在C语言的编程实践中,巧妙地使用宏定义(Macro)是提升代码质量、增强可移植性和预防错误的重要手段。与函数调用相比,宏在预处理阶段进行文本替换,虽然需要谨慎处理副作用,但在某些场景下能带来性能优势和极大的灵活性。许多成熟的软件和嵌入式系统代码库中都沉淀了大量经典的宏定义,它们像瑞士军刀一样,能高效解决特定问题。
本文将梳理和解析19个在实际项目中高频出现的C语言宏定义技巧,涵盖类型安全、内存操作、结构体处理、位运算、字符判断以及常见陷阱规避等多个方面,希望能为你的C语言开发工具箱增添几件得心应手的利器。
1. 防止头文件被重复包含
这是头文件编写的“黄金法则”。通过条件编译,可以确保头文件中的内容在同一个编译单元内只被引入一次,避免因重复定义导致的编译错误。
#ifndef COMDEF_H
#define COMDEF_H
// 头文件的实际内容
#endif

2. 统一类型定义,增强跨平台移植性
不同平台或编译器下,基础类型(如 int、long)的字节长度可能不同。通过typedef和宏进行统一封装,可以极大提高代码在不同环境下的可移植性。
typedef unsigned char boolean; /* 布尔值类型 */
typedef unsigned long uint32; /* 无符号32位整型 */
typedef unsigned short uint16; /* 无符号16位整型 */
typedef unsigned char uint8; /* 无符号8位整型 */
typedef signed long int32; /* 有符号32位整型 */
typedef signed short int16; /* 有符号16位整型 */
typedef signed char int8; /* 有符号8位整型 */

3. 获取指定地址上的字节或字
直接通过地址进行内存访问时,这类宏提供了清晰的语义,常见于底层驱动或对内存布局有精确要求的场景。
#define MEM_B(x) (*((byte*)(x)))
#define MEM_W(x) (*((word*)(x)))

4. 求最大值与最小值
非常经典且实用的宏。注意参数被括号包围,这是为了避免在替换时因运算符优先级导致错误。
#define MAX(x, y) (((x) > (y)) ? (x) : (y))
#define MIN(x, y) (((x) < (y)) ? (x) : (y))

5. 计算结构体成员的偏移量
在需要直接操作结构体底层内存,或者实现一些高级数据结构(如侵入式链表)时,这个宏非常有用。
#define FPOS(type, field) \
/*lint -e545 */ ((dword) &((type *)0)->field) /*lint +e545 */
6. 计算结构体中某个字段所占的字节数
利用sizeof直接获取成员大小,比手动计算更安全准确。
#define FSIZ(type, field) sizeof(((type *)0)->field)

7. 将两个字节按LSB格式合并为一个字
在小端(Little-Endian)字节序的系统中,这个宏可以将一个字节数组的前两个元素组合成一个16位的字。
#define FLIPW(ray) ((((word)(ray)[0]) * 256) + (ray)[1])

8. 将一个字按LSB格式拆分为两个字节
与上一个宏相反,用于将一个字存入字节数组。
#define FLOPW(ray, val) \
(ray)[0] = ((val) / 256); \
(ray)[1] = ((val) & 0xFF)

9. 获取变量的地址并转换为特定类型的指针
用于获取变量地址并将其解释为指定宽度(如字节、字)的指针,方便进行指针操作。
#define B_PTR(var) ((byte *)(void *)&(var))
#define W_PTR(var) ((word *)(void *)&(var))

10. 获取一个字的高位字节和低位字节
通过位操作快速分离出一个16位值的高8位和低8位。
#define WORD_LO(xxx) ((byte)((word)(xxx) & 255))
#define WORD_HI(xxx) ((byte)((word)(xxx) >> 8))

11. 对齐到8的倍数
在内存对齐要求严格的场合(如某些硬件DMA操作),此宏可用于计算满足对齐要求的最小值。
#define RND8(x) ((((x) + 7) / 8) * 8)

