昨晚一个拥有4年工作经验的朋友跟我复盘美团到店事业群的面试,心态有点崩了。面试官抛出了一道非常经典的营销场景题:“我们需要设计一个用户会员积分系统。用户购物会送积分,这些积分一年后就会过期。请问该如何维护积分的有效性?又该如何实现过期提醒?数据库表结构应该怎么设计?”
这位朋友第一反应是,积分不就是个数字吗?于是他自信地回答:“简单!在用户表里加个 points 字段就行了。加积分时就执行 Update + N,消费时就执行 Update - N。至于过期提醒,搞个定时任务每天扫描全表,看谁的积分快到期了,就给他发短信提醒。”
面试官听完,轻笑了一声,然后抛出了两个致命的追问:
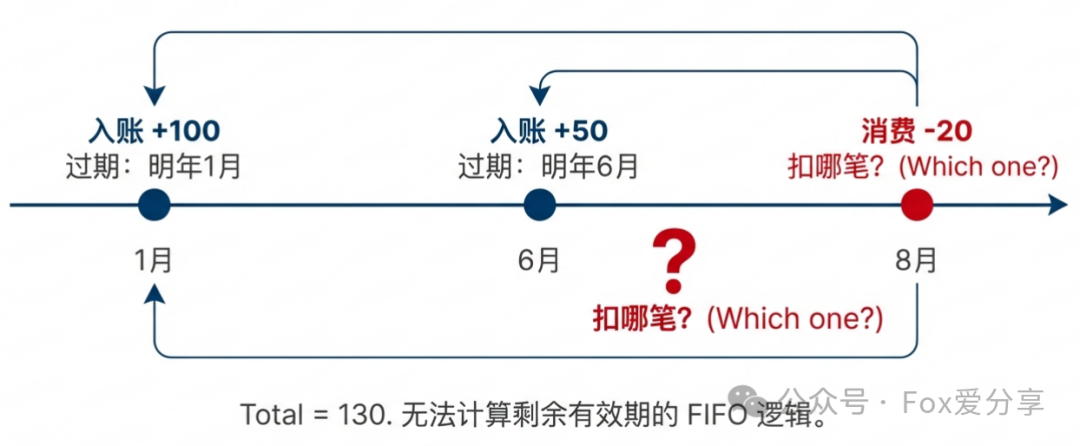
- “用户1月获得了100积分(明年1月过期),6月又获得了50积分(明年6月过期)。到了8月,他消费了20积分。请问这20分扣的是哪一笔?扣完之后还剩多少?过期时间发生变化了吗?”
- “假设你有5亿用户,你计划每天全表扫描一次数据库来发送提醒?就算你的数据库扛得住这种扫描压力,万一用户今天刚把积分消费掉,而你提醒的数据还没来得及更新,用户收到短信后投诉你诈骗,这又该怎么处理?”
朋友瞬间哑口无言,这时他才猛然意识到,自己把复杂的 “资产管理系统” 简化成了一个简单的 “计数器”。
兄弟们,积分系统 的本质是一个 “准金融系统”。它涉及 流水追溯、效期管理和对账核算。仅仅在数据库里存一个总数,是绝对行不通的。
今天,我们就来彻底拆解这道面试题的 三种设计段位,看看大厂是如何高效、安全地管理这笔“虚拟资产”的。
为什么“单字段存总数”是错误的设计?
