当前,许多致力于“可动” AI 的研究都在尝试将真实世界映射为可复用的数字世界,期望模型能生成动态的 3D 场景并保持画面一致性(在云栈社区的技术讨论中,这类模型备受关注)。但多数 4D 世界模型存在依赖昂贵采集设备或复杂预处理的问题,难以大规模推广。中科院与 CreateAI 联合提出的 NeoVerse,利用 100 万段开放场景单目视频进行大规模训练,开辟了构建可扩展 4D 世界模型的新路径。
相关链接

论文介绍
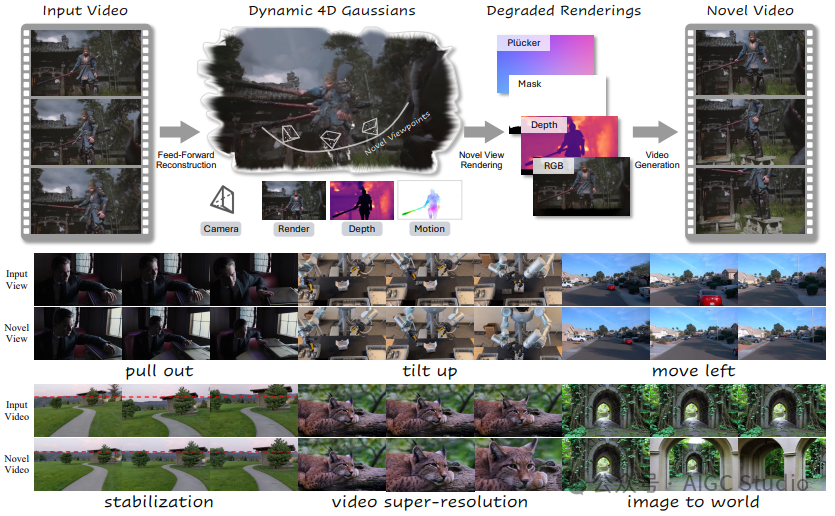
论文提出了名为 NeoVerse 的多功能 4D 世界模型,能够进行 4D 重建、生成新颖轨迹视频,并应用于丰富的下游场景。作者指出,当前 4D 世界建模方法普遍存在可扩展性限制——要么依赖昂贵且专门的多视角 4D 数据,要么需要繁琐的训练预处理。
相比之下,NeoVerse 基于一种核心理念构建,使整个流程能够扩展到各类真实场景的单目视频。具体来说,NeoVerse 采用了无需姿态的前馈 4D 重建、在线单目退化模式模拟等精心设计的技术。这些设计赋予了 NeoVerse 强大的通用性和泛化能力,使其能够应用于多个领域。同时,NeoVerse 在标准的重建和生成基准测试中取得了最先进的性能。
方法概述
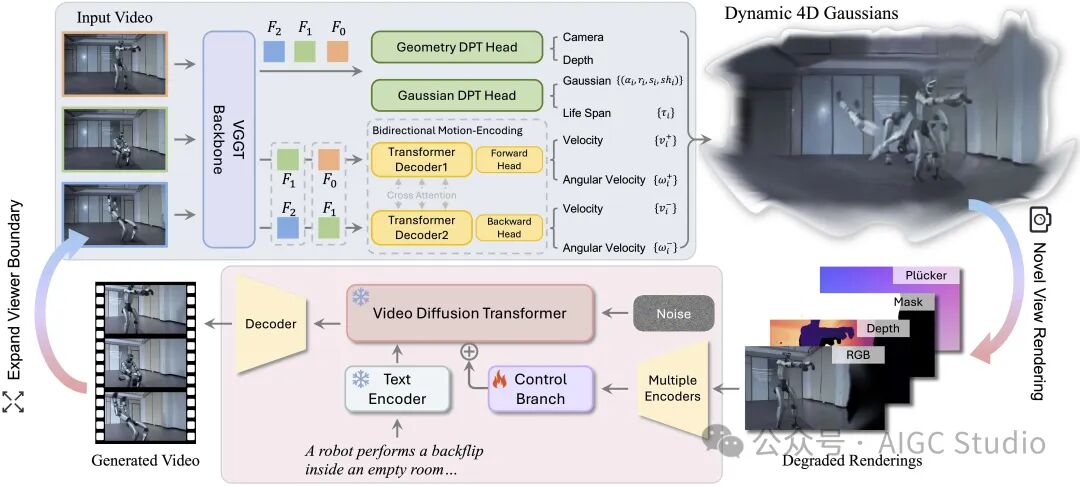
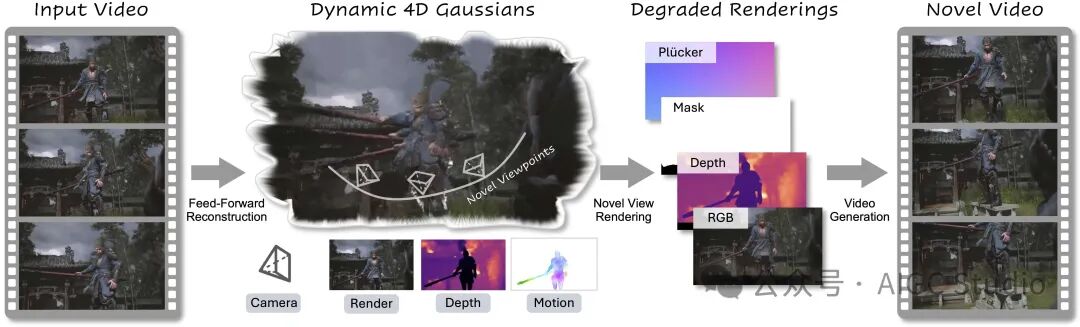
NeoVerse 框架在重建部分提出了一种无需姿态的前馈式 4DGS 重建模型,该模型采用双向运动建模。4DGS 在不同视角下的退化渲染结果作为条件输入到生成模型中。训练过程中,退化渲染条件通过单目视频模拟,而原始视频本身则作为目标。
实验结果

在具有挑战性的实拍视频中,利用大幅度的相机运动生成图像。我们将方法与相关工作进行比较,分别针对“向左平移”和“向右移动”的情况。NeoVerse 方法在保持精确相机控制的同时,实现了更高的图像生成质量(黄色方框突出显示了伪影)。

NeoVerse 可与功能强大的蒸馏 LoRa 集成,从而实现不到 30 秒的快速推理速度。运行时评估在单个 A800 GPU 上进行。
结论
论文介绍了一种名为 NeoVerse 的 4D 世界模型,它克服了以往模型的关键可扩展性限制,构建了一个可扩展至真实单目视频的训练流程。得益于此,NeoVerse 的泛化能力和通用性因丰富的真实数据而显著增强,从而能够应用于各种下游应用。大量实验表明,NeoVerse 在重建和生成任务中均取得了最先进的性能。
局限性:NeoVerse 需要具有正确底层 3D 信息的数据,因此不能直接应用于缺乏 3D 信息的场景(如 2D 卡通)。由于训练资源限制,当前精整理的数据集(100 万个视频片段)规模不算大,未来计划保留更多数据进一步扩展。 |  发表于 2026-4-27 02:07:15
|
查看: 139|
回复: 0
发表于 2026-4-27 02:07:15
|
查看: 139|
回复: 0
