随着AI浪潮的袭来,笔者本人以及团队都及时调整了业务方向,转型为AI开发者和AI产品开发团队。日常工作中,我们常需对大模型注入业务场景依赖的私域知识,完成微调后部署推理,以支撑智能体或智能问答产品的逻辑流程。
相信有相同转型经历的开发者都会感同身受:转型之路必然伴随阵痛。好在对技术的热情与职业发展的理性分析,促使我们克服多重困难——包括大模型知识的学习积累、AI产品的需求定义与交付,以及最难的GPU资源协调与实验室建设。
为什么获取GPU资源如此困难?首先,没有卡就没有实践,没有卡就无法开展研究,更不用说设计产品原型。然而现实是:GPU价格高昂,公司通常仅分配一台公共GPU服务器供多个团队轮流使用。这带来两个关键问题:
1)GPU服务器需预约时段轮流使用,无法第一时间验证新想法与代码实现,导致产品迭代效率低下;
2)服务器软件环境常被随意变更配置与版本,每次使用前都要耗费时间恢复环境,实际用于生产的时间极少,还易引入因环境差异导致的Bug。
可见,正如传统应用开发需要CPU开发机,AI时代的开发者也需要自己的GPU开发机——这是可持续、稳定且高效产出的前提。那么,采购消费级GPU是否可行?答案是否定的:消费级GPU并非为大模型而生,仅几十GB显存难以流畅运行主流大模型及其开发框架。
经过长期实践验证,公用GPU服务器与消费级GPU均难以满足日常AI开发的算力需求。直到我发现了联想ThinkStation PGX——联想与NVIDIA联合推出的AIPC(桌面上的AI超级计算机),一款开发者可独占、能稳定运行200B~400B参数量大模型的AI开发机。

联想ThinkStation PGX——个人AI算力基础设施
ThinkStation PGX定位为GPU工作站,处于GPU服务器与GPU个人电脑之间,面向AI开发者提供本地大模型开发与测试平台,号称“全球迄今最小的AI超算”。
PGX的发布标志着AI算力正从大型机构向个人开发者或小型团队渗透。随着生态成熟,越来越多AI开发者将人手一台趁手的开发机,在本地直接开展模型开发、调试与部署——从此不必再申请GPU服务器时段,不必争抢资源;若需更改软件配置以满足各类需求,它就在那里,随时可动手。
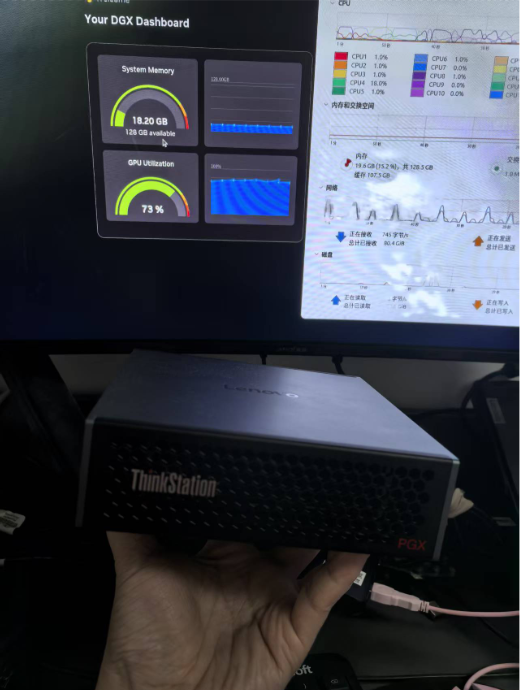
PGX不仅让AI开发者“随心所欲”,更重要的是保障研究与产出的持续演进。例如,当业务智能体团队要求通过微调注入特定私域知识数据集时,我们可立即选择合适模型分支在本地微调训练,再部署推理验证效果。若符合预期即上线;若上线后出问题,也可立即在本地复现与排查。
当在AI开发机上开发的模型,无需修改代码即可无缝迁移至生产环境,这正是CI/CD思想的产品迭代方式。换言之,当大模型可在个人开发机完成微调、推理与迭代,开发机角色也随之改变——它不再是终端,而是个人AI基础设施,作为桌面端与云端之间的桥梁,与生产环境AI基础设施具备可移植性。
显然,PGX的核心价值在于提供本地化的大模型运行环境,便于模型原型设计、微调与测试。对单兵作战或小团队开发者而言,这是革命性的生产力提升。
在售后服务方面,联想作为国内TOP1专业工作站品牌优势显著:为PGX提供专属三年上门服务、保修与技术支持,对注重省事省力的用户极具吸引力;还可提供三年一次硬盘恢复、专享NV技术咨询等PRC增值服务。
虽然AI开发机相较GPU服务器已大幅亲民,但仍属高价值消费品,建议选择国内售后实力强的品牌。联想在全国拥有超1万名认证工程师、2300+专业服务站,100%覆盖1~6线城市,保证7×24小时在线支持,值得信赖。
硬件参数
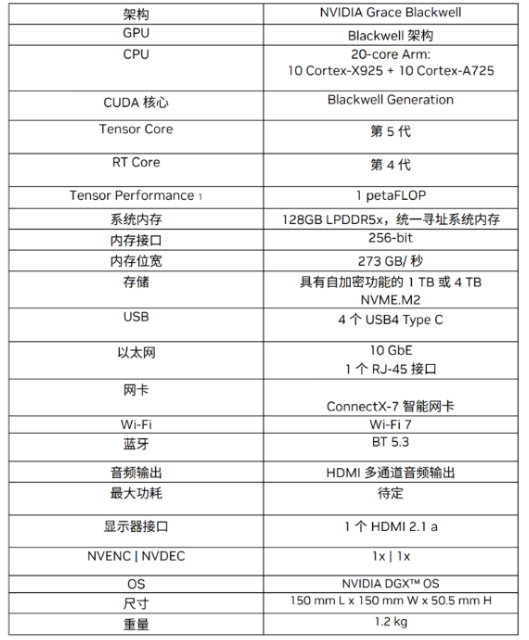
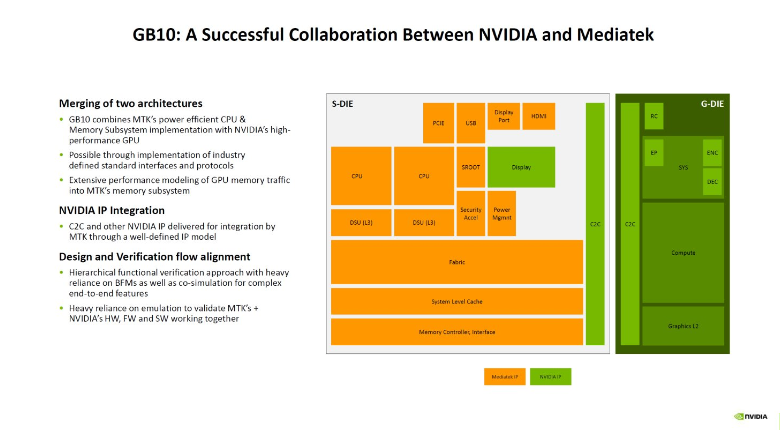
PGX是一款基于Grace-Blackwell芯片架构的桌面级AI超级计算机,其核心是一颗NVIDIA GB10 Grace Blackwell SoC芯片,将Grace CPU与Blackwell GPU融合于一体。如下图所示,除GB10外,还配备128GB统一内存、ConnectX-7网卡、4TB SSD存储等服务器级硬件模块。

下图是一张硬件参数概览表,我们将逐一分析每个参数,理解“ThinkStation PGX专为AI开发者设计的桌面级AI超级计算机”的设计理念。
Blackwell GPU
GB10 SoC芯片上的GPU模组采用Blackwell架构。如下图,从芯片原件排布可见左侧为GPU,采用台积电3nm工艺集成48个SM、约6144个CUDA core,以及第5代Tensor Core(张量核心)和第4代RT Core(光追核心)。

GB10的显著特点是支持FP4/FP6/FP8低精度计算,专为AI开发机应用场景而设计。特别是FP4精度,基于成熟的NVFP4大模型量化技术,结合稀疏性技术,可在一台ThinkStation PGX上提供惊人的1 PFLOP/s(1千万亿次每秒)AI算力峰值。
这意味着采用FP4精度处理大模型推理时,ThinkStation PGX可显著提升整体吞吐量,效率较FP8和FP16成倍提升——这是为了让AI开发机尽可能更快微调训练、更大吞吐推理而设计。
Grace ARM CPU
GB10的CPU模块采用精简指令集的ARM 10+10架构。
其中,ARM v9.2架构在保证高性能的同时兼具低功耗与小型化优势,使ThinkStation PGX可使用标准家用插座供电,无需额外专用充电设备,轻松置于桌面使用。
另外,10+10共计20个core:10个Cortex-X925 core(高性能核)负责高负载通用计算任务;10个Cortex-A725 core(高能效核)负责后台进程与I/O调度。10+10组合专为优化大模型训练数据加载、预处理与流程编排而设计,加速从数据清洗到模型调整的全流程。

128GB 统一系统内存
ThinkStation PGX另一项专为AI开发机而设计的是128GB统一系统内存(UMA)技术,使CPU与GPU在保证访存寻址一致性的前提下共享128GB LPDDR5X内存,而非传统分离式主存与显存。
128GB UMA从根本上解决了消费级GPU仅24GB/48GB显存容量受限的关键痛点。这意味着训练与推理数据无需在CPU主存与GPU显存间拷贝,降低延迟;处理大模型时,也避免了传统GPU因显存不足反复交换主存的开销,提高效率。
此外,结合FP4精度可将更大模型塞入PGX。例如,扣除操作系统占用空间后,128GB中约100GB可供给GPU使用。使用FP4量化后,原本需200GB显存的200B大模型,现仅需约100GB即可部署,使桌面端运行超大规模模型成为可能。
容量之外的带宽层面,128GB UMA与CPU/GPU间访存总线宽256bit,带宽约273GB/s。如下图所示,GB10的CPU与GPU模块间采用最先进的NVLink-C2C互联技术,数据传输无需经过PCIe,而是Chip-2-Chip直连,总线带宽最高达141GB,是PCIe 5.0的5倍。
NVLink-C2C技术突破传统PCIe瓶颈,带来更快协同运算性能。这也是GBXX架构被称为SuperChip的原因。
综上,GB10 SuperChip、128GB UMA、FP4精度三者组合,使专为NVIDIA NVFP4优化的vLLM等AI框架可根据实际负载动态分配UMA内存资源,读写模型参数、KV Cache等数据;中间激活值也不再需在CPU主存与GPU显存间反复搬运,不仅降低内存拷贝时延,也显著简化大模型部署与调优复杂度。最终实现:一台ThinkStation PGX最大可承载200B规模大模型进行推理,或对70B规模大模型进行微调。
通常需在GPU服务器上协调2~4张卡才能实现的目标,如今有了PGX,我们可随时随地开展工作。
值得一提的是,128GB UMA对MoE(混合专家)模型适用性极强,例如Qwen3-235B-A22B等MoE模型——虽总参数庞大,但单次激活参数较少,与PGX大内存优势高度匹配。无需复杂显存优化操作,即可稳定运行,拓展硬件应用场景。
另外,273GB/s内存带宽确属偏低,是大规模推理的主要性能瓶颈。但PGX的128GB大内存确实为部署超大MoE模型提供了坚实支撑。可见PGX的价值在于容量而非速度,其性能虽受限于内存带宽,但综合效果远超消费级GPU个人电脑方案。
高性能的存算分离网络连接
ThinkStation PGX在一台小小设备上实现了GPU服务器级别的高性能存算分离网络连接,包括:
- 1个10GbE的RJ-45万兆以太网接口:作为管理网络和存储网络,用于加载大模型权重数据及存储训练过程中的Checkpoint数据。
- 1张200Gbps的ConnectX-7智能网卡:双QSFP接口,作为RDMA高性能计算网络,用于连接2台ThinkStation PGX组成双机集群后进行NCCL集合通信,交换分布式训练或推理过程中的梯度数据。
通过CX7组成双机集群后,可实现256GB的UMA扩容,这种扩展能力为超大规模模型本地部署提供显存容量基础,可部署如Llama 3.1 405B和Qwen 3 235B此等量级大模型推理,无需担心内存溢出。
更进一步,通过Microick CRS 812 DDQ交换机,可将PGX集群扩展至6个或更多系统。

PC 化设计
前文着重介绍了PGX在“GPU服务器化”方面的能力,接下来介绍其“PC化”设计。
首先是尺寸:PGX是一个巴掌大小的金属壳盒子,体积为150×150×50.5mm,重量仅1.2kg。整机紧凑式设计,金属外壳兼具质感与耐用性,办公桌面占用极小,充分体现NVIDIA旗舰级硬件工业设计水准,初见即为其精湛工艺惊叹。
其次是功耗:PGX满载功耗理论仅约240W,其中GB10 SoC芯片TDP约140W,其余100W留给网卡、SSD等组件。标配240W外置电源适配器,适用于任何办公桌电源插槽,无需额外供电设备。
然后是散热:PGX散热系统讲究,采用静音设计,运行噪音控制优秀——空闲时约13dB,满载时约35dB,非常安静,完全适配办公环境。
再来是外设接口:PGX配备4个USB Type-C,其中一个用于供电输入;1个HDMI 2.1a显示器接口,支持多声道音频输出与最高8K显示;无线方面集成Wi-Fi 7与BT 5.3模块,覆盖无线办公全场景,无需特殊转换器。

可见,以上均为完全标准的“PC化”设计,使我可经常背着PGX上下班。实际使用中,只需插上电源与视频转接器,即可延续办公室或家中的工作进展。
最后不得不提的是PGX采用1TB或4TB NVMe M.2 SSD存储:一方面避免模型训练I/O瓶颈,另一方面支持自加密(Self-Encrypting)功能,为大模型权重数据与代码资产安全提供全面保护,让我相对放心地带PGX外出交流与学习。

