在 Linux 运维工作中,Shell 脚本是实现自动化部署、监控告警和批量操作的核心工具,是每位运维工程师必须掌握的基本功。扎实的 Shell 基础,也是进一步学习 Python、Perl 等更高级语言的有力跳板。而脚本执行后的退出状态码(简称退出码),则是实现流程精细控制的关键。理解并熟练运用它,能让你的脚本更健壮、更智能。
今天,我们就来深入聊聊 Shell 脚本退出码的使用技巧与实践场景。
什么是退出码?
在 Linux Shell 环境中,每一条命令或脚本执行完毕后,系统都会返回一个介于 0 到 255 之间的整数值,这个值就是退出码(Exit Code)。它的核心作用是向 Shell 反馈命令或脚本的执行状态,后续的操作可以根据这个状态来决定接下来的执行逻辑,例如是继续执行还是回滚操作。
这个退出码会被临时存储在特殊的环境变量 $? 中,只需一条简单命令即可查看上一条命令的执行结果:
echo $?
# 输出0,代表命令成功结束
# 输出非0值,代表命令执行失败
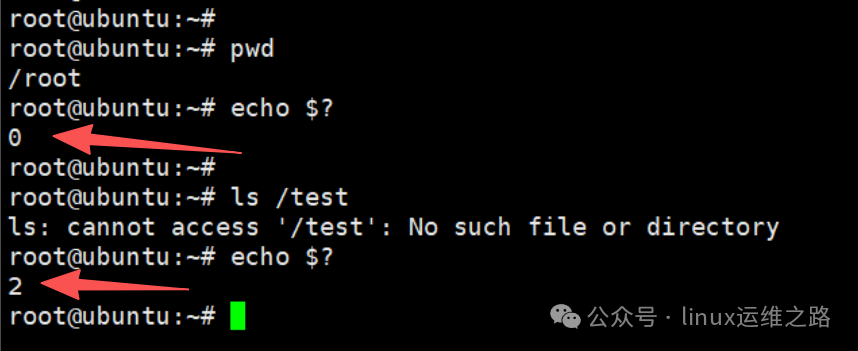
图中展示了在终端中执行 pwd(成功,返回0)和 ls /test(失败,返回2)后,通过 echo $? 查看退出码的过程。
Linux 系统定义了一系列标准的退出码,掌握这些常见代码的含义,能帮助运维工程师快速定位问题根源:
| 退出码 |
含义描述 |
典型场景 |
| 0 |
命令成功结束 |
正常执行的 ls、cp、mkdir 等命令 |
| 1 |
一般性未知错误 |
语法正确但执行逻辑出错(如脚本中变量未定义) |
| 2 |
不适合的 shell 命令 |
命令参数错误或选项不合法 |
| 126 |
命令无法执行 |
文件存在但无执行权限(如 chmod -x script.sh 后执行脚本) |
| 127 |
未找到命令 |
命令名拼写错误(如将 ls 写成 lss)或命令未在 PATH 路径中 |
| 128 |
无效的退出参数 |
exit 命令后跟随非数字参数(如 exit “error") |
| 128+x |
与 Linux 信号 x 相关的严重错误 |
128+2=130(代表通过 Ctrl+C 终止)、128+9=137(代表进程被 kill -9 强制终止) |
| 130 |
通过 Ctrl+C 终止的命令 |
执行脚本时手动按 Ctrl+C 中断 |
| 255 |
正常范围之外的退出状态码 |
自定义退出码超出 0~255 范围时的默认返回值 |
如何主动控制脚本退出码?
