离散token路线在多模态领域,一直以来给人的印象都是“理论很美,实践拉胯”。这个idea本身没人质疑——把图片、声音、文字都变成一串离散的符号,丢进同一个自回归模型里,用同一个“预测下一个token”的目标来训练。听起来优雅、统一、简洁。但一到实际评测的benchmark上就容易露馅:图片理解能力常常比不上使用连续特征的方案,生成质量也追不上专门的扩散模型。
不过,最近HuggingFace上出现了一篇来自美团的论文LongCat-Next,其GitHub仓库半天就收获了近300星。仔细看完后,我觉得这次离散token路线可能真的到了要翻身的时候。
当前多模态路线的两难困境
要理解这次突破的意义,得先看清背景。现在的多模态大模型基本在走两条路。
第一条是“连续特征”路线:用CLIP或SigLIP这类模型把图片编码成连续的向量,再通过一个投影层塞进语言模型里。像Qwen-VL、LLaVA、InternVL都是这个思路。好处是图片理解能力强,坏处是模型通常只能“看”不能“画”,想要生成图片还得额外接一个扩散模型。
第二条就是“离散token”路线:用VQ-VAE这类方法把图片量化成离散的token,然后跟文字token放在一起进行自回归建模。像Chameleon、Show-o走的就是这条路。理论上,一个模型就能同时理解和生成,非常诱人。但实际效果一直有个难以突破的性能天花板——因为离散化的过程往往丢失了太多视觉细节信息。
这就陷入了一个两难:想要架构统一、能力全面,就得牺牲单项性能;想要单项性能出色,就得把各种专用模块拼装起来。我一直觉得这个困境迟早会被打破,问题就在于由谁、用什么方式来实现。
早期离散方案的核心缺陷
离散token路线的核心问题其实就两个,但之前很多工作往往只解决了一个。
第一个是语义表达不够。早期的视觉分词器(Tokenizer),比如VQGAN,是从像素重建的角度训练的。它们学到的token更多是代表底层的纹理和颜色信息,缺乏高层的语义概念。用这种token去做视觉问答,模型可能根本“看不懂”图片在表达什么。
第二个是量化过程信息损失太大。把连续的视觉特征硬塞进一个有限的码本(codebook)里,必然会丢失信息。码本太小,信息丢得多;码本太大,模型又训练不好。这几乎是一个根本性的矛盾。
过去的方案要么换个更好的编码器(解决第一个问题),要么使用更大的码本(试图缓解第二个问题),但很少有人能同时把两个问题都解决到位。
LongCat-Next的创新:dNaViT视觉分词器
LongCat-Next的核心创新在于一个叫做dNaViT的视觉分词器。全称是Discrete Native Any-resolution Visual Transformer,名字很长,但背后的想法其实很直观。
