在分布式系统的广袤世界里,Dubbo 作为一款卓越的服务框架,连接着众多服务提供者与消费者。其中,负载均衡扮演着至关重要的角色,它负责合理分配服务请求,确保系统高效、稳定地运行。今天,我们就通过源码来解析 Dubbo 负载均衡的核心机制。
二、负载均衡概述
负载均衡是什么
负载均衡的核心目标,是把大量的网络请求均匀地分给多个服务器处理,从而防止单个服务器因压力过大而导致性能下降或崩溃。这就像是告诉公路通过多个车道来分流,以缓解交通拥堵。在网络世界里,负载均衡器就是那个负责引导请求的“交通指挥”,它接收客户端的请求,并按照预设的策略分发给后端多个服务器节点,从而提升系统的整体处理能力与可用性。
工作原理
负载均衡器位于客户端和后端服务器集群之间,它会实时监控后端服务器的状态与负载情况。当客户端请求到达时,负载均衡器根据预设的策略,从可用的服务器池中选择一台来处理。常见的策略包括:
- 轮询:将请求依次分配给后端的每台服务器。例如服务器 A、B、C,请求会按顺序 A->B->C->A... 循环分配,适合性能相近的服务器。
- 加权轮询:考虑到服务器性能的差异,为每台服务器设置权重。性能越好的服务器权重越高,获得更多的请求。例如 A 权重 2,B 和 C 权重 1,那么 A 大约会获得一半的请求,B 和 C 各约四分之一。
- 最少连接:将新的请求分配给当前连接数最少的服务器。这种策略适合长连接请求的场景,因为连接数少的服务器通常被认为负载较轻,有能力处理新请求。
- IP 哈希:根据客户端的 IP 地址计算哈希值,据此将请求分配到特定的服务器。这可以保证同一 IP 客户端的请求始终发往同一台服务器,适合需要保持会话状态的应用,例如购物车功能。
常见类型
- 硬件负载均衡器:专业的物理设备,如 F5 Big-IP。性能强大,能处理海量并发请求,稳定可靠,有专用芯片加速数据处理。但价格昂贵,部署维护成本高,适合对性能和稳定性要求极高的大型企业与数据中心。
- 软件负载均衡器:通过软件程序实现,如 Nginx、HAProxy。可以安装在通用的服务器硬件上,成本低、配置灵活。例如 Nginx,它本身可以作为 Web 服务器、反向代理和负载均衡器,通过简单的配置文件就能实现多种负载均衡策略。不过,其性能受限于服务器硬件,处理超大规模并发的能力通常不如硬件负载均衡器。
- 云负载均衡:云计算服务商提供的服务,如阿里云 SLB。基于云平台的弹性资源,能够按需自动伸缩,部署简单、成本可控,特别适合互联网创业公司或业务波动大的应用。
负载均衡的重要性
设想一个高并发的电商场景,大量用户同时请求商品信息。如果所有请求都集中在少数几台服务器上,而其他服务器却处于闲置状态,那么这些繁忙的服务器很可能因过载而响应缓慢甚至崩溃,严重影响用户体验。负载均衡正是通过将请求智能地分配到各个服务节点,避免了单点压力过大,从而提升了系统的整体性能和可用性。