如果你只在用户表中存放一个 total_points 字段,那么你将彻底丢失积分的 “时间维度”。
让我们还原一下场景:
- 入账: 2023年1月1日获得100积分(有效期1年)。
- 入账: 2023年6月1日获得50积分(有效期1年)。
- 消费: 2023年8月1日消耗20积分。
问题来了: 这20分应该从1月的积分里扣,还是从6月的积分里扣?根据 “对用户最有利” 的原则,系统通常需要遵循 FIFO(先进先出) 逻辑,优先扣除那些 “快过期” 的积分。如果你的系统里只有一个 total_points = 130 的总数,你根本无法追踪每一笔积分的“生老病死”。到了2024年1月1日,你该让多少积分过期?你根本算不出来。
结论: 一个健壮的积分系统必须采用 “分桶存储” 策略,而不是简单的总量存储。
核心架构:数据库表设计
要解决积分过期和精准扣减的问题,数据库设计至少需要 3张核心表 来支撑。
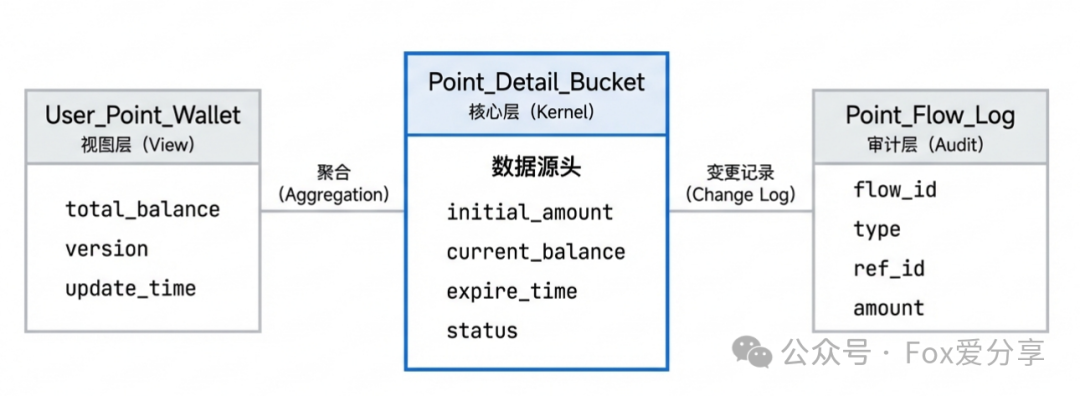
1. 积分总览表(User_Point_Wallet)
作用: 相当于用户的“钱包视图”,只存放当前可用的积分总额,用于 快速读取和展示(例如在用户个人中心显示)。
CREATE TABLE user_point_wallet (
user_id BIGINT PRIMARY KEY,
total_balance INT DEFAULT 0, -- 当前可用总积分
version INT DEFAULT 0, -- 乐观锁版本号,用于并发控制
update_time DATETIME
);
2. 积分流水表(Point_Flow_Log)
作用: 相当于“银行流水账”,不可变地 记录每一笔积分的增加或减少操作,主要用于事后对账和审计追溯。
CREATE TABLE point_flow_log (
flow_id BIGINT PRIMARY KEY,
user_id BIGINT,
amount INT, -- 变动金额(如 +100 或 -20)
type TINYINT, -- 类型:1-签到,2-购物奖励,3-兑换消费,4-过期扣减
