Project Valhalla前瞻:Java泛型性能短板与2026年值类型革新
21世纪初的软件开发领域正处于一个剧烈变革的前夜。在托管语言(Managed Language)的战场上,Java已经确立了其企业级霸主的地位,而微软的.NET Framework刚刚作为挑战者登场。2004年,Java 5发布;2005年,C# 2.0紧随其后。这两大语言几乎在同一时间点引入了泛型。表面上看,它们达成了共识,但这看似相同的语法背后,隐藏着两个工程团队在架构哲学上的巨大分歧。
向左转,向右转:类型擦除与运行时特化
Java和C#的泛型在编译时都为开发者提供了类型安全的契约,承诺编译器将负责维护集合内容的完整性。让我们先看两段几乎同时代的代码:
Java 5 代码:
List<String> names = new ArrayList<String>();
names.add(“Anders”);
names.add(“Gilad”);
String n = names.get(0); // 不需要显式强制转换
C# 2.0 代码:
List<string> names = new List<string>();
names.Add(“Anders”);
names.Add(“Gilad”);
string n = names[0]; // 不需要显式强制转换
除去细微的语法习惯差异,这两段代码在语义上几乎完全一致。然而,如果我们查看这两段代码编译后的字节码(Bytecode)和中间语言(IL),会发现它们截然不同。Java的泛型类型信息主要存在于编译阶段,在运行时则选择了隐退;而C#的泛型则被完整保留,成为了运行时可识别的实体。

Java类型擦除与C#运行时特化流程示意图
这背后的决策逻辑源于截然不同的历史包袱与目标。对于Java团队来说,2004年的Java已经是一个拥有庞大遗产的巨人。Sun Microsystems面临着一个严峻的挑战:如何引入泛型,而不破坏现有的生态系统?答案就是类型擦除(Type Erasure)。这是一个极为务实但充满了技术债色彩的决定。他们的核心思想是:泛型只是编译器的“护栏”,一旦代码通过了编译,所有的泛型信息就会被擦除,字节码中只剩下原始类型。这保证了新老代码的二进制兼容性,实现了生态系统的平滑过渡。
而在微软的雷德蒙德园区,Anders Hejlsberg面临着完全不同的局面。.NET Framework当时还是一个初出茅庐的新手。更重要的是,Anders深知如果泛型不能高效地支持值类型,那么它在高性能计算领域的价值将大打折扣。C#团队做出了一个大胆的决定:修改CLR,在CLR 2.0中引入了原生的泛型支持。这意味着C#的泛型是 具现化(Reification) 的。
揭开魔术:编译器的“标签”与虚拟机的“模具”
Java的泛型实现被戏称为“编译器的魔术”。让我们通过观察字节码来揭示这个魔术。假设有一个简单的Java泛型类:
public class Box<T> {
private T value;
public T get() { return value; }
