上一篇文章发布后,收到了一些关于“不看代码怎么保证质量”的讨论。我想说的是,当你能够熟练运用Claude Opus 4.5或同级别模型,并同时推进多个实际项目时,你会发现“写代码”本身正在快速贬值。
工作九年,我对编码、架构和故障排查能力有清晰的认知。亲手实现功能、定位隐蔽Bug、成功重构项目带来的成就感,确实令人兴奋。但时代在向前,固步自封的程序员终将被淘汰。程序员是一个需要终身学习的职业,它不会被AI替代,但会无情地淘汰那些止步不前的人。
背景:三人团队,如何保障每小时七万次告警的稳定性?
我目前正带领一个三人小组,负责重构公司的告警平台(基于夜莺二次开发)。项目已进入内测阶段,但一个现实的问题摆在我们面前:没有专职的测试人员,仅靠我一人Review代码来兜底质量,这几乎是不可完成的任务。
从一月份起,我的工作重心转向代码架构重构,核心目标是让AI编码更精准、更可控。为此,我们引入了OpenSpec规范、严格的编码约束、单元测试要求,并编写了辅助线上排查的AI Skill。
目前,平台仅接入了9个项目组,每小时告警规则的执行量已达7万次。想象一下,当公司百余个项目组全部接入后,必然会频繁出现“告警没触发,帮忙查一下”的求助。三人团队无力应对此类琐碎却消耗人力的答疑工作。
我们的解决方案是:让用户能清晰地感知告警执行的每一步。于是,“调度日志”功能被提上日程。令人惊讶的是,从需求分析、存储架构设计到编码实现,仅用了一周时间,两人便完成了初版上线。这,正是AI工程化赋能后所展现的交付能力。
整个项目代码量约三万行。通读并理解这三万行代码?这不现实。告警系统的稳定性至关重要,我必须找到一个可靠的机制,确保每个上线功能都“能用”,且不会引发稳定性问题。因此,我将目光投向了测试领域,这是我职业生涯中亟待补全的一环。
演进之路:从单元测试到黑盒集成测试
第一步:让代码变得“可测试”
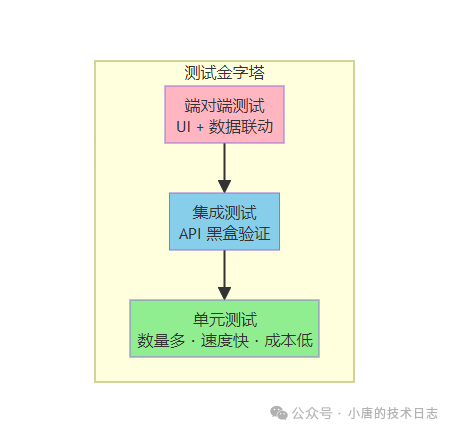
在工程化演进中,我们采用了DDD结合TDD的绞杀模式,对现有代码进行渐进式重构。大家都熟悉测试金字塔,单元测试是基石。有人会质疑:AI写的代码,再由AI写单元测试,能靠谱吗?
换个思路:单元测试的首要目的,未必是验证业务百分百正确,而是确保代码本身是“可测试的”。它迫使你写出结构清晰、依赖明确、便于隔离的代码,而非一堆难以测试的“泥球”。当发现问题时,让AI补充对应场景的单元测试,代码的稳定性便会逐步提升。因此,在我们的OpenSpec规范中,所有后端代码都必须附带单元测试。
探索过程:为什么UI自动化测试不是最优解?
仅有单元测试不足以验证复杂的端到端业务场景。为此,我花费了大半个月时间,深度实验了三种方案:
- 后端集成测试 —— 通过API验证完整业务流程。
- UI端到端测试 —— 使用Python + Playwright进行UI自动化。
- AI + MCP验收 —— 让AI直接操作浏览器并验证数据库状态。
最终结论是:后端集成测试为主,辅以AI/MCP验收,是最优组合。 UI自动化测试为何被放弃?其准确率偏低,维护成本高昂。AI生成的Playwright脚本命中率不稳定,且前端UI的频繁变动会导致测试用例大量失效,投入产出比不佳。
核心方案:基于API的黑盒集成测试
我们最终选用了Ginkgo测试框架。每次测试启动时,都会重建数据库、初始化基础数据,然后完全通过调用API来构建场景、触发业务并验证结果。

几个关键设计问题的解答:
Q:如何真实触发告警?