软件堆栈
前文从硬件参数设计层面分析了为何称PGX为“专为AI开发者设计的桌面级AI超级计算机”,接下来从软件堆栈设计说明:PGX不仅是AI开发机,更是个人级AI基础设施。
AI开发机与个人级AI基础设施的核心区别在于是否真正融入生产环境CI/CD流程——这取决于个人环境与生产环境是否具有一致性软件堆栈,确保代码与模型参数能否无缝流转。
ThinkStation PGX在软件方面尽量做到开箱即用:初次配置只需联网更新并简单设置用户信息,即可获得完整NVIDIA AI开发环境。后续通过NVIDIA Dashboard工具等,可方便维护系统状态并获取最新优化。
PGX已预先安装与GPU服务器一致的NVIDIA AI软件栈,包括经优化的GPU驱动、CUDA库及NVIDIA提供的各种AI工具与框架支持。如下图所示,开发者可直接访问NVIDIA NIM、NVIDIA Blueprint和AI Workbench平台,拉取NVIDIA容器镜像(含经测试的PyTorch/TensorFlow + CUDA运行环境),在PGX上直接运行。
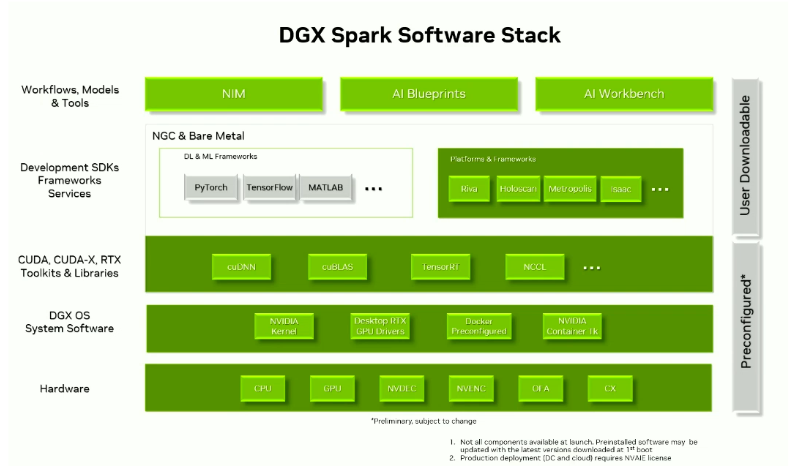
并且也可在PGX上立即使用PyTorch、TensorFlow、TensorRT-LLM等主流框架,以及Jupyter Notebook、Ollama等主流开发工具。开发者在PGX上开发调试的代码与容器,可无缝移植至企业级GPU服务器或NGC(NVIDIA GPU Cloud)云服务运行。
PGX实际上就是生产环境CI/CD流程中的一个开发环境,在本地重现了生产级GPU服务器的架构与软硬件环境,让开发者“所见即所得”地进行开发与调试。日常工作中,我们先用单机PGX验证,再小规模集群测试,最后上线至生产环境GPU服务器集群。
桌面操作系统
首先是操作系统。区别于纯命令行的GPU服务器,PGX OS是基于Ubuntu 24.04 LTS定制发行的桌面操作系统。
对于模型可视化、性能优化、图形图像开发等工作,开发者常需使用Nsight Systems等GUI工具调试GPU程序,纯命令行显然无法满足所有需求。因此PGX OS桌面操作系统专为让开发者在一台电脑上完成所有工作而设计。
此外,为让习惯macOS或Windows的开发者获得良好体验,PGX也预先安装并启用了xRDP图形远程桌面服务,可建立稳定顺畅的远程GUI连接,在自己习惯的笔记本上访问PGX桌面环境。
启动操作系统后,我们需要做基础软件环境检查:
- 查看Grace CPU信息:
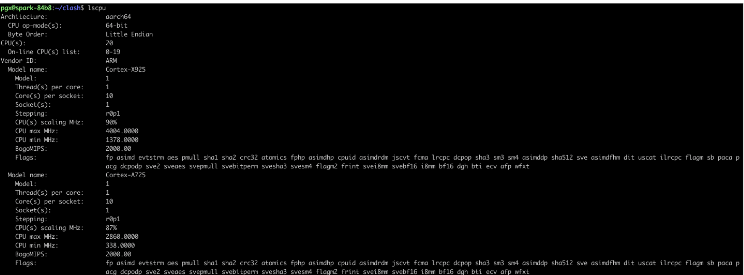
- 查看128GB UMA内存容量:
free和nvidia-smi看见的内存容量信息一致,因为是UMA架构。

- 查看SSD硬盘容量:

- 查看GPU信息:
nvidia-smi的Memory Usage一栏会显示"Not Supported",这是正常情况,因UMA架构下GPU无独立显存。
- 查看预安装的Docker版本:

- 查看预安装的CUDA工具链版本:
若直接运行Docker容器,容器内将看不见GPU设备,因此需安装NVIDIA Container Runtime和Toolkit以支持docker run --gpus选项。NVIDIA Container Runtime运行于HostOS中,是容器内无缝使用GPU的关键技术。
NVIDIA Container Toolkit则运行于Containers内部,提供必要组件,为容器化应用动态配置并接入GPU设备与CUDA库,具有以下优势:
- 容器内无缝访问GPU设备;
- 自动管理GPU驱动程序与CUDA库;
- 支持自动配置Multi-GPU;
- 与Docker等主流容器编排平台兼容。
在PGX系统中已预先完成NVIDIA Container Runtime & Toolkit的安装与配置,包括:与Docker集成、配置GPU设备访问、配置CUDA库等。因此PGX操作系统可开箱即用,立即开始处理AI工作负载、CUDA应用程序及其他GPU加速软件。
验证是否可正常调用GPU设备与CUDA库:
- 启动容器,使用
--gpus all参数让容器直接使用主机GPU。
- 在容器内输入
nvidia-smi、nvcc --version等命令,若均能获取正常输出,即说明Docker容器内GPU和CUDA环境已就绪。
$ docker run -rm -it --gpus=all \
-v "$PWD":/workspace \
-w /workspace \
nvcr.io/nvidia/pytorch:25.08-py3
默认情况下,PGX OS执行docker指令需sudo权限。为方便,可将pgx用户添加到docker用户组,即可无需sudo直接运行。

值得注意的是,PGX CPU是ARM64平台,因此自行安装软件或启动容器时,需选择对应arm64版本。
例如:直接docker pull pytorch/pytorch:latest默认拉取x86_64镜像,在ARM CPU上运行会报非法指令。因此应使用NVIDIA NGC提供的镜像,或Docker Hub上标记支持arm64平台的镜像。
NVIDIA官方提供了可直接应用于PGX的容器镜像,涵盖CUDA 13、PyTorch等。拉取nvcr.io/nvidia/cuda:13.0.1-devel-ubuntu24.04作为基础镜像,再安装AI框架即可保证兼容。
https://catalog.ngc.nvidia.com/
NVIDIA Dashboard
NVIDIA Dashboard是NVIDIA提供的软件管理工具,用于检查软件更新、安装补丁、升级GPU驱动、NIC固件等。NVIDIA会定期(每半年左右)发布OS重要更新及不定期安全补丁,为获更好稳定性与性能,建议定期检查系统更新。通过Dashboard可方便查看并一键安装可用更新。
强烈建议优先使用Dashboard执行系统更新,因NVIDIA针对PGX软件栈进行了特殊更新验证与优化,使用Dashboard可避免不兼容更新导致的问题。
另外,NVIDIA Sync桌面程序能实时显示PGX设备资源利用率,并集成命令行终端,为用户提供统一界面管理SSH访问及在PGX上启动开发工具。
LLM 推理实践
NVFP4 量化技术
随着大模型参数量增长,显存优化技术之一的低精度量化技术飞速发展。行业趋势是大模型正朝低位宽浮点数演进(FP32→FP16→FP8→FP4)。业内长期测试发现,不同低精度格式效果排序为FP8 > FP4 > INT8 > INT4。因FP4兼具体积与精度综合优势,已成为大模型量化技术主流趋势。
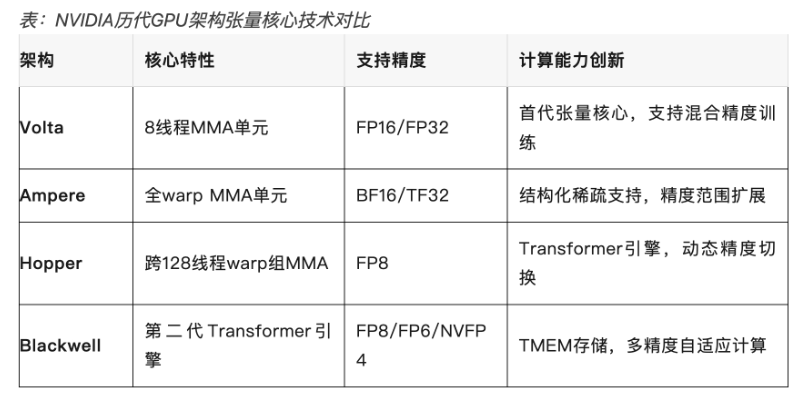
PGX的Blackwell GPU支持NVIDIA专为推理优化的NVFP4(4-bit浮点)格式,结合FP4量化技术,可实现接近FP8的精度(仅降低1%)。NVFP4量化技术可将模型权重压缩至原始大小的约3~3.5倍(相比FP16),或1.8倍(相比FP8),同时提升吞吐量。从而在不牺牲准确性的前提下,放下更大参数规模模型。在NVFP4加持下,一台PGX才得以实现最大承载200B规模大模型进行推理。

并且因FP4数据占用更小,系统性能亦得提升。因此,应用NVFP4量化技术后的PGX可在不牺牲模型精度前提下实现:
- 更高的推理吞吐
- 更低的响应延迟
- 更快的Token生成速度
- 更顺畅的Prompt处理能力
而高效的Prompt处理能力有助于提升token响应速度,加快端到端吞吐量,改善用户体验。下表展示了PGX在NVFP4 + TensorRT-LLM / llama.cpp环境下多款大模型的测试表现。
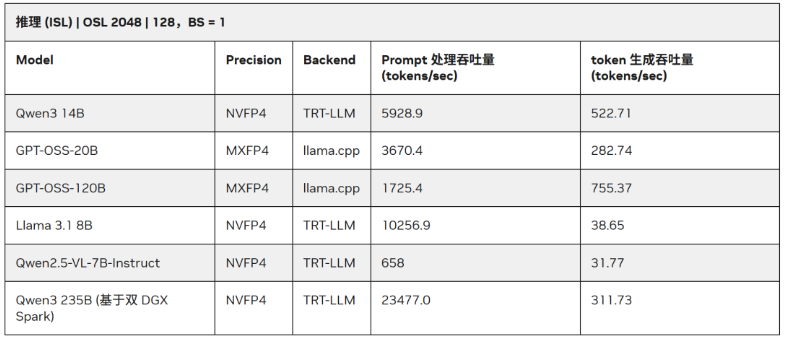
- ISL(输入序列长度):输入提示词数量,即Prefill tokens。
- OSL(输出序列长度):模型响应过程中生成token数量,即Decode tokens。
本文推理实践中采用NVIDIA官方发布的NVFP4量化模型nvidia/Qwen3-30B-A3B-NVFP4,总参数量30B、单次激活参数量3B的MoE模型,可最大化发挥PGX内存与算力优势,是理想应用场景。
TensorRT-LLM + Qwen3-30B-A3B-NVFP4
采用NVIDIA官方推荐的TensorRT-LLM框架搭配NVFP4量化模型进行测试。
https://huggingface.co/nvidia/Qwen3-30B-A3B-NVFP4
启动命令如下:
$ docker run -d \
--name trtllm-serve \
-v "/data/llm-model/nvidia/Qwen3-30B-A3B-NVFP4:/workspace/model" \
--gpus=all \
--ip=host \
--network host \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
trtllm-serve /workspace/model \
--backend pytorch \
--max_batch_size 10 \
--host 0.0.0.0 \
--port 8000

注意:官方推荐的--backend pytorch参数会让模型跳过TensorRT的CUDA Graph优化与Kernel算子融合功能,仅以PyTorch原生模式运行,未能发挥TensorRT-LLM核心加速优势。

vLLM + Qwen3-30B-A3B-NVFP4
在v0.12.0版本以前,使用vLLM + Qwen3-30B-A3B-NVFP4组合在执行CUTLASS FP4 MoE矩阵乘法操作时会遇见RuntimeError: Failed to initialize GEMM错误。这是因为旧版本vLLM MoE模型对GB10 SM12.1架构NVFP4格式适配不成熟,部分关键Kernel核函数尚未完成。
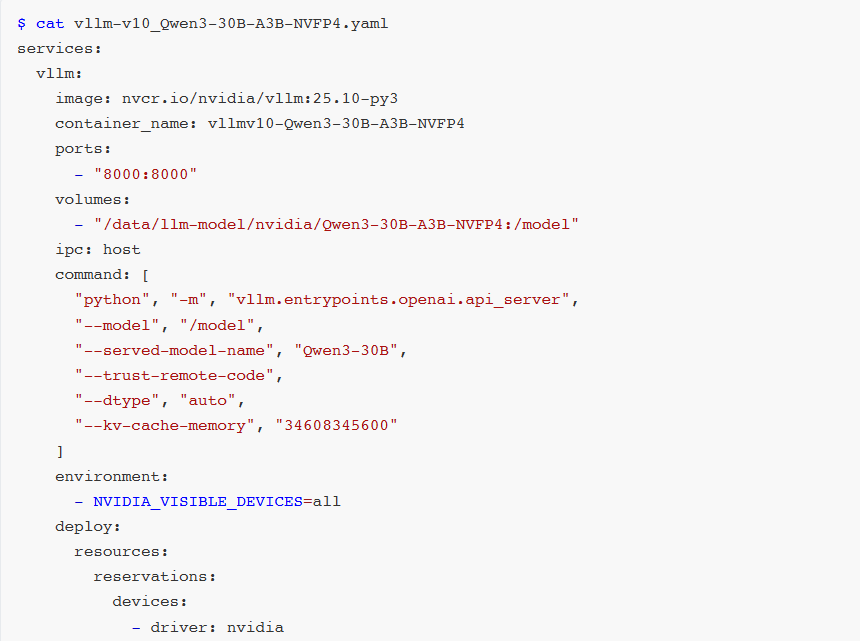

