如果能在计算机里模拟一个细胞,告诉它“把这个基因敲掉”或“加这种药物”,它就能预测出所有大约18000个基因的表达会如何变化——这对药物研发意味着什么?这意味着可以省去真实实验、无需培养细胞、不用等待数周才能得到结果,一切都能直接通过计算获得。
这听起来是不是有些科幻?但这正是“虚拟细胞”技术努力实现的目标,而阿里巴巴达摩院最新发布的 Lingshu-Cell 模型正朝着这个方向迈出了坚实的一步。该模型在 Virtual Cell Challenge (VCC) H1 排行榜上取得了第一名,而其训练数据仅使用了约60万个细胞。
图:Lingshu-Cell模型数据处理框架示意图。
问题挑战:为何单细胞生成如此困难?
单细胞RNA测序(scRNA-seq) 是当前生物学最强大的工具之一。它能够一次性测量单个细胞中几乎所有基因的表达水平——大约18000个基因,每个基因都有一个计数值。然而,这些数据存在几个固有的难题:极其稀疏(大量基因的表达量记录为零)、离散(基因计数是非负整数)以及无序(基因之间没有天然的排列顺序)。
预测的目标是:如果对特定类型的细胞施加某种干预(例如敲除一个基因或添加一种细胞因子),这18000个基因的表达量将如何精确变化?这不仅仅是简单的“上调或下调”判断,而是需要预测所有基因的完整分布变化。
现有方案的局限与困境
目前,该领域主要有三类方法,但各有其局限性:
- 大模型(Foundation Model)路线:如 scGPT、Geneformer。它们在大量单细胞数据上进行自监督预训练,能够学到良好的细胞表示。但这些模型本质上是分类和嵌入模型,而非生成模型——它们擅长为细胞“画像”,却难以创造出一个逼真的“虚拟细胞”。
- 连续生成模型路线:如 scDiffusion、scVI。它们能够生成转录组数据,但使用的是连续的高斯噪声。问题在于,单细胞数据本质上是离散且极度稀疏的,用连续噪声去建模,就像用水彩去画油画,工具与材料并不匹配。
- 扰动预测专用模型:如 CellFlow、AlphaCell。它们直接学习从“正常细胞”到“扰动后细胞”的映射。虽然效果尚可,但这些模型并不建模底层的细胞状态分布,因此当遇到全新的扰动条件时,其预测能力可能会失效。
