写在前面的话
趴下继续睡。昨天在图书馆遇见一哥们。我问他怎么11点了才来,他说自己比较随性,主打一个出其不意。我让他展开说说。他讲了个事:之前老家人让他介绍工作,他满口答应。结果某天老家人直接找上门,推门进来时他正困得不行,趴在桌上睡觉。家人推醒他,他看了一眼,又趴下继续睡。老家人气得摔门而去,醒来后母亲责备他,说之前明明答应好的,怎么这个态度。他却反问:“答应的事一定要办吗?谁规定的。”后来,这哥们只要回村就会招人骂,但他慢慢也习惯了。
再后来,哥们受不了公司约束,出来单干,但毫无章法。有时连着三天不睡,有时连睡三天。最后做直播,明明写好了直播时间,结果没开播。可一些粉丝偏偏就喜欢他这种出其不意,觉得有趣,能给人带来快乐,他也因此赚到了钱。给我的感觉是,这哥们活出了“真我”,算是个奇人。
(文章底部有一张生活照片)
【今日技术关键词】:Python、Neo4j、列表搜索、获取标签
一、Python + Neo4j 接口开发
1. 列表搜索功能实现
需求描述:需要对节点属性列表(比如节点ID)增加搜索功能。因为当节点数量太多时,没有搜索基本无法操作。
开工实施:
第一步:确定搜索项
总共六项需要支持搜索的列表,数据结构如下:
{
"type":"node_labels",
"type":"entity_type",
"type":"source_id",
"type":"description",
"type":"id",
"type":"relation_labels",
}
注:最后一项 "type":"relation_labels" 需要特别注意,修改对应程序。
核心的搜索逻辑是使用 Neo4j Cypher 查询中的 CONTAINS 语句进行模糊匹配。代码实现如下(图中展示了关键函数):
第二步:上线部署
将修改好的代码部署上线,并同步更新接口文档。
2. 动态获取节点标签
需求描述:项目中需要获取图数据库里所有的节点标签(Label)。之前是写死在一个JSON配置文件里的,现在需要优化为动态获取。
开工实施:
第一步:规划时间段
任务执行时间记录。
第二步:编写获取程序
参考 Neo4j 自带的 CALL db.labels() 过程,编写一个带缓存和关键词过滤的 Python 函数。
CALL db.labels() YIELD label
WHERE label = ‘Person’
RETURN label
基于此,实现代码如下:
@lru_cache(maxsize=None)
def getLabelsDataUseCache(keyword,limit):
