本文讨论了一种名为 TVG 的创新方法,它能在不进行额外训练的前提下,利用扩散模型生成高质量的过渡视频。论文及代码均已开源:

研究背景:视频过渡的痛点
你是否想过,如何让两段差异巨大的视频片段实现丝滑、自然的衔接?传统视频变形技术往往效果生硬,缺乏艺术感,对创作者的技能要求也很高。
近年来,基于扩散模型的图像和视频生成技术为这个问题提供了新思路,通过生成中间帧来实现过渡。然而,当起始帧和结束帧在内容上存在显著差异时,现有方法常常力不从心,要么产生突兀的跳跃变化,要么只能生成平淡的淡入淡出效果,甚至会出现破坏画面的伪影。
核心挑战是什么?
视频过渡生成主要面临两大难点:
- 图像级模型的局限:直接扩展单图像扩散模型难以稳健地建模帧间关系。当画面主体变化很大时,这类模型虽然能避免剧烈跳变,但往往生成动态性不足的结果,比如简单的淡出效果。
- 视频级模型的瓶颈:专为视频设计的扩散模型通过时空注意力来建立帧间联系,但容易出现条件图像信息泄露、交叉注意力失效或注意力机制激活不当等问题,导致过渡不自然或生成异常内容。
TVG方法的精妙之处
这篇论文提出的TVG方法,基于开源的 DynamiCrafter 模型进行改进,无需重新训练,专门攻克上述难题。其核心在于对条件控制、潜在空间建模和特征融合三方面的优化。
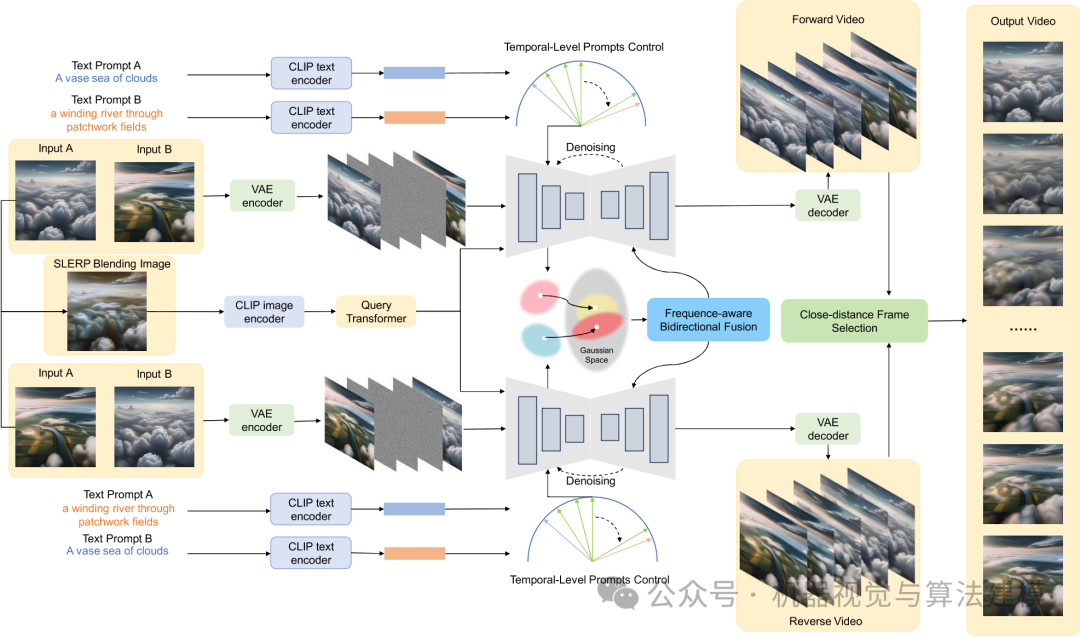
1. 条件控制优化
为了给模型提供更平滑的引导,TVG首先对输入的条件图像和文本提示进行插值处理:
- 图像条件:通过对起始帧(Input A)和结束帧(Input B)进行线性插值(SLERP Blending),生成一系列融合图像作为视觉条件。
- 文本提示:对描述两个场景的文本提示(Text Prompt A/B),同样使用时序级的球面线性插值(SLERP)来生成过渡的语义特征。
这样,模型在去噪过程的每一步,都能获得一个从起点平滑变化到终点的“路标”,从而引导生成连贯的中间帧。
2. 潜在空间高斯过程回归
这是TVG的一个关键创新。在模型U-Net的潜在空间中,TVG引入了高斯过程回归来显式地建模并约束帧与帧之间的关系。简单来说,GPR能够学习一个连续的分布函数,预测出某一帧在给定其前后帧特征时应有的样子。公式(9)展示了如何将GPR预测的帧间关系融入到注意力机制中,从而确保生成的视频序列在内容上保持连贯和平滑演进。
3. 频率感知双向融合
TVG同时生成“从前向后”和“从后向前”两个过渡视频序列。然后,在潜在空间中使用上述GPR方法对这两个序列的特征分布进行对齐。最后,通过一个频率感知的双向融合模块,将两个序列的低频(结构、轮廓)和高频(细节、纹理)信息智能地结合起来,生成最终的视频。公式(10)描述了这一融合过程,确保了输出视频兼具时序平滑性和丰富的视觉细节。
实验结果与对比
研究在 MorphBench 和 TC-Bench-I2V 两个数据集上进行了验证。实验使用预训练的 DynamiCrafter 模型作为基线,主要超参数保持默认,视频帧率设为16,在单个NVIDIA A800 GPU上运行。
在 TC-Bench-I2V 数据集上的定量评估结果如下表所示(TCR和TC-Score越高越好)。TVG方法在属性过渡和物体关系变化场景中表现最优,在背景转换场景中也取得了极具竞争力的成绩。

