在嵌入式项目中,你是否遇到过这样的场景:现场设备返回一个错误码 -5,对着日志却一脸茫然——究竟是哪个模块出了问题?是硬件故障还是参数非法?翻遍代码查找定义,耽误大量定位时间。更糟的情况是,不同模块使用了相同的错误码表示不同含义,跨模块调用时问题排查更是难上加难。
本文旨在总结嵌入式系统中错误码设计的实用方法:针对什么场景选择什么方案、如何规避常见陷阱、以及如何模块化地设计一个灵活的错误码系统,帮助开发者提升调试效率和代码可维护性。
一、错误码方案选择
错误码方案的设计并非一成不变,关键在于匹配项目的实际需求。
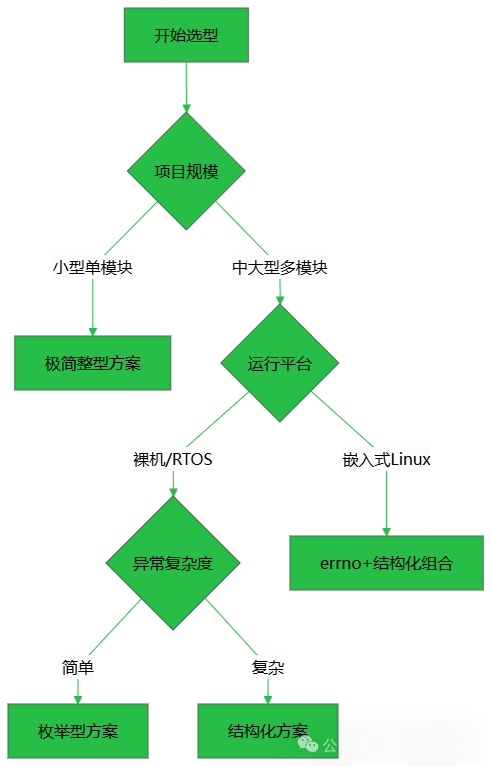
1. 项目规模与模块数量
对于小型项目(如单MCU裸机、单一驱动模块),模块数量少,异常类型简单,没有必要引入复杂设计。而中大型项目(涉及多模块协同、嵌入式Linux、跨团队开发)如果沿用简单方案,后期的维护和问题追踪将是灾难。
2. 运行平台特性
裸机MCU没有系统标准错误码,错误定义完全自主,关键是要覆盖硬件异常和逻辑异常。而在嵌入式Linux或RTOS环境下,系统自带 errno,自定义错误码时就必须考虑兼容性,避免与系统码冲突。理解不同平台的设计约束,是构建健壮系统的基础。
3. 异常类型复杂度
简单场景如参数校验、空指针、内存不足等纯软件逻辑错误,基础设计就足够应对。但涉及SPI/CAN总线通信、Flash擦写、DMA传输等硬件外设的异常场景,就需要更细粒度的错误信息,否则现场定位问题会如同大海捞针。
4. 系统集成需求
如果错误码仅在设备内部使用,规则可以相对灵活,团队内部约定即可。但若需要跨设备传递、上报云端服务器,或者需要考虑不同版本间的兼容性,那么标准化、版本化的设计就必不可少,错误码的数值和含义不能随意更改。
二、三种常见方案与实现
方案一:极简整型错误码
这种方案最为简单直接,适合裸机小型驱动、单功能模块等异常类型少于10种的轻量级场景。早期开发单片机驱动时常用,优点是见效快。
设计上通常遵循一个简单的约定:成功固定为 0,负数表示致命错误(如硬件故障、参数非法),正数表示警告(非致命,可重试)。这样通过 if(ret < 0) 就能快速判断是否发生错误。
下面是一个模块化的代码实现:
/**
* @file error_simple.h
*/
#ifndef ERROR_SIMPLE_H
#define ERROR_SIMPLE_H
#include <stdint.h>
/* 全局通用错误码 */
#define ERR_OK 0 /* 成功 */
#define ERR_PARAM -1 /* 参数非法 */
#define ERR_TIMEOUT -2 /* 超时 */
#define ERR_HW_FAIL -3 /* 硬件故障 */
#define WARN_BUSY 1 /* 设备忙(非致命) */
/* 获取错误描述字符串 */
const char* err_get_string(int err_code);
#endif /* ERROR_SIMPLE_H */
/**
* @file error_simple.c
* @brief 错误码解析实现
*/
#include "error_simple.h"
const char* err_get_string(int err_code)
{
switch (err_code) {
case ERR_OK: return "Success";
case ERR_PARAM: return "Invalid parameter";
case ERR_TIMEOUT: return "Operation timeout";
case ERR_HW_FAIL: return "Hardware failure";
case WARN_BUSY: return "Device busy";
default: return "Unknown error";
}
}
方案二:枚举型错误码
在C/C++开发中,当面对中大型裸机或RTOS项目时,模块增多后,简单的整型错误码就显得力不从心。枚举型方案能很好地解决这个问题,特别适用于异常类型在10到50种之间的场景。
该方案有几个关键优势:使用枚举类型,编译器可进行类型检查,防止低级错误;每个模块独立定义枚举,并使用统一前缀(如 GPIO_ERR_、SPI_ERR_);通过提前规划码段(例如GPIO占用100~199,SPI占用200~299)来彻底避免模块间的码值冲突。
以下是具体的实现示例:
/**
* @file error_common.h
* @brief 通用错误码基础定义(所有模块共享)
*/
#ifndef ERROR_COMMON_H
#define ERROR_COMMON_H
#include <stdint.h>
/* 全局通用错误基类 */
typedef enum {
