用一个大家熟悉的场景——在线电商系统(比如一个类似淘宝或京东的系统)作为例子,贯穿始终。
1. 什么是软件可靠性?
想象一下,你正在一个重要的电商大促日(比如“双十一”)下单抢购心仪的商品。这时,你肯定希望页面加载飞快、搜索准确无误、支付流程顺畅。这种“关键时刻不掉链子”的能力,就是软件的可靠性。
在软件系统中,可靠性指的是系统在规定的条件下(如特定的硬件环境、网络状态或用户负载)和规定的时间内(例如一天、一个月或一年),能够持续、正确地完成预定功能的能力。简单说,就是软件能不能稳定干活、不出岔子。它关注的是系统能否长期无故障运行,即使遇到一些小问题,也能保持核心功能可用。
核心要点:规定条件、规定时间、规定功能。
对于我们的电商系统,“规定条件”可能是每秒要处理10万个用户请求;“规定时间”是要求在大促的24小时内;“规定功能”则包括用户能正常浏览商品、添加购物车和完成支付。
可靠性直接影响用户体验和业务收益。例如,如果支付系统不可靠,经常出错,用户会流失,公司可能损失收入和信誉。因此,设计软件时,可靠性是一个基础目标,它让系统值得信赖。
2. 可靠性的衡量指标:系统的“体检报告”
如何判断一个系统是否可靠?我们不能凭感觉,需要可量化的指标,就像通过体检报告了解身体健康状况一样。
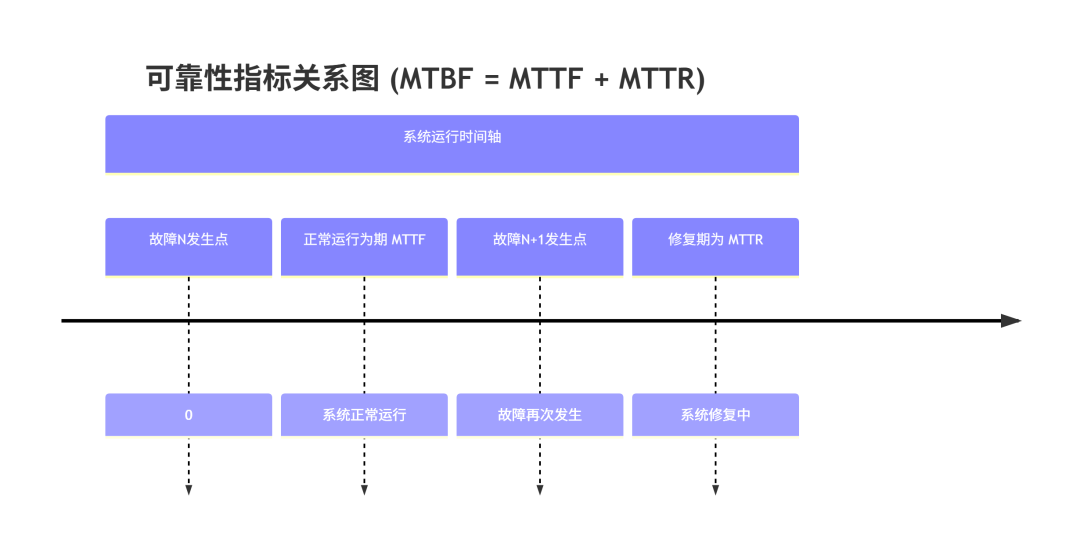
2.1 平均故障修复时间(MTTR)
它衡量的是从系统发生故障到被修复并恢复正常运行所需的平均时间,反映系统的修复能力。
计算公式:MTTR = 总故障修复时间 / 故障次数
电商系统示例
假设电商系统的订单服务在一年内发生了4次故障,每次从发现到修复完成分别耗时10分钟、30分钟、15分钟和5分钟。那么:
MTTR = (10 + 30 + 15 + 5) / 4 = 15分钟
这个结果说明,平均每次故障能在15分钟内修复,展现了较强的应急恢复能力。
2.2 平均无故障时间(MTTF)
它衡量的是系统在发生故障之前,能够连续正常提供服务的平均时间长度。这个指标直接反映了系统的业务持续性能力。MTTF 值越长,说明系统越稳定、越不容易出故障。
计算公式:MTTF = 给定时间周期内系统可正常运行总时间 / 故障次数
电商系统示例
继续上面的例子,假设这一年里订单服务累计正常运行时间为350天(即350 × 24 = 8400小时),发生了4次故障。那么:
MTTF = 8400小时 / 4 = 2100小时
这意味着,平均每运行2100小时(约87.5天)才会发生一次故障,稳定性相当不错。
2.3 平均故障间隔时间(MTBF)
从一次故障发生到下一次故障发生之间的平均时间间隔。MTBF 包含了系统正常运行的时间和修复故障的时间,因此它衡量的是系统可靠性的综合周期。
计算公式:MTBF = 多次故障之间系统运行总时间 / 故障次数 = MTTF + MTTR
电商系统示例
根据前两个指标,MTBF = MTTF + MTTR = 2100小时 + 0.25小时(15分钟) ≈ 2100.25小时。MTBF 略大于 MTTF,因为它把短暂的修复窗口也考虑在内,反映了故障发生的整体频率。
下面的图表直观展示了这三个时间指标在系统运行时间轴上的关系:
3. 可靠性设计战术:打造“打不垮”的系统
