你有没有过这种经历:在接手同事的代码,或者回顾自己几个月前写的 <script setup> 组件时,感觉像是在面对一团纠缠不清的意大利面?
import 语句和各种 ref 变量混作一团,watch 监听器夹杂在 function 中间,想找一个变量的定义得在代码里上下翻飞,鼠标滚轮都快搓出火星子了。
Vue.js 的 Composition API 赋予了我们极大的灵活性,但这种自由往往也伴随着潜在的混乱。如果不加以约束,<script setup> 区域很容易成为新一代“代码泥潭”的温床。坦白说,最初接触 Vue 3 时,我也是想到哪写到哪,代码结构天马行空。直到有一次凌晨为了解决一个 Bug,为了追踪一个变量的来源,我在近千行的组件代码里反复跳转了足足五分钟——那一刻,心态彻底崩了。
痛定思痛后,我总结出了一套名为 「组件代码组织八步法」 的实践。这不仅仅是一套代码书写规范,更是一种符合认知逻辑的思维流程:从输入到输出,从状态到副作用。
经过团队半年的实践与磨合,这套约定让组件的可读性和团队协作效率有了肉眼可见的提升。
什么是「八步法」?
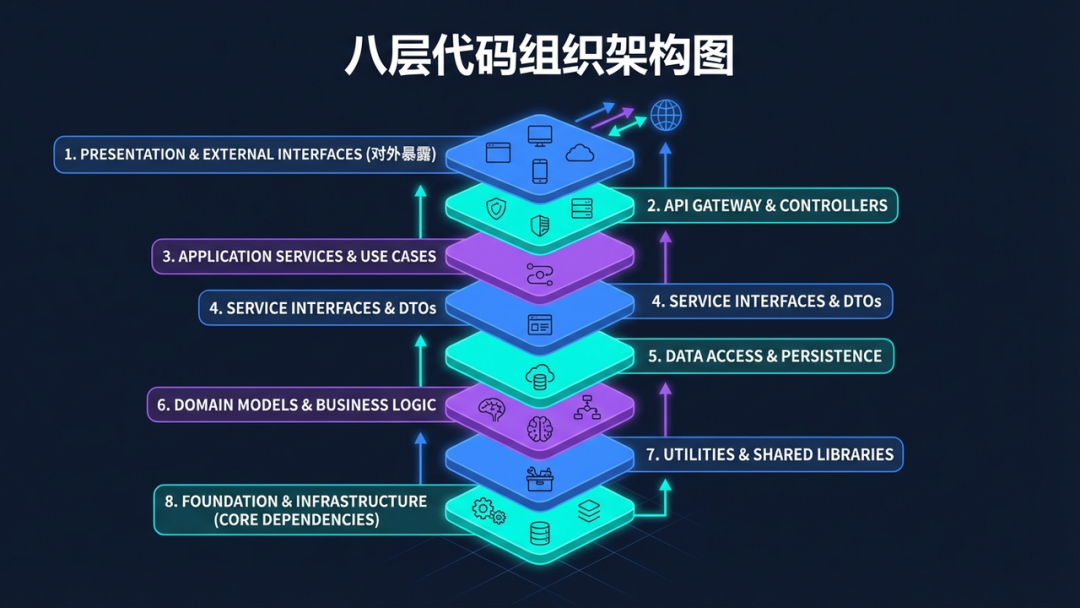
简单来说,它要求我们在 <script setup> 中严格按照以下八个类别和顺序来组织代码:
| 顺序 |
类别 |
说明 |
| 1 |
核心依赖 |
Vue 内置 API、插件、第三方通用库 |
| 2 |
业务资源 |
自定义组件、Hooks、常量、API 函数 |
| 3 |
通信定义 |
defineProps, defineEmits |
| 4 |
状态声明 |
ref, reactive, Hooks 结果, Template Refs |
| 5 |
计算属性 |
computed |
| 6 |
逻辑方法 |
事件处理、内部函数 |
| 7 |
副作用 |
watch, onMounted 等生命周期函数 |
| 8 |
对外暴露 |
defineExpose |
实战代码演示
理论讲再多也不如看一个实际的例子。下面这段代码严格遵循了八步法,你可以感受一下这种阅读逻辑是否更加顺畅。
<script setup>
/**
* 1. 核心依赖引入
* 先看这一层,知道用了哪些“基建”
*/
import { ref, computed, onMounted, watch } from 'vue'
import { ElMessage } from 'element-plus'
/**
* 2. 业务资源引入
* 再看这一层,知道依赖了哪些“业务模块”
*/
import UserEditDialog from './components/UserEditDialog.vue'
import { useUserManagement } from '@/hooks/useUserManagement'
import { DEFAULT_ROLE } from '@/constants/user'
/**
* 3. 组件通信定义 (Props & Emits)
* 搞清楚组件的“输入”和“输出”接口
*/
const props = defineProps({
userId: { type: Number, default: null }
})
const emit = defineEmits(['refresh', 'close'])
/**
* 4. 状态声明
* 所有的响应式变量都在这,想找状态直接跳这儿
*/
// 4.1 Hooks 解构
const { list, loading, submitting, loadList, saveUser } = useUserManagement()
// 4.2 模板引用 (Template Refs)
// ⚠️ 坑点提示:始终把它放在 Hooks 之后,保持统一
const dialogRef = ref(null)
// 4.3 本地状态
const isEditMode = ref(false)
const searchQuery = ref('')
/**
* 5. 计算属性
* 基于状态的加工逻辑
*/
const dialogTitle = computed(() => isEditMode.value ? '编辑用户' : '新增用户')
/**
* 6. 逻辑方法
* 交互逻辑的大本营
*/
const handleOpenAdd = () => {
