在我的 GeForce RTX 3070 显卡上逐一测试了它们的实际表现。
1. 项目探索:dhlive
第一个考察的项目是 dhlive,其开源地址为:https://github.com/kleinlee/DH_live
这个框架基于 DINet 模型,其核心优势在于:一旦模型训练完成,在实际推理时便不再需要 GPU 进行复杂的渲染,也无需依赖传统的视频推流服务。它的工作流程是,接收音频流直接生成对应的数字人嘴型图片帧,然后通过前端 Canvas 技术将图片帧合成为视频流进行播放。
相比于市面上普遍采用推流服务的 2D 数字人方案,这种方法在服务器成本和架构复杂度上有着显著的优势。
下图展示了将训练好的模型集成到我自研的实时互动系统(集成了ASR、TTS、LLM及知识库)后的运行效果。
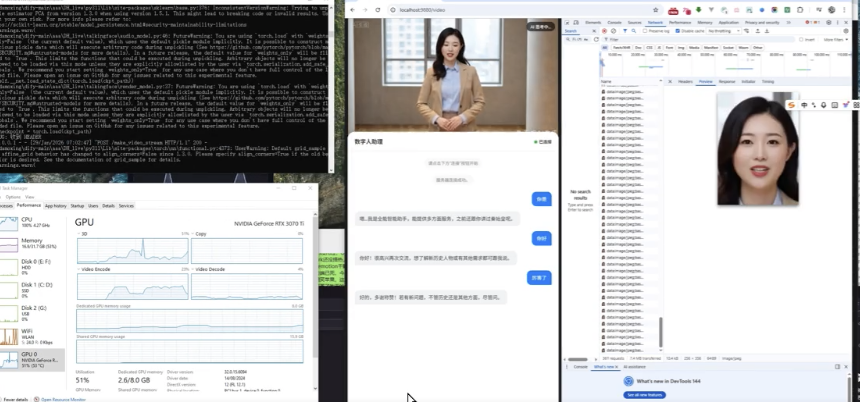
由于当前测试电脑的C盘内存可能不足,延迟仍有优化空间,期待后续拿到更高配置的设备进行进一步测试。
操作与训练过程
我主要参考了B站上刘悦老师的视频教程进行训练。使用一段个人视频作为训练集,整个训练过程耗时将近8个小时。期间因为系统待机中断了一次,最终成功生成了21000步的模型文件。如果直接使用项目提供的默认泛化模型 render.pth,生成的嘴型区域会显得比较模糊,而使用自己训练的专属模型则效果更佳。
性能优化思路与实践
在源代码的实时对话演示 demo.py 中,每次传入一段音频,后端都会生成一个完整的视频文件,这种方式对 CPU 和磁盘 I/O 的消耗极大。为了将其应用于低延迟的实时互动场景,我进行了三步优化。
第一步:区域化渲染 (ROI)
不再生成完整的全身视频。我们仅截取数字人的面部区域(ROI),生成一个分辨率较小的视频(例如 256x256)。前端利用 Canvas 的图层叠加能力,底层播放静态的全身背景图或视频,上层则在指定坐标实时绘制生成的面部小视频。这一改动能将需要编码和传输的视频数据量减少 90% 以上,对降低延迟效果显著。
第二步:去 MP4 化 (音频 + 图片序列)
第一步优化后,仍然存在瓶颈:
- FFmpeg 编码延迟:使用
cv2.VideoWriter 或 FFmpeg 将图片帧和音频压缩成 H.264 MP4 视频非常耗时。
- 磁盘 I/O:需要频繁写入和读取视频临时文件。
- HTTP 请求延迟:前端必须等待整个 MP4 文件生成完成才能开始下载播放。
为此,我们采用了更彻底的方案:后端直接返回原始音频数据 + 一组 Base64 编码的 JPEG 图片字符串。前端在播放音频的同时,根据当前音频播放的时间戳,从图片数组中取出对应的帧绘制到 Canvas 上。
这种方案的优势在于:
- 音频同步简单:前端只需解码音频,速度极快。
- 绕过 FFmpeg:后端跳过了最耗时的视频编码环节,通常能节省 60% 以上的处理时间。
- 无磁盘延迟:所有数据在内存中处理并转换为 JSON 格式发送,避免了磁盘读写等待。
- 数据传输量小:一张 256x256 的 JPEG 图片可能只有 5KB,一段3秒钟的视频总计约 300KB 数据,网络传输瞬间完成。
第三步:WebSocket 二进制流式传输
我们进一步消除了“等待整句生成完毕”的延迟。采用流式处理:后端每生成一帧图片(约 0.04秒),就立即通过 WebSocket 以二进制形式发送给前端。前端收到帧后,立刻放入渲染缓冲区准备显示。
这样一来,首帧延迟从“整句话的生成时间(例如3秒)”大幅降低到“单帧的生成时间(0.04秒)”,实现了质的飞跃。上文展示的效果图,正是通过这种一帧帧实时流式合成实现的。流式处理是构建高性能实时应用的关键技术之一,在云栈社区的许多前沿开源实战讨论中也有深入探讨。
2. 项目探索:heygem
之前我们曾尝试使用官方的 heygem 部署方案集成到数字人系统中制作口播视频。在B站上看到不少开发者基于其源码实现了实时对话功能后,我也亲自尝试了一下。
实际测试中,其嘴部驱动的视觉效果确实非常出色,但对于实时对话场景,它需要持续的 GPU 渲染,直接将我 8G 显存的显卡占用拉满,对硬件资源要求较高。
总结与选择
目前,在我成功部署并测试的开源方案中,能够实现“无需推流”的2D视频数字人主要是 dhlive 和 heygem 这两个项目。综合考虑部署复杂度、运行资源消耗以及后续的优化可控性,在当前阶段,dhlive 仍然是我的首选方案。它的技术路径更清晰,通过上述优化后,能在普通消费级显卡上实现可用的实时互动效果。
本次探索涉及了从模型训练、深度学习原理到工程化优化的全过程,是一次非常有价值的实践。如果你也对类似的低资源消耗实时AI应用开发感兴趣,不妨持续关注云栈社区的技术动态。

参考链接
 发表于 2026-1-31 07:14:01
|
查看: 202|
回复: 0
发表于 2026-1-31 07:14:01
|
查看: 202|
回复: 0
