今天在浏览学术动态时,一篇名为FIPO的论文引起了我的注意。第一眼看去,它似乎又是一个关于训练技巧的微调工作?但深入研究其实验后,我发现远不止于此。这篇文章指出了一个非常实际的问题:我们总在追求模型“更会推理”,但在训练过程中,对每个token的奖励分配往往过于粗糙,导致关键推理步骤和填充性废话常常得到同等对待。这可能导致模型虽然输出了很长的思考链,却未必在真正关键的地方想明白。
FIPO的核心思想可以用一句话概括:奖励不再平均发放,而是评估每个token对未来推理路径的引导作用。
其结果相当扎实:在Qwen2.5-32B模型上,该方法将AIME 2024基准测试的Pass@1准确率从50%提升到了峰值58%,同时将平均推理长度从约4000个token显著拉升至10000个以上。
问题的症结何在
首先明确场景。对于AIME这类复杂问题,模型并非“灵光一现”给出答案,而是需要构建一个很长的推理链(Chain-of-Thought)。训练过程中的最大难点在于:如何准确评估序列中每个token的贡献。
过去常见的做法更接近“整段结算”:如果最终答案正确,整段推理都获得奖励;如果错了,整段都被扣分。这种方式实现简单,但它默认了一个不切实际的假设:每个token同等重要。
现实情况是,决定推理走向的关键转折点可能只有寥寥数个token。正是这些关键节点,决定了后续思路是走向正轨还是一路偏航。如果将这些关键token与大量普通的填充性token混在一起进行训练,模型很容易陷入一种“看起来在思考,实际上在绕圈子”的状态。