12. 将字母转换为大写
一个简单的条件运算符实现的大小写转换。
#define UPCASE(c) (((c) >= 'a' && (c) <= 'z') ? ((c) - 0x20) : (c))
13. 判断字符是否为十进制数字
用于输入验证或解析数字字符串。
#define DECCHK(c) ((c) >= '0' && (c) <= '9')

14. 判断字符是否为十六进制数字
比十进制判断更复杂一些,需要覆盖0-9,A-F,a-f。
#define HEXCHK(c) (((c) >= '0' && (c) <= '9') || \
((c) >= 'A' && (c) <= 'F') || \
((c) >= 'a' && (c) <= 'f'))
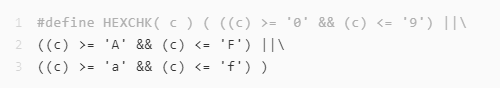
15. 饱和递增
防止无符号整数回绕的一种简单方法。当值达到最大值时,不再增加。
#define INC_SAT(val) (val = ((val)+1 > (val)) ? (val)+1 : (val))
16. 计算数组元素个数
经典用法,用于在不知道数组显式大小的情况下遍历数组。但注意不能用于指针。
#define ARR_SIZE(a) (sizeof((a)) / sizeof((a[0])))

17. 对2的幂取模
利用位与(&)运算实现高效的取模操作,这是一个非常著名的优化技巧。
#define MOD_BY_POWER_OF_TWO(val, mod_by) \
((dword)(val) & (dword)((mod_by)-1))

18. 硬件端口IO操作
在嵌入式开发中,对于内存映射的IO空间,通常使用volatile关键字来防止编译器优化,这些宏封装了读写操作。
#define inp(port) (*((volatile byte *) (port)))
#define inpw(port) (*((volatile word *) (port)))
#define inpdw(port) (*((volatile dword *)(port)))
#define outp(port, val) (*((volatile byte *) (port)) = ((byte) (val)))
#define outpw(port, val) (*((volatile word *) (port)) = ((word) (val)))
#define outpdw(port, val) (*((volatile dword *) (port)) = ((dword) (val)))
19. 宏使用的安全规范与常见陷阱规避
宏虽好,但陷阱也不少。遵循一些安全规范至关重要。
a. 始终用括号包围参数和整体结果
这是最基本的一条。看一个反例:
#define ADD(a,b) a+b

想象一下 ADD(1, 2) * 3 会被展开成 1+2*3,结果是7而不是预期的9。正确的定义是 #define ADD(a,b) ((a)+(b))。
b. 多条语句用 do { ... } while(0) 包裹
如果宏包含多条语句,直接定义可能会导致语法错误或逻辑错误。例如:
#define DO(a,b) a+b; \
a++;

在如下代码中使用时:
if(...)
DO(a,b); // 产生错误
else
...

展开后,a++; 独立于 if 语句,导致 else 没有匹配的 if。解决方案是使用 do { ... } while(0) 结构:
#define DO(a,b) do { a+b; \
a++; } while(0)

do { ... } while(0) 会确保宏中的语句被当作一个整体,并且末尾的分号使用起来和普通函数调用一致,非常安全。
结语
熟练掌握这些宏定义技巧,能让你在C语言开发中更加游刃有余,尤其是在对性能、可移植性有严苛要求的系统编程和嵌入式开发领域。它们不仅仅是代码片段,更体现了一种精细控制和深入理解计算机系统底层细节的编程哲学。当然,在现代C++中,许多功能可以用内联函数、模板和constexpr更安全地实现,但在纯C的世界里,宏依然扮演着不可替代的角色。建议你在理解原理的基础上,将它们融入自己的代码实践中。如果想深入探讨更多关于C语言预处理器或其他底层话题,欢迎在云栈社区交流。
 发表于 2026-2-4 08:05:23
|
查看: 176|
回复: 0
发表于 2026-2-4 08:05:23
|
查看: 176|
回复: 0