}
当我们编写 Box<String> box = ...; String s = box.get(); 时,直觉上我们认为 get() 方法返回的是String。但使用 javap -c 反编译生成的.class文件,我们会看到字段类型是 Ljava/lang/Object;。T 已经彻底消失了,变成了 Object。而在调用端,编译器会插入一条 checkcast 指令进行运行时检查。
这种设计导致了几个严重的副作用:
- 无法使用基本类型:你不能写
List<int>,这迫使Java使用包装类(Integer),带来了巨大的内存和性能开销。
- 反射能力的缺失:在运行时,你无法通过反射知道一个
ArrayList 原本是 ArrayList<Integer> 还是 ArrayList<String>。
一个例子:
public class ErasureDemo {
public static void main(String[] args) throws Exception {
List<String> names = new ArrayList<>();
names.add(“OK”);
// 反射绕过泛型检查,强行塞入一个 Integer
Method add = ArrayList.class.getMethod(“add”, Object.class);
add.invoke(names, 123);
// ✅ 只当 Object 用(打印),不会立刻报错
System.out.println(names.get(1)); // 123
// ❌ 一旦要求它必须是 String,就会触发 checkcast,当场爆炸
String s = names.get(1); // ClassCastException
System.out.println(s.length());
}
}
你会发现:错的东西可以先“潜伏”在列表里。只要你一直把它当 Object 用,程序还能继续跑;但一旦你要求它必须是特定的类型,编译器插入的 checkcast 就会爆炸。但有一点需要注意:Java 的泛型并非“失忆”,而是“位移”。泛型信息从“对象本身”转移到了“类的定义”中,通过 class 文件中的 Signature 属性保留。
而在C#中,泛型信息被完整地保留到了IL(中间语言)中,并最终被JIT(即时编译器)利用。
public class Box<T> {
public T Value;
}
编译后的IL代码中,!T 是一个受尊重的、明确的类型符号。当程序运行并第一次遇到 Box<int> 时,CLR的JIT编译器会根据蓝图动态生成一段专门针对 int 优化的机器码。如果接着遇到 Box<float>,JIT会再次启动,生成一份专门针对 float 的代码。
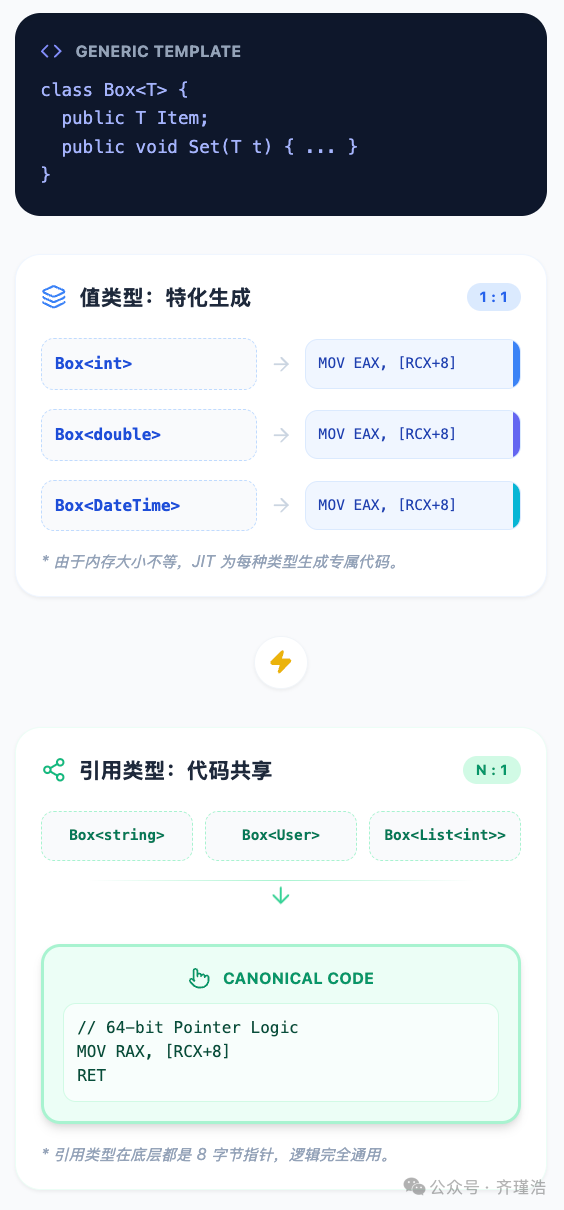
JIT针对值类型特化代码,针对引用类型共享代码的机制
沉重的代价:性能杀手“装箱”