Dubbo 负载均衡策略简介
在 Dubbo 的微服务架构中,它原生提供了多种负载均衡策略,例如随机(Random)、轮询(RoundRobin)、最少活跃调用数(LeastActive)和一致性哈希(ConsistentHash)等。每种策略都有其独特的适用场景,开发人员可以根据具体的业务需求进行灵活选择。
三、Dubbo 负载均衡源码剖析
整体架构
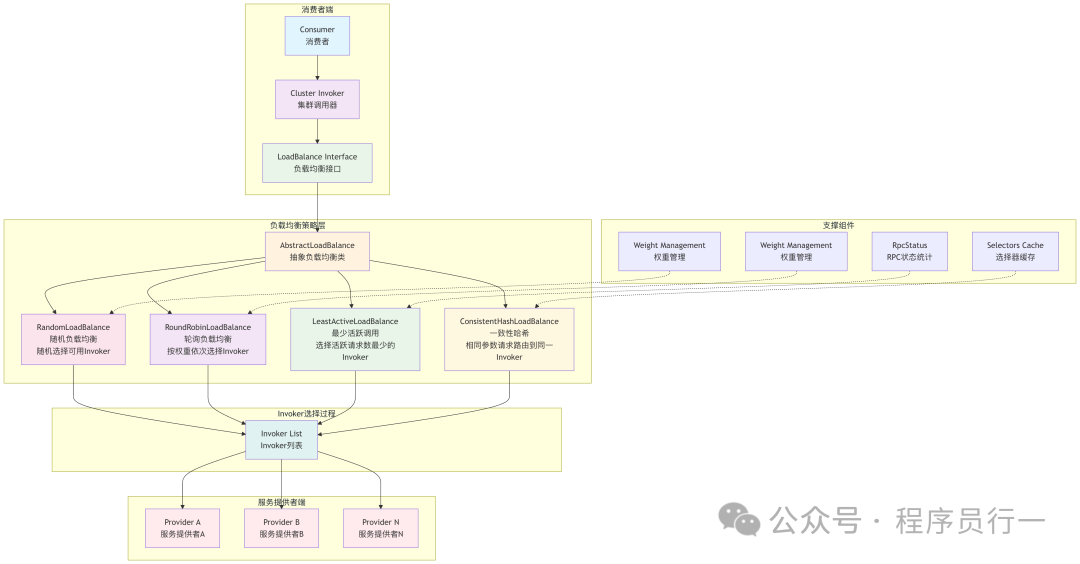
随机(Random)负载均衡
- 核心类与接口:
RandomLoadBalance 类是实现随机负载均衡的核心,它继承了 AbstractLoadBalance。在 Dubbo 的 SPI 机制下,通过配置可以轻松启用该策略。
- 选择逻辑实现:在
doSelect 方法中,首先计算所有服务提供者(Invoker)的权重总和。然后,生成一个介于 0 到权重总和之间的随机数。最后,遍历服务提供者列表,根据随机数与每个服务提供者权重的累积值进行比较,确定最终的选择。
整体流程图
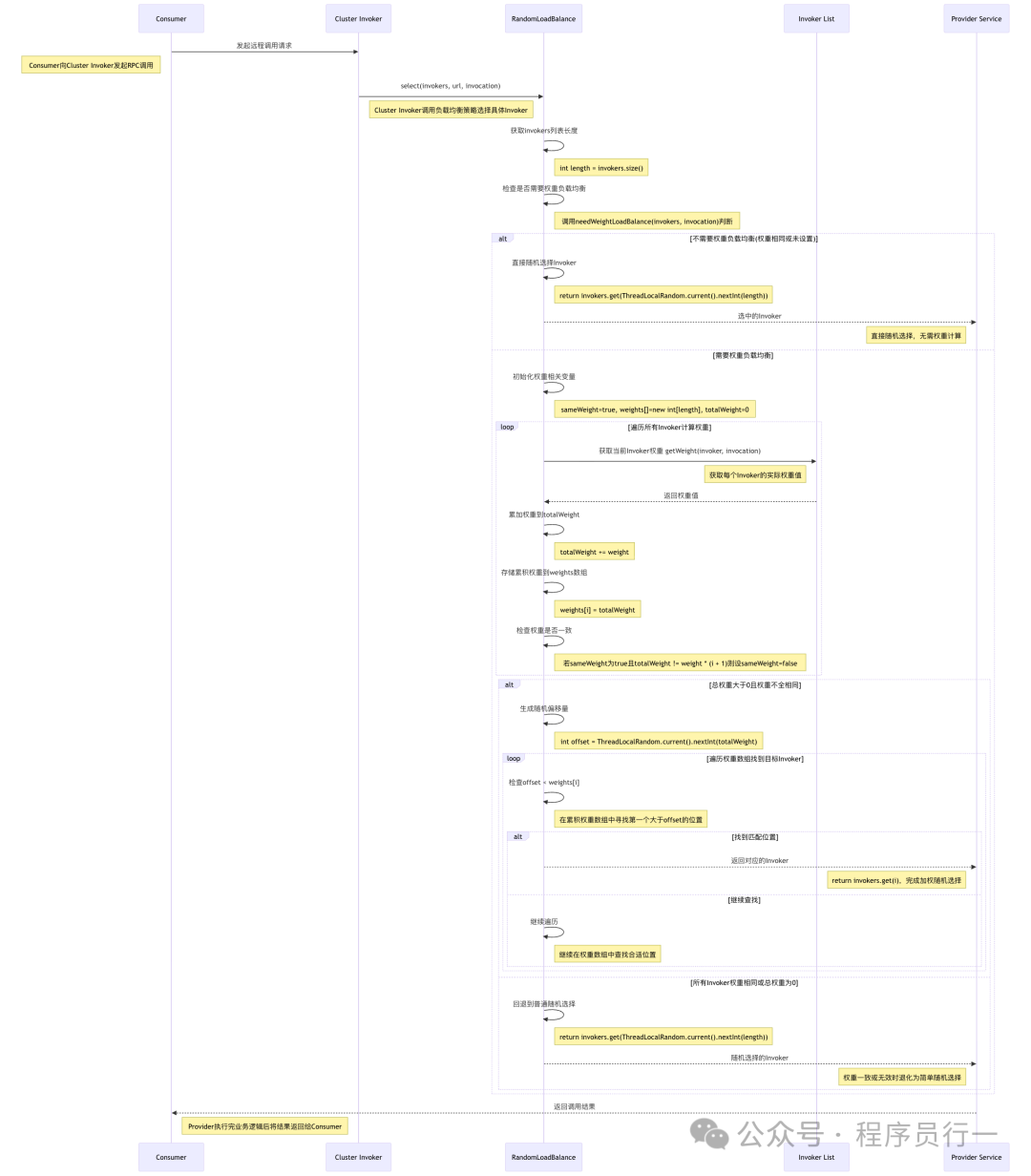
- 关键源码解读:
// RandomLoadBalance类实现随机负载均衡策略,实现LoadBalance接口
public class RandomLoadBalance extends AbstractLoadBalance {
// 选择逻辑实现方法
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 获取服务提供者列表的长度
int length = invokers.size();
// 用于标记所有服务提供者权重是否相同
boolean sameWeight = true;
// 用于存储每个服务提供者的权重
int[] weights = new int[length];
// 所有服务提供者权重总和
int totalWeight = 0;
for (int i = 0; i < length; i++) {
// 获取第i个服务提供者的权重
int weight = getWeight(invokers.get(i), invocation);
weights[i] = weight;
totalWeight += weight;
// 如果发现有不同权重,则标记为权重不同
if (sameWeight && i > 0 && weight != weights[0]) {
sameWeight = false;
}
}
// 如果权重总和大于0且权重不同
if (totalWeight > 0 && !sameWeight) {