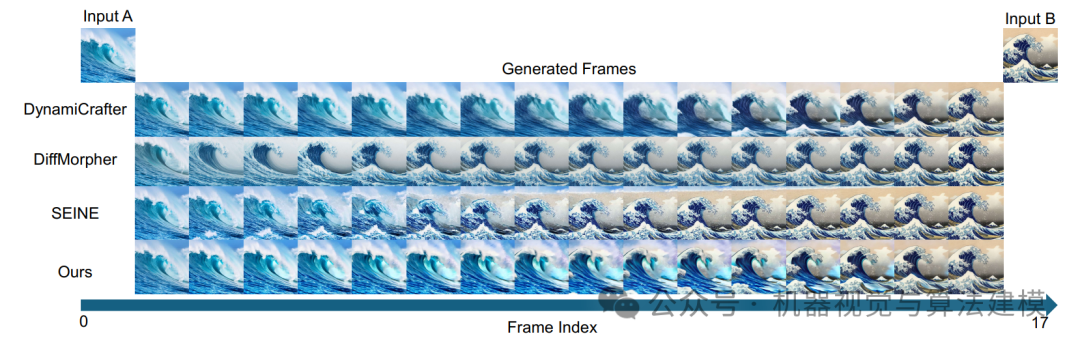
视觉效果对比更能说明问题。下图展示了在“杯子图案化”和“折纸”任务上,TVG与其他先进方法的生成结果。可以看到,TVG生成的过渡序列更加平滑自然,没有明显的跳变或伪影。

另一组对比(下图)展示了从真实海浪到名画《神奈川冲浪里》风格的艺术化过渡。TVG生成的序列在保持海浪形态的同时,色彩和笔触风格实现了流畅渐变。
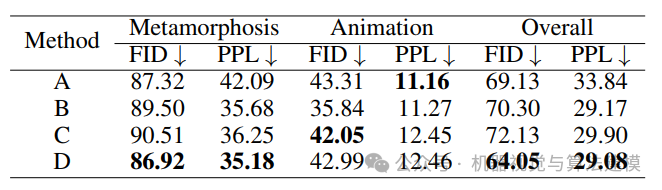
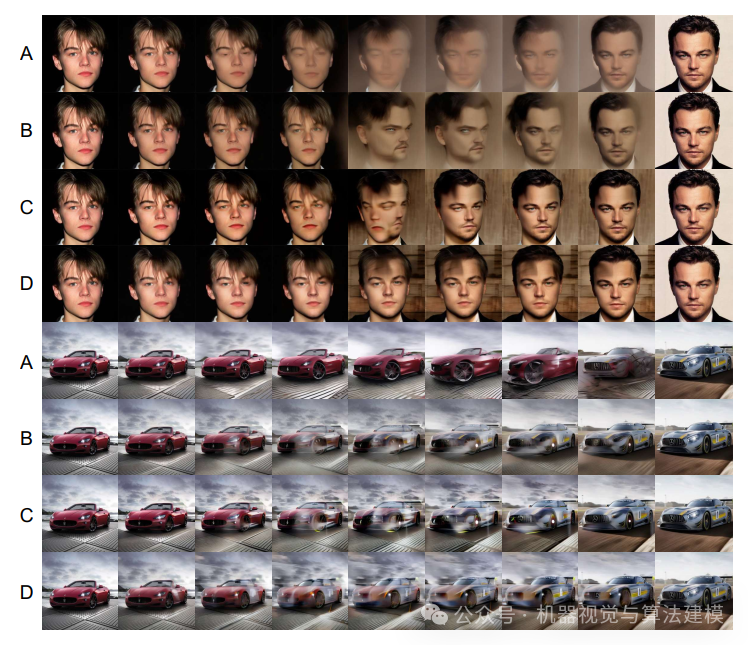
消融实验进一步证实了每个组件(条件插值、GPR、双向融合)的有效性。如下表和下图所示,完整版的TVG在关键指标上显著优于基线及其他变体。
总结与展望
总而言之,TVG提出了一套巧妙的无训练方案,通过插值条件控制、潜在空间高斯过程回归和频率感知双向融合,有效解决了扩散模型在生成高差异帧间过渡时的难题。实验表明,该方法在定量指标和视觉质量上均优于现有模型,特别是在动态场景中能产生更平滑、连贯的过渡效果。
这项工作为视频编辑和创意生成领域提供了一个强大且易用的工具。未来的研究可以探索如何利用整个视频片段而不仅仅是起止两帧的信息,以实现更长、更复杂场景之间的无缝过渡。对这类生成式AI技术感兴趣的朋友,欢迎在云栈社区的智能数据与云板块进行深入讨论。 |  发表于 2026-4-11 08:42:17
|
查看: 157|
回复: 0
发表于 2026-4-11 08:42:17
|
查看: 157|
回复: 0
