很多人都有这样的疑问:
我的 CPU 主频 3.6GHz,一秒能执行几十亿条指令,
可为什么程序还是会卡?
为什么加内存有用?
为什么一旦“换页”,系统就像“抽风”?
一、计算机真正的“速度差距”:CPU、缓存、内存与磁盘
我们常常被 CPU 的主频数字迷惑,以为 GHz 就是性能的全部。但实际上,CPU 的运算速度只是故事的一面,另一面是它获取数据的速度。这个速度差距之大,往往超出直觉。
1. CPU 并不直接面对内存
CPU 内部并非只有一个“算数器”,而是一整套精密的结构。它并不直接访问速度慢得多的主内存(RAM),而是通过一个多层次的缓存系统。数据流动的路径,大致遵循下图所示的层次结构:

从上到下,速度递减,容量递增:
- 寄存器(Register)
- L1 Cache
- L2 Cache(有的还有 L3)
- 再往下,才是主存(RAM)
- 最慢的,是磁盘(虚拟内存)
这并非设计缺陷,而是物理与成本权衡下的必然结果。
越靠近 CPU,速度越快,容量越小,成本越高。
2. 速度差距有多夸张?
结合图中的数量级,我们可以粗略感受一下:
| 存储层级 |
访问延迟 |
| 寄存器 / L1 Cache |
接近 CPU 主频(≈3.6GHz) |
| L2 Cache |
略慢,但仍是纳秒级 |
| 主存(RAM) |
数十~上百纳秒 |
| 磁盘(虚拟内存) |
毫秒级(ms) |
请注意这个单位的变化: ns(纳秒) → μs(微秒) → ms(毫秒)。
从纳秒到毫秒,中间差了 10⁶(百万倍) 的数量级。所以,一个至关重要的结论是:CPU 并不怕“计算”,它怕的是“等数据”。
二、Cache Miss:程序“突然变慢”的罪魁祸首
上图中有一条非常关键的红线:cache miss / fill。
什么是 Cache Miss?
简单说就是:CPU 在当前的高速缓存中找不到它急需的数据。
CPU 想用的数据,缓存里没有
→ 只能去更慢的内存里找
→ 整个执行流水线被迫“空转”等待
此时,虽然 CPU 时钟仍在跳动,指令指针仍在推进,但负责计算的算术逻辑单元(ALU)可能无事可做,实际效率断崖式下跌。这解释了为什么同一段程序,运行时性能会波动:
- 缓存命中:数据就在 L1/L2,访问飞快。
- 缓存未命中:需要访问慢数十倍的主内存。
- 再次未命中(触发换页):甚至需要从慢百万倍的磁盘加载。
你以为你的代码逻辑没变,但程序执行的数据访问路径已经完全不一样了,性能自然天差地别。
三、虚拟内存:系统性能的“最后一道保险丝”
当物理内存吃紧,或者某些内存页面长期未被访问时,现代操作系统会启动“虚拟内存”机制:将不活跃的物理内存页内容写入磁盘(换出),腾出空间。
1. 虚拟内存是如何拖慢系统的?
当程序再次访问这些已被换出的内存时,会触发“缺页异常”。此时会发生三件事:
- CPU 中断:停止当前执行流。
- 操作系统介入:调度器工作,处理异常。
- 磁盘 I/O:从缓慢的磁盘中将所需数据读回物理内存。
这个过程的代价是毫秒级的延迟。对于一个主频 3.6GHz 的 CPU 而言,等待一次磁盘 I/O 的时间,足够它执行数百万条指令。这就像是让F1赛车手在赛道上等一个红绿灯。
2. 为什么换页会导致系统“卡死”?