// 生成一个0到权重总和之间的随机数
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
for (int i = 0; i < length; i++) {
offset -= weights[i];
// 当随机数减去当前服务提供者权重小于0时,选择该服务提供者
if (offset < 0) {
return invokers.get(i);
}
}
}
// 如果权重相同或者上述条件不满足,随机选择一个服务提供者
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}
}
轮询(RoundRobin)负载均衡
- 核心类与接口:
RoundRobinLoadBalance 类实现了轮询负载均衡策略。它通过维护一个原子变量来记录当前轮询的位置。
- 选择逻辑实现:在
doSelect 方法中,首先获取服务提供者列表的长度。然后,根据原子变量的当前值对列表长度取模,得到本次要选择的服务提供者索引。每次选择后,原子变量的值自动增加 1,从而实现循环选择。
整体流程图
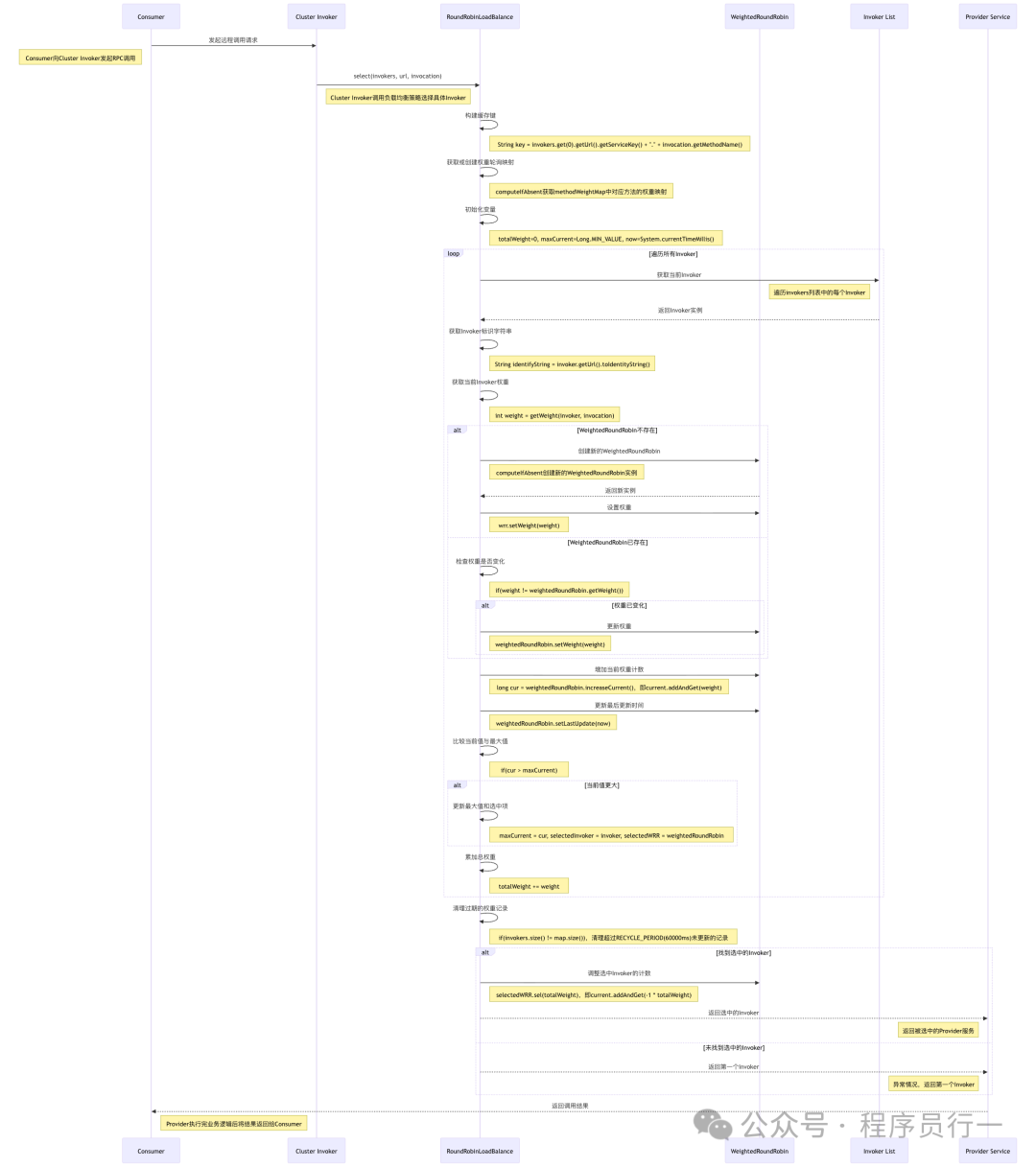
- 源码关键片段解读:
// RoundRobinLoadBalance类实现轮询负载均衡策略,实现LoadBalance接口
public class RoundRobinLoadBalance extends AbstractLoadBalance {
// 用于存储每个服务方法对应的原子变量,记录当前轮询位置
private final ConcurrentMap<String, AtomicPositiveInteger> sequences = new ConcurrentHashMap<>();
// 选择逻辑实现方法
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 生成一个唯一标识,由服务键和方法名组成
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
// 获取服务提供者列表的长度
int length = invokers.size();
// 获取或创建对应服务方法的原子变量
AtomicPositiveInteger sequence = sequences.computeIfAbsent(key, k -> new AtomicPositiveInteger());
// 根据原子变量的值对列表长度取模,得到当前要选择的服务提供者的索引
int index = sequence.getAndIncrement() % length;
return invokers.get(index);
