传统TTS系统需要先把音频切成离散token,这个过程就像处理一张数码照片时强行降低它的颜色深度,不可避免地会丢失高频细节和细腻的音色纹理。VoxCPM2带来的核心突破,是绕过了这个离散化的步骤,直接操作连续的声学特征,从而在声音克隆的保真度上实现了质的飞跃。
技术架构深度解析
VoxCPM2基于一个创新的扩散自回归架构,完全在AudioVAE V2的潜在空间中运行。其四阶段流水线 LocEnc → TSLM → RALM → LocDiT 构成了一个高效的生成引擎,让模型能够直接输出48kHz的高质量原生音频,无需依赖任何外部上采样器。这种端到端的设计简化了流程,也减少了信息损失。
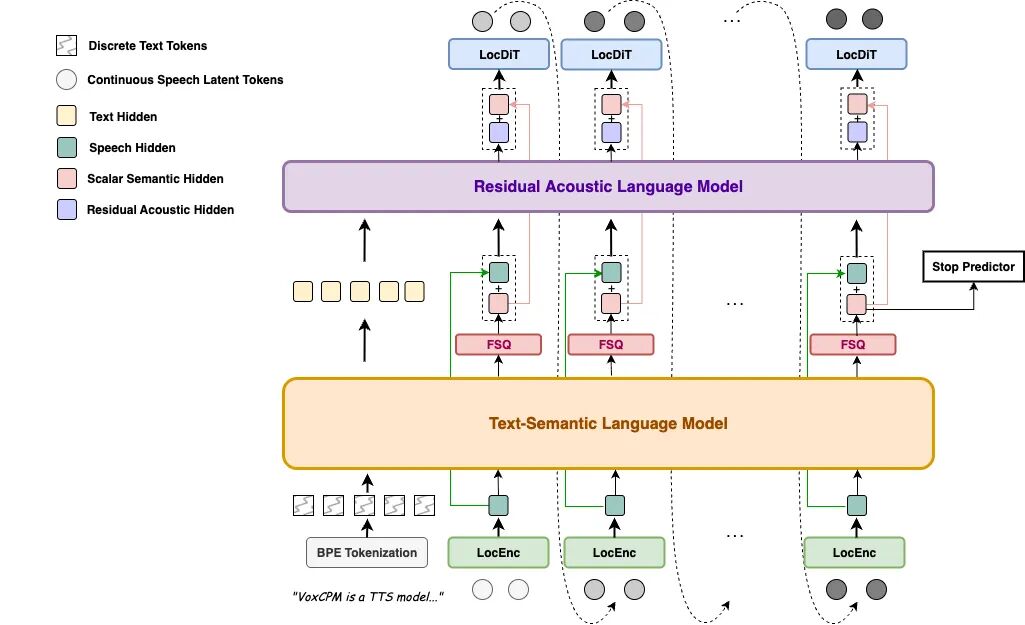
它的技术指标相当硬核:
- 20亿参数模型,在200万小时的多语言数据上训练而成。
- 支持30种主流语言,包括英语、中文、日语、德语、阿拉伯语等。
- 内置9种中文方言支持,如四川话、粤语、吴语、东北话等。
- 在RTX 4090上实现实时率0.13,支持流畅的流式输出。
- 可通过自然语言描述生成全新音色(例如:“30岁男性,略带沙哑的播音腔”)。
- 在克隆声音时,能够精确复刻并控制原声的呼吸节奏和个人口癖。
三种克隆模式的差异
项目贴心地提供了三种不同精度和用途的语音克隆方式,你可以根据需求选择:
- 语音设计:无需任何参考音频,仅通过文字描述就能创造出全新的、符合要求的声音。
- 可控语音克隆:基于一段参考音频克隆音色,同时允许你自由调节语速、情感等参数。
- 终极克隆:在提供参考音频的基础上,再提供其准确的转录文本,可实现对所有声音细节的最高精度复刻。
性能基准测试
在权威的Seed-TTS-eval基准测试中,VoxCPM2展现了强大的实力:
- 英文测试集上,词错误率(WER)低至1.84%,声音相似度达到75.3%。
- 中文测试集上,字错误率(CER)仅为0.97%,相似度高达79.5%。
- 在多语言CV3-eval测试中,在30种语言上的平均错误率仅为1.68%。
更值得一提的是,在更具挑战性的指令引导语音设计任务(InstructTTSEval)中,VoxCPM2在英文任务上取得了84.2%的准确率,甚至超过了包括Hume、Qwen3-TTS在内的部分商业方案。
生态系统完善
一个好的开源项目离不开完善的工具链,VoxCPM2的生态系统已经相当成熟:
- Nano-vLLM:专门为高吞吐量推理优化的推理引擎。
- VoxCPM.cpp:支持CPU、CUDA、Vulkan的跨平台推理库,部署灵活。
- ComfyUI插件:为可视化工作流爱好者提供了节点式集成方案。
- ONNX导出:便于将模型部署到各种生产环境中。
微调能力
如果你有特定的声音需求,VoxCPM2的微调门槛很低。仅需5-10分钟的目标音频数据,即可通过LoRA等高效微调技术,让模型适配特定的说话人、语言或专业领域。项目还提供了完整的WebUI界面,进一步简化了微调的操作流程。
应用场景与安全思考
这些强大的能力打开了丰富的应用场景。播客创作者可以用它生成带气声的、富有感染力的旁白;游戏开发者能批量、低成本地产出性格各异的NPC语音;而48kHz的专业级采样率,让生成的音频可以直接导入专业的混音工程进行后期处理,无缝衔接内容生产管线。
当然,强大的技术也伴随着需要严肃对待的安全风险。项目团队明确禁止使用该技术进行身份冒充、欺诈或虚假信息传播,并要求所有AI生成内容必须明确标注。已有测试表明,仅用5秒的语音样本,就可能克隆出足以骗过一些简单语音验证系统的声音。项目采用Apache 2.0开源协议,意味着在商用前,使用者需要自行评估并承担相关风险。
如果你对这类前沿的Transformer架构开源项目感兴趣,或者想了解更多AI语音技术的最新进展,欢迎到云栈社区的对应板块交流讨论。
相关资源
|  发表于 2026-4-14 03:15:37
|
查看: 304|
回复: 0
发表于 2026-4-14 03:15:37
|
查看: 304|
回复: 0