res_data = [{"id":"id"}]
sql = """
CALL db.labels() YIELD label
WHERE label CONTAINS ‘"""+keyword+”“'
WITH DISTINCT label AS distinct_column_name
limit """+limit+"""
RETURN {id: distinct_column_name} AS column_data;
"""
# writeMyLog(sql,get_caller_line_number()+'sql-getLabelsDataUseCache')
res_data = getSelectData(sql)
r_data=[]
for record in res_data:
r_data.append(record['column_data'])
if r_data:
res_data = r_data
return res_data
注:这里使用了 @lru_cache(maxsize=None) 装饰器进行缓存。因为线上环境是 Python 2.7,所以采用了这种旧的缓存方式。
第三步:功能测试
测试通过,功能正常。
3. 节点颜色动态配置
需求描述:返回给前端的数据中,需要根据节点的 entity_type(实体类型)赋予不同的颜色。颜色配置来源于一个JSON文件,当前配置较为混乱,需要优化。
当前的颜色配置文件现状如下(部分截图):
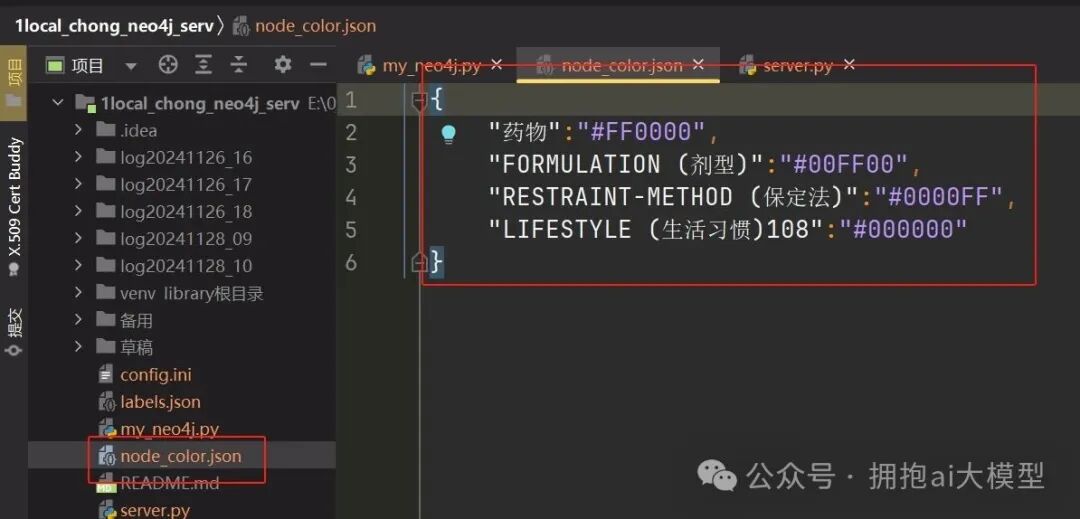
开工实施:
第一步:规划时间段
记录任务执行时间。
第二步:探查实体类型数量
首先,需要知道数据库里有多少种不同的 entity_type。执行以下 Cypher 查询:
MATCH (n)
WITH DISTINCT n.entity_type AS distinct_column_name
limit 10000
RETURN {id: distinct_column_name} AS column_data;
注:查询结果数据量很大,有上千条。这里只展示前几条示例。
第三步:优化颜色配置
由于实体类型过多,全部配置不现实。采取折中方案:先为最常用的前七种实体类型配置颜色,其他暂时不管。修改后的配置片段如下(示例):
完成配置文件的修改。
第四步:测试验证
测试修改后的颜色映射逻辑,运行正常。
二、PHP-Laravel 项目问题排查
1. 运行项目时的数据库建表错误