}
}
最少活跃调用数(LeastActive)负载均衡
- 核心类与接口:
LeastActiveLoadBalance 类负责实现最少活跃调用数负载均衡策略。Dubbo 会记录每个服务提供者的活跃调用数(正在处理的请求数)和权重来进行选择。
- 选择逻辑实现:在
doSelect 方法中,首先遍历所有服务提供者,找出活跃调用数最少的那一个(或多个)。如果存在多个活跃数相同的服务提供者,则在这些候选者中根据权重进行二次选择。
整体流程图
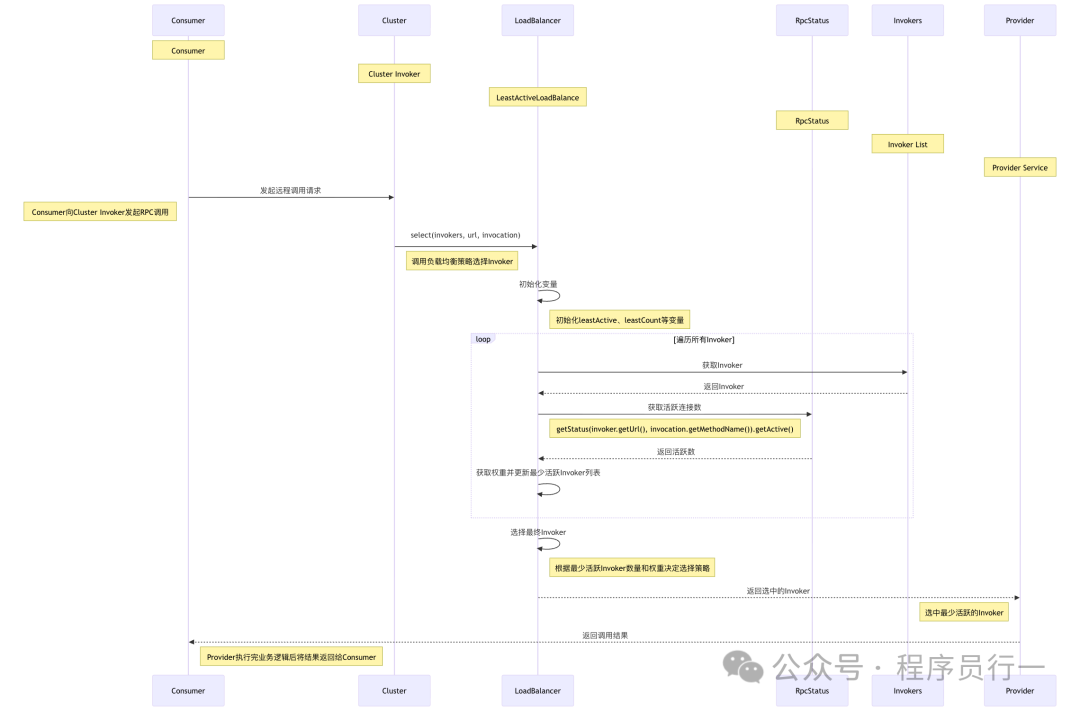
- 关键源码解读:
// LeastActiveLoadBalance类实现最少活跃调用数负载均衡策略,实现LoadBalance接口
public class LeastActiveLoadBalance extends AbstractLoadBalance {
// 选择逻辑实现方法
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 获取服务提供者列表的长度
int length = invokers.size();
// 最少活跃调用数,初始值为-1
int leastActive = -1;
// 具有最少活跃调用数的服务提供者数量
int leastCount = 0;
// 用于存储具有最少活跃调用数的服务提供者索引
int[] leastIndexs = new int[length];
// 所有具有最少活跃调用数的服务提供者权重总和
int totalWeight = 0;
// 第一个具有最少活跃调用数的服务提供者权重
int firstWeight = 0;
// 用于标记所有具有最少活跃调用数的服务提供者权重是否相同
boolean sameWeight = true;
for (int i = 0; i < length; i++) {
Invoker<T> invoker = invokers.get(i);
// 获取第i个服务提供者的活跃调用数
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
// 获取第i个服务提供者的权重
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), "weight", 100);
if (leastActive == -1 || active < leastActive) {
leastActive = active;
leastCount = 1;
leastIndexs[0] = i;
totalWeight = weight;
firstWeight = weight;