这实际上是强化学习用于推理任务中的一个老问题:训练信号过于粗糙,导致模型学会了“延长输出”,却没能学会“在关键分叉处做出正确选择”。
既有方法的瓶颈
GRPO、DAPO等路线已经证明了纯强化学习能够有效提升模型的推理能力。但随着训练的深入,通常会遇到两个明显的瓶颈:
第一,推理长度增长到某个阶段后便停滞不前。
第二,精度提升变得越来越困难。
其核心原因并非模型不具备生成长文本的能力,而在于信用分配(Credit Assignment)的粒度不足。奖励在序列中的分配过于平均,使得真正关键的逻辑步骤无法获得应有的权重强化。
这好比团队复盘:项目成功,所有人得到相同奖励;项目失败,所有人受到同样处罚。这样的制度固然简单,但很难识别并强化那些真正决定成败的关键行为。
FIPO 的核心思路
FIPO的思路非常直接:一个token的价值,应取决于它对后续整个推理轨迹的影响,而不仅仅是它当前这一步的表现。
具体而言,该方法将“未来轨迹影响”量化为一个可用于训练的信号,并用这个信号来调节token级别的优势函数(Advantage)。如果后续轨迹被证明是正向强化的,那么当前token的更新强度就会增大;如果后续轨迹明显走向错误,对应的更新权重就会被抑制。
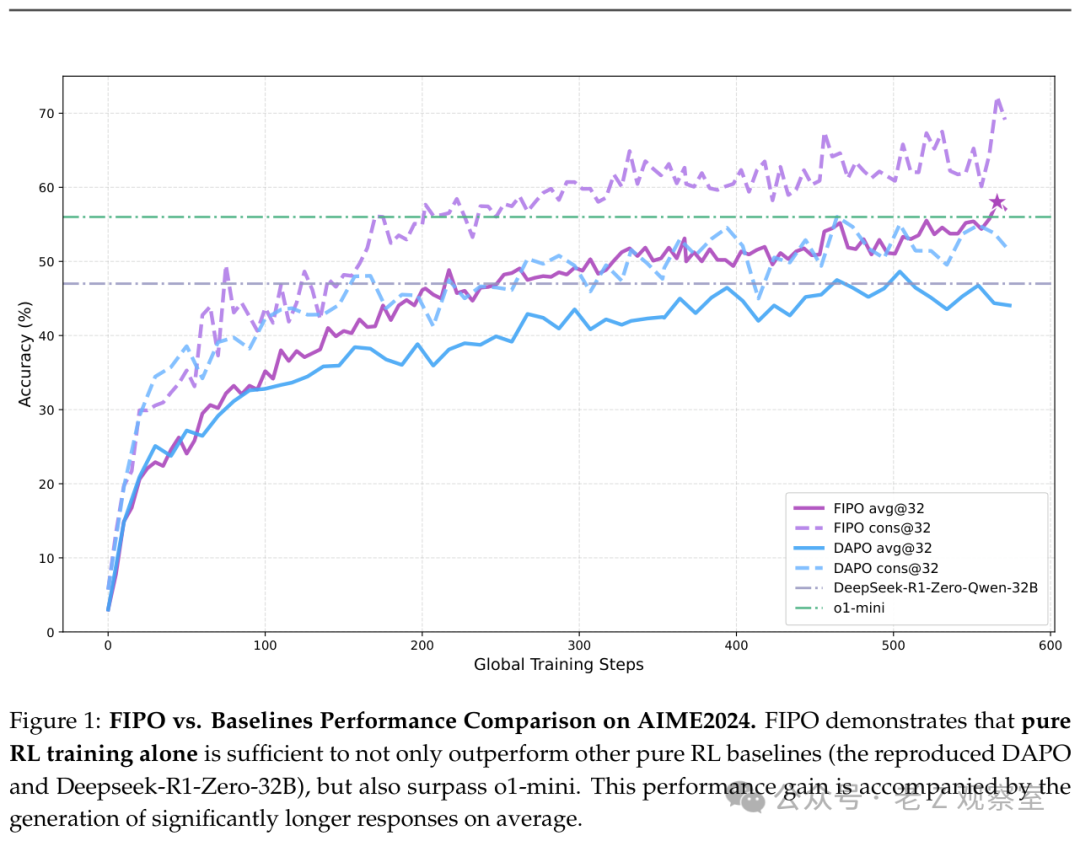
图1:FIPO与基线方法在AIME2024上的对比。关键看点在于,纯RL路线在复杂推理任务上仍有显著的性能提升空间。
这个方法最巧妙之处在于,它并未试图推翻整个训练框架,而是精准地改进了“奖励如何落实到每个token上”这一环节。改动点并不花哨,却直击要害。