isEditMode.value = false
dialogRef.value?.open()
}
const handleConfirmSave = async (data) => {
const success = await saveUser(props.userId, data)
if (success) {
emit('refresh')
dialogRef.value?.close()
}
}
/**
* 7. 生命周期 & 监听
* 副作用和初始化逻辑放在最后,因为它们往往依赖上面的所有内容
*/
onMounted(() => {
if (props.userId) {
isEditMode.value = true
loadList()
}
})
watch(() => props.userId, (newId) => {
console.log('用户 ID 变更为:', newId)
})
/**
* 8. 对外暴露
* 组件的“后门”
*/
defineExpose({
openAdd: handleOpenAdd,
refresh: loadList
})
</script>
<template>
<UserEditDialog ref="dialogRef" @save="handleConfirmSave" />
</template>
为什么要这么排列?
这种排列顺序背后,其实遵循了一套符合人类认知规律的心理模型:
- 先上下文,后逻辑:前三步(依赖、资源、通信接口)是在搭建“舞台”。在了解剧情(业务逻辑)之前,你需要先知道有哪些“演员”(组件、Hooks)和“剧本大纲”(Props 与 Emits)。
- 先数据,后行为:中间两步(状态、计算属性)是“数据源”。你得先有了
isEditMode 这个数据状态,后面定义的 function 才能去修改或响应它。
- 副作用沉底:
watch 和 onMounted 通常是逻辑的“触发器”或“响应器”。把它们放在最后,是因为它们几乎总是依赖于前面已定义好的变量和函数。如果把它们放在开头,阅读体验就会变得很别扭——你会先看到“监听某个东西”,然后才翻到下面发现“哦,原来监听的目标在这里定义”。
这种组织方式对降低心智负担的效果是巨大的。
当你需要修复一个 Bug 时,通常只关注两点:状态变没变?方法调没调?
- 想知道组件里有哪些变量?直接滚动到 第 4 区(状态声明)。
- 想找到某个点击事件的处理函数?直接定位到 第 6 区(逻辑方法)。
你不再需要依赖编辑器强大的全局搜索功能进行人肉解析,大脑会自动为代码结构建立清晰的“索引”。
避坑指南:别做规则的奴隶
虽然这套规则非常实用,但我也必须提醒几点在实践中容易走入的误区(这也是我自己的经验教训):
1. 别为了排序而排序
如果你的组件极其简单,可能总共就二三十行代码,那么不一定非要死板地加上 /** 1. 核心依赖 */ 这类注释,那样反而显得画蛇添足。记住,规范的目的是为了清晰,而不是为了凑格式。
2. 过于复杂的组件怎么办?
如果你发现 第 6 区(逻辑方法) 的代码已经膨胀到了两三百行,那么单靠这套排序法也救不了你。此时,正确的做法不是继续整理顺序,而是 果断进行逻辑拆分。将那一大坨复杂的交互逻辑提取到独立的 useXxx.js 自定义 Hook 中,然后在 第 2 区(业务资源) 引入它,并在 第 4 区(状态声明) 进行解构。
3. Template Refs 的位置
示例代码中有个小细节:const dialogRef = ref(null)。我建议将它 紧跟在 Hooks 调用解构之后,一同放在第 4 区。很多人习惯把它藏在文件最底部,结果在修改模板时需要这个引用时,半天都找不到它的定义在哪里。
写在最后
代码的整洁度,就像日常收拾房间。一开始你可能会觉得“随手一放”很方便,但等到东西堆满整个屋子,想找一个指甲刀都得翻箱倒柜时,就悔之晚矣。Vue 3 给了我们极高的自由度,但如果不主动加上一些合理的约束,自由很快会演变成混乱。
不妨从今天开始,就在你手头的一个组件里尝试应用这“八步法”。相信一个月后,当你再次阅读或修改这段代码时,一定会感谢今天这个愿意建立条理的自己。
希望这套方法能对你的开发工作有所帮助。如果你想与更多开发者交流类似的前端工程实践与架构思考,欢迎来 云栈社区 一起探讨。
 发表于 2026-1-31 08:10:03
|
查看: 199|
回复: 0
发表于 2026-1-31 08:10:03
|
查看: 199|
回复: 0
