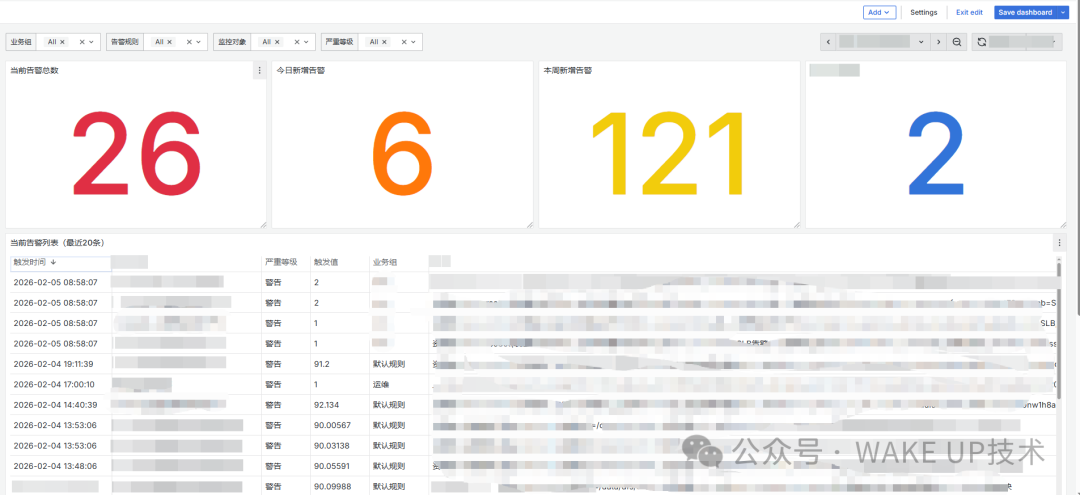
这张大屏构建于夜莺告警系统之上,通过Grafana呈现,旨在为运维团队提供一个实时、全局的告警态势感知视图。整个设计采用了模块化思路,清晰地划分为关键指标统计区、告警列表展示区和趋势分析区三大功能区块。
一、仪表盘整体概览
1.1 核心特性
- 实时更新:仪表盘每30秒自动刷新一次(配置为
"refresh": "30s"),确保信息时效性。
- 多维度分析:不仅关注告警总量,还涵盖了时效分析(今日/本周)、分布趋势和处理效率等多个观察视角。
- 用户友好:界面标签和业务术语均采用中文,降低了团队成员的使用和认知门槛。
二、关键面板深度解析
2.1 指标统计面板(Stat类型)
这类面板用于展示核心的聚合数据。
当前告警总数
SELECT COUNT(*) as value FROM alert_cur_event
说明:直接统计 alert_cur_event 表中的活跃告警记录。这是最简单、也最关键的指标,反映了系统当前的告警压力。
今日新增告警
SELECT COUNT(*) as value FROM alert_his_event
WHERE is_recovered = 0
AND trigger_time >= UNIX_TIMESTAMP(CURDATE())
说明:统计从当天0点开始触发且尚未恢复的告警数量。
CURDATE():获取当前日期(例如‘2024-01-15’)。UNIX_TIMESTAMP(CURDATE()):将日期转换为Unix时间戳。- 潜在时区问题:
CURDATE() 函数依赖于MySQL服务器的本地时区设置,而非UTC时间,这一点在跨地域部署时需要特别注意。
本周新增告警
SELECT COUNT(*) as value FROM alert_his_event
WHERE is_recovered = 0
AND trigger_time >= UNIX_TIMESTAMP(DATE_SUB(CURDATE(), INTERVAL WEEKDAY(CURDATE()) DAY))
说明:统计从本周一零点至今的新增告警。WEEKDAY(CURDATE()) 返回当前日期是本周的第几天(周一为0),借此计算出本周一的日期。
今日恢复告警
SELECT COUNT(*) as value FROM alert_his_event
WHERE is_recovered = 1
AND recover_time >= UNIX_TIMESTAMP(CURDATE())
说明:统计当天已恢复的告警数量。这个指标能有效反映运维团队的处理效率。
2.2 告警列表面板(Table类型)
此面板以表格形式展示最详尽的告警明细。
SELECT
FROM_UNIXTIME(trigger_time) as '触发时间',
rule_name as '告警规则',
CASE severity
WHEN 0 THEN '紧急'
WHEN 1 THEN '警告'
WHEN 2 THEN '通知'
ELSE '未知'
END as '严重等级',
trigger_value as '触发值',
group_name as '业务组',
tags as '标签'
FROM alert_cur_event
ORDER BY trigger_time DESC
LIMIT 20
关键特性:
- 时间格式转换:
FROM_UNIXTIME(trigger_time) 将存储的Unix时间戳转换为人类可读的时间格式。
- 数据映射:通过
CASE 语句将数字代码表示的严重等级(0,1,2)转换为直观的中文描述(紧急,警告,通知)。
- 智能排序:按触发时间降序排列,确保最新的告警始终显示在最顶部。
- 列宽优化:可以在Grafana面板的
Overrides设置中,为各列配置合适的显示宽度,提升可读性。
2.3 趋势分析面板(TimeSeries类型)
这类面板用于揭示数据随时间的变化规律。
告警业务组分布趋势
SELECT
DATE(FROM_UNIXTIME(trigger_time)) as time,
group_name,
COUNT(*) as value
FROM alert_his_event
WHERE FROM_UNIXTIME(trigger_time) >= DATE_SUB(NOW(), INTERVAL 7 DAY)