ERR_OK = 0, /* 全局成功标志 */
ERR_PARAM = 1, /* 参数错误 */
ERR_MEMORY = 2, /* 内存不足 */
ERR_TIMEOUT = 3, /* 超时 */
ERR_UNKNOWN = 0xFF /* 未知错误 */
} err_base_t;
/* 错误码转字符串回调函数类型 */
typedef const char* (*err_to_string_fn)(int err_code);
/* 注册错误码解析器 */
void err_register_parser(uint8_t module_id, err_to_string_fn parser);
/* 统一错误码解析入口 */
const char* err_parse(uint8_t module_id, int err_code);
#endif /* ERROR_COMMON_H */
/**
* @file error_common.c
* @brief 通用错误码解析实现
*/
#include "error_common.h"
#include <stddef.h>
#define MAX_MODULES 16
static struct {
uint8_t module_id;
err_to_string_fn parser;
} parser_table[MAX_MODULES];
static int parser_count = 0;
void err_register_parser(uint8_t module_id, err_to_string_fn parser)
{
if (parser_count >= MAX_MODULES || parser == NULL) {
return;
}
parser_table[parser_count].module_id = module_id;
parser_table[parser_count].parser = parser;
parser_count++;
}
const char* err_parse(uint8_t module_id, int err_code)
{
for (int i = 0; i < parser_count; i++) {
if (parser_table[i].module_id == module_id) {
return parser_table[i].parser(err_code);
}
}
return "Module parser not found";
}
/**
* @file error_gpio.h
* @brief GPIO模块错误码定义
*/
#ifndef ERROR_GPIO_H
#define ERROR_GPIO_H
#include "error_common.h"
/* GPIO模块错误码段:100~199 */
typedef enum {
GPIO_ERR_OK = ERR_OK,
GPIO_ERR_PIN = 100,
GPIO_ERR_MODE = 101,
GPIO_ERR_HW = 102,
GPIO_ERR_BUSY = 103
} gpio_err_t;
const char* gpio_err_to_string(int err_code);
gpio_err_t gpio_init(uint8_t pin, uint8_t mode);
#endif /* ERROR_GPIO_H */
/**
* @file error_gpio.c
* @brief GPIO模块错误处理实现
*/
#include "error_gpio.h"
#include <stddef.h>
#define GPIO_MAX_PIN 31
const char* gpio_err_to_string(int err_code)
{
switch ((gpio_err_t)err_code) {
case GPIO_ERR_OK: return "GPIO success";
case GPIO_ERR_PIN: return "GPIO pin number invalid";
case GPIO_ERR_MODE: return "GPIO mode invalid";
case GPIO_ERR_HW: return "GPIO hardware init failed";
case GPIO_ERR_BUSY: return "GPIO pin is busy";
default: return "GPIO unknown error";
}
}
使用示例:
#include "error_common.h"
#include "error_gpio.h"
#include <stdio.h>
#define MODULE_ID_GPIO 1
int main(void)
{
