Elasticsearch 作为现代大型系统架构中的核心组件,其处理海量数据与高并发查询的能力至关重要。本文将从架构原理入手,详细剖析 Elasticsearch 如何支撑亿级流量的检索场景。
支撑亿级检索的核心架构
Elasticsearch 能够从容应对“亿级检索量”,其核心能力建立在四个关键设计之上:分布式分片架构、倒排索引与列式存储、查询剪枝与缓存机制、以及冷热分层与滚动索引策略。
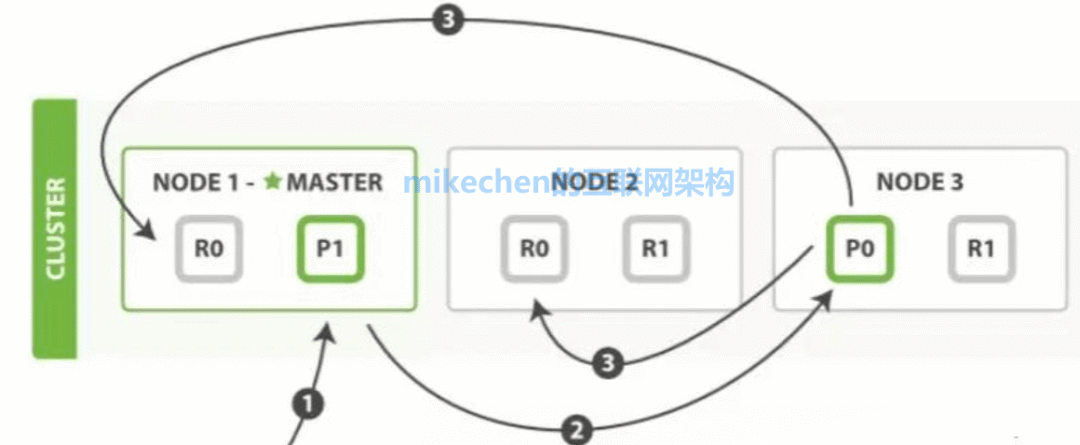
ES 通过将索引划分为多个分片(Shard),实现了数据的水平切分与存储。这些分片可以分布在集群的不同节点上,使得查询和写入操作能够并行处理,从而显著提升整体吞吐能力。同时,为每个分片创建副本(Replica),不仅提供了故障恢复的高可用性,还能分担读请求,实现读写分离与负载均衡。在亿级流量的检索场景下,合理的分片数量与副本策略,是保障高并发检索性能与系统可用性的基石。
分布式分片架构详解
在 Elasticsearch 的分布式架构中,一个索引被逻辑拆分为多个主分片(Primary Shard),每个分片本质上都是一个独立的、功能完整的 Lucene 索引。这种设计使得查询可以并行地在多个分片上执行,系统的读写吞吐量能够随着节点数和分片数的增加而近似线性扩展。
每个主分片又可以拥有一个或多个副本分片。副本分片的存在极大地提高了系统的读吞吐量(多个副本可以共同分担读取流量)和高可用性(当某个节点故障时,其上的分片可以由副本接管服务)。
在实际生产环境中,大型互联网公司的 ES 集群可以轻松扩展到数百个节点、管理百万级分片的规模。亿级数据被均匀分散到众多节点上,每个节点只需承担一小部分负载,从而使得整个集群能够扛住极高的 QPS(每秒查询率)检索压力。如果你对构建高可用的分布式系统有更多兴趣,可以到 云栈社区 的相关板块深入探讨。
倒排索引:全文检索的引擎
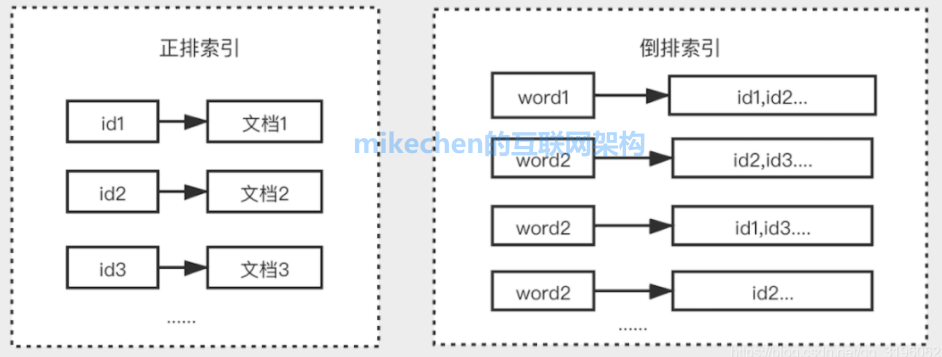
倒排索引是支撑全文检索高速响应的核心数据结构。它建立了从词项到包含该词项的文档列表的映射,使得根据关键词快速定位相关文档成为可能。
为了应对海量数据,Elasticsearch(基于 Lucene)在构建倒排索引时,采用了高效的字典、位图(BitMap)或跳表(Skip List)等数据结构来组织词项和文档ID列表。同时,它对索引数据进行了深度压缩,例如 DocValues 列式存储和 Postings List 压缩,这大幅减少了磁盘与内存的占用,提升了 I/O 效率,从而为大规模数据检索提供了可能。
分布式查询与缓存优化

当用户发起一个查询时,ES 的协调节点(Coordinating Node)会将查询请求拆分为多个子查询,分发到相关的数据分片(包括主分片或副本分片)上并行执行。各分片完成本地查询后,将结果返回给协调节点进行归并、排序等聚合操作,最终将完整结果返回给客户端。这一过程充分利用了集群的并行计算能力。
此外,ES 内置了多层缓存机制来优化高并发场景下的性能:
- 查询结果缓存:缓存特定查询的结果,对于完全相同的重复查询可以直接返回。
- 分片级请求缓存:缓存分片级别的查询结果。
- 文件系统缓存:Elasticsearch 重度依赖操作系统的页缓存(Page Cache),将索引的热点数据缓存在内存中,避免直接磁盘 I/O。
通过合理的查询路由、预热以及缓存配置,可以在高并发流量下保持稳定且低延迟的检索体验。
以上就是 Elasticsearch 支撑亿级流量检索的核心架构原理分析。在实践中,还需要结合具体的业务数据量、查询模式和应用场景进行细致的调优。如果你想了解更多关于数据库、中间件及其他技术栈的深度内容,欢迎访问 云栈社区 进行交流与学习。 |  发表于 2026-2-6 07:08:11
|
查看: 176|
回复: 0
发表于 2026-2-6 07:08:11
|
查看: 176|
回复: 0