GROUP BY DATE(FROM_UNIXTIME(trigger_time)), group_name
ORDER BY time
平均告警恢复时长
SELECT
DATE(FROM_UNIXTIME(trigger_time)) as time,
AVG(recover_time - trigger_time) as value
FROM alert_his_event
WHERE is_recovered = 1
AND recover_time IS NOT NULL
AND FROM_UNIXTIME(trigger_time) >= DATE_SUB(NOW(), INTERVAL 7 DAY)
GROUP BY DATE(FROM_UNIXTIME(trigger_time))
ORDER BY time
三、时区问题的深入分析与解决方案
在构建这类全局监控大屏时,时区不一致是一个常见且容易被忽略的“暗坑”。你看到的“今日”统计,真的准确吗?
3.1 问题根源:三时区不一致
问题通常由以下三个层面的时区设置不匹配导致:
- 数据库存储时区:
trigger_time、recover_time 等字段通常以Unix时间戳格式存储,其基准是UTC。
- MySQL服务器时区:执行
CURDATE()、NOW()、DATE_SUB() 等日期时间函数时,MySQL会使用其配置的本地系统时区。
- Grafana展示时区:最终用户在浏览器中查看图表时,Grafana可能会根据用户本地时区或仪表盘设置进行时间转换。
3.2 解决方案:统一时区处理
方案一:设置MySQL会话时区(推荐)
最彻底的方案是在Grafana的MySQL数据源连接配置中,添加初始化命令:
time_zone='+00:00'
这能确保该数据源的所有查询会话都使用UTC时区,CURDATE()、NOW()、FROM_UNIXTIME() 等函数都将基于UTC进行计算,从根本上消除时区歧义。
四、模板变量的高级应用
仪表盘集成了四个模板变量,实现了强大的动态交互过滤功能:
$group_name:按业务组筛选$rule_name:按告警规则筛选$target_ident:按监控对象(主机/实例)筛选$severity:按严重等级筛选
这些变量可以被灵活地嵌入SQL查询的WHERE条件中,实现交互式数据钻取。例如:
SELECT * FROM alert_cur_event
WHERE
(group_name IN ($group_name) OR '$group_name'='All')
AND (rule_name IN ($rule_name) OR '$rule_name'='All')
五、性能优化建议
随着告警数据量的增长,大屏查询性能可能面临挑战。以下几点优化建议可供参考:
- 索引优化:为
alert_cur_event和alert_his_event表中高频查询的字段,如trigger_time、is_recovered、group_name等,创建合适的索引。
- 查询简化:尽量避免在
WHERE条件中对字段使用函数(如 FROM_UNIXTIME(trigger_time) >= ...),这会导致索引失效。可考虑将条件转换为对时间戳字段的直接比较。
- 数据聚合:对于趋势分析类查询,如果实时计算压力大,可以考虑创建定时任务生成的物化视图或聚合表。
- 分页加载:对于历史告警列表,实现分页查询机制,避免一次性拉取大量数据。
六、总结
这个基于夜莺和Grafana的告警监控大屏,展示了一个典型的生产级监控数据可视化方案。它将原始的、分散的告警事件,转化为了具备运营价值的全局洞察。其中,时区问题的识别与正确处理,是保障这类跨地域协作系统数据准确性的关键。
核心行动建议:
- 立即检查并考虑在Grafana的MySQL数据源配置中增加
time_zone='+00:00' 设置。
- 全面审查仪表盘中所有使用了
CURDATE()、NOW()、FROM_UNIXTIME() 的查询逻辑。
- 在业务允许的范围内,推动将系统内的时间处理逻辑统一到UTC时区。
通过以上措施,可以确保无论团队成员身处何方,看到的都是同一套准确、一致的告警态势,真正实现“一处告警,全局感知”的运维协同目标。这类实战经验的分享与探讨,正是云栈社区所鼓励的技术交流氛围。
 发表于 2026-2-6 06:42:11
|
查看: 254|
回复: 0
发表于 2026-2-6 06:42:11
|
查看: 254|
回复: 0