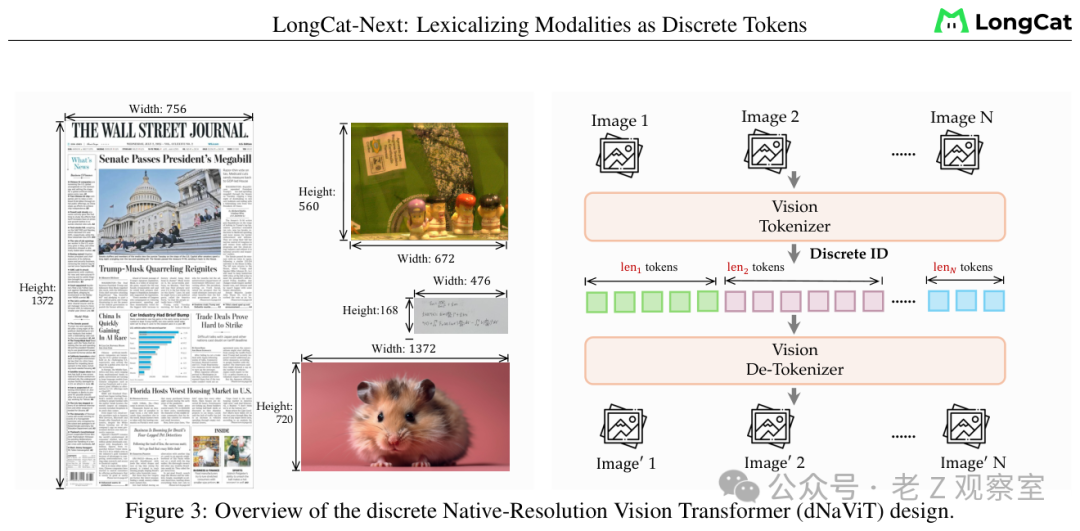
图:dNaViT的设计细节。编码端用SAE + RVQ进行多层量化,解码端用DepthTransformer高效还原图像。
先看他们如何解决语义不足的问题。团队没有从零开始训练一个视觉编码器,而是直接拿SigLIP——一个已经在海量图文对上预训练好的模型——作为基础。SigLIP本身就具备很强的图文语义对齐能力。更有趣的是,他们发现了一个隐藏的好处:SigLIP的残差连接结构天然保留了低层视觉信息的传播通路。这意味着,即使这个编码器没有被明确训练去做像素级的重建,其内部依然“藏着”足够的细节信息。
再来看如何应对量化损失。他们采用了残差向量量化(RVQ)。这不是一次性把特征量化到一个码本里,而是分多层、循序渐进地来做。第一层捕获最主要的视觉信息,第二层捕获第一层量化后的残差信息,第三层再捕获第二层的残差,如此层层叠加。这就像画一幅画:先打草稿定大体轮廓,再加一遍细节,最后再点缀更细微的笔触。最终的信息损失,远小于传统的单层量化。
在自回归建模阶段,如何处理多层RVQ产生的token呢?他们的做法很巧妙:将多层token通过加法编码合并成一个统一的embedding。这样,在模型进行“预测下一个token”时,只需要一步自回归(而不是为每一层分别预测),计算效率和预测单层token是一样的。在需要解码还原图像时,则使用一个轻量级的DepthTransformer把合并的embedding拆解回多层token。
整个模型的主干(Backbone)是一个基于MoE架构的Decoder-Only Transformer。文字、图片、音频的离散token全部共享同一个embedding空间,用同一个自回归目标进行训练。不同模态之间不需要任何额外的适配器,实现了真正的统一建模。
音频部分的处理思路也类似:基于Whisper编码器,用RVQ把音频信号压缩成12.5Hz的离散token,解码端则用流匹配(Flow Matching)进行高保真重建。
用实验数据说话
在看数据之前,需要明确一个前提:LongCat-Next是一个“统一模型”——同一个模型同时负责理解(看、听)和生成(画、说)。与它对比的选手,既包括专门做理解的模型(如Qwen2.5-VL、InternVL3),也包括专门做生成的模型(如FLUX、DALL-E 3),这些都是只精通一门的“专家”。
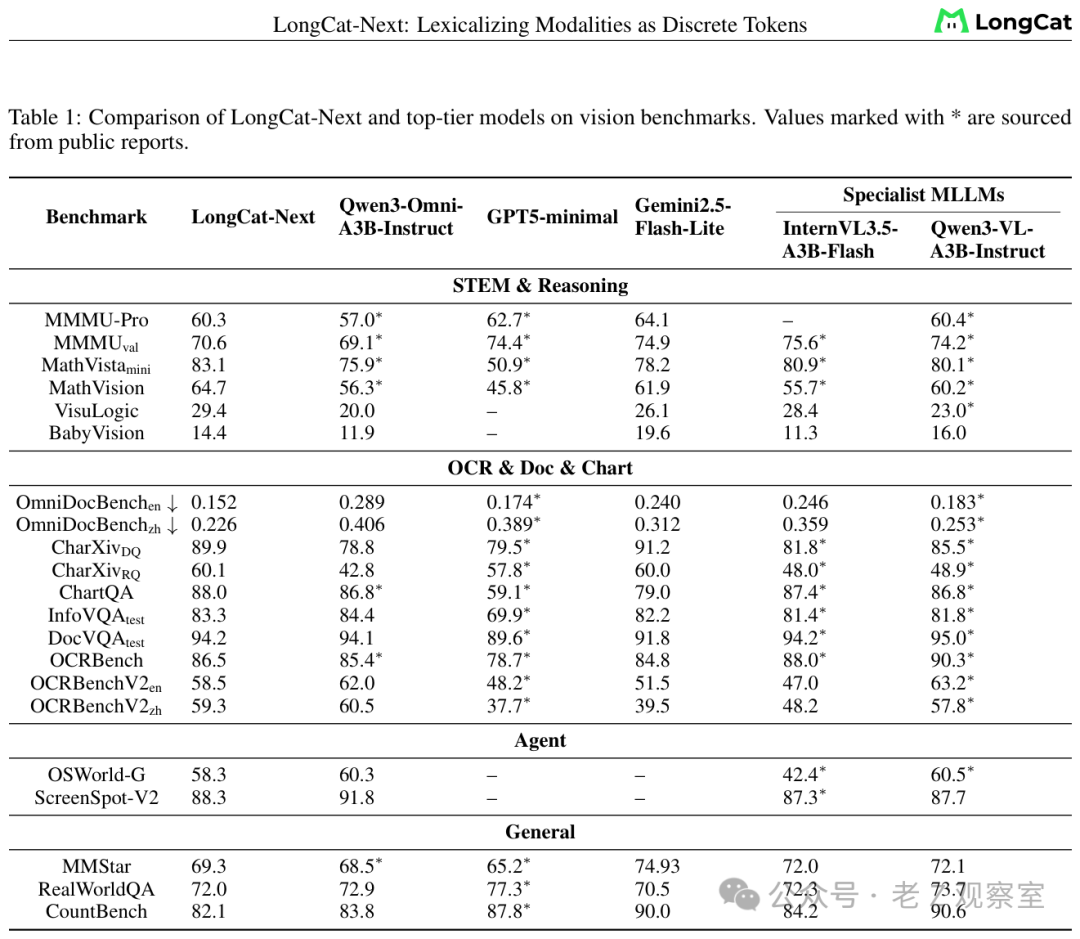
表:视觉理解benchmark对比。LongCat-Next作为统一模型,与专门的理解模型打得有来有回。
