4D 世界模型是数字内容创作、自动驾驶和具身智能的核心基础设施。当前主流的“重建-生成”混合范式虽已展现潜力,但面临两大可扩展性瓶颈:数据端依赖昂贵的多视角或静态场景数据,训练端需要繁重的离线预处理(深度估计、3D 重建等)。这使得现有方法难以利用互联网上海量的单目视频资源,模型的泛化能力和应用场景也因此受限。
针对上述挑战,中国科学院自动化研究所与 CreateAI 联合提出通用 4D 世界模型 NeoVerse,将全训练流程扩展至开放场景单目视频数据。
NeoVerse 通过免位姿前馈式 4DGS 重建与在线退化模拟,从百万级互联网单目视频中学习,不仅在重建和生成基准上均达 SOTA,更凭借强大的泛化能力,一个模型即可支持 4D 重建、新视角生成、自动驾驶仿真、机器人、视频编辑等海量下游任务。研究论文已被 CVPR 2026 接收。

方法
NeoVerse 的架构如图 1 所示,采用两阶段架构——先通过前馈式 4DGS 模型秒级重建4D场景,再利用在线退化模拟构造训练对,引导视频生成模型从退化渲染中恢复高质量新视角视频。
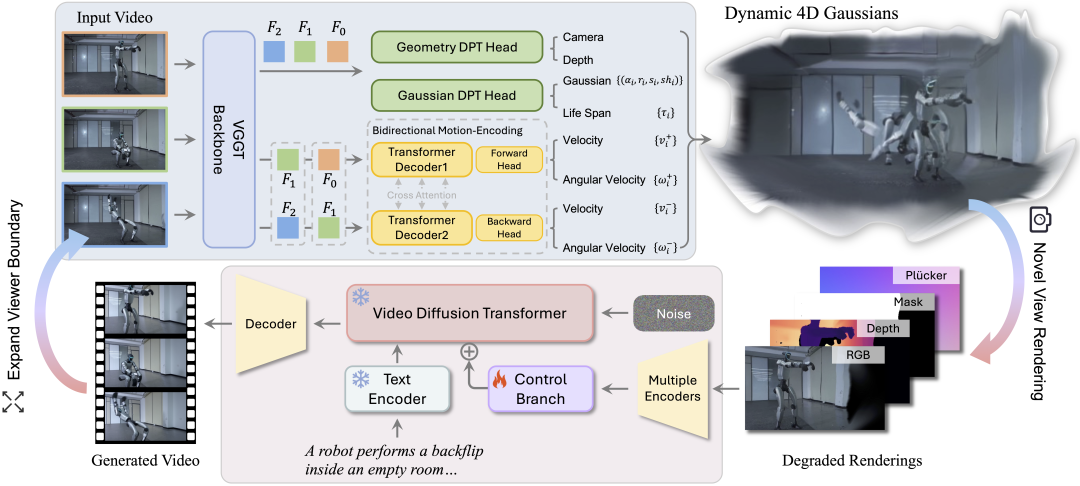
图 1: NeoVerse框架概述。
1. 免位姿前馈式4DGS重建
研究团队提出的前馈模型部分基于 VGGT 骨干网络扩展,输入单目视频,无需相机位姿,前馈输出完整 4D 高斯场(3D位置、不透明度、旋转、缩放、球谐系数、生命周期、双向速度/角速度)。重建仅需 2-10 秒。
双向运动建模: 区别于单向运动预测,NeoVerse 同时建模 t->t+1 与 t->t-1 两个方向的瞬时运动。帧特征沿时间维切分后,通过交叉注意力分别编码前向/后向运动特征。
2. 重建引导的视频生成
稀疏关键帧重建 + 密集渲染: 仅从长视频中选取 11-21 帧关键帧作为重建输入,但渲染全部 N 帧:
- 位置基于线性运动假设进行平移;
- 旋转通过角速度进行变换;
- 不透明度则依据时间衰减函数调整,其衰减速率由生命周期参数控制,并利用归一化时间距离以适应非均匀关键帧间隔。
在线单目退化模拟: 单目视频只有一个视角,如何构造训练对?NeoVerse 提出三种在线退化机制,数据构建如图 2 所示:
- 基于可见性的 Gaussian 裁剪 —— 模拟遮挡;
- 平均几何滤波器 —— 模拟飞边像素与几何畸变;
- 退化渲染条件注入 —— 将 RGB、深度、不透明度掩码和 Plücker 嵌入作为多模态条件输入生成模型。