测试会完整编译并启动中心服务与告警引擎。告警规则、监控指标数据均由测试代码构造,并按照生产环境的标准流程——将指标数据推送到VictoriaMetrics,触发告警引擎评估规则,进而验证整个告警链路。
Q:测试结束后为何不清理数据?
有两个考量:一是担心API构造场景可能存在偏差,保留数据便于手动二次核查关联关系;二是为后续使用AI Skill进行自动化验收预留空间。
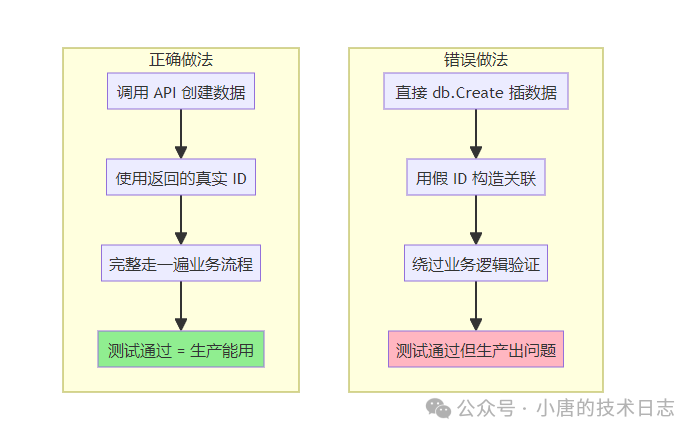
必须遵守的黑盒测试原则
这是整个方案最核心的纪律,必须严格执行:
| 规则 |
说明 |
| 数据创建必须通过API |
用户、用户组、业务组、策略、规则等所有前置数据,必须调用中心服务API创建,严禁直接操作数据库。 |
| 数据验证优先通过API |
验证系统状态时,优先调用查询API,而非直接读取数据库。 |
| 业务流程触发通过API |
推送指标、确认事故、解决事故等所有业务操作,必须通过API完成。 |
| 禁止硬编码假数据 |
禁止使用假ID(如 RuleId: 1001)直接插入数据库,必须使用API返回的真实ID。 |
为何要如此严格?
集成测试的目的是验证整个系统的端到端行为。直接操作数据库会绕过API层的参数校验、权限控制和核心业务逻辑。使用假数据则无法保障数据关联的完整性,可能导致测试场景与生产环境脱节,失去验证价值。
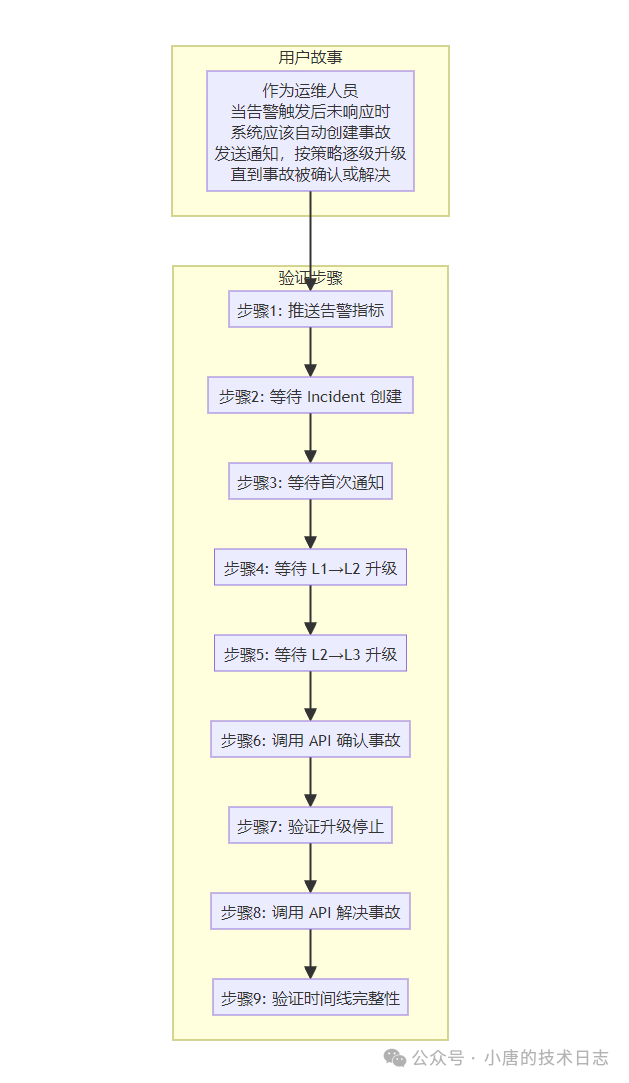
实战:一个P0级测试用例剖析
理论说再多,不如看代码。以“告警触发后未响应,系统应自动创建事故并逐级升级”这个P0场景为例,其用户故事和验证步骤设计如下:
对应的测试代码结构大致如下(使用Go语言和Ginkgo框架):
var _ = Describe("P0: FullEscalationFlow", Label("P0"), Ordered, func() {
BeforeAll(func() {
// 从共享上下文获取场景数据(已通过 API 创建)
scenario = sharedCtx.Scenarios["s_full_escalation"]
testTags = scenario.UniqueDefaultTags()
metricName = scenario.UniqueMetric("full_esc")
})
Context("步骤1: 推送告警指标", func() {
It("推送告警指标触发告警规则", func() {
// 推送 5 次指标,每次间隔 3 秒
err := localAPI.PushMetricsContinuously(metricName, 100, testTags, 5, 3*time.Second)
Expect(err).NotTo(HaveOccurred())
})