直到v0.12.0版本,vLLM正式支持NVFP4,标志着FP4格式逐渐被主流认可。

NGC已提供vLLM v0.12.0版本镜像,可直接使用。
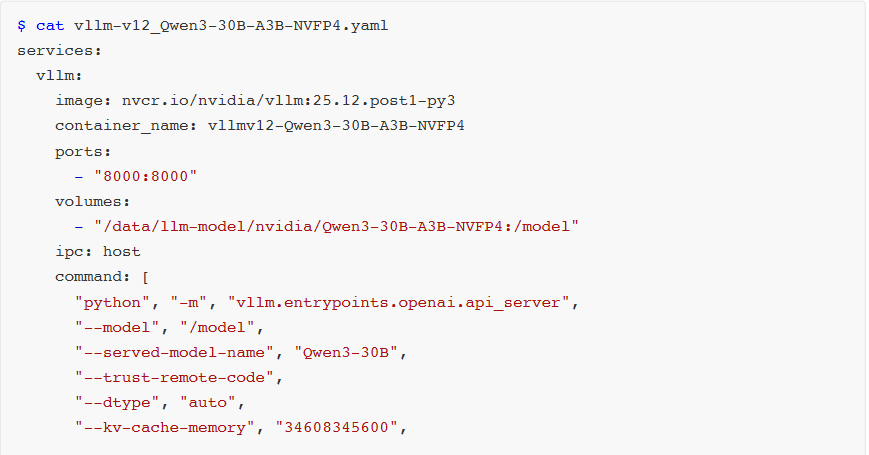

若需使用自定义镜像,可手动编译v12版本。
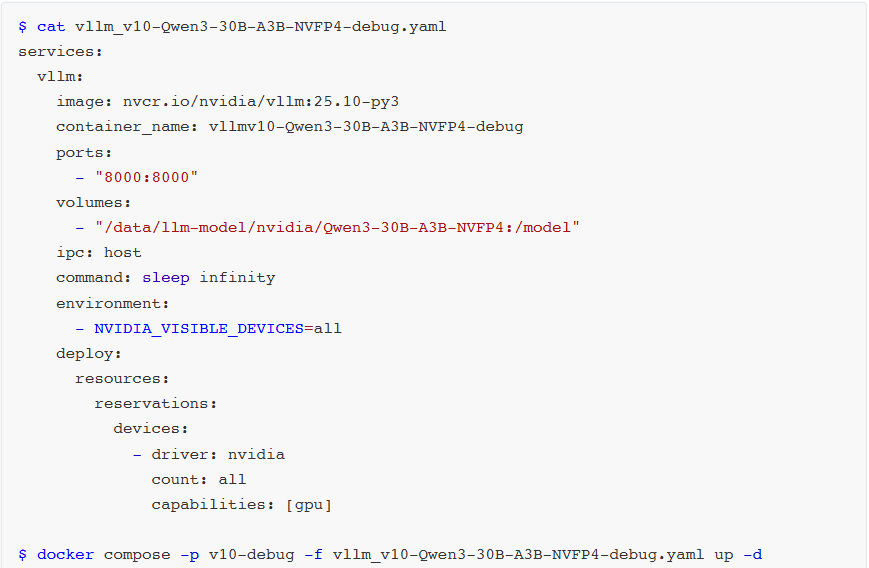


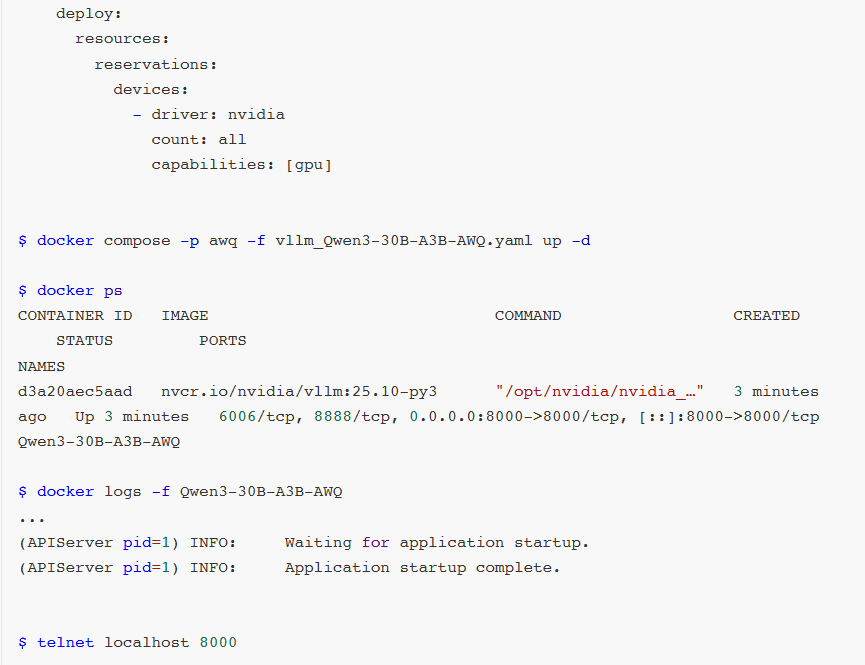
启动vLLM:
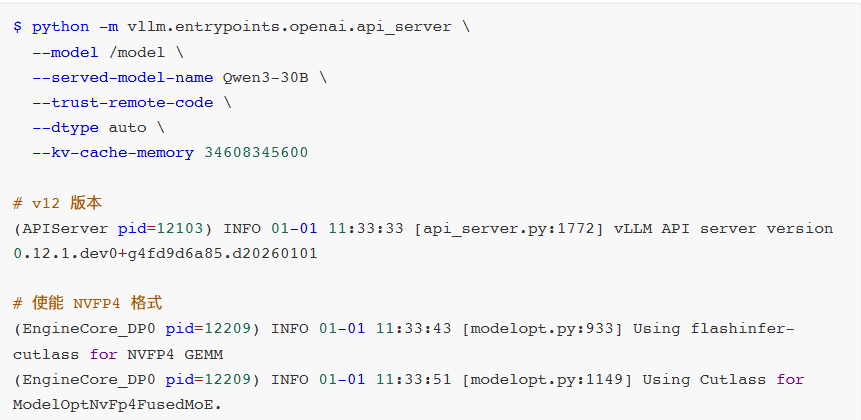
$ python -m vllm.entrypoints.openai.api_server \
--model /model \
--served-model-name Qwen3-30B \
--trust-remote-code \
--dtype auto \
--kv-cache-memory 34608345600
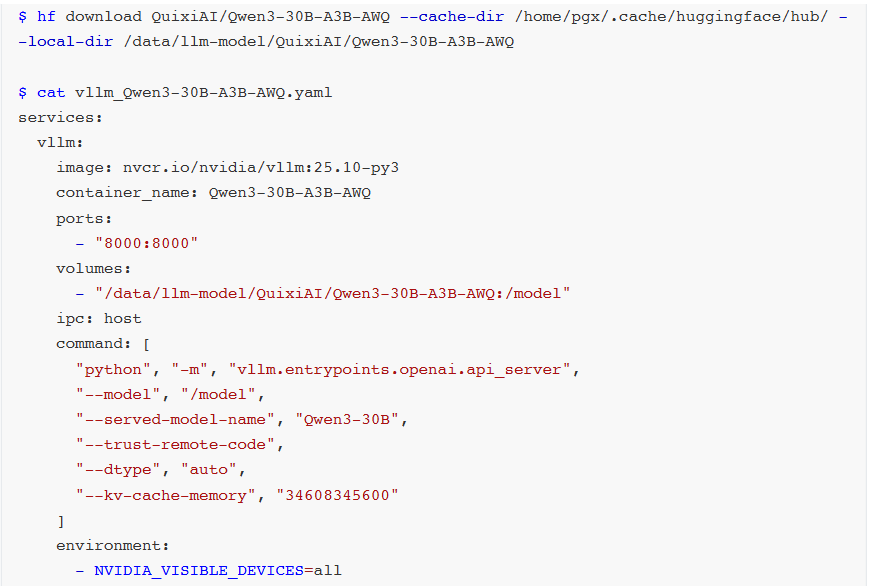
vLLM + Qwen3-30B-A3B-AWQ
若使用较旧vLLM版本,推荐采用AWQ量化的Qwen3-30B-A3B-AWQ模型。
AWQ作为成熟量化技术,拥有完善社区支持与大量实践验证。vLLM框架对AWQ适配经多轮优化,具备稳定高效运行链路。

性能压测对比
使用第三方压测工具:
https://evalscope.readthedocs.io/zh-cn/v0.7.1/user_guides/stress_test/quick_start.html
![pip安装evalscope命令截图:`pip install evalscope[perf] -U`](https://static1.yunpan.plus/attachment/51af38d8f44e0643.webp)
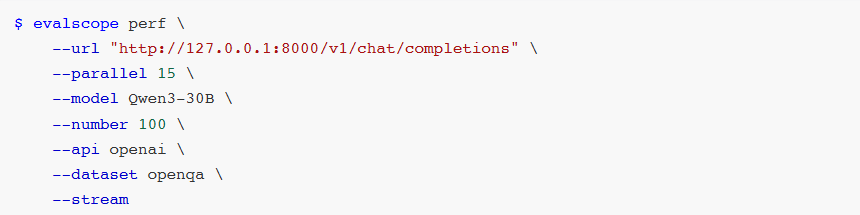
压测参数设置:
url:请求URL parallel:并行请求数量 model:使用的模型名称 number:请求数量 api:使用的API服务类型 dataset:数据集名称 stream:是否启用流式处理
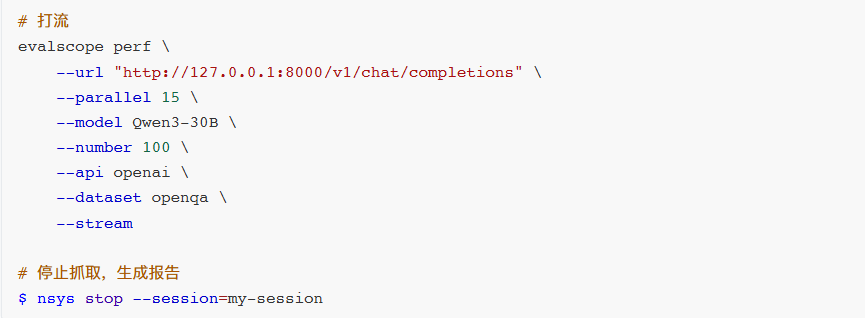
$ evalscope perf \
--url "http://127.0.0.1:8000/v1/chat/completions" \
--parallel 15 \
--model Qwen3-30B \
--number 100 \
--api openai \
--dataset openga \
--stream
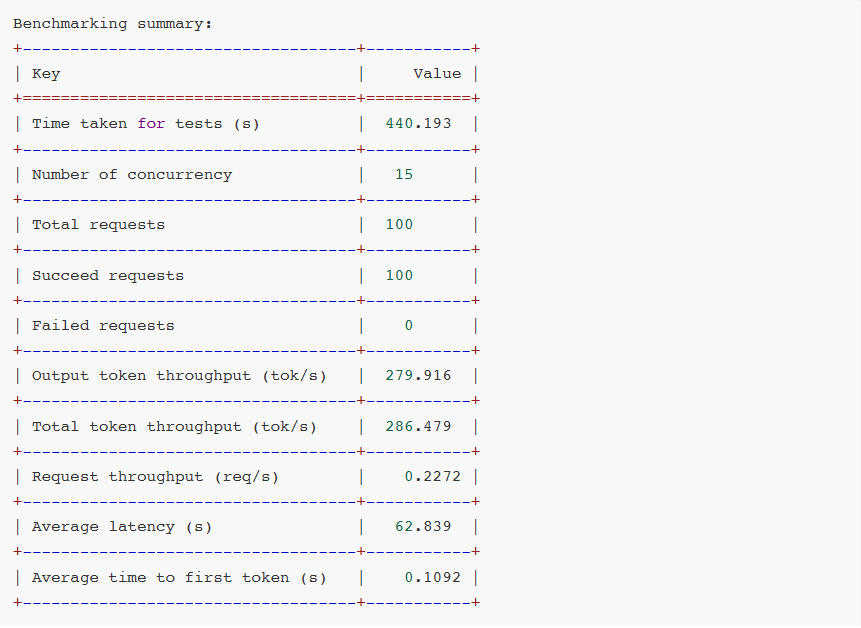
对比测试结果:
- TensorRT-LLM + Qwen3-30B-A3B-NVFP4
- vLLM + Qwen3-30B-A3B-NVFP4
- vLLM + Qwen3-30B-A3B-AWQ