ref_id VARCHAR(64), -- 关联的业务单号(订单ID等)
create_time DATETIME
);
3. 积分明细/分桶表(Point_Detail_Bucket)
作用: 这是整个系统的 核算核心。它精确记录每一笔入账积分的 当前剩余余额 和 过期时间。每一行记录就是一个“积分桶”。
CREATE TABLE point_detail_bucket (
id BIGINT PRIMARY KEY,
user_id BIGINT,
initial_amount INT, -- 初始入账金额(例如 100)
current_balance INT, -- 当前剩余金额(初始等于initial_amount,消费后递减)
expire_time DATETIME, -- 过期时间(决定了这个“桶”的生命周期)
status TINYINT, -- 状态:0-有效,1-已用完,2-已过期
INDEX idx_user_expire (user_id, expire_time) -- 关键复合索引:用于按用户和过期时间排序查询
);
用户的消费扣减操作,正是基于这张表,按照 FIFO 规则来执行的。
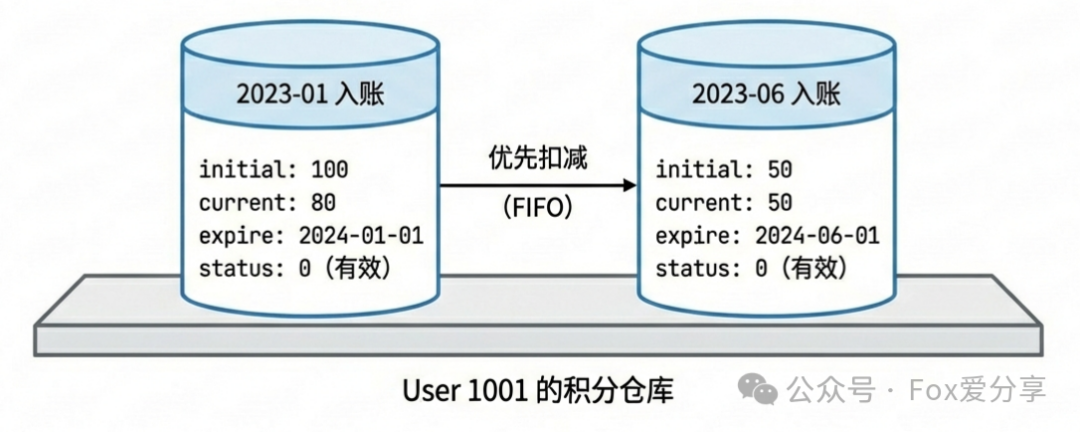
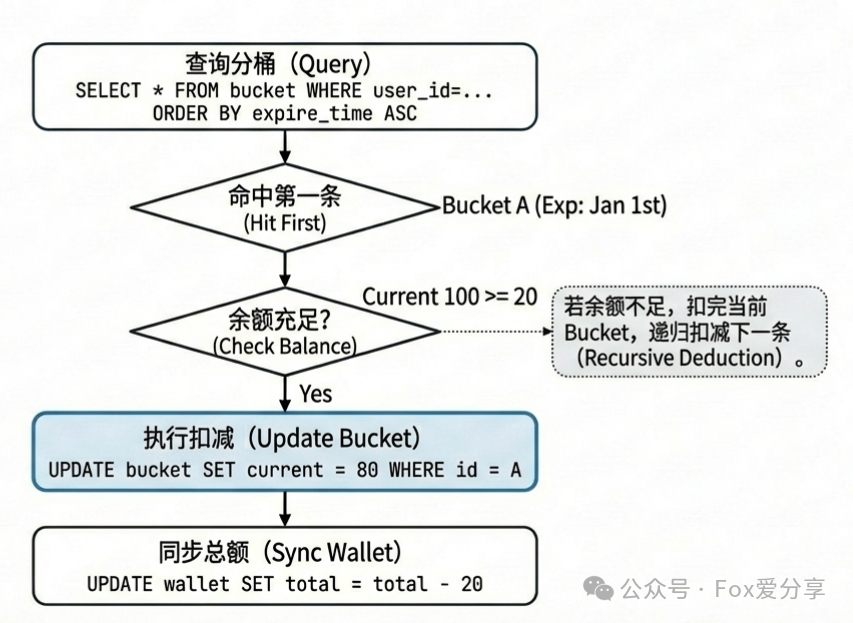
扣减逻辑解析: 当用户需要消费20积分时:
- 查询
point_detail_bucket 表,条件为 user_id = 当前用户,并按照 expire_time ASC(过期时间升序)排序。
- 找到第一条未过期的记录(比如1月入账的桶)。检查其
current_balance 是否足够(100 >= 20)。
- 如果足够,则更新该记录的
current_balance 为 80;如果不够,则扣完当前桶的全部余额,并继续查找下一个桶进行递归扣减。
- 最后,同步更新
user_point_wallet 表中的 total_balance 总额。
这就是标准的 “账本拆分” 和 “先进先出” 的核销逻辑。
过期提醒与数据清理:如何应对海量数据?
面试官的第二个灵魂拷问:“如何高效地提醒用户积分即将过期?”