It("应该自动创建 Incident", func() {
// 等待 Incident 创建(最多 90 秒)
Eventually(func() int64 {
incidents, _ := localAPI.ListIncidents(api.ListIncidentsParams{
GroupID: scenario.BusiGroupID,
})
// ... 查找未解决的 Incident
}, 90*time.Second, 5*time.Second).Should(BeNumerically(">", 0))
})
})
Context("步骤3: 等待 L1→L2 升级", func() {
It("应该升级到 L2", func() {
Eventually(func() int {
incident, _ := localAPI.GetIncident(incidentID)
return incident.CurrentEscalationLevel
}, 75*time.Second, 5*time.Second).Should(BeNumerically(">=", 2))
})
})
// ... 后续步骤
})
这段代码体现了几个关键点:
- 场景数据通过API创建:在
BeforeAll 中使用的数据,是预先通过调用真实API创建的,绝非硬编码的假数据。
- 使用
Eventually 等待异步结果:对于告警触发、状态变更等异步操作,使用 Eventually 进行轮询等待,而非写死的 Sleep,使测试更健壮。
- 每个
It 验证一个业务预期:测试聚焦于“系统应该做什么”,而不是“代码如何实现”。
- 完善的失败诊断:测试失败时,会自动收集事故状态、通知记录、时间线等上下文信息,便于快速定位。
测试分层与执行策略
我们将测试用例按优先级分为三层,平衡了反馈速度与覆盖广度:
| 优先级 |
场景示例 |
运行时机 |
| P0 |
完整升级流程、确认后停止升级 |
每次代码提交 |
| P1 |
最大升级次数限制、策略优先级、自动恢复、通知验证 |
每日定时构建 |
| P2 |
边界条件、异常处理、基础CRUD操作 |
发布前回归测试 |
通过Ginkgo的标签过滤功能,可以灵活选择执行范围:
# 仅快速验证核心P0流程(约5分钟)
go test ./tests/integration/duty/... -v --ginkgo.label-filter="P0"
# 执行P0+P1,进行完整功能验证(约15分钟)
go test ./tests/integration/duty/... -v --ginkgo.label-filter="P0 || P1"
AI如何赋能测试调试与维护
当测试失败时,我的排查工作流已经高度依赖AI协同:
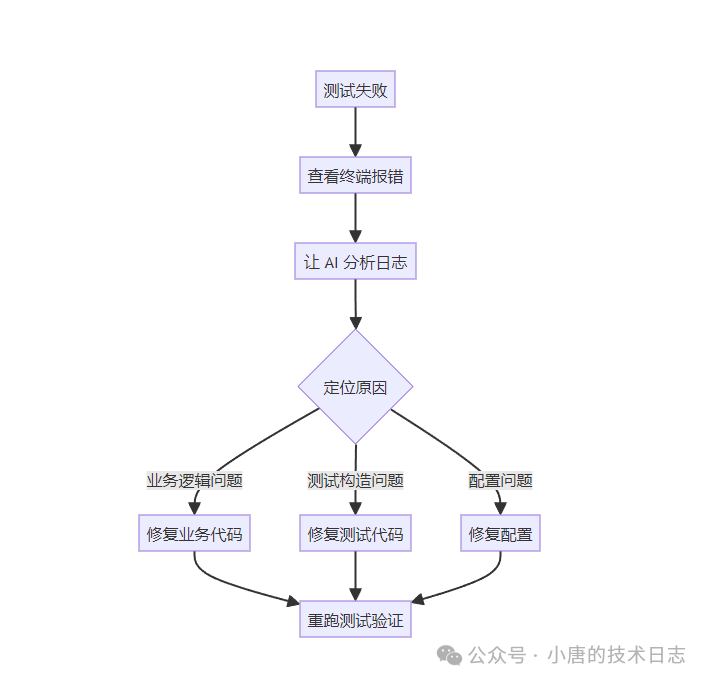
