在项目开发中想要调用大模型,通常有哪些选择呢?如果你需要使用DeepSeek的模型能力,可以登录其DeepSeek官网,通过其API开放平台创建密钥并在代码中集成。如果你倾向于调用阿里云的Qwen系列模型,那么阿里云百炼平台提供了从文本、语音到视觉乃至全模态的全面模型服务。
那么,当我们希望将大模型部署在本地环境中,实现完全的私有化与可控时,又该如何操作?除了像Ollama这样大家熟知的工具之外,最近我发现了一款同样出色且功能强大的新选择——Xinference。

安装指南
Xinference支持在Linux、Windows以及macOS系统上运行,最便捷的安装方式是通过pip。值得注意的是,Xinference支持多种推理后端引擎(如Transformers、vLLM等),你可以根据后续需要运行的模型类型来选择安装对应的依赖包。
最完整的安装方式是使用“all”选项,它会囊括所有可能的依赖:
pip install "xinference[all]"
在实际安装过程中,我发现这个过程比较耗时,因为依赖包众多。为了提高下载速度,可以切换到国内的镜像源,例如:
pip install -i https://mirrors.aliyun.com/pypi/simple/ "xinference[all]"
“xinference[all]”这个选项会一并安装Transformers、vLLM、Llama.cpp等多个核心引擎。如果你明确只需要使用其中一种,比如仅安装Transformers引擎,可以执行更轻量的命令:
pip install "xinference[transformers]"
启动本地服务
安装完成后,可以通过一条简单的命令拉起本地服务。以下命令指定了服务监听的地址和端口:
xinference-local --host 0.0.0.0 --port 9997
服务成功启动后,在浏览器中访问 http://0.0.0.0:9997/ 即可进入其Web管理界面。
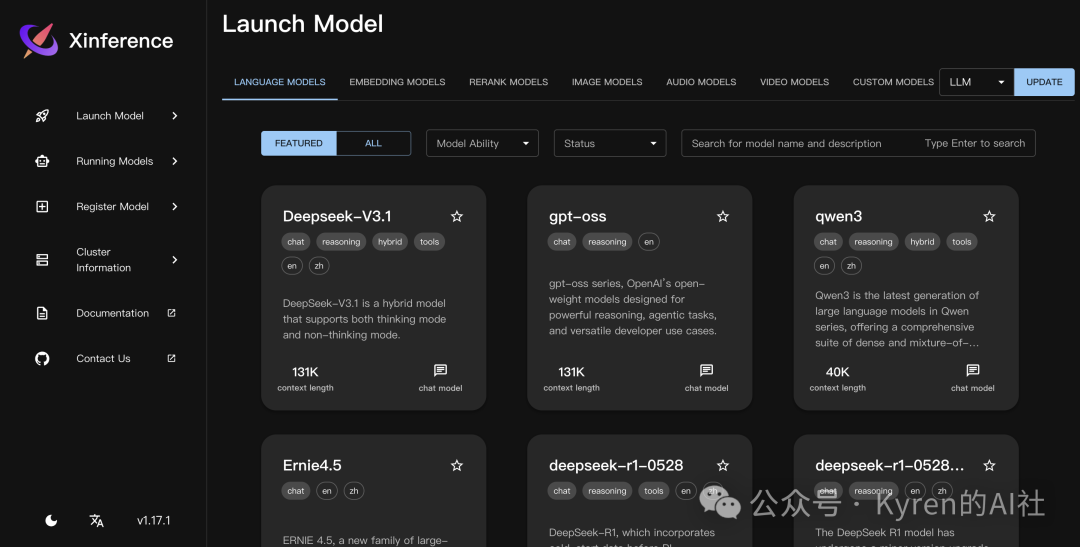