当然,引入这种前瞻性信号会带来副作用:极易导致训练方差剧增。作者也承认,早期版本在训练中期会出现明显的不稳定性。因此,他们增加了多层保护机制:
- 软衰减窗口:使更远的未来影响权重自然递减。
- 影响权重截断:防止极端样本将梯度带偏。
- 异常比率过滤:避免训练被少数噪声样本主导。
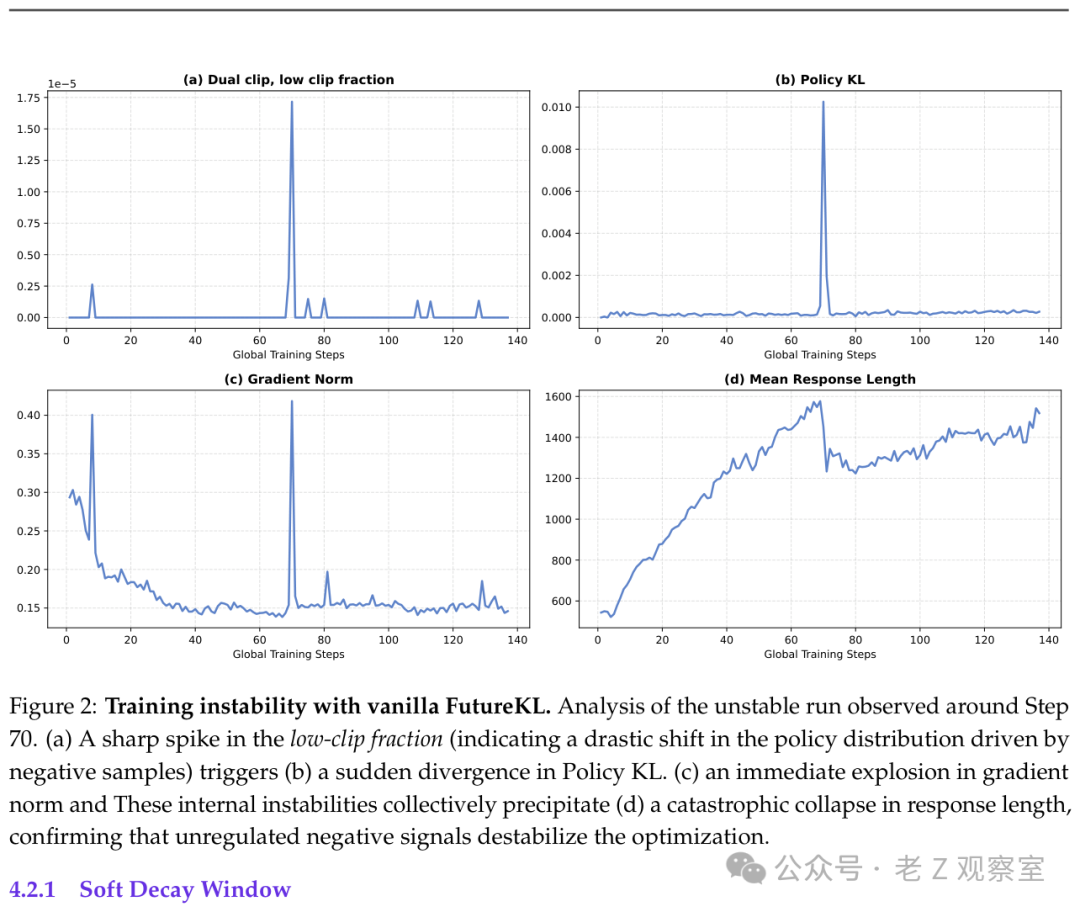
图2:未添加稳定化机制时,策略漂移、梯度异常和响应长度崩塌会连锁发生。
这组设计给我的感觉是“工程感很强”:它不单纯追求理论上的优美,而是明确着眼于解决实际训练中的可行性问题。
关键实验结果
1. 性能指标的显著提升
主要结果中,Qwen2.5-32B模型在AIME 2024的Pass@1准确率从50.0%提升至峰值58.0%,收敛稳定在约56.0%。这个提升幅度在高分段模型竞争中意义重大,尤其是在众多方法都在探索类似RL配方的大背景下。

表1:AIME 2024/2025基准测试的关键结果对比,FIPO在核心指标上保持领先。
2. 长度与精度同步增长
在很多情况下,“输出更长”并不等同于“推理更正确”。而这项工作的难得之处在于,模型输出长度分布整体上移的同时,准确率曲线也同步上行。平均推理长度从约4000 token增长到10000+,并且这不是偶然的波动,而是一个持续的、阶段性的演进过程。
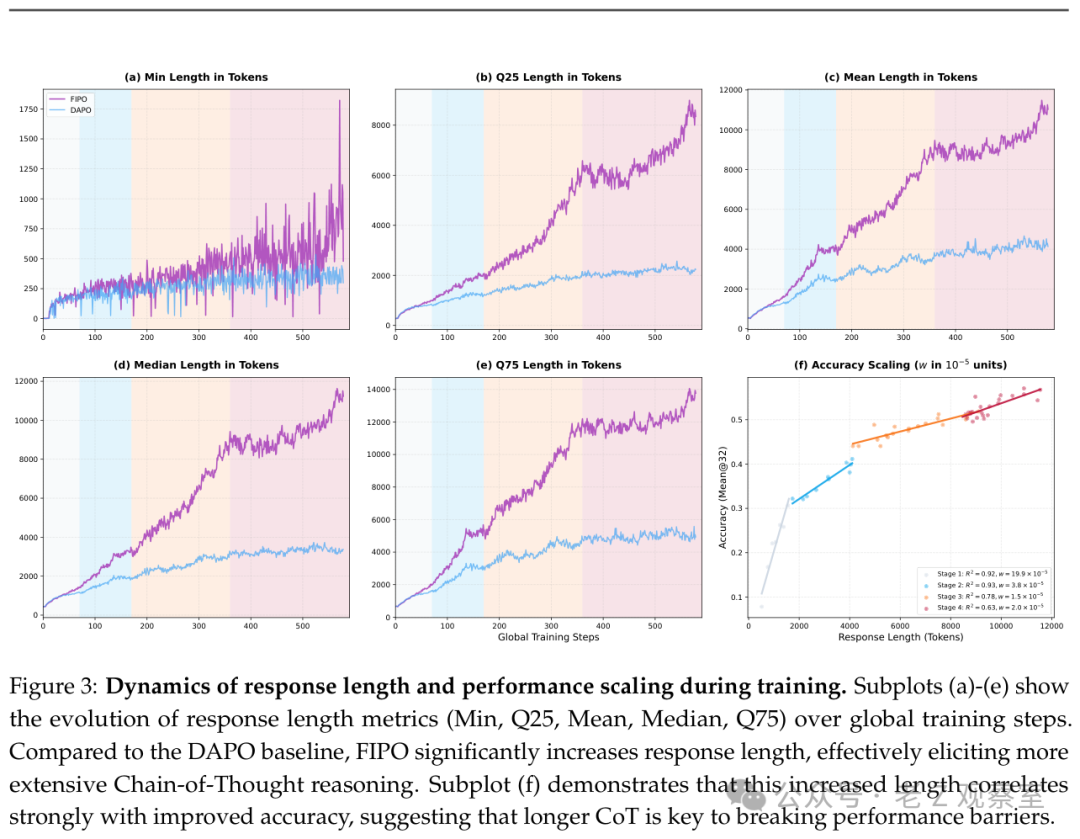
图3:多个长度分位数指标与准确率随训练步数共同上升,表明更长的推理链与更高的准确率强相关。