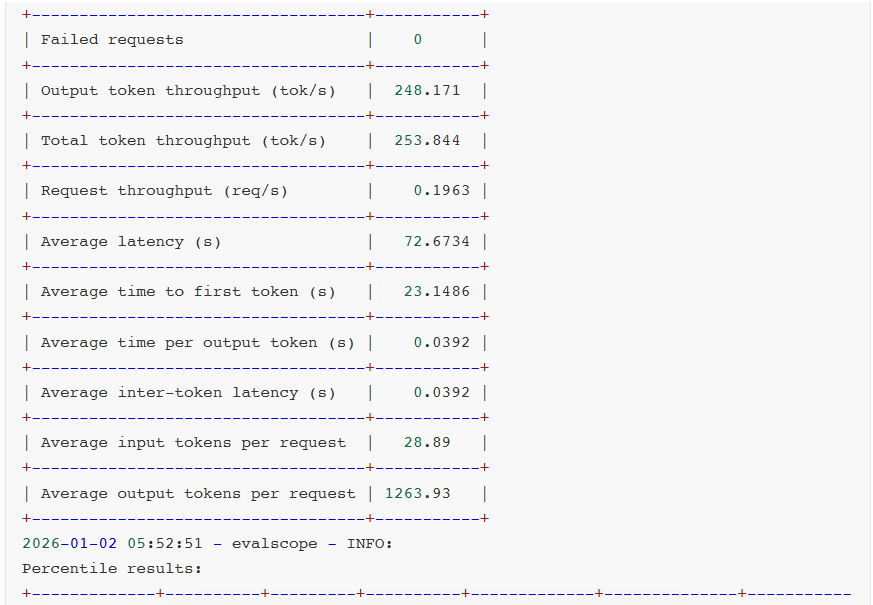
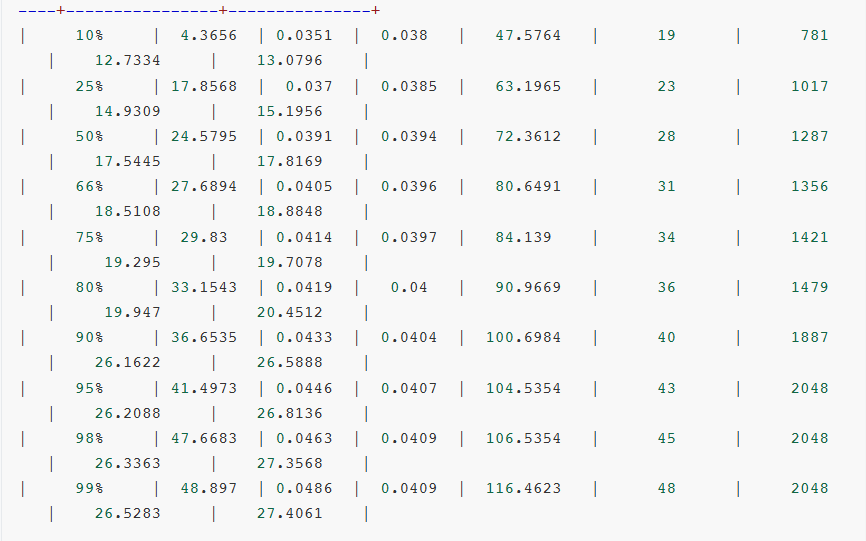

- vLLM + Qwen3-30B-A3B-NVFP4
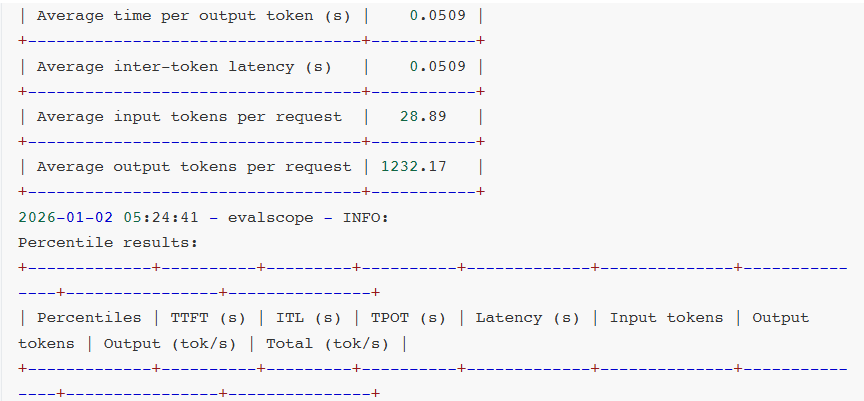
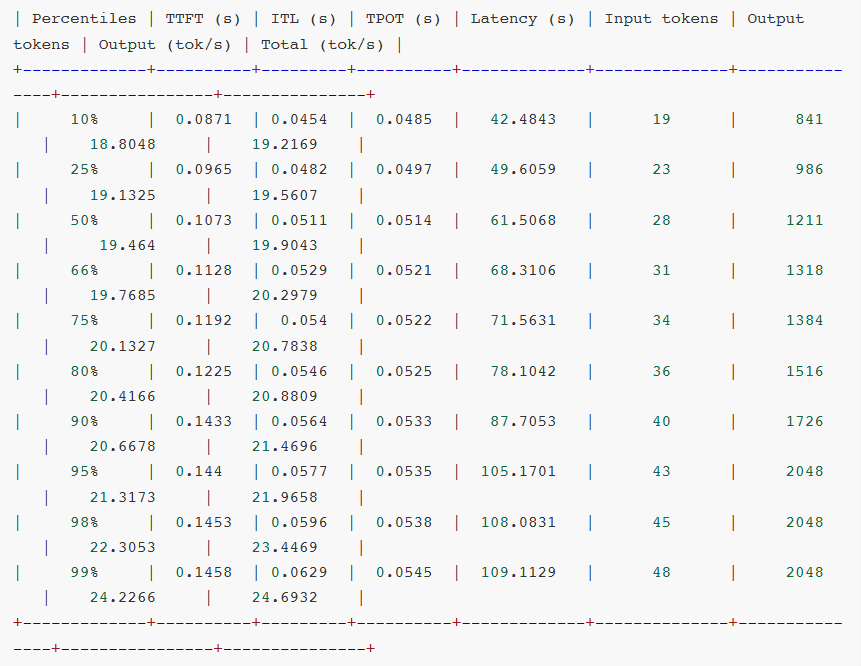
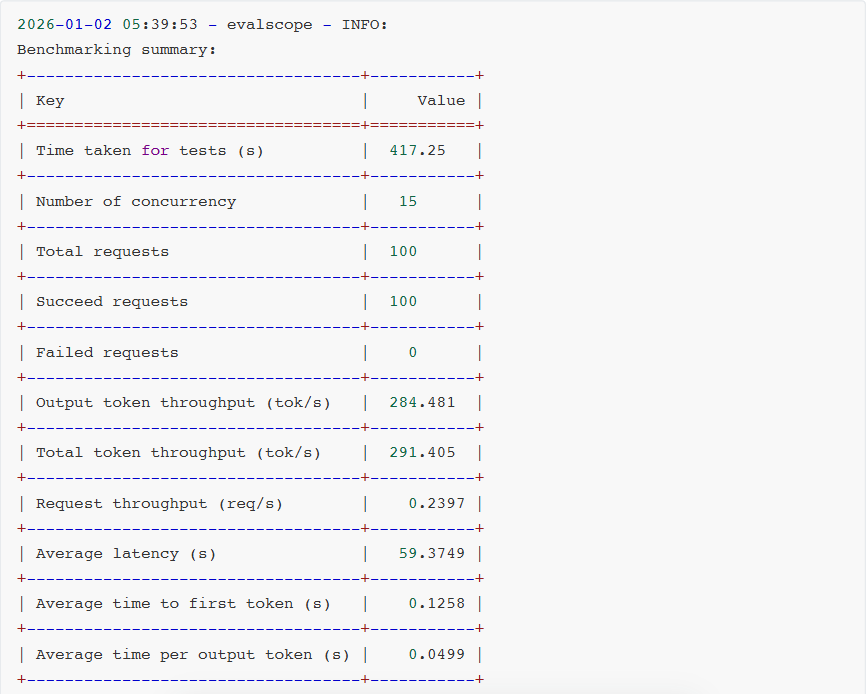
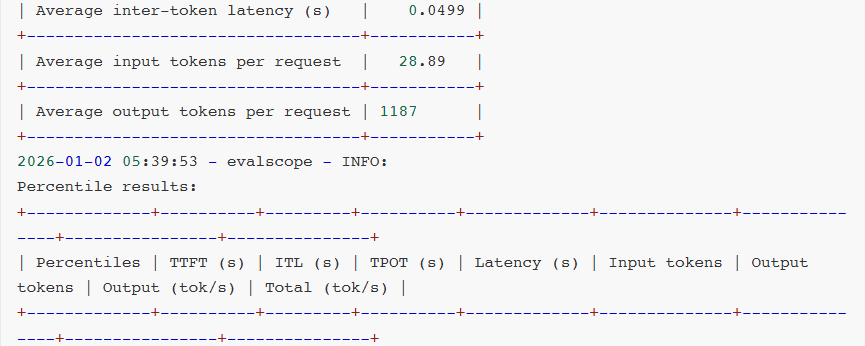
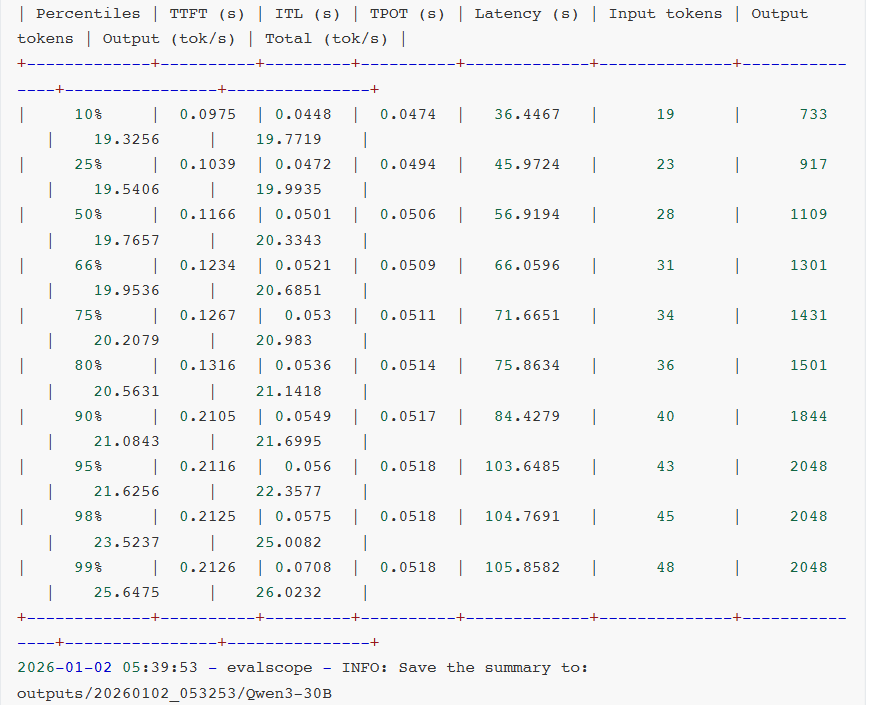
- Latency(延迟):整体响应时间。
- Throughput(吞吐量):每秒处理的请求数和token数。
- TTFT(Time to First Token):首token时间,用户感知体验。
- ITL(Inter-Token Latency):token间延迟,生成流畅度的关键指标。
- TPOT(Time per Output Token):每token输出时间,生成效率的直接体现。
- E2EL(End-to-End Latency):端到端延迟,完整请求的时间开销。
对比测试分析:
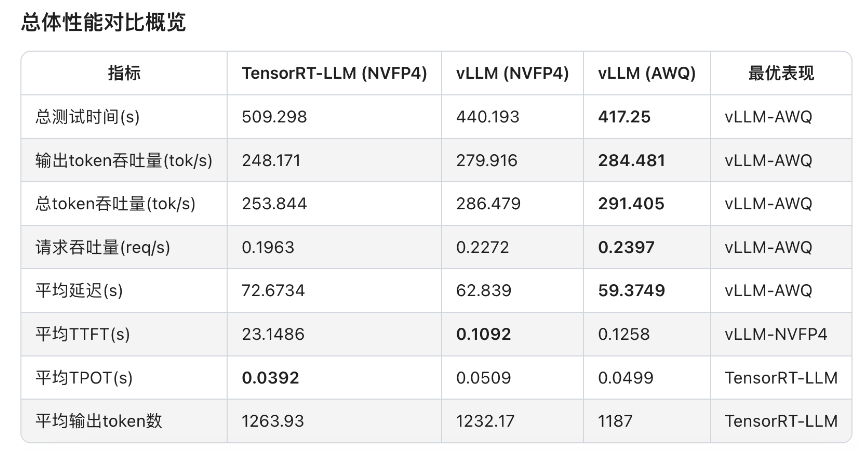
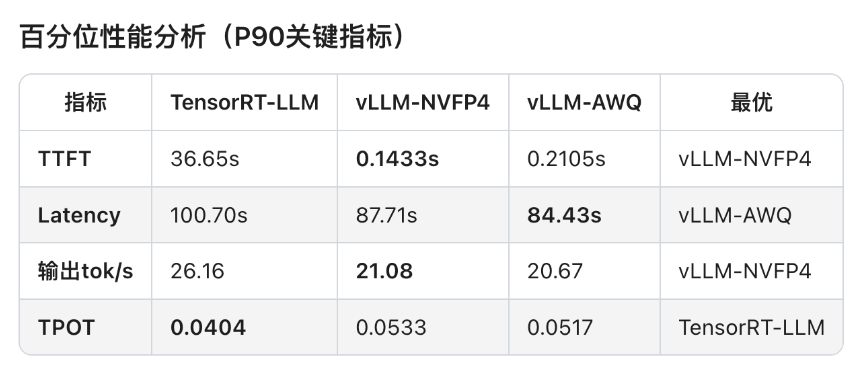
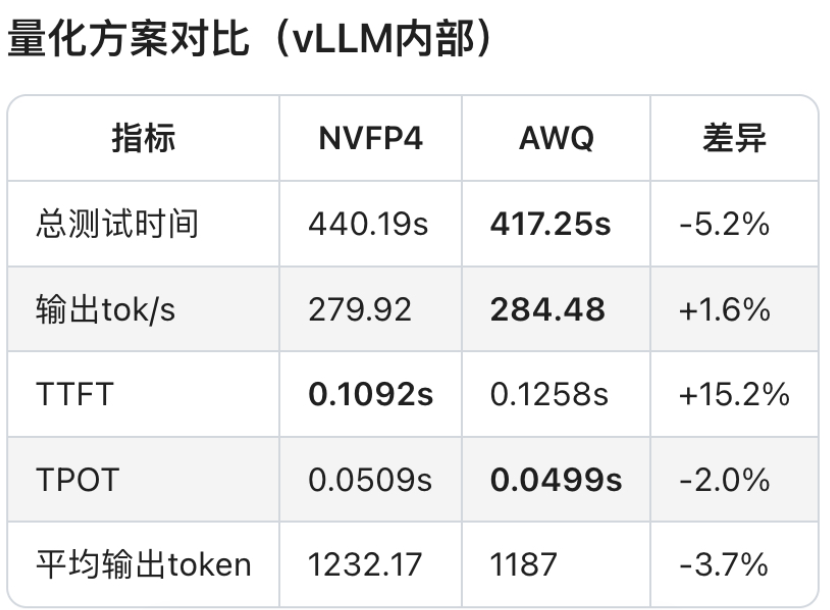
可见,软件生态成熟度通常滞后于硬件迭代。GB10 SM12.1属于新型架构,TensorRT-LLM框架对其优化仍处初期阶段,部分性能优化实现无法启用,整体软件栈尚未完成与新硬件深度适配。
相较于AWQ量化技术,虽然NVFP4具备理论技术优势,但NVFP4针对MoE模型推理所需的Fused MoE Kernel尚未完成全场景适配。从报错日志可见,FlashInfer kernels缺失导致TensorRT-LLM即便能运行模型,也无法调用最优Kernel实现,限制性能发挥。
另外,NVIDIA官方目前尚未针对batch size、KV cache等vLLM参数配置给出最佳实践方案。可见NVFP4软件生态仍处建设阶段,尚未形成成熟应用闭环。不过好在NVIDIA已明确NVFP4全面优化将很快上线。
性能剖析工具
在模型开发日常工作中离不开性能剖析,尤其是Nsight System和Nsight Compute这两款NVIDIA性能剖析工具的使用,这些工具均已被预先安装在PGX上,可通过GUI桌面方便使用。
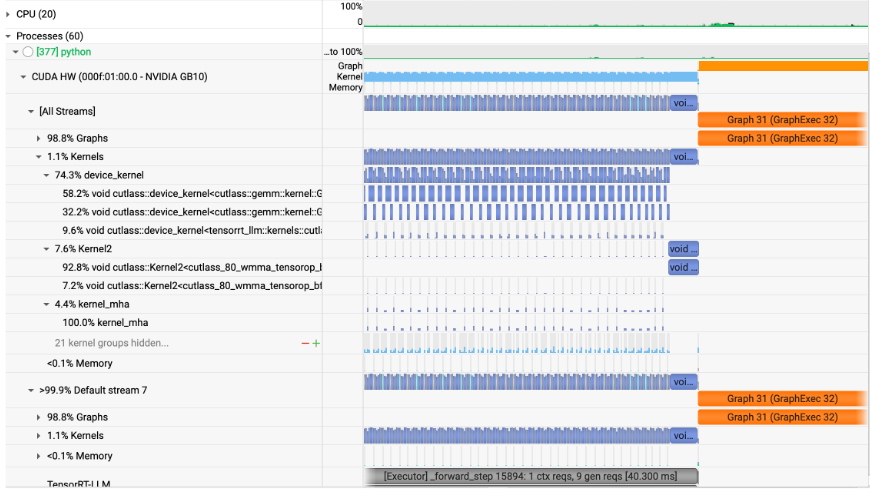
例如,上述性能测试对比可知,在同等条件下NVIDIA官方提供的TensorRT-LLM + Qwen3-30B-A3B-NVFP4方案的TTFT较高,此时需使用性能剖析工具调查。这里主要介绍如何在PGX上使用nsys等工具的流程。
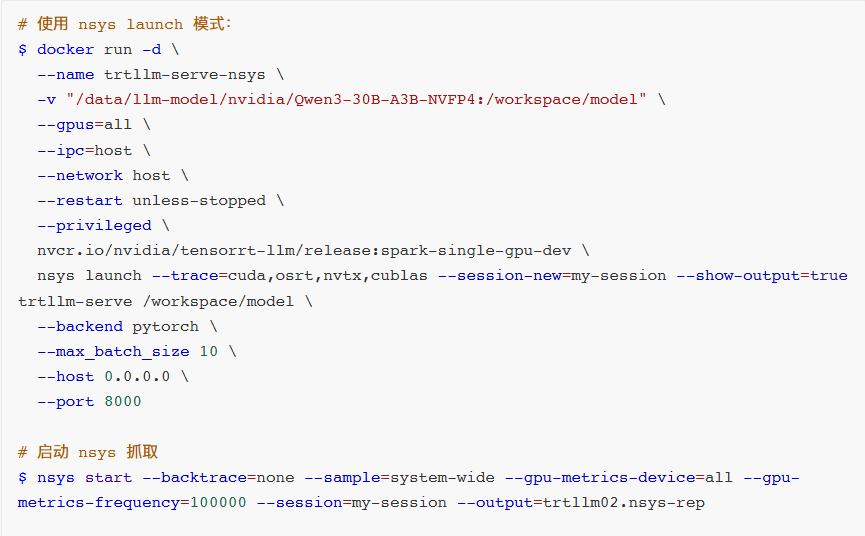
- 方式1:在容器内部抓取性能剖析数据。注意在容器内抓取GPU Metrics需修改推理进程启动指令,添加
nsys launch指令,并为容器启用特权模式,配置GPU可访问模式。
# 使用 nsys launch 模式:
$ docker run -d \
--name trtllm-serve-nsys \
-v "/data/llm-model/nvidia/Qwen3-30B-A3B-NVFP4:/workspace/model" \
--gpus=all \
--ipc=host \
--network host \
--restart unless-stopped \
--privileged \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
nsys launch --trace=cuda,osrt,nvtx,cublas --session-new=my-session --show-output=true trtllm-serve /workspace/model \
--backend pytorch \
--max_batch_size 10 \
--host 0.0.0.0 \
--port 8000
# 启动 nsys 抓取
$ nsys start --backtrace=none --sample=system-wide --gpu-metrics-device=all --gpu-metrics-frequency=100000 --session=my-session --output=trtllm02.nsys.rep
- 方式2:在容器外部抓取。注意因容器外部无法指定容器内部具体进程,故抓不了
--trace指向的CUDA HW数据,只能抓取GPU Metrics数据。
sudo nsys profile --sample=system-wide --gpu-metrics-device=all --gpu-metrics-frequency=100000 --duration=10 -o trtllm01