类型擦除带来的最大痛点,莫过于对Java基本数据类型的排斥。由于擦除后的底层容器是 Object,而Java中的 int, long, double 不是对象,它们不能被放入 Object 中。为了解决这个问题,Java引入了自动装箱机制,自动将 int 转换为 Integer 对象。这看似方便的语法糖,实际上是高性能计算的梦魇。
它引入了两个巨大的性能杀手:内存膨胀与指针追逐。
比内存膨胀更可怕的是对CPU缓存的破坏。现代CPU严重依赖多级缓存(L1/L2/L3)。缓存以“缓存行”(Cache Line,通常64字节)为单位加载数据。
C# 的场景 (缓存友好):
当你遍历 List<int> 时,数据是连续平铺的。一次64字节的缓存行加载不仅读取了第1个整数,还顺便把第2到第16个整数一起加载进了L1缓存。当你处理下一个整数时,它已经在缓存里等着你了。
Java 的场景 (缓存未命中):
当你遍历 ArrayList<Integer> 时,list.get(i) 只是拿到了一个内存地址(引用)。真正的整数值位于堆内存的某个随机位置。CPU必须根据这个地址去抓取数据,导致频繁的“指针追逐”和缓存未命中,性能可能相差一个数量级。
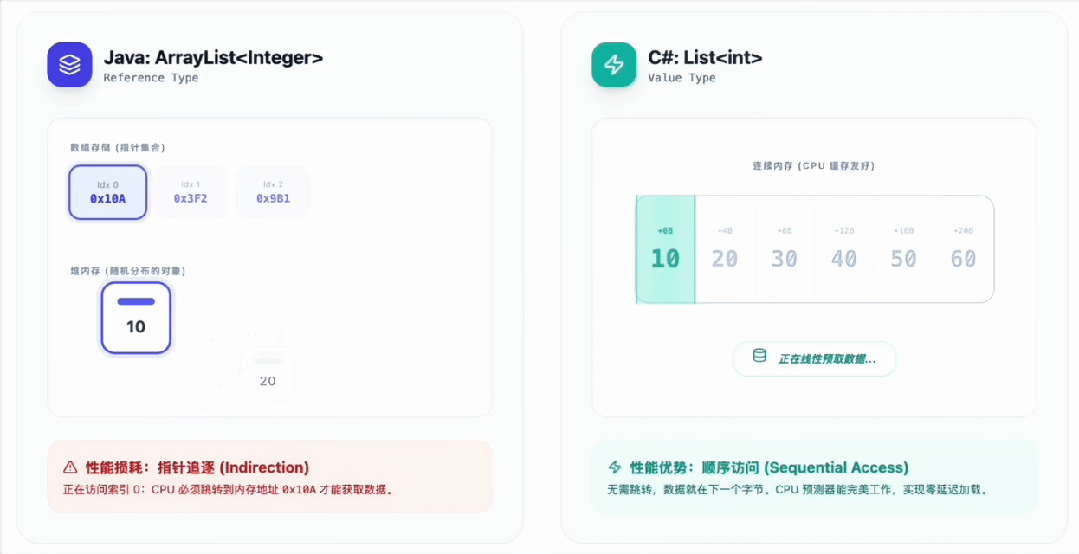
Java引用类型集合与C#值类型集合在内存访问模式上的差异
这就是为什么在过去二十年里,Java开发者在进行高性能计算时,往往被迫放弃标准的 ArrayList,转而使用原始的 int[] 数组,或者使用第三方库来模拟原始类型集合,退化回非面向对象的编程模式。这种性能短板在后端 & 架构领域,尤其是高并发、大数据处理场景下,一直是开发者心中的隐痛。
Project Valhalla:二十年的救赎之旅
Java架构师们并非不知道C#的优势。但是,要在一个已经有千万级开发者和海量遗留代码的平台上“换引擎”,其难度无异于在飞行中更换飞机引擎。
这就是 Project Valhalla 的使命。这个项目启动于2014年左右,是OpenJDK历史上最复杂、最雄心勃勃的项目之一。它旨在解决Java泛型的核心历史问题,其核心是通过引入值类型(Value Types)和泛型特化(Generic Specialization)来填补性能鸿沟。
站在2026年的视角回顾,Project Valhalla的成果终于开始落地。
JEP 401: Value Classes and Objects 引入了新的关键字 value。
// 2026年的 Java 代码示例
public value class Point {
int x;
int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
}
这段代码定义的 Point 类具有革命性的特性:
- 无身份(Identity-less):你不能对
Point 对象使用 synchronized 锁,== 比较的是字段值而非内存地址。
- 不可变(Immutable):字段默认是
final 的。