错误解法:在线实时扫描
每天定时跑一个任务,去数据库里执行 SELECT ... WHERE expire_time = 明天。致命缺陷: 面对5亿用户的数据量,这种全表或大范围扫描根本不可行,会对数据库造成巨大压力。更严重的是,如果用户在今天把积分花光了,系统明天依然会给他发送“积分快过期”的提醒,导致用户体验极差,可能引发投诉。
正确解法:离线计算 + 惰性清理策略
对于亿级数据量的系统,必须放弃“在线计算”的思路,转向更高效的 “离线计算”。
1. 过期提醒策略(T+1 离线计算)
在海量数据背景下,实时提醒既成本高昂又非必要。
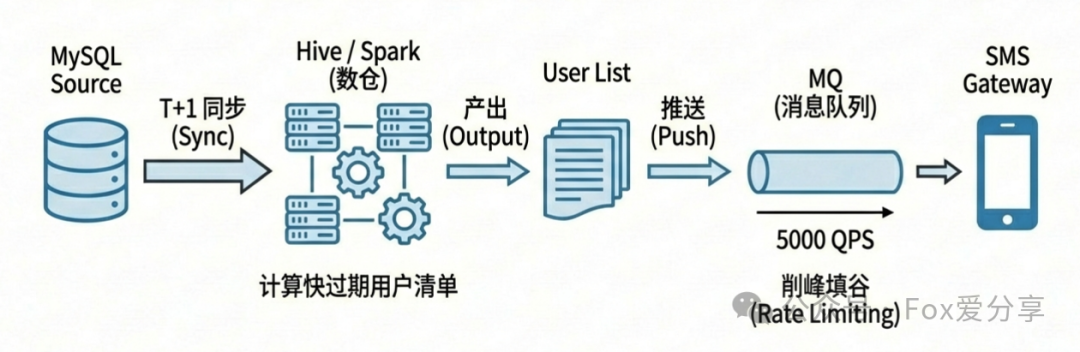
- 核心方案: 利用大数据平台(如 Hive/Spark)。这才是处理海量数据的正确姿势,也是系统设计能力的体现。
- 实现逻辑: 每天凌晨,通过ETL任务将
point_detail_bucket 表的数据快照同步到数据仓库。在数仓中执行计算任务,筛选出 “未来7天内有过期积分,且当前总有效余额大于0” 的用户名单。
- 消息触达(MQ削峰填谷): 拿到用户名单后,绝对不要直接调用短信或推送接口! 假设5亿用户中有1%需要提醒,就是500万条消息。必须引入 消息队列(如Kafka, RabbitMQ) 进行削峰填谷。后端服务从MQ中匀速消费(例如控制为5000 QPS),再调用下游的短信网关,从而保护下游系统不被突发流量冲垮。
- 轻量级备选方案: 如果公司没有大数据基础设施,可以采用 ‘过期日历表’ 作为降级方案。即创建一张辅助表,按日期聚合第二天需要过期的用户ID,每天扫描这张小表。虽然需要额外维护数据的一致性,但避免了维护Hadoop集群的复杂性,适合中等数据体量的业务。
2. 数据清理策略(惰性 + 定时归档)