nsys性能剖析数据抓取完成后,可直接在PGX GUI桌面上查看。如下图,可用可视化方式观测TensorRT-LLM的Kernel核函数执行Timeline图,对理解其执行流程至关重要。这些工具在PGX上均已预装,非常方便。
LLM 微调实践
微调是指在已训练好的大型预训练模型基础上,进一步训练该模型以适应特定任务或领域数据。可在特定任务上取得更好性能,因模型在微调中重点学习与任务相关特性;亦可在情感分析、问答系统等多领域快速适应;相比从零训练,所需数据与计算资源显著减少。
在实际大模型应用场景中,高效微调主要用于以下四个方面:
- 改变对话风格:根据特定需求调整模型对话风格。如客服、虚拟助理等场景,通过微调少量参数(如对话生成策略、情感表达),使模型适应不同语气、礼貌程度或回答方式。
- 注入私域知识:将外部知识或领域特定信息快速集成到预训练模型中。如法律、医疗、IT等专业领域,通过少量标注数据微调,帮助模型理解术语、规则与知识,提升专业问答能力。
- 提升推理能力:在处理复杂推理任务时,微调使模型更高效理解长文本、推理隐含信息或提取逻辑关系,从而在多轮推理中提供更准确答案。
- 支撑Agent需求:通过Agent使模型能与其他系统交互、调用外部API执行任务。通过针对性微调,模型可学会更精准Function Calling策略、参数解析与操作指令,支撑Agent能力。
现在绝大多数开源模型开源时会公布两个版本:Base模型(仅预训练,未指令微调)与微调模型(在Base基础上进一步全量指令微调后的对话模型)。
微调技术原理
广义上,微调可分为2种主要方式:全量微调和高效微调。选择哪种方法,取决于开发者希望对原始模型进行多大程度调整。
参数高效微调:
- 工作原理:仅更新模型一小部分,以更快、更低代价完成训练。是在不大幅改变模型前提下提升能力的高效方式。
- 适用场景:几乎适用于所有传统需完整微调的场景,包括引入领域知识、提升代码准确性、使模型适配法律或科学任务、改进推理能力,或对语气和行为进行对齐。
- 要求:小到中等规模数据集(100~1000组示例提示词对)。
完整微调:
- 工作原理:更新模型所有参数,适用于训练模型遵循特定格式或风格。
- 适用场景:高级应用场景,如构建AI智能体和聊天机器人,需围绕特定主题提供帮助、遵循既定约束规则并以特定方式响应。
- 要求:大规模数据集(1000+组示例提示词对)。
LLM微调是对GPU显存和计算要求极高的工作负载,每个训练步骤均需数十亿次量级矩阵乘法更新模型权重。即使是Mistral 7B这样的小型LLM进行全面微调,也可能需高达100GB内存。因此,微调前需考虑各种微调方法的GPU显存需求。
显然,相较于LoRA和QLoRA高效微调,完整微调对内存与吞吐量要求更高。尽管完全微调可对模型能力进行深度改造,但需带入全部参数训练,消耗大量算力且有技术门槛。相比之下,在绝大多数场景中,若只想提升模型某具体领域能力,高效微调更合适。
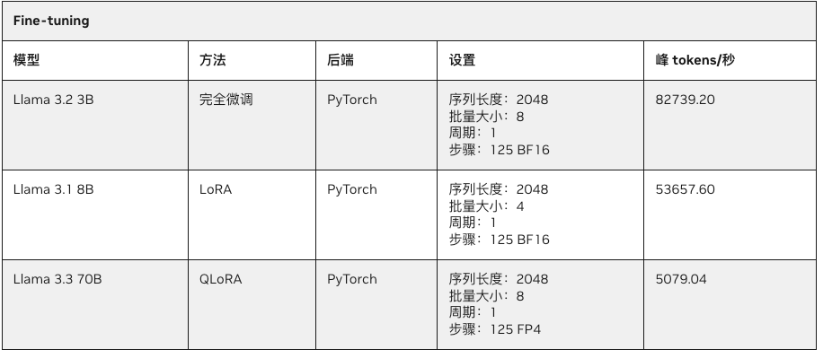
由于微调需消耗大量显存,参数规模超30B的大模型往往无法在32GB消费级GPU上运行,却可轻松在拥有128GB UMA的PGX上随时进行。下表展示了在PGX上对Llama系列模型进行微调的性能表现。
- Llama 3.2 3B完全微调:每秒82739.2 tokens处理速度。
- Llama 3.1 8B LoRA微调:每秒53657.6 tokens处理速度。
- Llama 3.3 70B QLoRA微调:每秒5079.4 tokens处理速度。
LoRA
LoRA(Low-Rank Adaptation,低秩适应)旨在通过引入低秩矩阵减少微调时需调整的参数数量,从而显著降低显存与计算资源消耗。具体来说,LoRA微调并不直接调整原始模型所有参数,而是通过在某些层中插入低秩适配器(Adapter)层来训练低秩矩阵。
LoRA的原理:
在完全微调中,会修改模型所有权重;而在LoRA中,只有某些低秩矩阵(适配器)会被训练和调整。这意味着原始模型参数保持不变,仅通过少量新参数调整模型输出。
低秩矩阵引入可在显存与计算能力有限的情况下,依然有效对大型预训练模型微调,使LoRA成为显存较小设备的理想选择。
LoRA的优势:
- 显存优化:只需调整少量参数(适配器),显著减少显存需求,适合显存有限的GPU。
- 计算效率:微调过程计算负担更轻,因减少了需调整的参数量。
- 灵活性:可与现有预训练模型轻松结合,适用于文本生成、分类、问答等多种任务。
QLoRA
QLoRA(Quantized Low-Rank Adaptation)是LoRA的扩展版本,结合了LoRA低秩适配器技术与量化技术。在LoRA基础上进一步优化计算效率与显存需求,尤其适用于极端显存受限环境。
QLoRA的原理:
与LoRA不同,QLoRA会将插入的低秩适配器层的部分权重进行量化,通常为FP4、INT4或INT8等低精度格式,在保持性能同时显著降低模型存储与计算需求。
可见,QLoRA涉及量化(quantization)技术,将模型一部分权重参数存储在较低精度数值格式中,以此减少内存使用与计算量,同时结合LoRA低秩调整,使适应过程更高效。
QLoRA的优势:
- 在显存非常有限的情况下仍能进行微调。
- 可处理更大规模模型。
- 适合边缘设备和需低延迟推理的场景。
LLaMA Factory + Qwen3-7B + LoRA
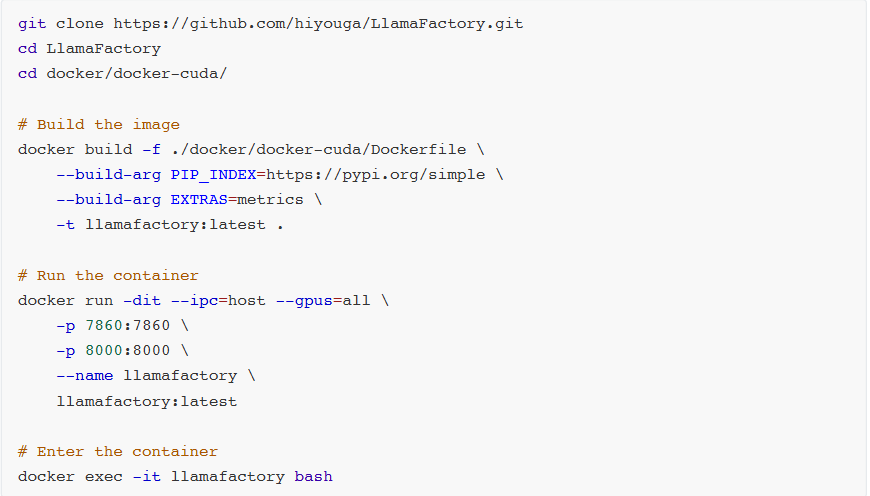
安装部署