Lingshu-Cell的核心思路:让模型适配数据特性
Lingshu-Cell 的核心洞见非常直接:单细胞数据的三大特性——离散、稀疏、无序——恰好适合用 掩码离散扩散(Masked Discrete Diffusion) 模型来建模。
什么是掩码离散扩散?你可以把它想象成一个拼图游戏。前向过程 是将一个完整的拼图(即一个细胞的全部基因表达值)随机地一块块遮住,直到全部遮盖。反向过程 则是模型学习如何一块块地揭开这些遮盖,最终恢复出完整的拼图。
这种方法的优势何在?
- 相比自回归模型:自回归模型需要预先设定一个固定的基因预测顺序(例如先预测基因A,再预测基因B),但基因之间本就没有天然的先后顺序。Lingshu-Cell 的掩码扩散则无需此假设。
- 相比连续扩散模型:连续扩散是向所有位置添加连续的噪声,但基因计数是离散的整数,添加连续噪声本身就显得不够自然。离散扩散直接操作离散的 token,与数据特性更为匹配。
在具体实现上:模型首先将每个基因的表达量离散化为 token(通过分桶操作),然后训练一个 Transformer。这个 Transformer 的输入是部分被掩码的基因 token 序列,其任务是预测所有被掩码位置的基因表达值。在进行条件生成(如预测特定扰动效果)时,只需将细胞类型和扰动条件作为额外的嵌入向量注入模型即可。
整个过程无需预先筛选基因,而是对全部约18000个基因进行联合建模。这在先前的方法中较为少见——大多数方法会先挑选“高变异基因”再进行建模,但这样可能会丢失许多潜在的重要生物信息。
实验结果:性能表现卓越
1. 无条件生成:创造逼真的虚拟细胞
在无条件生成任务中,Lingshu-Cell 的表现非常出色。其生成的虚拟细胞在 UMAP 降维可视化图上与真实细胞几乎完全重叠——不仅主要细胞类型(如 T细胞、B细胞、单核细胞)能够对应,连细分亚型的比例也高度一致。该能力在9种人类组织和4个不同物种(包括小鼠、恒河猴、斑马鱼和果蝇)的数据上都得到了验证。
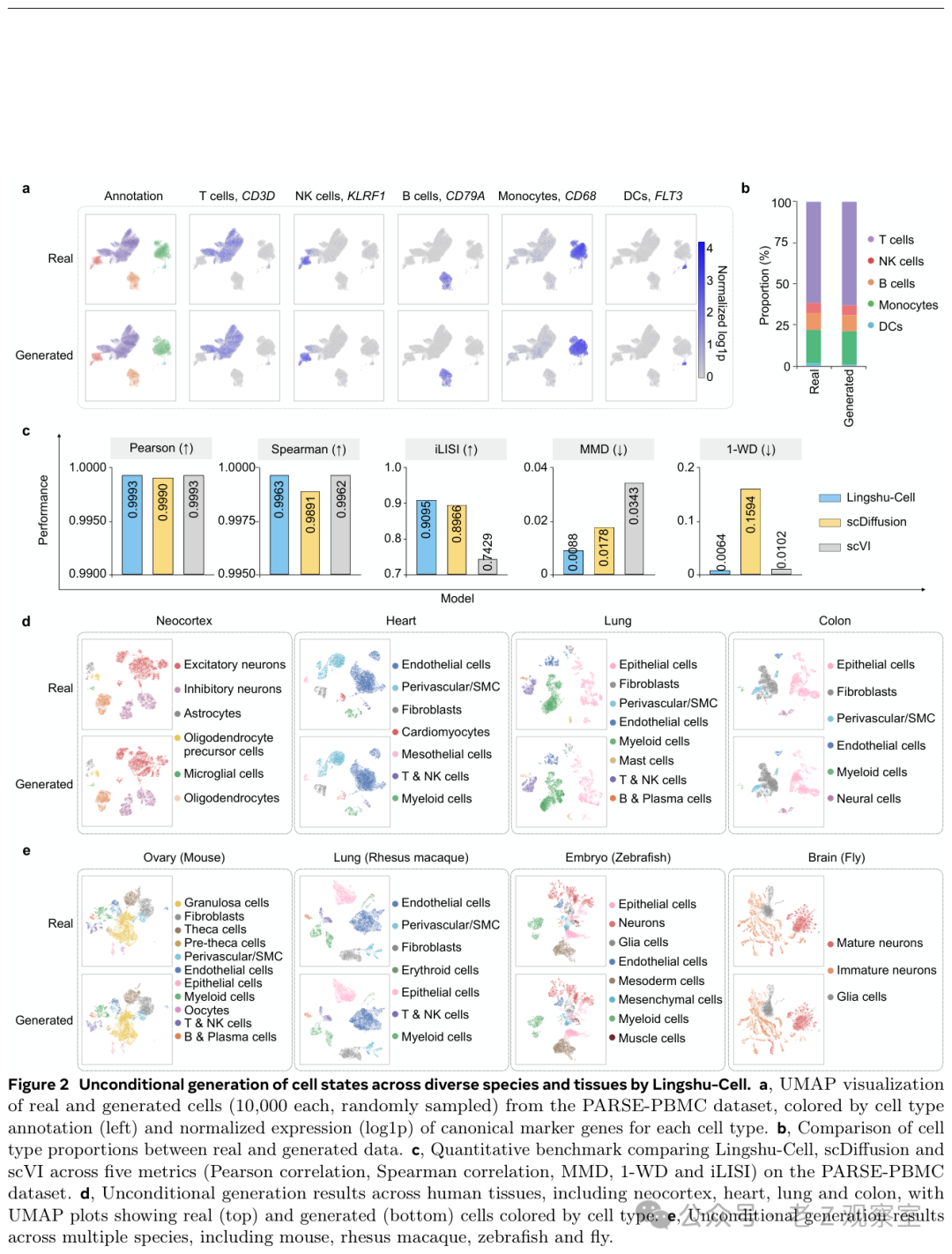
图:真实细胞(上)与 Lingshu-Cell 生成虚拟细胞(下)的 UMAP 可视化对比。各细胞类型的空间分布高度一致。