不要每天在业务高峰时段去主数据库执行 UPDATE ... SET status=2 WHERE expire_time < NOW() 这样的操作。
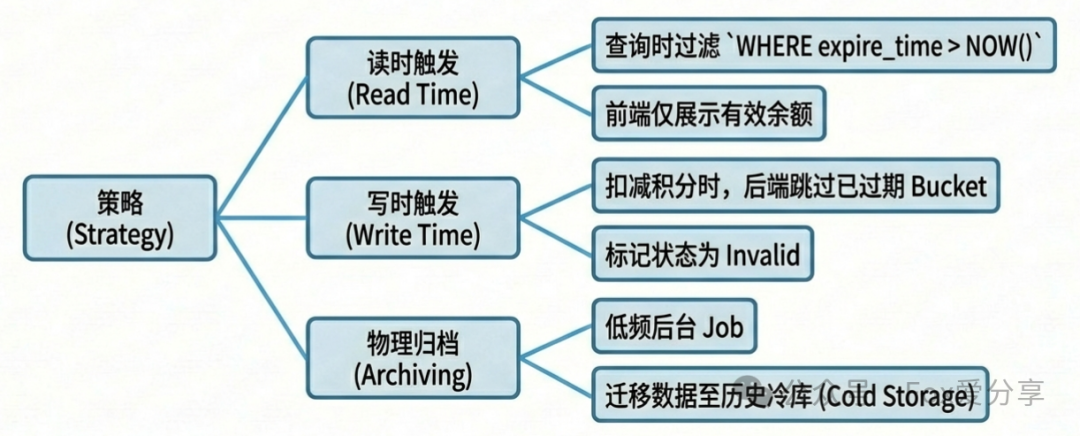
- 读时触发: 当用户查询自己的积分时,在查询语句或应用层过滤掉
expire_time 已过的记录,前端只展示有效余额。
- 写时触发: 当用户消费积分时,后端逻辑会自动跳过那些已过期的“桶”,只从有效桶中扣减,并可将过期桶标记为无效状态。
- 物理归档: 对于已经过期很长时间(如一年以上)的“垃圾数据”,可以启动一个低频的后台任务,在业务低峰期将它们迁移到历史归档库或对象存储中,释放主数据库的存储和索引压力。
进阶问题与“防杠”指南
设计完基础架构后,面试官往往会进行 “地狱级”追问。如果下面这三个问题答不好,前面的设计可能就白费了。
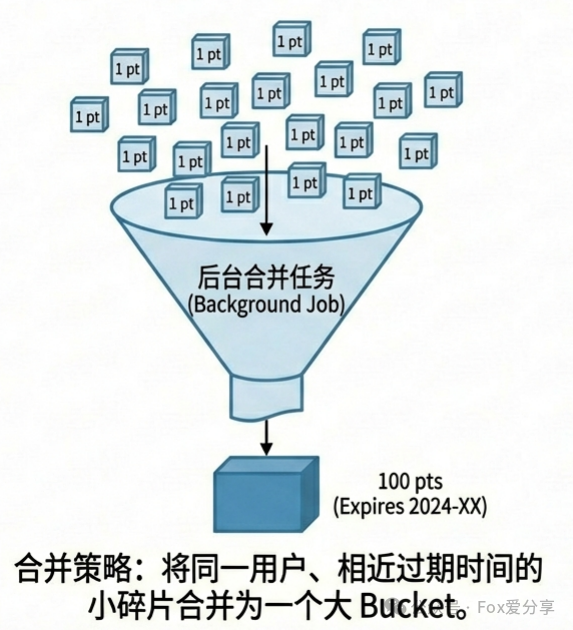
Q1:如果用户每天签到只送1积分,连续签了3年,就会产生上千条积分桶记录。现在他要消费500积分,难道要在一个事务里更新500行记录?这不会导致数据库死锁或性能暴跌吗?
答: “这是一个非常好的问题,它指出了‘碎片化账本’带来的性能隐患。针对这种由小额、高频操作产生的碎片积分,我们必须引入 ‘定期合并(Compaction)’ 机制。可以设定一个后台任务,定期扫描 point_detail_bucket 表,将同一用户、相近过期时间(例如相差7天内)的多个小积分桶,合并成一个大积分桶。这样一来,在用户进行大额消费时,只需要操作少数几行记录,性能就能得到充分保障。”
Q2:为了追求极致性能,我能不能先把积分变动写入Redis,然后异步同步到MySQL数据库?