这个界面设计得非常直观和现代化,展示了当前可用的各类模型(如语言模型、嵌入模型等),其美观和易用程度丝毫不逊色于Ollama。
配置与启动模型
在界面上选择你想要运行的模型(例如Qwen3),点击进入配置页面。这里可以根据你的硬件资源进行详细设置。
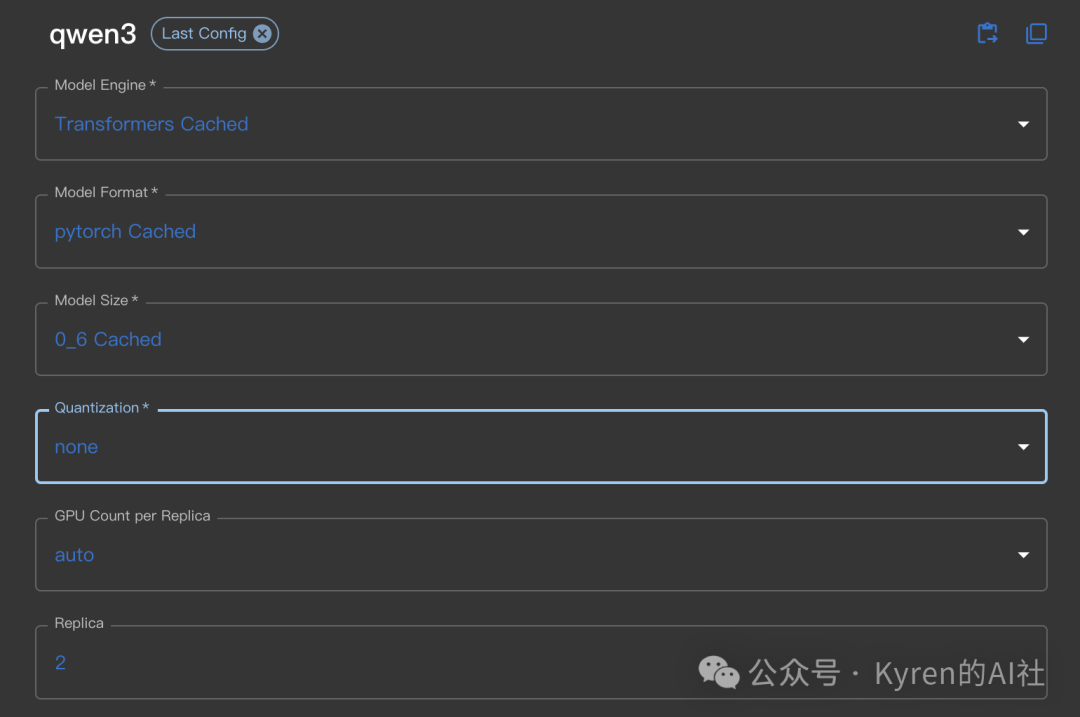
主要配置项通常包括:
- Model Engine: 例如选择
Transformers。
- Model Format: 例如
pytorch。
- Model Size: 例如
0.6(表示参数规模)。
- Quantization: 量化选项,例如选择
none(不量化)以保持最高精度,或选择int4等以减少显存占用。
- GPU Count per Replica: 每个副本使用的GPU数量。
- Replica: 副本数,用于并发请求。
配置完毕后,点击“Launch”按钮。Xinference会根据你的配置,自动从HuggingFace等模型仓库拉取相应的模型文件,并使用选定的推理引擎启动一个模型服务实例。
管理运行中的模型
模型成功启动后,你可以在“Running Models”菜单栏下看到所有正在运行的服务实例。
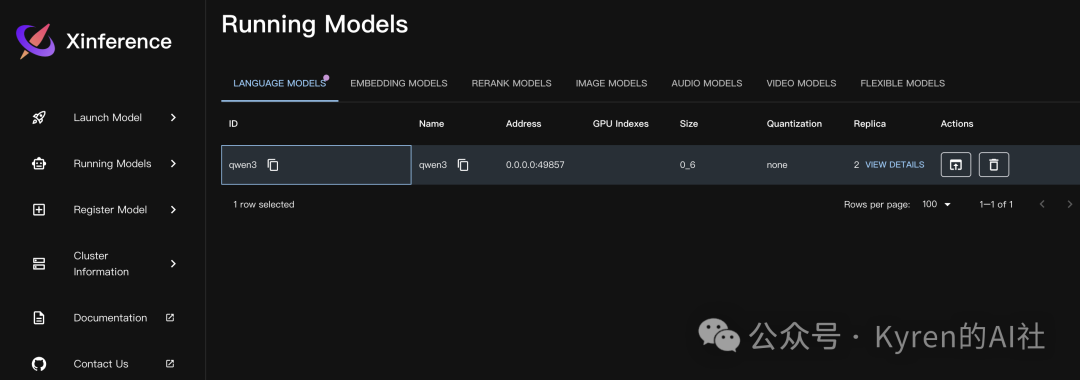
这里列出了每个运行实例的详细信息,包括模型ID、服务地址(可用于API调用)、占用的GPU索引、模型大小和量化状态等。你可以随时查看详情或停止某个模型服务。
总的来说,Xinference提供了一套功能完备、界面友好的大语言模型本地部署与管理方案。对于那些希望在公司内网或本地机器上搭建私有化模型服务的开发者和团队来说,它无疑是一个值得尝试的开源工具。如果你对这类技术实践感兴趣,欢迎到云栈社区的讨论区分享你的使用心得或遇到的问题。
 发表于 2026-1-31 17:13:19
|
查看: 278|
回复: 0
发表于 2026-1-31 17:13:19
|
查看: 278|
回复: 0