sameWeight = true;
} else if (active == leastActive) {
leastIndexs[leastCount++] = i;
totalWeight += weight;
if (sameWeight && i > 0 && weight != firstWeight) {
sameWeight = false;
}
}
}
// 如果只有一个服务提供者具有最少活跃调用数,直接返回该服务提供者
if (leastCount == 1) {
return invokers.get(leastIndexs[0]);
}
// 如果权重不同且权重总和大于0
if (!sameWeight && totalWeight > 0) {
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
for (int i = 0; i < leastCount; i++) {
int leastIndex = leastIndexs[i];
offset -= getWeight(invokers.get(leastIndex), invocation);
if (offset < 0) {
return invokers.get(leastIndex);
}
}
}
// 如果上述条件不满足,从具有最少活跃调用数的服务提供者中随机选择一个
return invokers.get(leastIndexs[ThreadLocalRandom.current().nextInt(leastCount)]);
}
}
一致性哈希(ConsistentHash)负载均衡
- 核心类与接口:
ConsistentHashLoadBalance 类实现一致性哈希负载均衡策略。它内部依赖 ConsistentHashSelector 类来完成具体的哈希环构建和节点选择。
- 选择逻辑实现:在
doSelect 方法中,首先为当前的服务提供者列表构建一个虚拟节点构成的一致性哈希环。当请求到来时,根据请求的某个特定参数(如用户ID)计算哈希值,然后在哈希环上顺时针查找,找到的第一个节点就是被选中的服务提供者。这种方式确保了相同参数的请求总是落到同一个服务节点上。
整体流程图
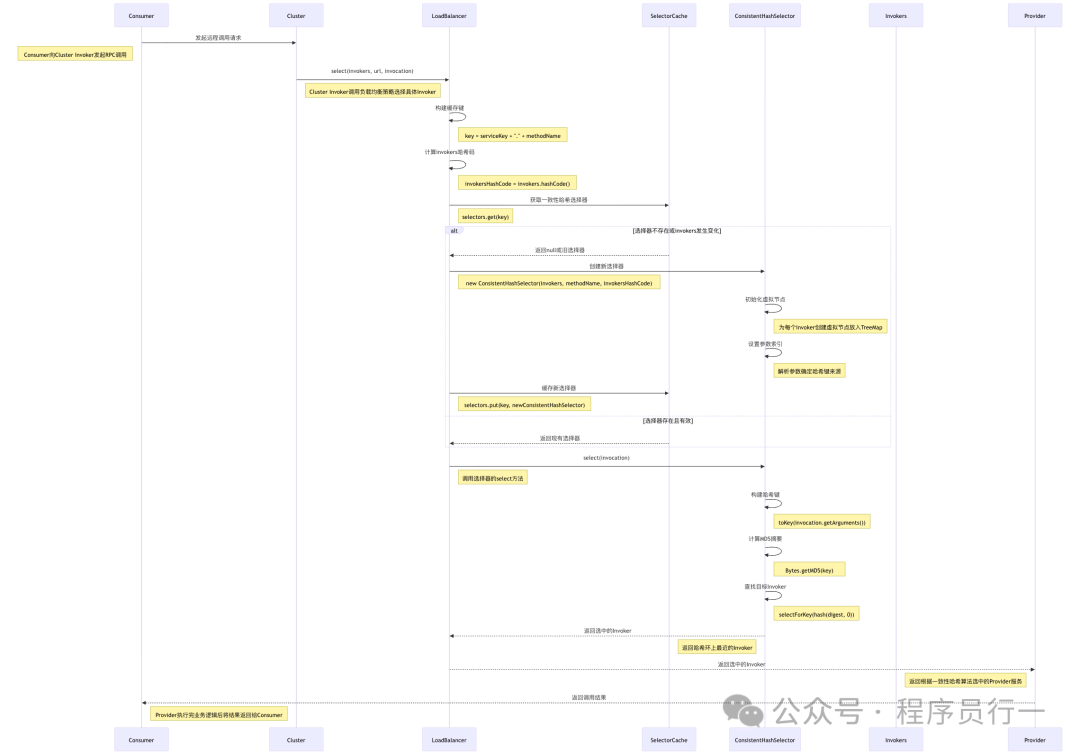
- 关键源码解读:
// ConsistentHashLoadBalance类实现一致性哈希负载均衡策略,实现LoadBalance接口
public class ConsistentHashLoadBalance extends AbstractLoadBalance {
// 用于存储每个服务方法对应的一致性哈希选择器
