◆ AI演义|第7篇
论文: Deep Residual Learning for Image Recognition
时间: 2015年12月
作者: 何恺明、张祥雨、任少卿、孙剑(微软亚洲研究院)
AlexNet有8层,VGGNet有19层,GoogleNet有22层。
深度学习热潮兴起后,研究者们似乎达成了一个共识:把网络做得更深。背后的逻辑很直观——更深的网络理论上具备更强的表征能力,能学习更复杂的特征,性能理应更好。
然而在2015年,微软亚洲研究院的团队发现了一个有悖直觉的现象:网络并非越深越好。
他们设计了一个对照实验:在CIFAR-10数据集上,分别训练一个20层的网络和一个56层的网络。按照常理,拥有更多参数的56层网络应该表现更优。但实验结果却令人意外——56层网络不仅在测试集上准确率更低,甚至在训练集上的表现也不如20层的网络。
这并非典型的过拟合。过拟合的特征是模型在训练集上表现良好却在测试集上失准。而这里出现的是训练和测试性能的全面下降。
研究人员将这一难题称为 “退化问题”。
———— ◆ ————
退化问题为何如此棘手?
我们不妨这样想:一个56层的网络,其能力下限至少应该与20层的网络持平吧?最不济,让额外增加的36层学习“恒等映射”(Identity Mapping),即输入什么就输出什么,这样整个网络不就退化成一个20层的网络了吗?
理论上可行,但实践中却异常困难。神经网络的每一层都在进行非线性变换,要求它精确地学会“什么都不做”,意味着需要将所有参数调整到一个极其特殊的状态。在随机初始化的起点上,网络依靠梯度下降很难自行收敛到这个解。
何恺明等人洞悉了关键所在:既然让网络直接学习恒等映射如此艰难,何不换一种思路——让网络去学习“残差”。
———— ◆ ————
什么是残差?
假设我们希望某一层(或一组层)学习的潜在映射是 $H(x)$,其中 $x$ 是输入。传统网络的直接做法是让参数层去拟合 $H(x)$。
而残差学习则提出了一个巧妙的改写:让网络去学习残差函数 $F(x) = H(x) - x$。那么,原本的映射就可以表示为 $F(x) + x$。
这仅仅是数学表达上的小把戏吗?恰恰相反,这一改写带来了根本性的差异。
如果对于某些层来说,最优的映射就是恒等映射(即 $H(x) = x$),那么残差学习的目标 $F(x)$ 就变成了 $0$。让一组参数学习“输出零向量”远比学习“输出输入本身”要容易得多——理论上,将所有权重置零就能逼近这个目标。
打个比方:传统网络好比让你在白纸上创作一幅完整的画;而残差网络则是给你一张草图,让你只做修改和补充。后者任务的难度显然更低。
———— ◆ ————
这一思想在工程实现上极为简洁:增加一条“捷径连接”,将输入直接跳接到输出,进行逐元素相加。
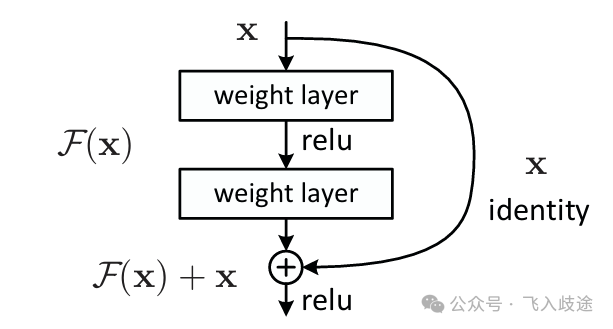
Residual learning: a building block.(残差学习的基本构建块)
标准残差块的结构如图所示:输入 $x$ 经过两个权重层(通常伴随ReLU激活函数)后得到 $F(x)$,然后与原始的输入 $x$ 相加,最后再通过一个ReLU激活函数输出。这条旁路(Skip Connection)就像为信号和梯度修建了一条“高速公路”。
实现就是如此简单。它不引入额外的参数,计算开销也微乎其微,仅仅是在架构上多了一条“跳线”。
但带来的效果却是革命性的。
借助残差连接,神经网络可以轻松训练到100层、200层,甚至上千层。退化问题迎刃而解,更深的网络确实能够学习到更优的特征表示。
在2015年的ImageNet大规模视觉识别挑战赛上,何恺明团队凭借152层的ResNet一举夺魁,将Top-5错误率降至3.57%——这是首次有模型的识别准确率超越人类平均水平(约5%)。
———— ◆ ————
ResNet的影响力早已超越了图像识别的范畴。
残差连接 这一设计思想,后来被广泛集成到各类神经网络架构中。2017年划时代的 Transformer 论文中,编码器和解码器的每一个子层都包含了残差连接。时至今日,驱动着GPT、Claude、Gemini等大模型的核心架构,底层无一不是“残差网络”。
为什么残差连接如此有效?除了前文提到的“易于学习恒等映射”之外,另一个至关重要的原因是:它极大地改善了梯度流动。
神经网络的训练依赖于反向传播算法,梯度需要从输出层逐层传递回输入层。网络越深,梯度需要穿越的层数越多,越容易出现问题——要么梯度在传播过程中不断衰减直至消失(梯度消失),要么不断放大导致数值不稳定(梯度爆炸)。
残差连接提供了一条“梯度高速公路”,让梯度可以直接通过捷径连接反向传播,绕过了部分权重层的非线性变换。这显著缓解了深度网络中的梯度消失/爆炸问题,使得训练成百上千层的超深网络成为可能。
———— ◆ ————
ResNet论文的四位作者均为华人研究者,当时均供职于微软亚洲研究院。
何恺明后来加入Facebook AI Research,现任麻省理工学院教授,是计算机视觉领域最具影响力的研究者之一,其多篇论文引用量逾万次。
张祥雨是阶跃星辰的联合创始人兼首席科学家,该公司是国内头部的大模型创业公司之一。
任少卿现任蔚来汽车自动驾驶研发负责人。
孙剑曾任旷视科技首席科学家,不幸于2022年逝世,享年45岁。他是计算机视觉领域的杰出学者,培养了大量优秀人才,他的离去是学术界的重大损失。
微软亚洲研究院素有“AI界黄埔军校”之称,为中国AI领域输送了大量顶尖人才。ResNet无疑是该机构最具影响力的成果之一。
———— ◆ ————
ResNet论文已成为深度学习史上被引用次数最多的论文之一,截至2024年,其在Google Scholar上的引用量已超过22万次。
它的贡献远不止提出一个具体的网络模型,更重要的是确立了 “残差学习” 这一核心思想。这一思想简洁、优雅且极为有效,如今已成为构建几乎所有深度模型的标配组件。
有人说,深度学习的历史可以划分为“ResNet之前”和“ResNet之后”。此言或许略有夸张,但ResNet无疑是一座关键的里程碑。
它向世界证明了一个道理:有时,最朴素的想法,恰恰是最具威力的。 更多关于前沿人工智能技术的深度讨论,欢迎访问 云栈社区。
原文链接:
Deep Residual Learning for Image Recognition (2015)
https://arxiv.org/pdf/1512.03385
下一篇预告: 我们将来到2017年——那一年,一篇题为“Attention Is All You Need”的论文横空出世,提出了名为Transformer的架构。这个架构将彻底改变AI发展的轨迹。
AI演义|重读重要论文
上一篇:Distilling·知识蒸馏的艺术
下一篇:Transformer·一个时代的序幕
 发表于 2026-3-19 07:08:13
|
查看: 158|
回复: 0
发表于 2026-3-19 07:08:13
|
查看: 158|
回复: 0