/* 初始化时注册各模块的错误码解析器 */
err_register_parser(MODULE_ID_GPIO, gpio_err_to_string);
gpio_err_t ret = gpio_init(32, 1); // 假设引脚号非法
if (ret != GPIO_ERR_OK) {
printf("Error: %s\n", err_parse(MODULE_ID_GPIO, ret));
}
return 0;
}
方案三:结构化错误码
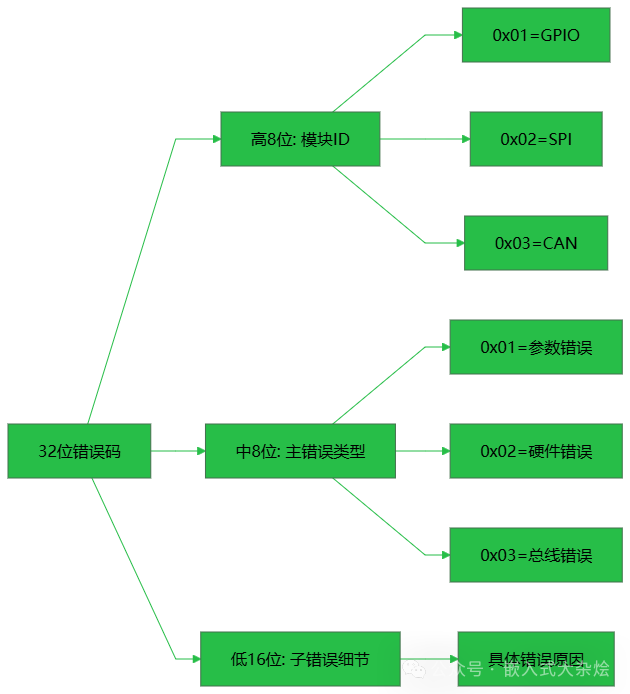
遇到多MCU协同、Linux驱动加应用层、模块众多或需要将错误码上报云端等复杂场景时,前两种方案的信息承载能力就显得不足。结构化错误码通过将一个32位整型拆分为多个字段,利用位运算进行解析,能够精确表达错误的来源、类型和具体细节,这对于设计高可维护性的后端与架构尤为重要。
字段划分通常如下:高8位存储模块ID(用于区分GPIO、SPI、CAN等),中8位存储主错误类型(如参数错误、硬件错误、总线错误),低16位存储子错误细节(例如SPI总线忙、CRC校验失败等具体原因)。
|-----8bit-----|-----8bit-----|--------16bit--------|
| 模块ID | 主错误码 | 子错误码 |
| (MODULE_ID) | (MAIN_ERR) | (SUB_ERR) |
模块化代码实现:
/**
* @file error_struct.h
* @brief 结构化错误码定义(适用于大型系统)
*/
#ifndef ERROR_STRUCT_H
#define ERROR_STRUCT_H
#include <stdint.h>
/* 错误码类型定义 */
typedef uint32_t err_code_t;
/* 字段位掩码定义 */
#define ERR_MODULE_MASK 0xFF000000U /* 高8位:模块ID */
#define ERR_MAIN_MASK 0x00FF0000U /* 中8位:主错误码 */
#define ERR_SUB_MASK 0x0000FFFFU /* 低16位:子错误码 */
/* 位移偏移量 */
#define ERR_MODULE_SHIFT 24
#define ERR_MAIN_SHIFT 16
#define ERR_SUB_SHIFT 0
/* 模块ID枚举 */
typedef enum {
MODULE_SYSTEM = 0x00, /* 系统模块 */
MODULE_GPIO = 0x01, /* GPIO模块 */
MODULE_SPI = 0x02, /* SPI模块 */
MODULE_CAN = 0x03, /* CAN模块 */
MODULE_UART = 0x04, /* UART模块 */
MODULE_APP = 0x10 /* 应用层 */
} module_id_t;
/* 主错误类型枚举 */
typedef enum {
MAIN_ERR_OK = 0x00, /* 成功 */
MAIN_ERR_PARAM = 0x01, /* 参数错误 */
MAIN_ERR_HW = 0x02, /* 硬件错误 */
MAIN_ERR_BUS = 0x03, /* 总线错误 */
MAIN_ERR_TIMEOUT = 0x04, /* 超时 */
MAIN_ERR_MEM = 0x05 /* 内存错误 */
} main_err_t;
/* 构造结构化错误码 */
#define ERR_MAKE(module, main, sub) \
((err_code_t)(((module) << ERR_MODULE_SHIFT) | \
((main) << ERR_MAIN_SHIFT) | \
((sub) << ERR_SUB_SHIFT)))
/* 从错误码提取模块ID */
#define ERR_GET_MODULE(err_code) \
(((err_code) & ERR_MODULE_MASK) >> ERR_MODULE_SHIFT)
/* 从错误码提取主错误码 */
#define ERR_GET_MAIN(err_code) \
(((err_code) & ERR_MAIN_MASK) >> ERR_MAIN_SHIFT)
/* 从错误码提取子错误码 */
#define ERR_GET_SUB(err_code) \
((err_code) & ERR_SUB_MASK)
/* 判断是否成功 */
#define ERR_IS_OK(err_code) \
(ERR_GET_MAIN(err_code) == MAIN_ERR_OK)
/* 子错误码解析函数类型 */
typedef const char* (*err_sub_parser_fn)(uint16_t sub_code);
