最近帮同事处理一些成绩表,核心操作是维度表转事实表,再通过数据透视达成最终需求。这个流程听起来就像把大象装进冰箱:开门、放象、关门。就这么简单吗?实际操作中,还是遇到了一些值得记录的小插曲和技巧。
一、透视表内存溢出?可能是 observed 参数在“作怪”
在执行数据透视时,我那台16G内存的机器弹出了一个令人困惑的错误:
Unable to allocate 2.35 GiB for an array with shape (315956160,) and data type object
乍一看是内存不足。但我的数据明明只有3万7千多行、9列,并且分组列都转换成了 category 类型。16G内存处理这点数据怎么会不够用?
于是我换了一台128G内存的“大家伙”进行测试,结果问题依旧!在国内外技术站点(包括 pandas.pydata.org)上搜寻,常见的解决方案无非两种:调整数据形状,或者增加物理内存。但这对我都不适用——我的数据量“少得可怜”。
经过反复排查,最终发现问题的症结在于 pivot_table 或 groupby 操作中的 observed 参数。在分组列被定义为分类(category)数据类型时,Pandas 的默认行为(observed=False)会计算所有可能的类别组合,即使某些组合在实际数据中并未出现。这可能导致生成一个极其稀疏的巨大中间数组,从而瞬间耗尽内存。
解决方案很简单:将 observed 参数设置为 True。
# 在groupby操作中
df.groupby(['category_col1', 'category_col2'], observed=True).sum()
# 或者在构建透视表时
pd.pivot_table(df, values='score', index='class', columns='subject', aggfunc='mean', observed=True)
设置 observed=True 后,Pandas 将只计算数据中实际存在的类别组合,从而避免因虚构大量空组合而导致的内存爆炸。所以你看,在数据处理中保持“观测”(observed),有时能省下大量资源。
二、正则替换“翻车”?检查你的原始字符串(Raw String)
这个小技巧源于一个正则表达式替换的“翻车”现场。在替换类似“初一年级”这样的字符串时,如果引用分组写错了,可能会得不到预期结果。
关键在于:在正则表达式中使用反斜杠 \ 引用分组(如 \1, \2)时,模式字符串和替换字符串都应该使用原始字符串(raw string),即在字符串前加 r 前缀。
看一个具体的例子:
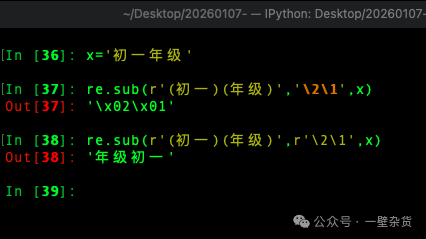
图中代码演示了如何将“初一年级”替换为“年级初一”。注意,无论是匹配模式 r'(初一)(年级)',还是替换模式 r'\2\1',前面都加了 r。这确保了反斜杠被正确解释为分组引用,而不是转义字符。记住这个口诀:前面 r 了,后面也要 r。
三、快速找出两个列表中的不同元素
这属于 Python 列表的基础操作,但在处理数据对比、校验时非常实用,值得记上一笔。
假设有两个列表:
list1 = ['a', 'b', 'c']
list2 = ['a', 'c', 'd']
如果想快速找出两个列表中互不相同的元素(即存在于A但不存在于B,以及存在于B但不存在于A的元素),最简洁的方法是使用集合(set)的 symmetric_difference 方法:
set(list1).symmetric_difference(set(list2))
这行代码会返回一个集合:{'b', 'd'}。这个方法清晰高效,避免了繁琐的循环判断。
以上就是本次数据处理实践中总结的几个小技巧。尤其是在面对 Pandas 这类强大但复杂的库时,一个参数的差异可能就会导致性能天差地别。希望这些经验对你有所帮助。如果你在数据处理中也有独到的发现,欢迎来 云栈社区 分享交流。
 发表于 2026-2-5 03:17:11
|
查看: 152|
回复: 0
发表于 2026-2-5 03:17:11
|
查看: 152|
回复: 0