private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<>();
// 选择逻辑实现方法
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 生成一个唯一标识,由服务键和方法名组成
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
// 获取服务提供者列表的系统身份HashCode
int identityHashCode = System.identityHashCode(invokers);
// 获取对应服务方法的一致性哈希选择器
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
if (selector == null || selector.identityHashCode != identityHashCode) {
// 如果选择器为空或身份HashCode不匹配,创建新的选择器
selectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
return selector.select(invocation);
}
// 一致性哈希选择器内部类
private static final class ConsistentHashSelector<T> {
// 用于存储虚拟节点的TreeMap,按哈希值排序
private final TreeMap<Long, Invoker<T>> virtualInvokers;
// 服务提供者列表的系统身份HashCode
private final int identityHashCode;
// 用于存储参与哈希计算的参数索引
private final int[] argumentIndex;
public ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
this.virtualInvokers = new TreeMap<>();
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
// 获取虚拟节点数量,默认为160
int replicaNumber = url.getParameter("hash.nodes", 160);
// 获取参与哈希计算的参数索引字符串,以逗号分隔
String[] index = COMMA_SPLIT_PATTERN.split(url.getParameter("hash.arguments", "0"));
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
for (Invoker<T> invoker : invokers) {
// 获取服务提供者的地址
String address = invoker.getUrl().getAddress();
for (int i = 0; i < replicaNumber / 4; i++) {
// 计算地址和索引的MD5值
byte[] digest = md5(address + i);
for (int h = 0; h < 4; h++) {
// 计算哈希值并放入TreeMap
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
}
}
// 根据请求选择服务提供者的方法
public Invoker<T> select(Invocation invocation) {
// 根据请求参数生成键
String key = toKey(invocation.getArguments());
// 计算键的MD5值
byte[] digest = md5(key);
// 根据哈希值选择服务提供者
return selectForKey(hash(digest, 0));
}
// 根据哈希值选择服务提供者的具体方法
private Invoker<T> selectForKey(long hash) {
// 获取大于等于该哈希值的第一个节点
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash);
if (entry == null) {
// 如果没有找到,选择第一个节点
entry = virtualInvokers.firstEntry();
}
return entry.getValue();
}
// 计算MD5值的方法
private byte[] md5(String value) {
try {
MessageDigest md = MessageDigest.getInstance("MD5");
return md.digest(value.getBytes(StandardCharsets.UTF_8));
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
// 从MD5值中提取哈希值的方法
private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
// 根据请求参数生成键的方法
private String toKey(Object[] args) {
StringBuilder buf = new StringBuilder();
for (int i : argumentIndex) {