问题描述:数据库连接正常,但在执行迁移(migrate)建表时出现错误。错误信息提示索引长度超限。

问题分析:错误信息 Specified key was too long; max length is 1000 bytes 表明是索引字段长度过长,这是 Laravel 默认使用 utf8mb4 字符集时可能遇到的经典问题。
开工解决:
第一步:处理数据库配置
通常的解决方法是调整数据库配置或修改迁移文件。这里通过重新要了一个符合要求的数据库解决了连接问题。
第二步:尝试破解登录逻辑(分析阶段)
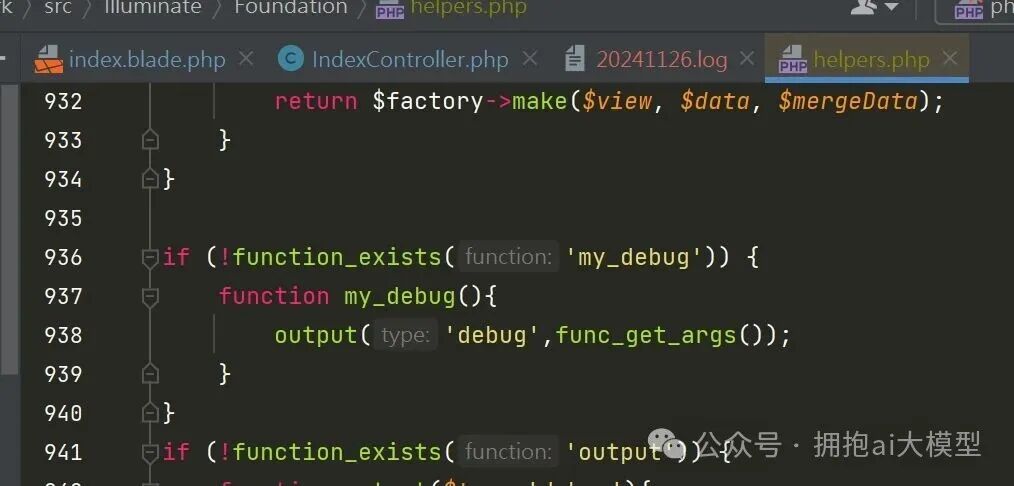
为了调试,尝试分析登录验证逻辑。首先在公共函数 helpers.php 中找到日志记录方法。
然后,查看登录控制器(LoginController)中的验证逻辑。
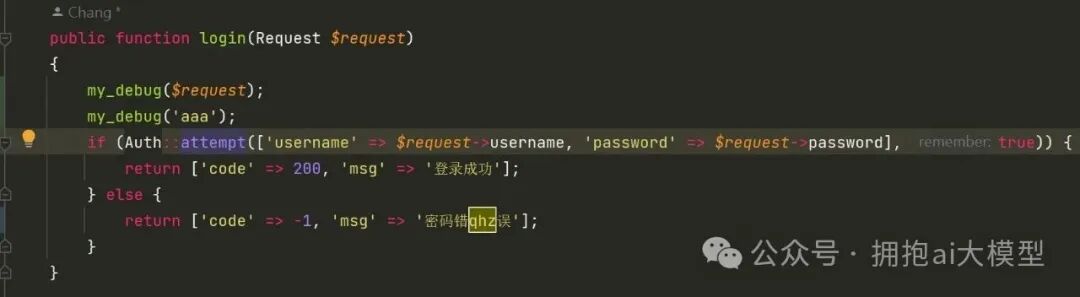
注:代码显示使用 Auth::attempt 进行验证,但当时不清楚密码的验证源在哪里。
第三步:绕过问题
由于后续对方直接提供了可用的账号密码,因此跳过了密码破解环节。接下来重点排查下一个问题。
2. 邀请码“已使用”状态异常
问题描述:后台生成的邀请码,在前台注册时明明未使用,系统却提示“该邀请码已被使用”。
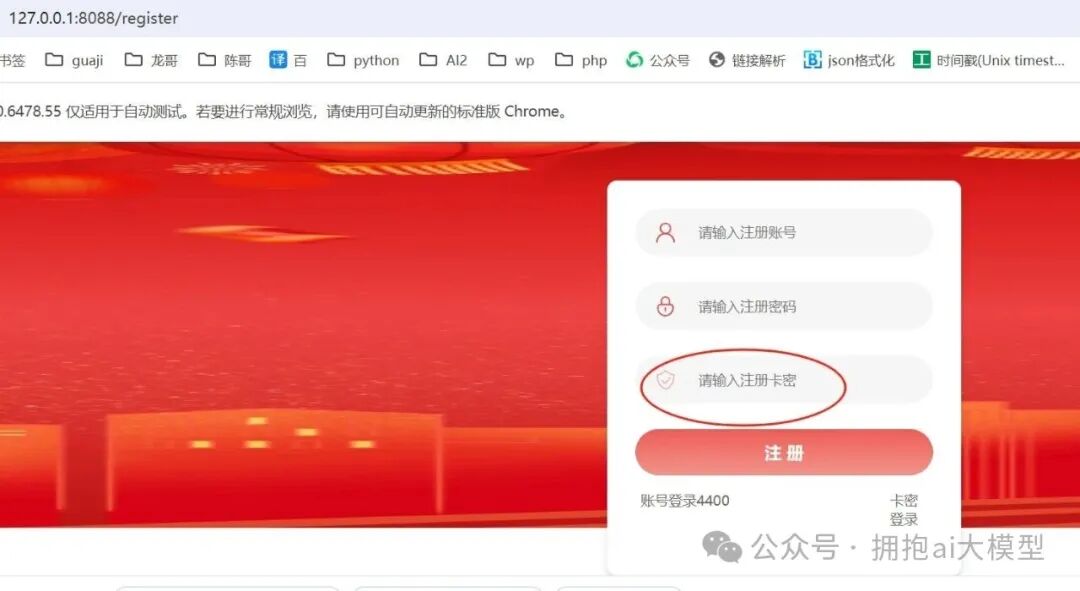
开工排查:
第一步:规划时间段
记录问题排查的时间段。
第二步:审查前台验证代码
需要从前端代码或API请求入手,检查邀请码状态验证的逻辑,看是否存在状态判断错误(如字段值误解)、缓存问题或并发逻辑错误。
第三步:测试与验证
根据代码审查结果进行测试,定位具体原因。
三、使用 Python 进行 PDF 数据抽取
1. 运行开源数据抽取项目
需求描述:需要运行一个开源的数据抽取框架(Unstructured IO),其功能是将PDF文档中的文字内容提取出来,输出到TXT等格式。
开工实施:
第一步:规划时间段
记录任务时间。
第二步:下载项目
项目地址:https://github.com/Unstructured-IO/unstructured
Clone 地址:https://github.com/Unstructured-IO/unstructured.git
第三步:运行示例代码
安装必要的依赖(如PDF处理扩展)后,运行以下示例代码:
import unstructured
from unstructured.partition.auto import partition