2. 基因扰动预测:VCC 排行榜夺冠
更具说服力的是其在扰动预测任务上的表现。在 Virtual Cell Challenge (VCC) H1 基因扰动预测排行榜 上,Lingshu-Cell 成功斩获第一名。该挑战赛要求模型预测特定基因被敲除后,细胞转录组的整体变化,任务难度极大。
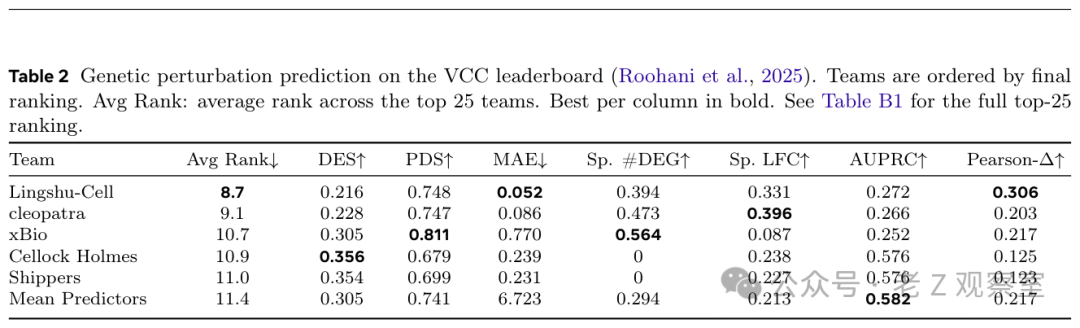
表:Virtual Cell Challenge H1 排行榜,Lingshu-Cell 以领先优势排名第一。
3. 细胞因子扰动预测:强大的泛化能力
模型在细胞因子扰动预测任务上同样表现优异。它能够准确预测此前从未见过的“细胞类型+扰动条件”组合所产生的转录组响应——这表明模型学习到的并非简单的数据记忆,而是某种具有可迁移性的细胞响应规律。
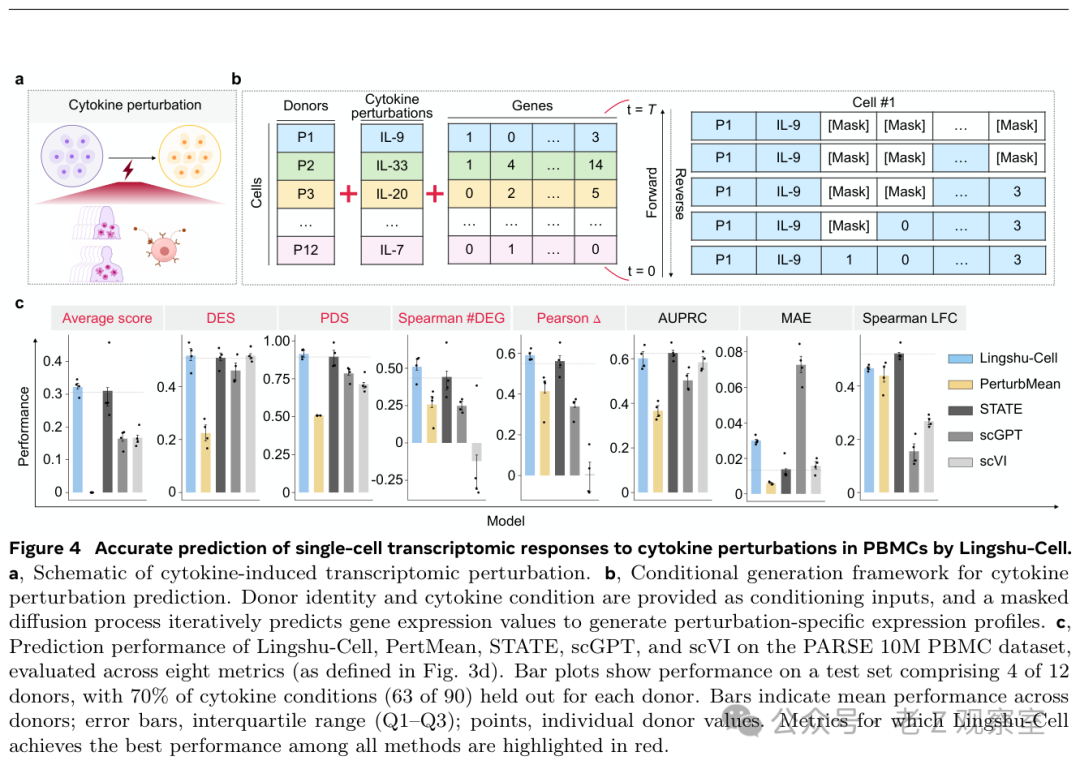
图:Lingshu-Cell 在 PBMC 细胞因子扰动预测中的框架与结果,其在新组合上仍能给出准确预测。
展望与思考
这项研究的定位非常清晰:它并非旨在打造最好的细胞分类器或基因网络推断工具,而是致力于构建一个“细胞世界模型”——一个能够理解细胞状态分布、并能模拟干预后变化的系统。这个方向如果最终取得成功,对于加速药物研发和推动精准医疗的价值将不可估量。这类复杂系统的仿真与预测,正是当前 人工智能 与 智能 & 数据 & 云 技术交叉应用的前沿领域。
当然,目前模型也存在明显的局限性。它仅建模了转录组层面(RNA)的信息,而真实的细胞还包含蛋白质、表观遗传等多层面的复杂调控。此外,训练数据中存在的批次效应和技术噪声也可能对生成质量产生影响。
从 AI 技术的角度看,掩码离散扩散模型 在这一特定场景下展现出了极高的适配度——用离散扩散处理离散数据,用掩码机制代替自回归以应对无序性。这种“让模型架构主动适配数据特性”的设计哲学,非常值得其他领域的研发者借鉴。
相关资源
对单细胞分析与生成式AI的交叉应用感兴趣?欢迎到 云栈社区 的对应板块与更多开发者交流探讨。
 发表于 2026-4-4 08:08:31
|
查看: 704|
回复: 0
发表于 2026-4-4 08:08:31
|
查看: 704|
回复: 0