答: “绝对不行! 积分是用户的 虚拟资产,资产类数据必须保证 强一致性。Redis 作为缓存,其数据持久化和一致性模型是 弱一致性 的。一旦出现Redis宕机未持久化、或者异步消息丢失的情况,就可能导致用户积分凭空消失或增多,这属于最高级别(P0)的资产损失事故。正确的做法是: 核心的积分增减写操作,必须通过 MySQL数据库事务 来保证ACID。Redis 只能用作 ‘读缓存’(Cache-Aside模式),在查询时加速,绝不能作为数据的 ‘唯一来源’ 或 ‘写缓冲区’。”
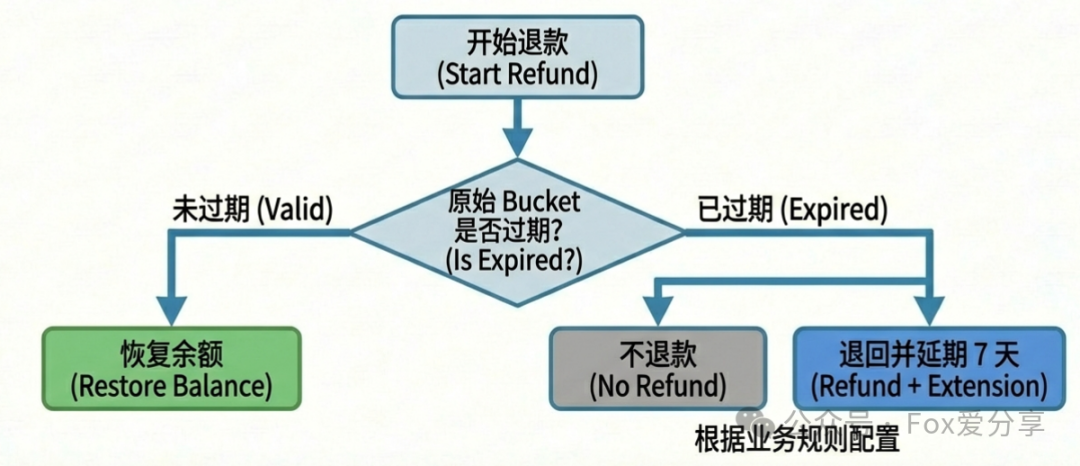
Q3:如果用户订单发生退款,积分该如何退回?退回的积分有效期又该怎么计算?
答: “这需要遵循 ‘原路退回’ 原则。我们在扣减积分时,除了更新分桶表,还会记录一条详细的 consumption_log(消费明细日志),明确记录这笔订单扣减了用户哪些具体的积分桶、各扣了多少。当发生退款时,就根据这条日志进行 逆向恢复。
- 如果被扣减的那个原始积分桶 尚未过期,则直接将扣减的余额恢复回去。
- 如果原始积分桶 已经过期,常见的业务策略有两种:一是直接 不予退还;二是 退还积分但赋予一个较短的新的有效期(例如7天)。具体采用哪种,取决于业务规则和产品设计。”
面试标准答案模板(建议掌握核心思路)
下次面试中再被问到“如何设计一个积分系统?”,你可以按照以下结构清晰阐述:
“对于积分系统,我的核心设计思路是 ‘总分分离核算、FIFO先进先出扣减、离线计算提醒’:
- 数据库设计: 采用三层结构。总额表作为快速读视图,流水表作为不可变审计日志,明细分桶表作为核算核心,记录每笔积分的有效期。这是解决过期问题的数据基础。
- 扣减逻辑: 消费时,遵循 FIFO原则,优先扣减最快过期的积分桶。针对可能产生的大量碎片化积分桶,我会设计 ‘定期合并机制’ 来优化性能,防止数据库锁冲突。
- 资产安全: 将积分视为虚拟资产,核心的写操作(增、减)坚持通过数据库事务保证强一致性。缓存仅用于加速读查询,杜绝因最终一致性导致的资产损失风险。
- 过期处理: 对于海量用户的过期提醒,放弃低效的在线扫表,采用 ‘T+1离线计算(Hive/Spark)’ 生成待提醒名单,再通过 消息队列进行削峰 后触达用户。数据清理采用惰性判断结合低频归档的策略。”
写在最后
积分系统绝非一个简单的计数器,它本质上是一套 资产管理系统。面试官通过这个问题,考察的不仅仅是你写SQL的能力,更是你对 数据一致性 的深刻理解,以及对 海量数据处理成本与方案选型 的精准把控。在云栈社区的后端 & 架构板块,常有关于此类系统设计更深入的讨论。账记清楚了,系统自然就稳了。
 发表于 2026-2-5 05:58:05
|
查看: 244|
回复: 0
发表于 2026-2-5 05:58:05
|
查看: 244|
回复: 0