elements = partition(“paper.pdf”)
# 打印提取的元素
for element in elements:
print(element)
程序运行后,输出了PDF中的一些结构化文本内容。
2. 解析带目录的复杂PDF文章
需求描述:使用 unstructured 库的一个重要场景是解析带有目录的复杂PDF,希望能够按章节进行解析。现在找一篇带目录的PDF进行测试。
开工实施:
第一步:规划时间段
记录任务时间。
第二步:准备测试PDF
找到一篇带有详细目录的PDF文档(如技术手册或书籍)。
第三步:运行解析并遇错
使用同样的代码解析新PDF时,程序报错。错误栈信息最终指向:
pdf2image.exceptions.PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?
问题分析:这个错误表明 unstructured 库底层依赖的 pdf2image 模块需要 Poppler 工具包(一个PDF渲染库)的支持。在Windows系统上,需要单独下载 Poppler 并将其 bin 目录添加到系统的环境变量 PATH 中。
四、生活随拍
这张照片拍摄于2025年12月6日,18:22:24,是大宝过8岁生日时拍的。后来我又想了想图书馆那哥们的事,他算是歪打正着成功了,把“不守规则”打造成了个人特色,一身“明牌”,很气派。他恰好抓住了网红内容千篇一律的同质化痛点,把自己的非常规个性展现出来,反而有粉丝就爱这一口。这或许可以算作一种畸形的成功。
但是,他这种完全不顾及他人感受的做法,迟早会遭到反噬。比如,他和一个老板约好下周三晚上8点会面谈事,结果他既没去,也没提前通知,事后也不说明原因。用他的逻辑说:“约好就一定要去啊?” 长此以往,信用破产,可能就没人再愿意和他合作了。所以,他的路子风险极高,不建议模仿。

五、昨日消费记录
昨日的消费明细记录如下。

《本文完》
后记:技术开发中,我们既需要像优化Neo4j查询和PHP逻辑那样的严谨,也会遇到配置环境(如Poppler)这类琐碎但关键的问题。记录和分享这些具体的实践过程与踩坑经历,本身就是一个宝贵的成长路径。如果你也对Python自动化、数据处理或后端开发感兴趣,欢迎到云栈社区交流讨论,这里聚集了许多乐于分享的开发者。
 发表于 2026-2-2 00:11:55
|
查看: 155|
回复: 0
发表于 2026-2-2 00:11:55
|
查看: 155|
回复: 0