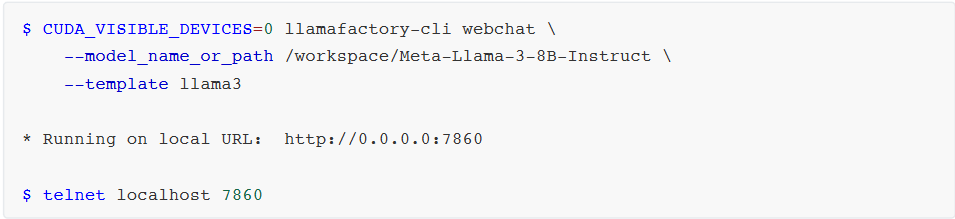
$ CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path /workspace/Meta-Llama-3-8B-Instruct \
--template llama3
* Running on local URL: http://0.0.0.0:7860
$ telnet localhost 7860
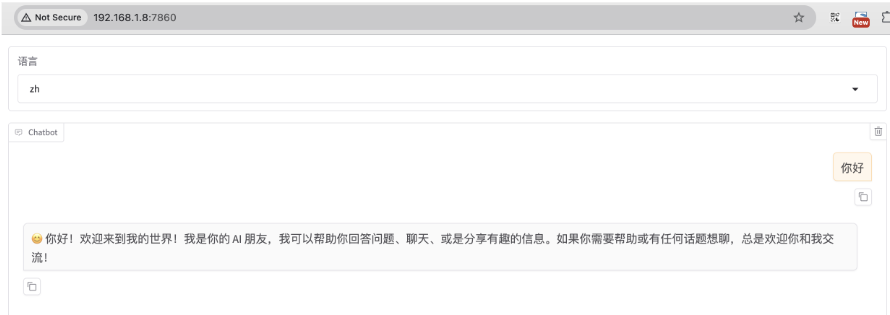
- model_name_or_path:huggingface或modelscope的模型名称,如
meta-llama/Meta-Llama-3-8B-Instruct;或本地下载的绝对路径。
- template:模型问答所用prompt模板,不同模型需各自模板,否则会出现重复生成等异常。如Meta-Llama-3-8B的template即
llama3。
魔搭社区集成了相当丰富的中文数据集,有很多分类可选。
https://www.modelscope.cn/datasets
找一个角色扮演的数据集来微调(方便查看效果)。
https://www.modelscope.cn/datasets/kmno4zx/huanhuan-chat
在数据预览这里查看详细数据。
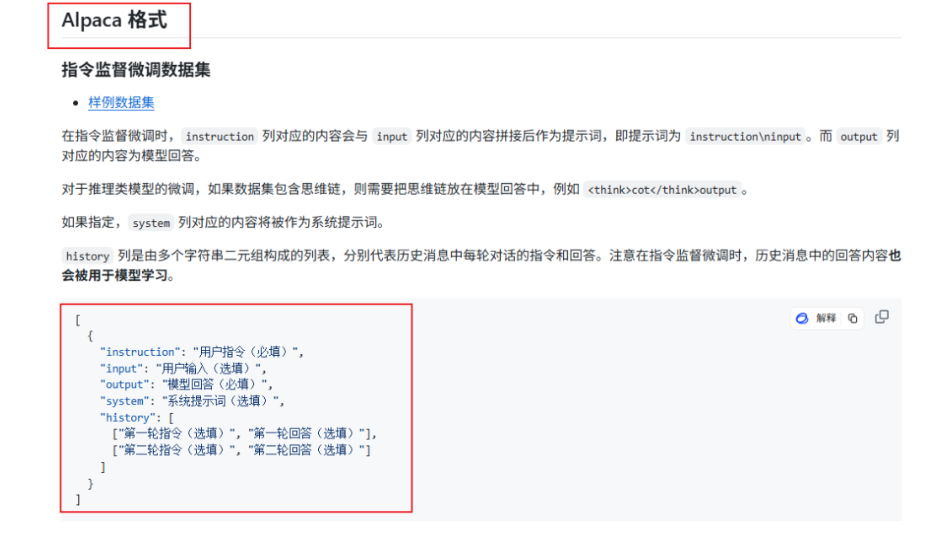
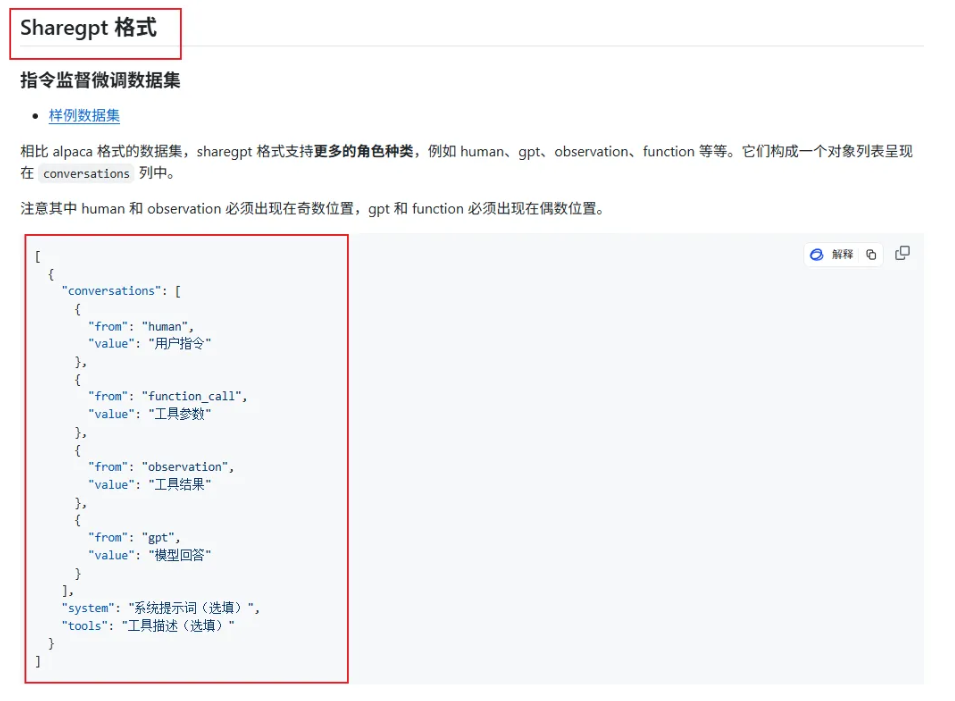
注意,llama-factory目前只支持两种格式的数据集:Alpaca和Sharegpt格式。
https://github.com/hiyouga/LlamaFactory/tree/v0.9.1/data
切换到数据集文件这边,打开huanhuan.json文件,看到它其实就是Alpaca格式的数据集,仅下载这一个文件即可。
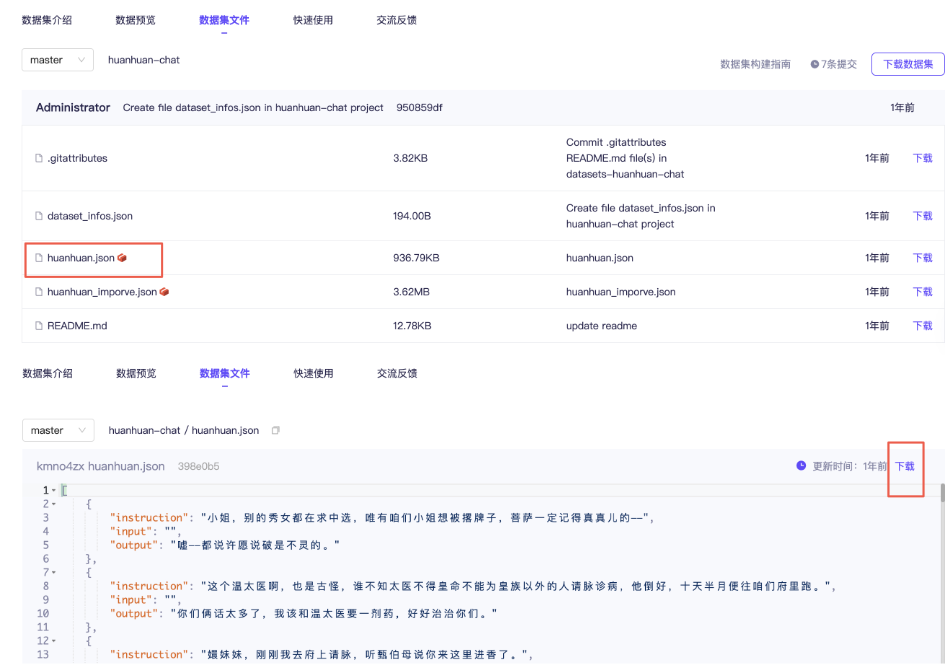
在llama-factory添加数据集,不仅要把数据文件放到data目录下,还需在配置文件dataset_infos.json里添加一条该数据集记录。这样新数据集才能被识别。
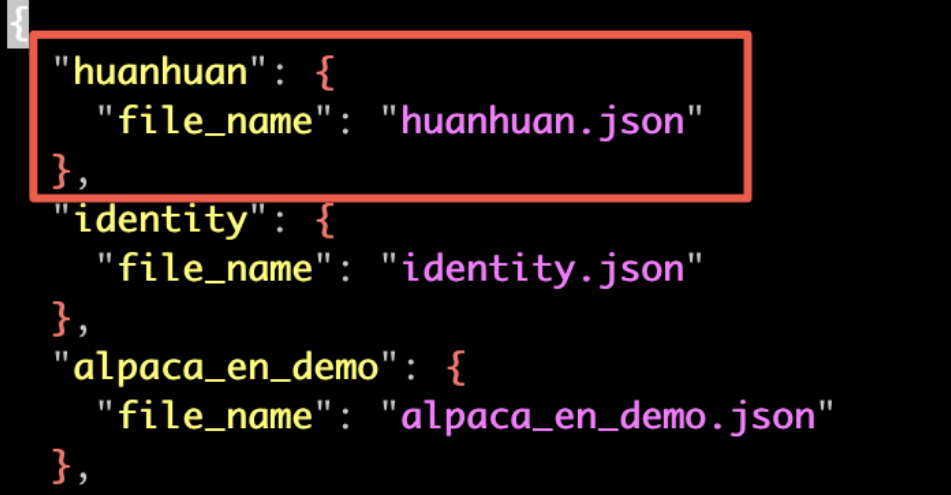
这里保存后,webui那边会实时更新,无需重启。
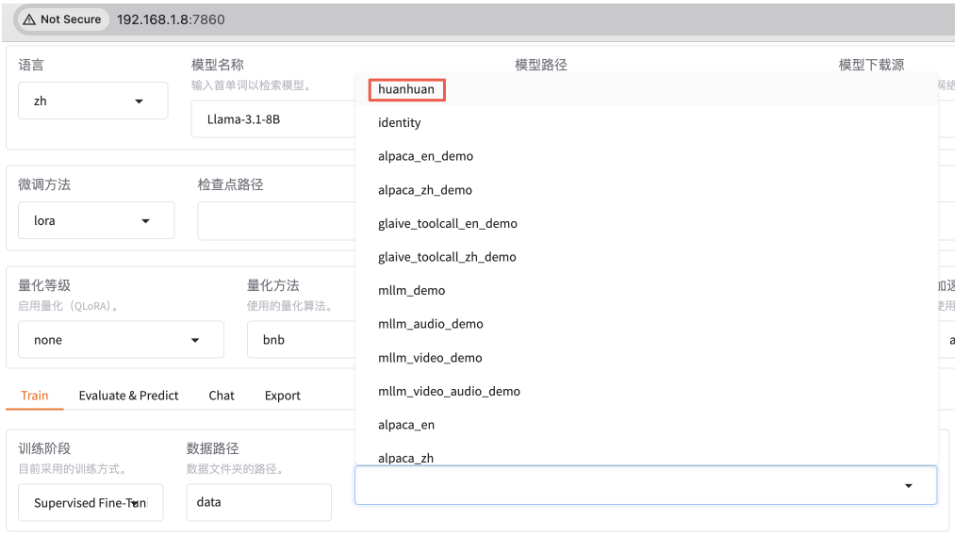
执行微调
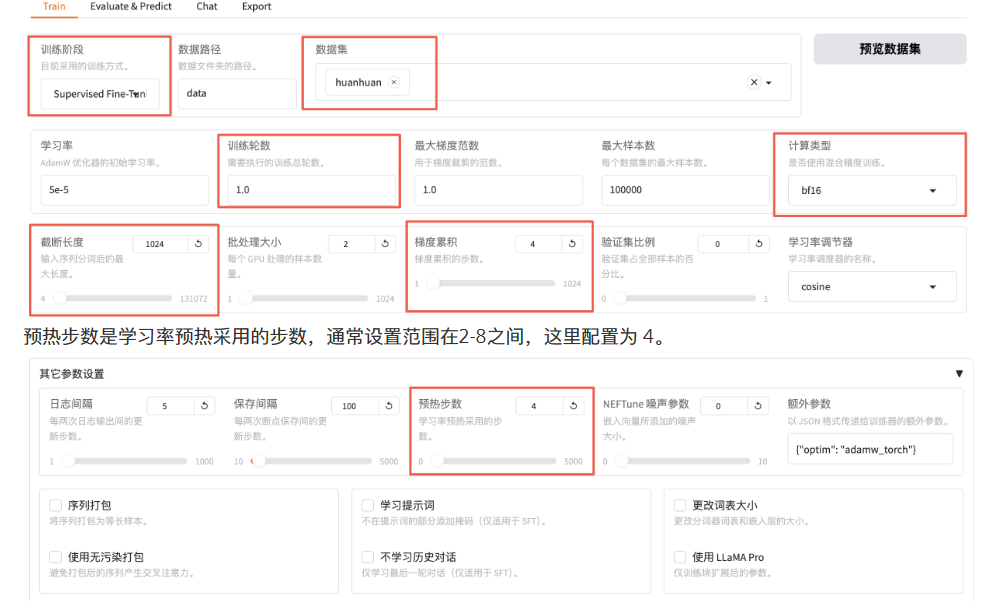
微调Qwen3-1.7B-Base基础大模型,方法选用LoRA。
- Base基础预训练模型。
- 没有经过指令微调。
- 适合继续预训练或指令微调。
- Base通常情况下输出质量不如Instruct版本。