具体操作时,我会将终端报错信息和日志文件路径直接抛给AI,指令如下:
“P0测试在第180行失败,相关日志在 logs/alert.log,请帮我分析根本原因。”
AI会主动去搜索 workers_created、incident created、escalation 等关键日志,快速定位问题究竟是规则未加载、事故未创建,还是升级逻辑未触发。这套流程下来,从发现测试失败到定位并开始修复,通常只需3到5分钟。
思考:AI时代,程序员角色的必然演进
不知你是否意识到,程序员的核心价值在于完整交付一个可用的需求。在AI普及之前,编码占据了大量体力劳动,导致测试环节常常需要他人分担(即便简单的P0场景,开发者也需手动验收)。正因为编码是重体力活,很少有人愿意再额外编写自动化验收脚本。
但AI时代改变了这一切。我们小组的成员现在需要全面承担设计、编码、测试、运维的职责。这并非内卷,而是后端工程师面向未来必须完成的角色演进。
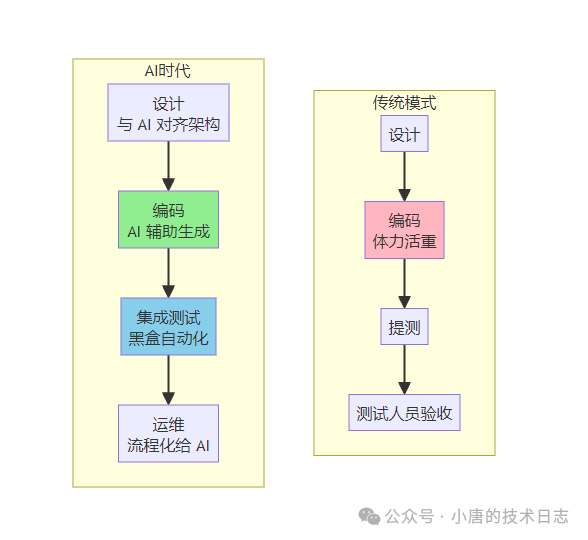
具体职责转变如下:
- 设计:与AI充分对齐架构与需求细节,你必须预判AI会如何实现。
- 编码:将具体的实现任务交给AI。
- 测试:遵循黑盒测试原则,由于你不深入代码细节,你的职责是对功能、场景和最终结果负责。
- 运维:你能阅读的代码和查询的数据,AI同样可以。关键在于将你的排查手段流程化、工具化,赋能给AI,让它比你更快地执行。
至于更高阶的系统规划、架构演进等依赖深厚经验的工作,其价值将愈发凸显。
总结与展望
这套集成测试体系运行近一个月,带来了几点深刻体会:
- 测试是信心的来源:无需过度焦虑AI生成的代码是否有隐患,测试通过即代表功能可用。
- 场景驱动优于盲目追求覆盖率:与其执着于达到80%的代码覆盖率,不如切实保障所有核心业务场景(P0)的畅通无阻。
- AI是高效的调试伙伴:将日志分析、关键词检索、根因定位等繁琐工作交给AI,能极大提升排查效率。
- 测试代码同样需要工程化:测试代码也是软件产品的一部分,需要良好的抽象、设计和持续重构,切忌写成难以维护的“一次性脚本”。
如今的Claude Opus 4.5,其能力大约只是一年前Sonnet 3.5的水平。试想一下,未来模型的进化速度又将如何?
焦虑吗?我已度过那个阶段。现在,我更多的感受是:只要你有好的想法,就有能力将其实现。我庆幸自己在职业生涯中,涉足了规划、设计、编码、运维、架构演进的方方面面。记得几年前面试时,我曾问对方:“你们的服务跑在哪里?上线流程是怎样的?”得到的回答是:“点一键发布就行,做业务不需要关心这些。”
时代真的变了。
(最后,谁能保证代码Review后,就100%没有Bug呢?)
 发表于 2026-2-7 09:38:43
|
查看: 142|
回复: 0
发表于 2026-2-7 09:38:43
|
查看: 142|
回复: 0
