如果你也遇到过Kubernetes容器日志“不翼而飞”的情况,明明容器运行得好好的,半小时甚至更早的日志却怎么也查不到,这篇文章将为你揭开谜底。这背后并非是灵异事件,而是由Kubernetes的日志管理机制决定的。要彻底理解并解决它,我们需要从节点本地日志的保存规则说起。
一、节点本地默认日志保存机制(由Kubelet管控)
在K8s集群中,容器打印到标准输出(stdout/stderr)的日志默认由kubelet组件负责收集和管理。其核心策略是基于“文件大小+数量”的双重限制,而非基于一个固定的时间周期(比如7天或30天)。
1. 核心限制参数(默认值)
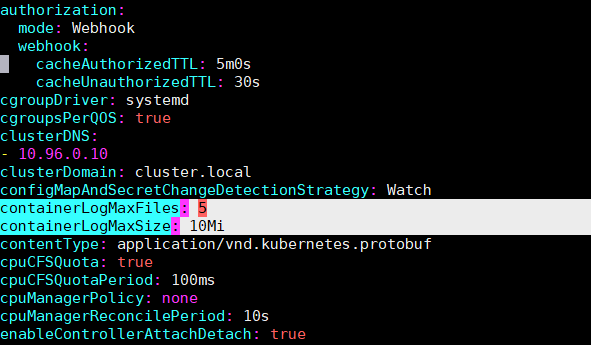
你可以查看kubelet的配置文件(通常位于/var/lib/kubelet/config.yaml)来确认以下参数:
containerLogMaxSize: 10Mi:单个日志文件的最大尺寸为10MiB。一旦日志文件达到这个大小,kubelet就会触发日志轮转。containerLogMaxFiles: 5:每个容器最多保留5个日志文件(这包括了当前正在写入的活跃文件)。
简单计算一下:按照默认配置,单个容器在本地的日志存储上限大约是 50MiB(10MiB * 5个文件)。
2. 日志存储路径
- Docker运行时:日志实际存储在
/var/lib/docker/containers/$CONTAINER_ID/$CONTAINER_ID-json.log,同时kubelet会在/var/log/pods和/var/log/containers目录下创建对应的软链接,便于统一访问。
- Containerd运行时:日志由kubelet直接管理,存储在
/var/log/pods/<pod_uid>/<container_name>/目录下,通常以0.log、1.log……命名。

3. 容器日志的生命周期
这里有两个关键点:
- 容器删除,日志同步删除:当Pod或容器被删除时,kubelet会清理掉其对应的所有日志文件。本地不会保留已终止容器的日志。
- 轮转基于大小,而非时间:日志轮转的唯一触发条件是文件大小达到
containerLogMaxSize。因此,对于日志输出量巨大的应用(例如高频调试日志),可能几小时甚至几分钟内就会写满10MiB并完成多次轮转,导致“半小时前的日志”被覆盖;而对于输出极少的应用,日志文件可能留存数天。
二、影响日志保存时长的关键因素
1. 容器运行时的差异
- Docker:除了kubelet的管控,Docker自身的日志驱动(如默认的
json-file)也有配置项(如max-size, max-file),如果配置不当可能与kubelet的策略产生冲突。生产环境更推荐使用Containerd。
- Containerd:日志管理完全交由kubelet控制,配置更统一,行为更可预测。
2. 日志输出方式的巨大影响
容器内应用的日志输出目的地不同,其保存机制也完全不同。
| 输出方式 |
保存机制 |
保存时长特点 |
| 标准输出 (stdout/stderr) |
kubelet 统一管控 |
严格遵循上述50MiB/5个文件的默认限制,容器删除即日志删除。 |
| 写入容器内文件 |
由应用自身或Sidecar(如filebeat)管理 |
完全不受kubelet限制。如果应用没有配置日志切割和清理,日志文件会无限增长,直至占满磁盘。 |
| 挂载HostPath到宿主机 |
作为宿主机普通文件存在 |
脱离容器生命周期,需要像管理宿主机日志一样,手动或通过logrotate等工具进行清理。 |
logrotate是Linux系统的标准日志管理工具,用于自动轮转、压缩和删除日志文件,是管理宿主机日志和通过HostPath挂载的日志的必备工具。
3. 自定义kubelet配置以延长本地保存
如果你确实需要节点保留更多日志(例如用于短期的本地调试),可以修改kubelet配置:
- 编辑kubelet配置文件:
vim /var/lib/kubelet/config.yaml
修改或添加以下参数:
containerLogMaxSize: “20Mi” # 将单个文件大小上限提高到20MiB
containerLogMaxFiles: 10 # 将保留文件数增加到10个
- 重启kubelet服务使配置生效:
systemctl restart kubelet
注意:此修改仅对此后新创建的容器生效,不会影响已经运行的容器。
三、持久化日志方案:突破本地限制的根本方法