知道了目标,关键是如何实现。软件可靠性设计主要有三大战术思想:避错(不让错误发生)、检错(快速发现错误)和容错(错误发生也能扛住)。
3.1 避错技术:最好的防守是进攻
在软件的设计、编码和测试阶段,通过一系列严格的规范、方法和实践,尽可能地预防和消除潜在的错误、缺陷或漏洞,防止它们被引入到最终的生产系统中。这是一种 “预防优于治疗” 的主动性策略。
它的目标是从源头减少故障发生的可能性,从而直接提升系统的内在质量(MTTF)。
大白话类比
这就像建筑行业的安全规范。优秀的建筑师和施工队会在设计和建造阶段就严格遵守抗震、防火标准,使用高质量材料,确保大楼本身坚固安全,而不是等建好了再不停地打补丁。
3.1.1 防卫式程序设计
这是避错思想在编码层面的具体体现。其核心是预见各种异常(如输入错误、依赖故障),并主动嵌入检查与保护逻辑,使程序在遇到意外时能以可控方式处理,而非崩溃。
电商系统示例
在电商系统的商品搜索功能中,防卫式编程体现为:
- 输入校验:对用户输入的搜索关键词进行长度、字符类型检查,防止恶意输入或无效查询冲击数据库。
- 边界处理:当查询结果数量巨大时,程序应自动进行分页或限流,避免内存溢出导致服务崩溃。
- 异常捕获:调用搜索引擎服务时,如果对方无响应,应捕获超时异常,返回友好的提示或默认结果,而不是让整个搜索页面卡死。
3.2 检错技术:给系统装上“火情警报器”
在软件系统运行过程中,通过植入各种探针、监控点和数据收集机制,持续地、主动地探测系统的运行状态、性能指标和业务健康度,旨在故障发生时或发生前,能够快速、准确地发现、定位并发出警报。
它的目标是最大限度地缩短“故障发生”到“问题被发现”之间的时间,即降低平均故障检测时间,从而为后续的应急响应和修复(降低MTTR)争取宝贵时间。
大白话类比
这就像家中安装的烟雾报警器和智能摄像头。它们7x24小时不间断地监测环境,一旦检测到烟雾(异常指标)或发现陌生人(潜在威胁),立即发出刺耳的警报(告警通知),让你能第一时间采取措施,避免小火酿成大灾。
3.2.1 可观测性设计
这是现代检错技术的集大成者,通过日志(Logs)、指标(Metrics)、链路追踪(Traces) 这三大支柱,从外部观察理解系统内部状态。
在电商系统中,可观测性系统会这样工作:
- 指标(Metrics):监控大屏显示“订单支付成功率”从99.9%突然暴跌至80%。
- 告警:监控系统立即向运维团队发送告警短信。
- 日志(Logs):工程师快速查询支付服务的错误日志,发现大量“调用银行网关超时”的报错。
- 链路追踪(Traces):通过追踪一个失败支付请求的完整路径(用户 -> 电商前端 -> 支付服务 -> 银行网关),精准定位到是网络问题导致支付服务与银行网关之间的通信不稳定。整个过程可能在几分钟内完成,极大缩短了MTTR。
3.3 容错技术:让系统具备“抗打击能力”
预先在系统架构和代码设计中植入冗余、补偿和自动恢复的机制,使得当硬件、软件、网络等不可避免的局部发生故障时,系统整体仍能持续提供可接受的服务,或者能够自动、平滑地从故障中恢复,对用户屏蔽故障细节。
它的目标是降低单个故障点对系统整体的影响,保障业务的连续性,从而直接提升系统的可用性和可靠性。
大白话类比
这就像汽车的安全设计。安全带和安全气囊(冗余组件)不会阻止车祸(故障)发生,但能在车祸发生时保护乘客(核心业务)。ABS防抱死系统(自动恢复机制)能在急刹车时防止车辆失控,帮助驾驶员维持控制。这些都是“容错”设计。