if (i >= 0 && i < args.length) {
buf.append(args[i]);
}
}
return buf.toString();
}
}
}
四、Dubbo 负载均衡策略的应用与选择
实际应用场景举例
- 随机负载均衡的应用:在对请求分配没有特殊要求,只希望实现简单、快速均匀分配的静态场景中表现良好。例如,提供相同静态资源下载的服务集群。
- 轮询负载均衡的应用:最适合服务提供者性能相近、无状态的服务场景。例如,一些提供简单计算或查询的微服务。
- 最少活跃调用数负载均衡的应用:在服务提供者性能差异明显时优势突出。它能将新请求智能地导向当前负载最轻(活跃请求最少)的节点,最大化利用高性能服务器,提高系统整体吞吐量。
- 一致性哈希负载均衡的应用:这是保证“会话粘性”或“数据局部性”的关键。典型场景是分布式缓存(如 Redis 集群的路由)或需要保证同一用户请求始终由同一台服务器处理的业务(如用户会话管理)。
如何选择合适的负载均衡策略
选择合适的 算法 需要综合考量:
- 考虑服务提供者的性能:如果集群节点性能均衡,轮询或随机是简单有效的选择;如果节点性能参差不齐,最少活跃调用数策略能更好地实现负载均衡。
- 业务对请求一致性的要求:如果业务逻辑要求相同参数的请求必须落到同一服务节点(如缓存、会话),一致性哈希是唯一选择;若无此要求,则可选用其他策略以获得更好的均衡性。
- 系统的稳定性和可扩展性:一致性哈希在节点增删时,能保证大部分请求的映射关系不变,对系统冲击较小,适合频繁扩缩容的场景。而轮询和随机策略在节点变化时,请求会重新分布。
五、总结与展望
核心内容回顾
本文深入剖析了 Dubbo 框架中负载均衡的源码实现,详细解读了随机、轮询、最少活跃调用数和一致性哈希这四种核心策略的工作原理和代码细节。通过对 doSelect 方法等核心流程的分析,我们清晰地看到了每种策略是如何根据权重、活跃数或哈希值来做出路由决策的,从而保障整个 分布式系统 的稳定与高效。
未来发展展望
随着云原生和微服务架构的演进,负载均衡技术也在不断发展。未来,我们可以期待 Dubbo 等框架集成更智能的负载均衡机制,例如基于实时指标(如CPU、内存、网络IO)的动态权重调整,或结合机器学习预测节点负载趋势,实现真正意义上的自适应负载均衡。理解这些基础算法的原理,将为我们应用和优化更高级的特性打下坚实的基础。
希望这篇源码级的解析能帮助你更深刻地理解 Dubbo 的负载均衡机制。如果你对微服务架构或 Java 后端开发有更多兴趣,欢迎到 云栈社区 与其他开发者交流探讨。
 发表于 2026-2-2 04:19:12
|
查看: 145|
回复: 0
发表于 2026-2-2 04:19:12
|
查看: 145|
回复: 0