节点本地日志应被视为临时缓存,而非可靠的长期存储。生产环境必须部署集中式日志系统,这是确保日志可长期查询、满足审计和排障需求的唯一途径。
1. EFK/ELK Stack(核心是Elasticsearch)
保存时长控制方式:
通过Elasticsearch的索引生命周期管理(ILM)策略,可以基于时间对日志进行分层管理和自动清理。
- 典型策略:热数据(0-7天)存放于SSD高性能存储;温数据(7-30天)移至普通硬盘;冷数据(30天以上)归档到对象存储(如S3)以降低成本。
- 常用保留周期:开发环境7-14天,生产环境30-90天,审计日志180天以上以满足合规要求。
配置示例(ILM策略):
{
“policy“: {
“phases“: {
“hot“: {
“actions“: {
“rollover“: {
“max_age“: “7d“ // 7天后滚动生成新索引
}
}
},
“delete“: {
“min_age“: “30d“, // 索引创建30天后执行删除
“actions“: {
“delete“: {}
}
}
}
}
}
2. 云厂商托管日志服务
- 阿里云SLS:默认保存90天,可配置1-3650天或永久保存。
- 腾讯云CLS:支持按存储容量或时间自动清理。
这类服务开箱即用,免运维,是许多团队的便捷选择。关于日志系统的选型与搭建,你可以在 云栈社区 的运维/DevOps板块找到更多深度讨论和实战案例。
四、特殊场景的日志处理
1. 容器内文件日志(非标准输出)
- 风险:此方式完全绕过kubelet的自动轮转,极易导致容器或宿主机磁盘空间被撑满。
- 解决方案:
- 应用内配置:强制要求所有写入文件的日志,必须在应用框架(如Logback、Log4j2)中配置按大小/时间切割,并设置合理的保留文件数(如保留最近7天的日志)。
- Sidecar采集:部署一个Fluent Bit或Filebeat容器作为Sidecar,与业务容器共享日志目录卷,实时读取日志文件并转发至集中式日志系统。同时,在宿主机或容器内配置
logrotate定期清理已被采集的本地日志文件。
2. 短生命周期Pod的日志
- 问题:Job或CronJob这类Pod运行完即销毁,其日志可能在被日志采集Agent抓取之前,就被kubelet清理掉了。
- 优化措施:
- 使用Sidecar优先采集:为短生命周期Pod也配置日志采集Sidecar,确保日志在Pod终止前被送出。
- 调整容器运行时设置:部分版本的Containerd支持延迟删除容器日志的功能,可以为日志采集争取时间。
五、最佳实践总结
- 基础配置强化:
- 统一并适度调整kubelet的
containerLogMaxSize(如20MiB)和containerLogMaxFiles(如10),在磁盘空间和本地可查日志量间取得平衡。
- 监控所有节点
/var/log目录所在分区的磁盘使用率,并设置告警(如>80%)。
- 日志输出规范:
- 强制规定:所有应用日志优先、直接输出到标准输出(stdout/stderr),这是最符合云原生理念、最易于采集的方式。
- 对于必须写文件的特殊日志,必须在应用层面配置严格的轮转和清理策略。
- 集中式日志系统必选:
- 根据集群规模和复杂度选择方案:轻量级可选Grafana Loki,功能全面则选EFK/ELK Stack。
- 务必配置分层存储和基于时间的自动清理策略(ILM),以控制成本。
- 满足合规与审计要求:
- 金融、医疗等行业需遵循法规(如等保2.0)要求,确保审计日志保存至少6个月。
- 关键业务日志建议保留90天以上,以便有充足时间进行问题回溯和分析。
总结
回到最初的问题:“K8s容器半小时前的日志怎么没有了,容器也没重启?”
根本原因在于:K8s节点本地默认没有基于时间的日志保留策略。日志的留存完全取决于日志输出速度与containerLogMaxSize、containerLogMaxFiles的配置。高频日志可能在很短时间内就被轮转覆盖。
因此,一个明确的答案是:要可靠地保存和查询历史日志,必须依赖部署到集群外部的集中式日志系统,并配置明确的数据保留策略。 本地日志只是临时缓冲区,绝非可依赖的数据源。理解这套机制,能帮助开发者和运维更高效地协作定位问题。如果你在实践中遇到了更多复杂的日志管理挑战,欢迎到云栈社区的云原生板块交流分享。 |  发表于 2026-2-8 02:57:19
|
查看: 199|
回复: 0
发表于 2026-2-8 02:57:19
|
查看: 199|
回复: 0