图 2: 基于退化模拟的训练数据构建。
3. 视频生成
模型基于 Wan-T2V 14B + Rectified Flow,采用 ControlNet 式控制分支注入退化渲染条件。冻结生成主干仅训练控制分支,兼容 LoRA 蒸馏将生成时间从 120 秒降至 18 秒。
应用
NeoVerse 作为通用 4D 世界模型,从开放场景单目视频中学到的 4D 场景理解与控制能力,可自然迁移到多种下游任务,无需针对每个任务单独训练。
- 任意视角控制: NeoVerse 的核心能力在于从单目视频重建完整 4D 场景后,支持用户自由定义任意相机轨迹(平移、旋转或复杂组合),生成时空一致的高质量新视角视频。
- 图像到3D世界: 给定单张静态图像,NeoVerse 通过迭代式新视角生成与重建,逐步将可见区域向四周扩展,最终将一张图像“展开”为完整的、可自由漫游的 3D 世界。
- 机器人与具身智能: NeoVerse 的 4D 重建能力天然适配具身智能场景,通过对单目视频的重建,机器人能够获取新视角信息,为环境感知与决策提供支持。
- 自动驾驶仿真:
- 单目变多视角,唤醒存量数据价值: 多视角数据是感知训练与闭环仿真的基础,但海量历史数据来自单目行车记录仪。NeoVerse 可从一段普通行车视频出发,自动生成多视角仿真画面,将单目数据高效转化为多视角仿真资源。
- 反事实场景构建,突破真实世界局限: 真实道路难遇“大象穿行”等反事实场景,但自动驾驶必须能应对极端长尾事件。NeoVerse 可在真实驾驶场景中插入各类罕见物体,生成高保真反事实视频——同一段路,插入不同物体,场景瞬间重构。
- 视频编辑: 精准修改场景元素,NeoVerse 结合 SAM2 等分割工具,可以对视频中的特定目标进行精准编辑(如更换车辆颜色、材质变换),且编辑结果在时间维度上保持一致。
- 子弹时间: 结合新视角生成,NeoVerse 可以实现电影级的子弹时间效果——时间仿佛凝固,镜头却自由变化。
- 相机抖动控制: 手持拍摄或车载视频常因运动产生抖动,影响观感与后续处理。NeoVerse 基于 4D 重建获取全局场景结构,可重新规划相机轨迹:既能为抖动视频做稳定化处理,也能为平稳视频人为注入抖动(例如用于训练抖动鲁棒的下游模型)。两种操作均源于对场景 4D 结构的理解,而非简单的像素级变换。
- 变焦控制: 除了相机位姿控制,NeoVerse 还支持对相机焦距的动态调整,实现从广角(短焦、大视野)到长焦(小视野、局部放大)的连续变焦效果。
评估
NeoVerse 在静态数据集与动态数据集上的重建结果分别如表 1 和表 2 所示。该重建部分在所有评估指标上均达到了 SOTA。
表 1: 与其他静态重建模型的定量比较。
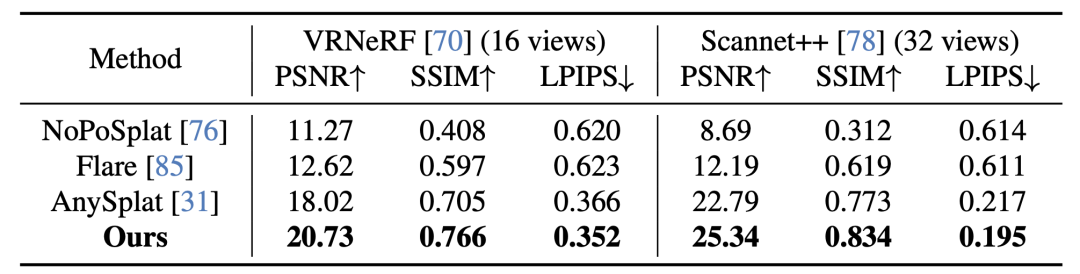
表 2: 与其他动态重建模型的定量比较。†:表示该方法以相机姿态作为输入。
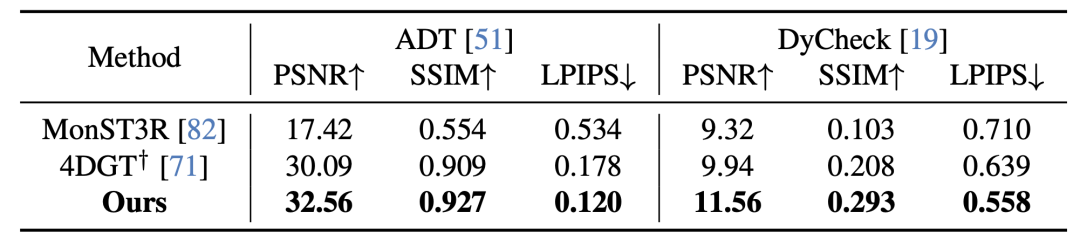
表 3 同时给出了重建与生成两个阶段的效率评估结果。生成过程可利用现成蒸馏技术实现显著加速;更重要的是,双向运动机制使得从稀疏关键帧中高效重建成为可能,且生成性能不受影响。
表 3: VBench 新视角生成结果。随机采集100个未见过的真实场景视频,每个视频包含4条不同的相机轨迹,共计400个测试案例。

论文代码已开源,感兴趣的开发者可以访问 GitHub 仓库 进一步研究。这是一个典型的利用海量单目互联网数据进行世界模型构建的优秀范例,其技术路径值得云栈社区的各位技术爱好者深入探讨和学习。 |  发表于 2026-3-19 07:10:42
|
查看: 441|
回复: 0
发表于 2026-3-19 07:10:42
|
查看: 441|
回复: 0