使用huanhuan数据集,先训练1轮看看效果,若不理想再多训几轮。因数据集多为短问答,可将截断长度设小一点,为1024(默认2048)。梯度累计设为4。注意,计算类型选BF16,暂不支持FP4。
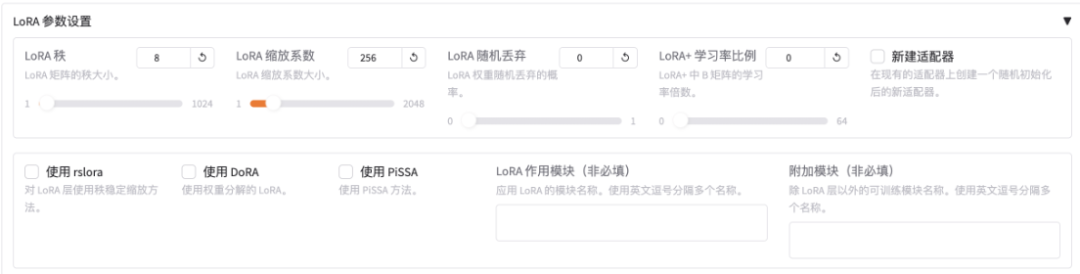
继续设置LoRA微调参数:
- LoRA秩:可看作学习广度,越大可能学得越多,微调效果可能越好,但非越大越好。太大易过拟合(书呆子,照本宣科,不知变通),此处设为8。
- LoRA缩放系数:可看作学习强度,越大效果可能越好;复杂场景数据集可设更大,简单场景可稍小。此处设为256。
预览训练指令并开始训练。
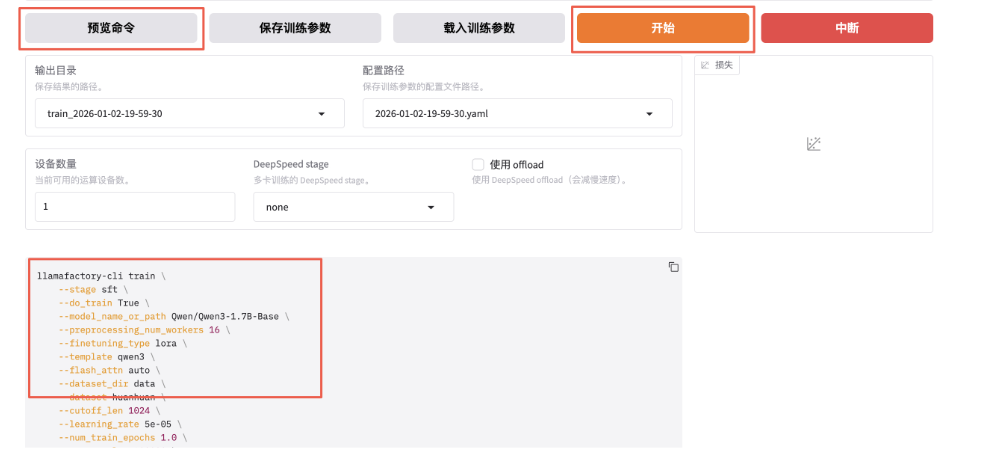
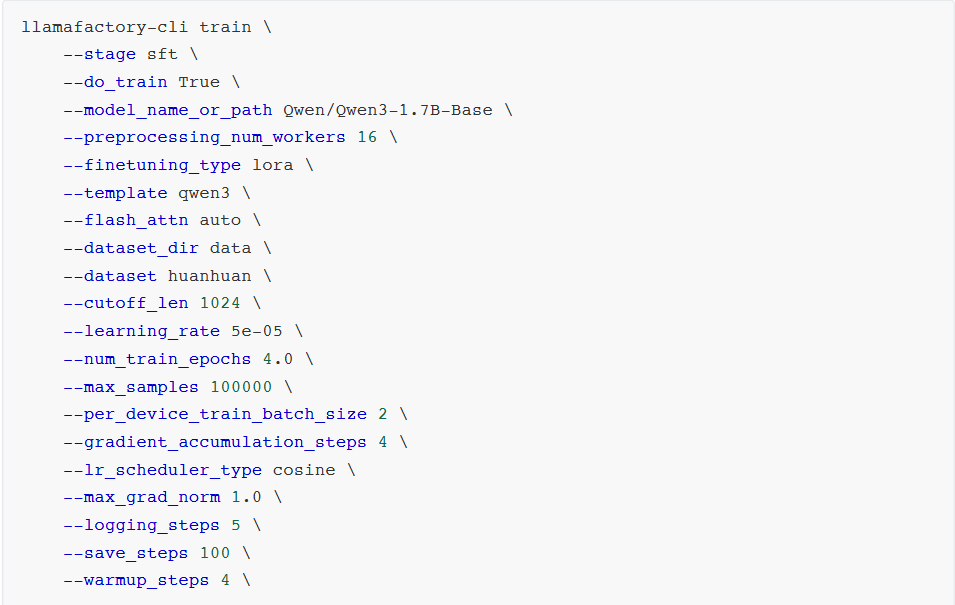
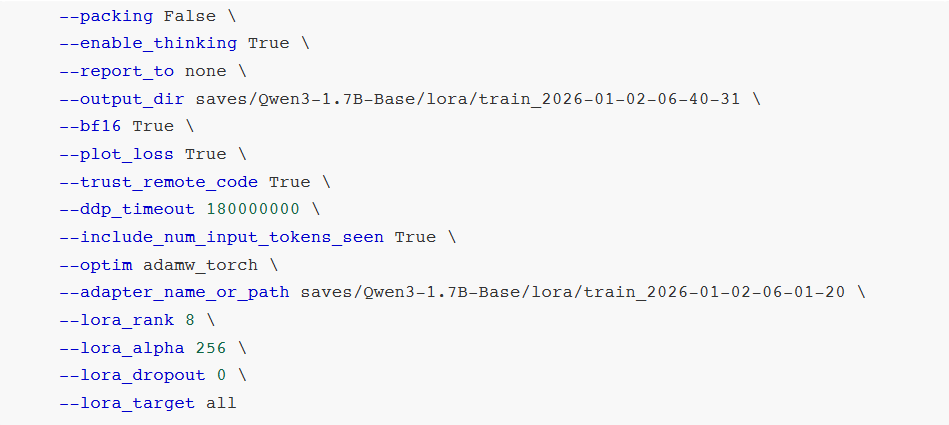
stage:指示当前训练阶段,枚举值sft、pt、rm、ppo等,此处为有监督指令微调,故为sft。 do_train:是否为训练模式。 dataset:使用的数据集。 dataset_dir:数据集所在目录,此处为data。 finetuning_type:微调训练类型,枚举值lora、full、freeze等,此处用lora。 output_dir:训练Checkpoint保存位置。 cutoff_len:训练数据集长度截断。 per_device_train_batch_size:每个设备上的batch size,最小为1,若GPU显存够大可适当增加。 bf16:训练数据精度格式。 max_samples:每个数据集采样多少数据。 val_size:随机抽取多少比例数据作为验证集。 logging_steps:定时输出训练日志,含当前loss、训练进度等。 adapter_name_or_path:LoRA适配器路径。 - 开始后,会启动一个新的训练进程。
若本地未找到模型,会先自动下载模型:

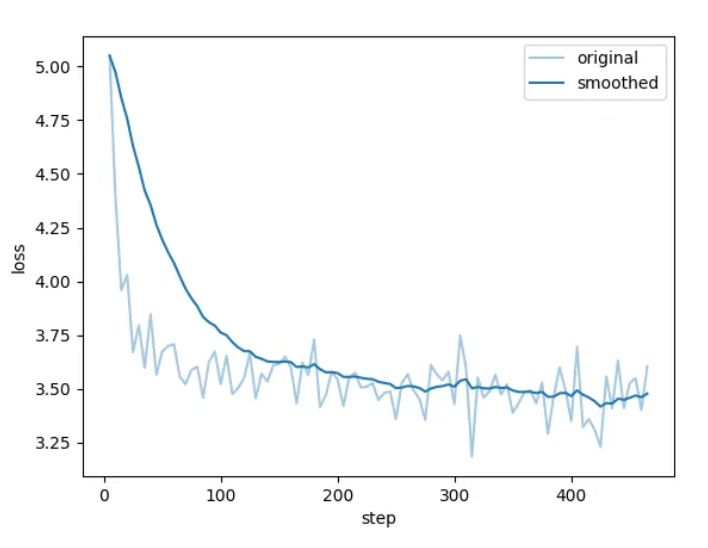
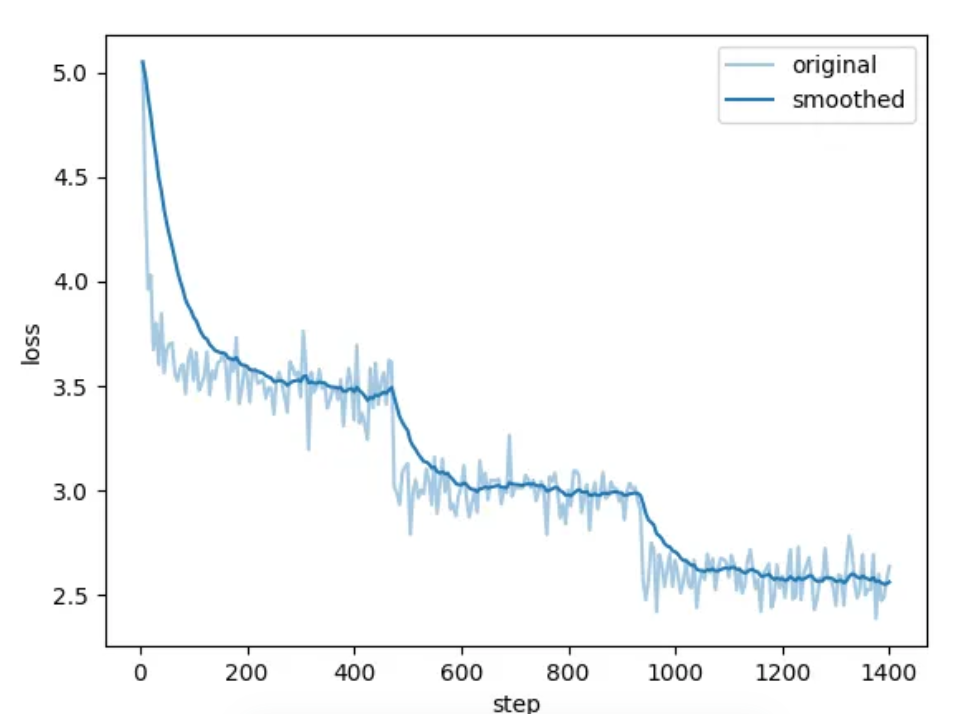
开始训练后可查看进度条和损失值曲线。
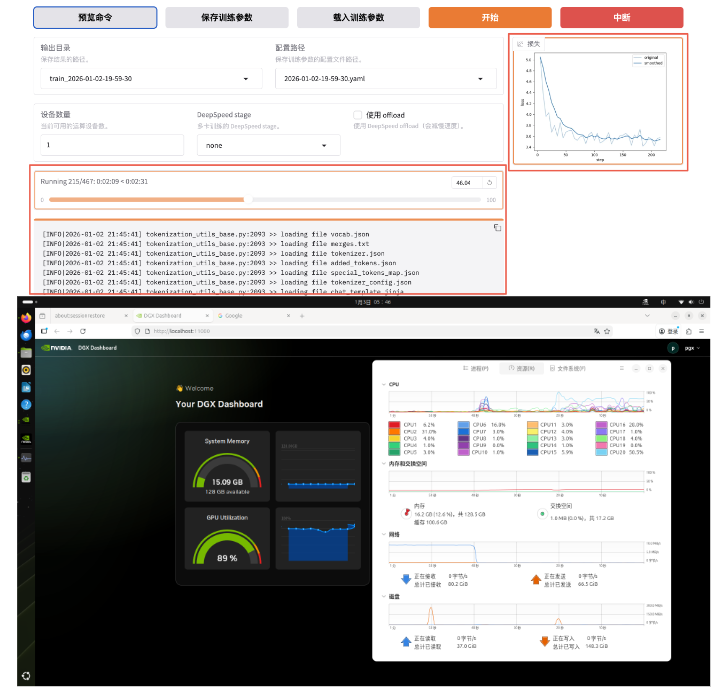
看到类似“训练完毕”即代表微调成功。
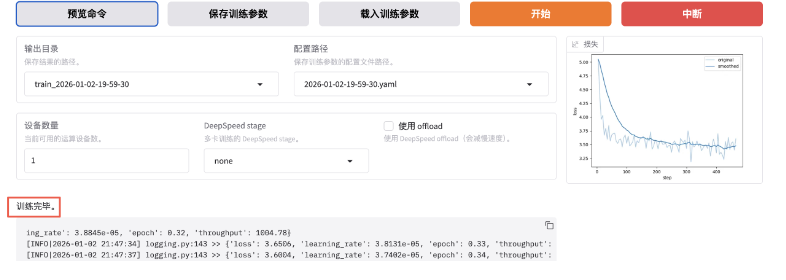
微调成功后,我们得到一个Checkpoint记录,下拉可选择刚刚微调好的模型。
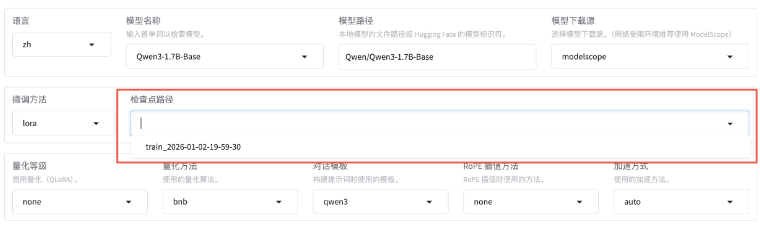
Checkpoint在后台存储位置是saves/Qwen3-1.7B-Base/lora/:
adapter开头的是LoRA适配器结果,后续用于模型推理融合。 training_loss和trainer_log等记录训练过程指标。 - 其他是训练时各种参数备份。
把窗口切换到chat,可点击加载模型。
加载好后即可在输入框发送问题,测试微调模型效果。
对LoRA微调模型进行推理,需应用动态合并LoRA适配器的推理技术。需通过finetuning_type参数告知使用了LoRA训练,再将LoRA模型位置通过adapter_name_or_path参数传入。