默认情况下,Shell 脚本执行完毕后,会以脚本中最后一条命令的退出码作为整个脚本的退出码。但在实际工作中,我们常常需要主动指定退出码来精确表达脚本的执行结果,这就需要用到 exit 这个内置命令。
exit 命令有两种基础用法:
第一种是退出并返回指定的退出码,语法格式为:
exit n # n为0~255的整数,代表脚本的退出码
第二种是退出并沿用前一条命令的退出码,语法格式为:
exit # 无参数时,使用上一条命令的退出码作为脚本退出码
使用 exit 命令时有两点需要注意:
- 退出码范围:指定的值必须在 0~255 范围内。如果指定了大于 255 的值(例如
exit 300),系统会自动取该值除以 256 的余数作为实际退出码(300 ÷ 256 = 1 余 44,最终退出码为 44)。
- 立即终止:脚本中执行
exit 命令后,脚本会立即终止,后续的所有代码都不再执行。因此,需要合理控制 exit 的执行时机,避免提前意外退出。
退出码的实际应用场景
掌握了基本概念后,我们来看看退出码在真实的 Bash 脚本和运维工作中如何大显身手。
1. 实现条件化流程控制
在自动化脚本中,最经典的应用就是通过判断前一步命令的退出码,来决定是否继续执行后续操作。例如,在部署应用时,我们可以先执行部署命令,再通过校验退出码来判断部署结果:
#!/bin/bash
# 部署应用
docker run -d --name app app:v1
# 校验部署是否成功(退出码0为成功)
if [ $? -eq 0 ]; then
echo "应用部署成功"
# 继续执行健康检查等后续操作
curl http://localhost:8080/health
else
echo "应用部署失败"
exit 1 # 部署失败,脚本退出并返回错误码
fi
2. 脚本间状态传递与协同工作
当多个脚本需要协同工作时(例如脚本 A 调用脚本 B),退出码是传递执行状态的有效方式。比如,一个主脚本调用备份脚本,只有备份成功后才继续执行同步脚本:
# 脚本A(主脚本)
#!/bin/bash
echo "执行数据备份脚本..."
./backup.sh
# 若备份脚本返回0(成功),则执行同步脚本
if [ $? -eq 0 ]; then
echo "备份成功,执行数据同步..."
./sync.sh
else
echo "备份失败,终止执行"
exit 1
fi
3. 结合日志记录与告警触发
在关键的维护任务(如数据库备份)中,我们可以结合退出码来记录详细的错误日志,并触发告警机制(如发送邮件或钉钉通知):
#!/bin/bash
# 数据库备份
mysqldump -u root -p123456 db > db_backup.sql
if [ $? -ne 0 ]; then
# 记录错误日志
echo "$(date) 数据库备份失败" >> /var/log/backup_error.log
# 触发钉钉告警(调用告警脚本)
./dingtalk_alert.sh "数据库备份失败,请立即检查!"
exit 1
fi
最佳实践与避坑指南
为了让你的脚本更加可靠和易于维护,这里有几个关于使用退出码的最佳实践:
- 主动设置关键步骤的退出码:对于备份、部署、数据同步等关键业务步骤,执行后应主动使用
exit n 返回明确的状态码。这能大幅提升问题定位和 Troubleshooting 的效率。
- 避免过度依赖默认退出码:如前所述,默认以最后一条命令的退出码为准。如果最后一条命令是像
echo “Done” 这样的“无关命令”(它几乎总是成功的),可能会掩盖脚本真实的执行结果。一个良好的习惯是在脚本末尾主动指定 exit 0(成功)或 exit 1(失败)。
- 处理脚本被中断的情况:当脚本可能被手动中断(如按 Ctrl+C)时,可以通过捕获信号量(如 SIGINT),在信号处理函数中返回特定的退出码(如 130),这有助于后续的日志分析和自动化处理。
- 建立团队内的自定义退出码规范:在多人协作的团队中,可以定义一套内部的退出码规则。例如:100 表示配置文件错误,101 表示网络异常,102 表示权限不足等。这套“密语”能让团队成员一眼看出问题所在,极大提升脚本的可读性和可维护性。当然,如果你是个人开发者,学习一门像 Perl 这样的脚本语言来编写更复杂的工具也是不错的选择,但清晰的退出码约定在任何语言中都是好习惯。
希望这篇关于 Shell 脚本退出码的梳理,能帮助你写出更具鲁棒性的自动化脚本。如果你在实践中遇到了其他有趣的用例或问题,欢迎到云栈社区的相关板块与大家交流探讨。
 发表于 2026-2-3 08:11:23
|
查看: 219|
回复: 0
发表于 2026-2-3 08:11:23
|
查看: 219|
回复: 0