/* 注册模块的子错误码解析器 */
void err_register_sub_parser(uint8_t module_id, err_sub_parser_fn parser);
/* 解析错误码到字符串 */
int err_parse_to_string(err_code_t err_code, char *buf, size_t len);
/* 获取模块名称 */
const char* err_get_module_name(uint8_t module_id);
/* 获取主错误描述 */
const char* err_get_main_desc(uint8_t main_err);
#endif /* ERROR_STRUCT_H */
/**
* @file error_struct.c
* @brief 结构化错误码解析实现
*/
#include "error_struct.h"
#include <stdio.h>
#include <string.h>
#define MAX_MODULES 16
static struct {
uint8_t module_id;
err_sub_parser_fn parser;
} sub_parser_table[MAX_MODULES];
static int sub_parser_count = 0;
const char* err_get_module_name(uint8_t module_id)
{
switch (module_id) {
case MODULE_SYSTEM: return "SYSTEM";
case MODULE_GPIO: return "GPIO";
case MODULE_SPI: return "SPI";
case MODULE_CAN: return "CAN";
case MODULE_UART: return "UART";
case MODULE_APP: return "APP";
default: return "UNKNOWN";
}
}
const char* err_get_main_desc(uint8_t main_err)
{
switch (main_err) {
case MAIN_ERR_OK: return "Success";
case MAIN_ERR_PARAM: return "Invalid parameter";
case MAIN_ERR_HW: return "Hardware failure";
case MAIN_ERR_BUS: return "Bus error";
case MAIN_ERR_TIMEOUT: return "Timeout";
case MAIN_ERR_MEM: return "Memory error";
default: return "Unknown error";
}
}
void err_register_sub_parser(uint8_t module_id, err_sub_parser_fn parser)
{
if (sub_parser_count >= MAX_MODULES || parser == NULL) {
return;
}
sub_parser_table[sub_parser_count].module_id = module_id;
sub_parser_table[sub_parser_count].parser = parser;
sub_parser_count++;
}
static const char* find_sub_parser(uint8_t module_id, uint16_t sub_code)
{
for (int i = 0; i < sub_parser_count; i++) {
if (sub_parser_table[i].module_id == module_id) {
return sub_parser_table[i].parser(sub_code);
}
}
return NULL;
}
int err_parse_to_string(err_code_t err_code, char *buf, size_t len)
{
if (buf == NULL || len == 0) {
return 0;
}
uint8_t module = ERR_GET_MODULE(err_code);
uint8_t main = ERR_GET_MAIN(err_code);
uint16_t sub = ERR_GET_SUB(err_code);
const char* sub_desc = find_sub_parser(module, sub);
if (sub_desc != NULL) {