在视觉理解任务上,LongCat-Next的表现与Qwen2.5-VL-72B这类专业理解模型基本处于同一级别。这对于离散token路线来说,是一个重要的里程碑——因为以往的离散方案在理解能力上通常要比连续特征方案落后好几个百分点。
在图片生成质量上,其在GenEval和DPG-Bench等基准上的分数,已经接近FLUX、DALL-E 3这些专用生成模型。考虑到这只是统一模型的一项“副业”,这个成绩已经相当亮眼。
最能说明问题的是下面这张与其他统一模型的全面对比表:
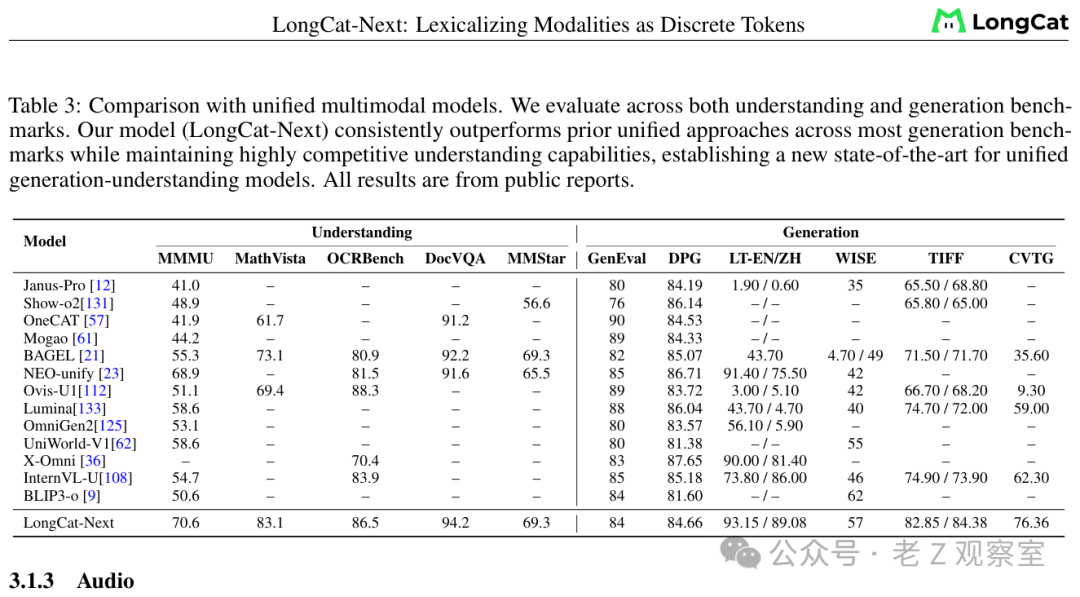
表:与Janus-Pro、TokenFlow等其他统一多模态模型的全面对比。LongCat-Next在理解和生成两端均取得领先。
与Janus-Pro、TokenFlow、EMU3等其他旨在统一理解和生成的研究相比,LongCat-Next在理解和生成两端都实现了领先,并且没有出现明显的“跷跷板”效应——即没有为了提升生成能力而牺牲理解能力,或者反过来。
在消融实验中还有一个非常有意思的发现:离散方案和连续方案在预对齐阶段的损失曲线差距其实非常小。这说明离散token本身的信息容量并不像大家之前认为的那么有限。之前的性能差距,更多是分词器(Tokenizer)设计的问题,而不是“离散化”这条技术路线本身有问题。
观点与展望
“万物皆Token”的统一建模范式,正在成为多模态领域的主流趋势。据传GPT-4o也在朝这个方向演进,Google的Gemini同样在探索原生多模态。LongCat-Next的价值在于,它用工业级的实验规模和扎实的数据,证明了离散token路线不仅可行,而且能达到很高的性能水平。更重要的是,团队将模型和分词器都进行了开源,为社区提供了宝贵的基线。
当然,挑战依然存在。Tokenizer的质量要求被提到了一个极高的位置,整个系统的性能天花板很大程度上被它锁死。而训练一个好的多模态Tokenizer本身就是一件重资源投入的事情,这意味着短期内可能只有大型机构有能力进行复现和改进。
此外,模型目前在实时语音交互方面还有提升空间,音频生成的速度和质量与GPT-4o的语音模式相比仍有差距。但这更多是工程优化和算力投入的问题,在技术方向上并不存在硬性障碍。
总的来说,这篇工作将离散token路线从“概念验证”阶段推进到了“工业可用”的阶段。其开源举动尤为重要,它为学术界提供了一个可靠且高性能的基线,从而能激发更多后续的深入研究。
相关资源链接:
 发表于 2026-4-4 08:11:09
|
查看: 157|
回复: 0
发表于 2026-4-4 08:11:09
|
查看: 157|
回复: 0