3.3.1 集群与负载均衡
集群指将多台服务器(节点)组织成一个群体,通过冗余来消除单点故障。负载均衡是位于集群前端的流量调度器,负责将请求分发给健康的节点,并实现故障转移。
电商系统示例
电商系统的商品详情页服务部署在一个包含10台服务器的集群中,前方有一台负载均衡器。如果其中一台服务器突然宕机,负载均衡器在下次心跳检测失败后,会自动将后续所有查询商品信息的请求转发到其余9台健康的服务器上。对于正在浏览网站的用户来说,这个过程完全无感知,服务没有中断。
3.3.2 服务容错措施
在微服务架构下,单个服务故障可能引发链式反应(雪崩效应)。以下是关键的容错模式:
- 熔断:如同电路的保险丝。当支付服务调用银行网关的失败率在2分钟内超过50%时,熔断器会“跳闸”。在接下来的5秒内,所有新的支付请求不再尝试调用银行网关,而是直接快速返回“系统繁忙,请稍后再试”的提示。这避免了因持续重试而耗尽系统资源,给了下游服务恢复的时间。
- 降级:当系统压力巨大时,为了保证核心交易流程,可以暂时关闭一些非核心服务。例如,在大流量冲击下,电商系统可以暂时关闭“商品推荐”、“用户积分计算”等功能,将有限的CPU和数据库连接用于保障“浏览商品”、“下单”和“支付”核心路径的畅通。
- 限流:为了防止系统被突发流量冲垮,在入口处设置流量管制。例如,秒杀活动开始时,系统只允许每秒1000个用户进入抢购页面,后续到达的用户会看到一个“排队中”的友好提示,而不是导致服务器崩溃,所有人都无法访问。在实际应用中,限流功能的实现常依赖中间件,例如在网关层集成 Redis 或通过消息队列如 Kafka 来平滑流量。
3.3.3 N版本程序设计 与 恢复块
这是两种更高级的、用于极端关键场景的容错技术。
- N版本程序设计:针对同一功能,由不同团队独立开发多个版本(如支付校验逻辑开发三个版本),运行时同时执行并通过表决器采纳多数结果。优点是能屏蔽特定设计缺陷,但成本极高,通常仅用于航天、金融交易等对安全要求极高的系统。
- 恢复块:为功能准备一个主版本和多个备用版本。先执行主版本,若验证失败则回滚状态并切换至备用版本重试。这类似于遇到问题时的“备用方案”。
4. 记忆技巧与实战技巧
核心口诀:
可靠性是基石,避检容三战术。
避错根源防漏洞,检错快速现火情。
容错冗余保核心,熔断降级抗雪崩。
指标MTTF和MTTR,衡量系统稳定度。
5. 实战技巧
- 设计阶段就要考虑可靠性,而不是事后补救。在架构评审时,主动询问“这个服务的单点在哪里?”、“依赖失败怎么办?”。
- 权衡成本与收益。不是所有系统都需要“四个9”(99.99%)的可用性。一个内部管理系统和支付宝的支付系统,可靠性投入完全不同。
- 渐进式构建韧性。从最脆弱的核心服务开始,逐步应用熔断、限流、降级等模式。
- 混沌工程。在可控环境下,主动模拟故障(如随机关闭一台服务器),验证系统的容错能力,做到心中有数。
希望这篇文章能帮助你系统地理解软件可靠性的核心。如果你在实践中遇到具体的设计难题,欢迎到云栈社区与其他开发者交流探讨,共同打造更健壮的系统。
 发表于 2026-2-2 04:25:35
|
查看: 177|
回复: 0
发表于 2026-2-2 04:25:35
|
查看: 177|
回复: 0