return snprintf(buf, len, "[%s] %s - %s",
err_get_module_name(module),
err_get_main_desc(main),
sub_desc);
} else {
return snprintf(buf, len, "[%s] %s (sub:%d)",
err_get_module_name(module),
err_get_main_desc(main),
sub);
}
}
使用示例:
/**
* @file spi_driver.c
* @brief SPI模块错误码实现
*/
#include "error_struct.h"
#include <stdio.h>
#include <stddef.h>
/* SPI子错误码定义 */
#define SPI_SUB_ERR_NONE 0
#define SPI_SUB_ERR_BUS_BUSY 1
#define SPI_SUB_ERR_CRC_FAIL 2
#define SPI_SUB_ERR_NO_DEVICE 3
/* SPI子错误码解析函数 */
static const char* spi_sub_err_to_string(uint16_t sub_code)
{
switch (sub_code) {
case SPI_SUB_ERR_NONE: return "None";
case SPI_SUB_ERR_BUS_BUSY: return "Bus busy";
case SPI_SUB_ERR_CRC_FAIL: return "CRC check failed";
case SPI_SUB_ERR_NO_DEVICE: return "No device";
default: return "Unknown sub error";
}
}
/* SPI驱动函数 */
err_code_t spi_transfer(uint8_t *data, uint32_t len)
{
if (data == NULL || len == 0) {
return ERR_MAKE(MODULE_SPI, MAIN_ERR_PARAM, SPI_SUB_ERR_NONE);
}
// ... 实际SPI传输操作 ...
// 假设发生了总线忙
return ERR_MAKE(MODULE_SPI, MAIN_ERR_BUS, SPI_SUB_ERR_BUS_BUSY);
}
/* 应用层使用 */
static void print_error(err_code_t err)
{
char err_str[128];
err_parse_to_string(err, err_str, sizeof(err_str));
printf(" Parsed: %s\n", err_str);
}
int main(void)
{
err_code_t ret;
uint8_t data[10] = {0};
// 注册各模块的子错误解析器
err_register_sub_parser(MODULE_SPI, spi_sub_err_to_string);
printf("spi_transfer(valid):\n");
ret = spi_transfer(data, 10); // 调用SPI传输
print_error(ret); // 将输出类似: [SPI] Bus error - Bus busy
printf("\n");
return 0;
}
三、总结
错误码设计的关键在于匹配项目实际需求,并非越复杂越好:
- 小型项目可选用极简整型或枚举方案,开发效率高,维护简单。
- 大型复杂项目则应考虑结构化方案,以实现精准的错误定位和清晰的信息传递。
在实施过程中,有几项重要的注意事项,它们构成了健壮错误处理机制的计算机基础:
- 错误码值不可修改:一旦定义并发布,错误码的数值和含义应永久固定,后续只能新增,不能修改或删除,以保证向后兼容性。
- 尽量提供解析函数:为错误码提供解析为可读字符串的函数,能极大提升调试效率。否则,开发者每次看到数字都需要翻查代码定义,非常低效。
- 避免跨模块码值冲突:在使用整型或枚举方案时,务必提前规划好各模块的码值段(例如GPIO占100~199,SPI占200~299),并严格遵守。
- 错误码与处理逻辑解耦:错误码只应定义“是什么错误”(例如
SPI_BUS_BUSY),而不应定义“该如何处理”。处理逻辑(如重试、降级、上报)应由调用方根据上下文决定。
希望以上关于嵌入式错误码模块化设计的思路和方案,能为你的项目开发带来帮助。如果你有更好的设计思路或实践经验,欢迎在云栈社区与广大开发者交流探讨。
 发表于 2026-2-3 07:26:34
|
查看: 163|
回复: 0
发表于 2026-2-3 07:26:34
|
查看: 163|
回复: 0
