大型语言模型(LLM)通过海量文本数据进行学习,能力日益强大。有趣的是,模型之间也能进行知识传递,甚至像师徒一样手把手地教学。这种模型间的知识传承技术,就叫做知识蒸馏,其核心目标是高效地将一个大型模型(教师模型)所学的知识“灌输”给另一个模型(学生模型)。
1. 知识蒸馏的应用时机
知识蒸馏并非只能在模型训练完成后进行,它实际上可以灵活应用于两个关键阶段:
- 预训练阶段:让经验丰富的教师模型(Teacher LLM)与一张白纸般的学生模型(Student LLM)同时训练,实时指导。
- 训练完成后:在教师模型已经“学有所成”后,将其积累的知识系统性地传授给学生模型。
当然,学生模型也可以在上述两个阶段都积极地汲取教师模型的知识,实现更全面的学习。
2. 软标签蒸馏 (Soft-label Distillation)
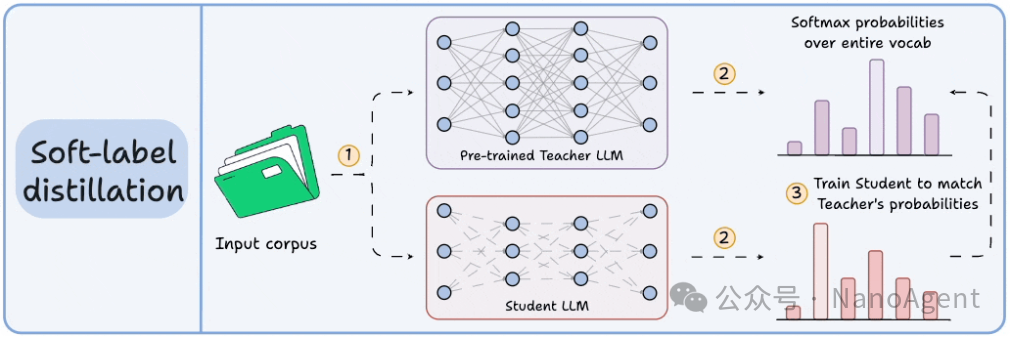
想象一下,一位老师教你解题时,不仅告诉你最终答案,还把解题的每一步思路、为什么这么选都详细解释清楚。软标签蒸馏就是类似的原理。
在这种方法中,对于给定的输入,教师模型不仅输出一个确定的答案(硬标签),还会输出一个涵盖整个词汇表的概率分布(软标签)。学生模型的学习目标,就是让自己的输出概率分布尽可能贴近教师的这个“软”概率分布。
优点:这种方式能最大程度地传递教师模型的推理能力和隐性知识,因为它揭示了模型判断的“置信度”和备选可能性。
挑战:软标签会产生海量的数据。试想,如果词汇表有10万个词,训练文本达到5万亿词元(token),那么需要存储的软标签数据量将是天文数字,对存储和计算资源要求极高。
3. 硬标签蒸馏 (Hard-label Distillation)
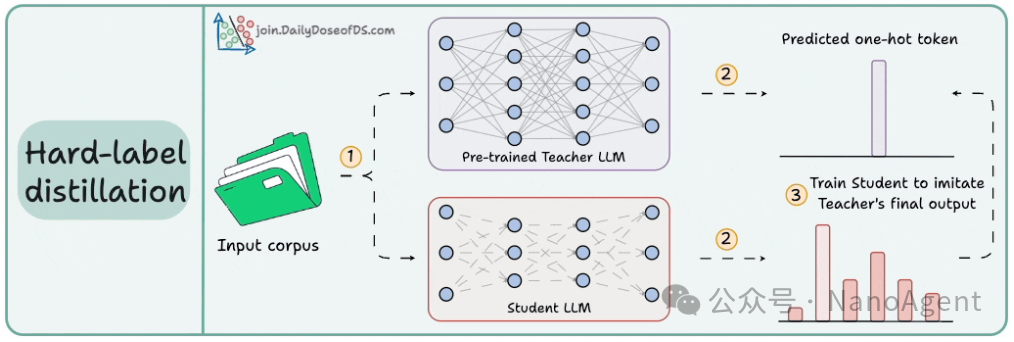
硬标签蒸馏则直接得多,它不要求学生模型学习教师的整个思考过程,而只要求其模仿教师的最终输出结果。例如,DeepSeek 通过将 DeepSeek-R1 提炼为 Qwen 和 Llama 3.1 模型时,就采用了这类方法。
优点:方法简单高效,避免了存储和传输庞大软标签数据的问题。
缺点:由于学生模型只学到了“答案”而没有学到“推导过程”,信息被高度压缩,可能导致模型更容易产生“幻觉”(输出不合逻辑或无根据的内容)。常见的解决策略有两种:一是将教师模型的推理过程(如思维链)也以硬标签形式写出来供学生模型学习;二是在蒸馏完成后,通过人工反馈(RHLF)等方式进行校正和微调。
4. 共蒸馏 (Co-distillation)
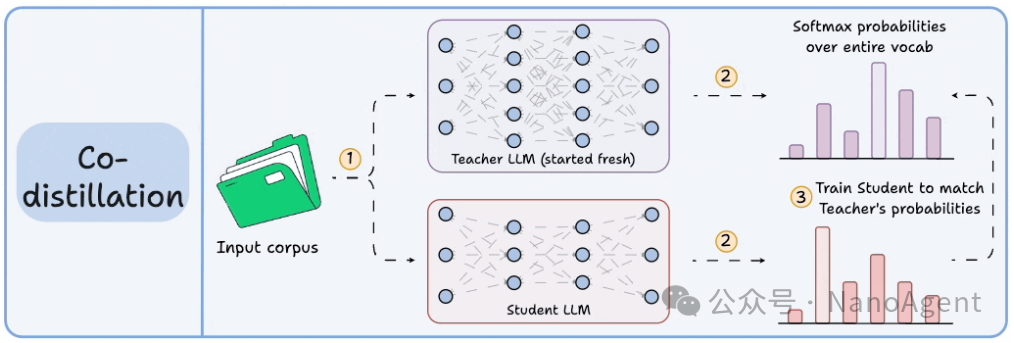
在共蒸馏的设定中,教师模型和学生模型都是“新手”,都从零开始或处于早期训练阶段。它们会同时对输入的文本进行预测。随后,教师模型会基于真实标签(或其它监督信号)进行常规的梯度更新训练,而学生模型的训练目标,则是让自己的预测输出与当前这位“新手教师”的输出保持一致。
优点:这种方法可以避免传统蒸馏中,因教师模型早期能力不足而导致的知识传递质量不高问题。师生在训练过程中相互促进,共同进步。
总结
知识蒸馏作为一种高效的模型压缩与知识迁移技术,让大模型之间的经验得以传承,加速了人工智能领域的迭代与发展。无论是细致入微的“软标签”传授,还是直截了当的“硬标签”模仿,亦或是共同成长的“共蒸馏”策略,这些巧妙的方法都在持续推动大模型变得更高效、更强大。
想了解更多关于 Transformer 架构、模型微调等前沿深度学习技术讨论,欢迎访问 云栈社区,与广大开发者一起交流学习。 |  发表于 2026-2-8 04:39:42
|
查看: 182|
回复: 0
发表于 2026-2-8 04:39:42
|
查看: 182|
回复: 0