一旦系统开始频繁换页(称为“内存抖动”),就会引发连锁灾难:
- CPU → 等待 I/O:多个进程因缺页而阻塞,CPU 利用率看似下降,实则是在空等。
- I/O → 占用总线:磁盘为换页疯狂读写,独占系统总线带宽。
- 总线 → 阻塞其他访问:连正常的内存访问也因总线繁忙而变慢。
- 最终结果:整个系统陷入泥潭,响应速度急剧下降。
四、总线竞争:CPU、内存、I/O 共享的“独木桥”
性能瓶颈不仅存在于存储层级,还存在于连接这些组件的通路上。看第二张架构图:
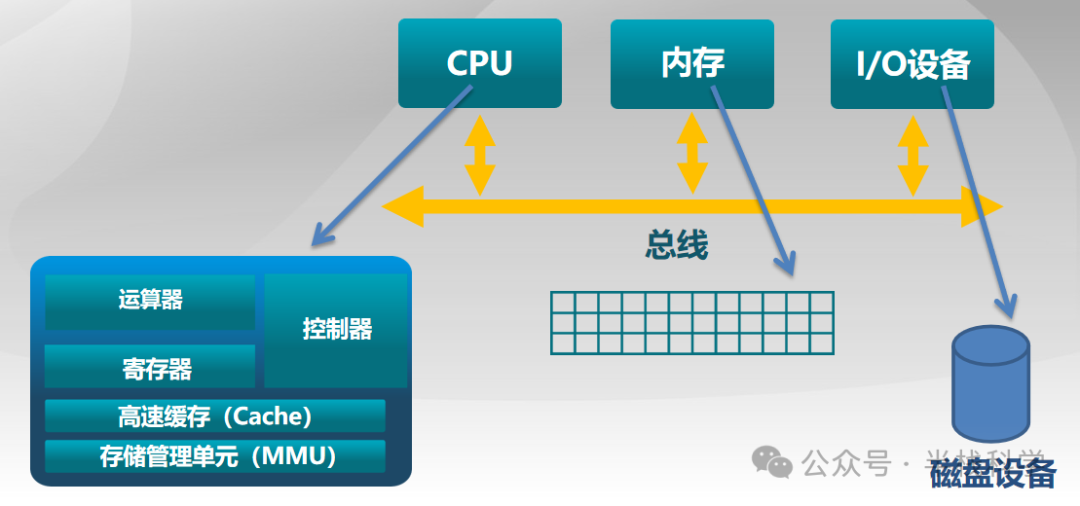
CPU、内存、I/O 设备并不是点对点直连,而是共享同一条系统总线。
1. 总线是稀缺的公共资源
CPU 访问内存要走总线,磁盘通过 DMA 传输数据要走总线,网卡、显卡等所有外设与内存交换数据也要走总线。因此,一旦发生频繁的磁盘 I/O(例如大量换页),总线就会成为瓶颈:
- 内存访问请求被延迟。
- CPU 获取数据的等待时间变长。
- 整体系统吞吐量下降。
2. I/O 密集型程序为何容易“拖垮”系统?
因为操作系统必须在 CPU 执行、内存调度和 I/O 访问三者之间进行复杂的协调。这正是图中右侧所抽象的层次:应用 → 操作系统 → 数据 → 硬件。你编写的代码,最终需要经过操作系统的层层调度,才能与物理硬件交互,任何一个环节拥堵,都会反映为程序卡顿。
五、MMU:内存访问的“隐形调度官”
在计算机系统中,有一个至关重要但常被忽略的硬件单元:MMU(内存管理单元)。它主要负责:
- 虚拟地址到物理地址的转换
- 页表查找与管理
- 内存访问权限控制
- 配合维护缓存一致性
正是 MMU 的默默工作,才使得每个进程都“感觉自己独占了整个内存空间”,也让操作系统能够安全、高效地实现虚拟内存和分页机制。但这一切的代价是:每一次内存访问,实际上都附加了额外的地址转换和管理开销。
六、总结:性能优化的核心是减少等待
通过以上的分析,我们应该刷新一个关键的认知:
错误直觉:
程序慢,是因为 CPU 不够快。
根本原因:
程序慢,往往是 数据访问路径太慢,CPU 在空转等待。
决定程序性能的关键,远不止 CPU 主频,而是以下因素的综合体:
- 数据局部性:是否能常驻高速缓存,避免 Cache Miss。
- 内存容量:是否充足,避免触发致命的磁盘换页。
- I/O 模式:是否频繁、随机,导致总线拥堵和CPU等待。
- 系统调度:操作系统是否因频繁处理中断和缺页而开销过大。
一言以蔽之,优化性能的本质,不是让 CPU 算得更快,而是想尽一切办法,让它少等待。 理解从寄存器到磁盘这条漫长的数据供给链,是进行任何有效性能分析和优化的起点。
 发表于 2026-2-6 01:33:29
|
查看: 230|
回复: 0
发表于 2026-2-6 01:33:29
|
查看: 230|
回复: 0