3. 推理行为的质变
论文在附录中提供了分阶段的案例研究,展示了模型从早期的浅层规划,到中期出现自我反思,再到后期能更系统地校验中间结论的演变过程。这一点至关重要,它说明FIPO带来的改变不仅仅是“输出变长了”,而是推理过程的组织方式发生了根本性变化。
观点与展望
在我看来,这项工作最值得关注的点并非58%这个具体数字,而是它正式将“未来轨迹影响”纳入了token级别的信用分配机制。这个方向如果持续深化,很可能成为下一代基于强化学习的推理训练方法中的通用组件。
当然,其局限性也很现实:
- 训练成本高昂:32B级别的模型训练非大多数团队所能轻易复现。
- 任务范围有限:目前验证仍偏重于数学推理,其在代码生成、智能体(Agent)规划、工具调用等更广泛领域的收益仍需更多公开结果验证。
- 稳定性依赖调参:方法的稳定性对超参数较为敏感,迁移到不同任务或模型时需要精细调整。
但就“精准打击技术卡点”而言,FIPO是成功的。以往许多工作侧重于“让模型思考更久”,而FIPO更像是在探索“让模型在该深入思考的地方想得更深”。我个人更认同后者的路径。
如果你关注强化学习在模型训练中的应用前沿,这篇论文值得细读。它并不追求形式的华丽,却很可能是未来诸多方法会借鉴的一块关键底层拼图。对这类前沿技术实践感兴趣的开发者,也可以在云栈社区找到更多相关的深度讨论和资源分享。
 发表于 2026-4-4 08:13:16
|
查看: 129|
回复: 0
发表于 2026-4-4 08:13:16
|
查看: 129|
回复: 0