但渲染只训练了一次的效果很差。

若想切换回微调前模型,只需先卸载模型,选择想要的Checkpoint,再加载模型即可。若想重新微调,需修改红框中两个值。
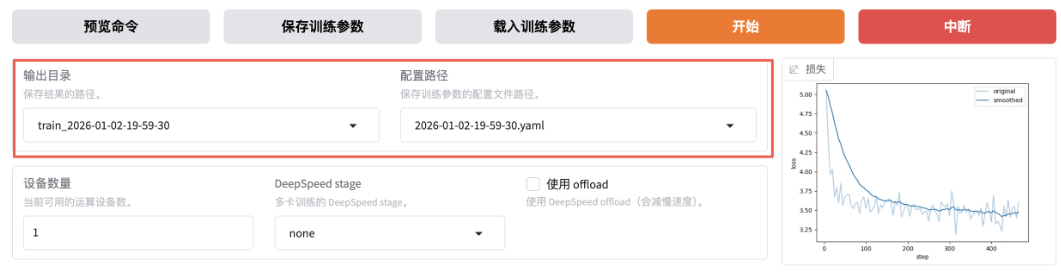
在经过3个Epoch训练后,效果越来越好。
批量推理和训练效果评估
上文人工交互测试并不严谨,通常需自动化批量测试,如使用BLEU和ROUGE等常用文本生成指标评估。
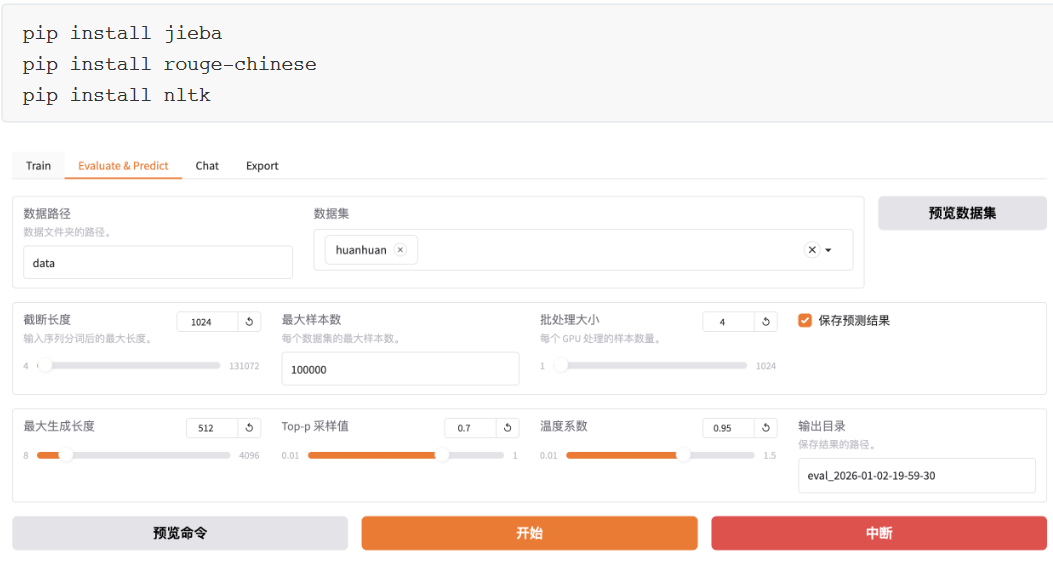
与训练脚本主要参数区别如下3个:
do_predict:现为预测模式。 predict_with_generate:现用于生成文本。 max_samples:每个数据集采样多少用于预测对比。
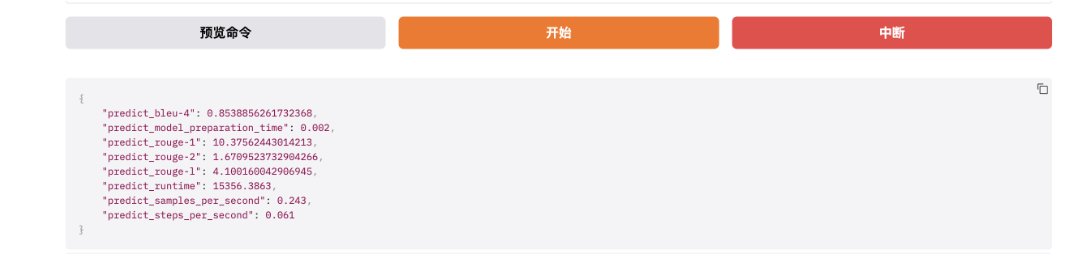
完成后查看微调质量评估结果,下面是训练效果评估指标。
质量类指标:BLEU-4 + ROUGE-1/2/L,衡量模型生成文本好坏、与标准答案匹配度、内容质量优劣。
BLEU-4:一种常用机器翻译质量评估指标。BLEU-4表示四元语法BLEU分数,衡量模型生成文本与参考文本间n-gram匹配程度(n=4)。值越高表示生成文本与参考文本越相似,最大值为100%。如下,BLEU-4=0.8539属高分,说明模型生成文本与标准答案语义贴合度极高、核心信息无遗漏、表达逻辑一致,对8B量级开源大模型而言属优秀水平。
predict_rouge-1:一种用于评估自动摘要和文本生成模型性能的指标。ROUGE-1表示一元ROUGE分数,衡量模型生成文本与参考文本间单个词序列匹配程度,即词汇层面匹配度,看生成文本是否用到标准答案里的核心词。值越高表示生成文本与参考文本越相似,最大值为100。如下,rouge-1=10.37属高分,模型能精准捕捉标准答案里的核心关键词,生成内容不会偏离主题,是优质模型核心特征。
predict_rouge-2:ROUGE-2表示二元ROUGE分数,衡量模型生成文本与参考文本间双词序列匹配程度,即短语/短句层面匹配度。同上,最大值为100。如下,rouge-2=1.67分偏低,但属正常现象:ROUGE-2要求连续两个词与标准答案完全一致,而大模型优势是语义一致但表达多样化泛化能力。大模型用不同短语表达相同意思,是生成能力体现,非缺陷。若rouge-2分数很高,反而说明模型泛化能力极差。
predict_rouge-l:ROUGE-L表示最长公共子序列匹配率,衡量模型生成文本与参考文本间最长公共子序列匹配程度,即整句语义连贯性与语序一致性。同上,最大值为100。如下,rouge-L=4.10中等分数,表示模型生成文本语义完整、逻辑通顺,虽句式与标准答案不同,但核心信息完整、语序合理,能准确回答问题。
若是文本摘要任务,则rouge-1一般20-40,rouge-2 5-15,rouge-L 10-25;若是开放问答/对话/指令遵循任务,则rouge-1 8-15,rouge-2 1-3,rouge-L 3-6。下列数值完全落在该区间内,属标准水平。
性能类指标:耗时/吞吐量/加载时间,衡量模型推理速度、效率、硬件利用率。
predict_model_preparation_time:表示模型加载和预热(显存初始化)耗时。如下,0.002s是优秀数值。
predict_runtime:本次批量推理总耗时,单位为秒。如下,15356秒 = 4小时16分钟。
predict_samples_per_second:每秒推理生成的样本数量,推理吞吐量核心指标,表示模型每秒钟生成的样本数量。用于评估模型推理速度。如下,0.243样本/秒,表示模型平均每4.1秒处理1条推理样本。
predict_steps_per_second:每秒执行的step数量,模型每秒钟能执行的step数量。模型每生成一个token就是一个step。如下,0.061 step/s表示每秒生成约0.061个token。
通过对比1 Epoch和3 Epoch微调结果可见,多轮训练后效果更好一些。

训练后也会在output_dir下看到如下新文件:
generated_predictions.jsonl:输出要预测的数据集原始label与模型predict结果。 predict_results.json:给出原始label与模型predict结果,并用自动计算的指标数据。

LoRA模型合并导出
通过不断“炼丹”直至效果满意后即可导出模型:将训练的LoRA模型与原始Base模型融合,输出一个完整模型文件。
检查点路径选择刚刚微调好的模型,切换到export,填写导出目录output/qwen3-1.7b-huanhuan。
导出完成即可在output目录下看到qwen3-1.7b-huanhuan目录。
部署运行微调后的大模型
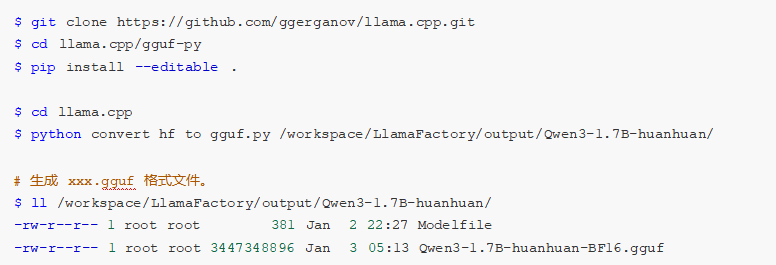
此处用Ollama + GGUF进行部署。
其中,GGUF是大模型存储格式,可对模型进行高效压缩,减少模型大小与内存占用,从而提升推理速度与效率。如下,安装GGUF并将微调后大模型格式转换。
另外,Ollama是大模型推理框架,适用于个人环境,简单而高效。
$ curl -fsSL https://ollama.com/install.sh | sh
$ ollama serve
$ ollama create qwen3-huanhuan -f /workspace/LlamaFactory/output/Qwen3-1.7B-huanhuan/Modelfile
$ ollama run qwen3-huanhuan


为什么ThinkStation PGX是AI开发者的创新加速器?
相信很多AI开发者都经历过与笔者同样的困境:一方面,公司仅有的公共GPU服务器要排队申请,好不容易排到却发现环境被改得面目全非,调试半天才能跑代码;另一方面,想用消费级显卡本地验证想法,却发现小几十GB显存连70B大模型都加载不动。资源短缺与环境割裂,让我们80%的时间浪费在等待与折腾上,而非真正的创新。
ThinkStation PGX这台巴掌大的设备确实能解决AI开发的关键痛点:
-
独占算力,不再排队:128GB统一内存 + FP4量化技术,单机支持200B模型推理或70B模型微调,相当于把2~4张高端显卡算力浓缩进桌面设备。从此不必再争抢资源,想研究什么AI技术、安装什么AI框架、开发什么AI应用,皆可立刻开始。
-
开箱即用的生产级环境:预装与NVIDIA数据中心完全一致的软件栈(CUDA、PyTorch),本地调试的模型与容器可直接部署到云端服务器,告别“开发环境能跑,生产环境崩掉”的尴尬。
-
移动式超算工作站:1.2kg重量 + 35dB静音设计,插上电源与显示器就能在工位、实验室甚至咖啡厅继续工作,研究进程不再被地点束缚。
在深度使用与体验后,笔者认为ThinkStation PGX非常适用于以下人群与场景:
- 个人AI开发者 / 小团队:独占资源,加速创新。
- 高校实验室 / 教育机构:低成本构建AI研究与教学平台,研究经费投入比GPU服务器更低。
- 企业研发部门:敏感数据本地微调,结合快速原型验证,兼顾安全与效率。
- 边缘计算:体积小巧、移动方便、算力强大,可塞进200B模型在边缘推理,促进AI边缘化应用。
简而言之,如果你厌倦了在共享GPU的等待队列中消磨创造力,受够了消费级显卡的显存天花板,ThinkStation PGX就是那台能够让我们把“超算装进背包”的终极武器——让开发环境沉默而可靠,让创新专注且自由。
 发表于 2026-1-31 18:31:39
|
查看: 287|
回复: 0
发表于 2026-1-31 18:31:39
|
查看: 287|
回复: 0