- 内联存储(Flattening):JVM知道它没有身份,因此在数组或对象中,可以直接存储
x 和 y 的值,而不是存储指向它的指针。
关键细节:Point! 与 Point? 的博弈
在2026年,Java引入了 Null-Restricted Types(非空受限类型)。Valhalla引入了 ! 符号:
Point? (或 Point): 可为空的值对象。Point! : 非空值对象。这是一个严格的承诺,变量永远不会是null。JVM可以毫无顾忌地将其像 int 一样彻底平铺在内存中,去掉了所有的对象头和指针开销。
这标志着Java终于在语法层面引入了C#早在2005年就拥有的“结构体语义”,但以一种更符合Java面向对象传统的方式。
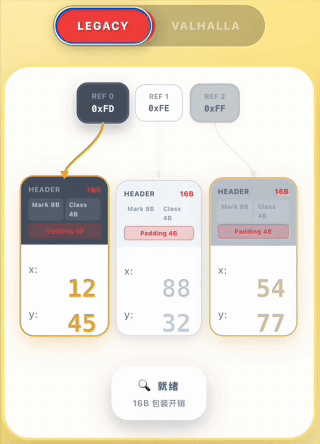
值类型内联存储与旧引用类型内存布局对比,显著减少了开销
有了值类型还不够,关键是让 List<int> 能够像C#的 List<int> 一样高效。这就是 JEP 402: Generic Specialization (Parametric JVM) 的任务。
Java正在对其泛型系统进行“迟到的具现化”。JVM将具备一种能力:当它看到泛型参数是值类型(如 int 或 Point!)时,它会在运行时动态生成一个特化的类,比如 ArrayList$int。这个特化类的底层数组将是 int[] 而非 Object[]。
这意味着,在2026年,Java终于可以写出 ArrayList<int>(或者至少是性能等价的 ArrayList<int!>),并在性能上追平C#。
工程师的宿命:生态与工程的取舍
回顾这二十年的演进,我们很难简单地判定谁输谁赢。这更像是一场关于“技术债”的实验。
Java赢在了生态。Sun在2004年选择类型擦除,是为了保护当时的软件资产。这个决定虽然让Java背负了沉重的性能包袱,但它避免了社区的分裂,使得Java能够平稳地渡过泛型转型期,并在大数据、高并发服务领域建立了坚不可摧的生态壁垒。
C#赢在了工程。微软选择具现化泛型,是为了追求架构的完美和长期的性能红利。这个决定让C#成为了一个在底层能力上更强大的语言,能够轻松胜任高性能游戏开发、系统级编程等Java曾难以涉足的领域。
编程语言的演进史,本质上就是一部“如何优雅地处理历史债务”的历史。Java用了20年的时间,通过Project Valhalla,终于在不破坏 Object 崇高地位的前提下,找回了丢失的性能。它证明了即使是背负着最沉重历史包袱的巨轮,也可以通过精妙的工程设计完成转身。
对于工程师而言,工具的优劣是表象,背后的权衡是真相。所有的抽象皆有代价,所有的兼容皆有隐形成本。深入理解这些底层机制,才能做出更明智的技术选型与设计。在云栈社区这样的技术论坛中,也常有关于这类底层设计权衡的深入探讨,对于开发者理解计算机基础原理大有裨益。
在2026年,当我们在Java中写下 Point! 时,我们不仅是在声明一个非空对象,更是在向二十年前那场关于类型、性能与未来的伟大博弈致敬。
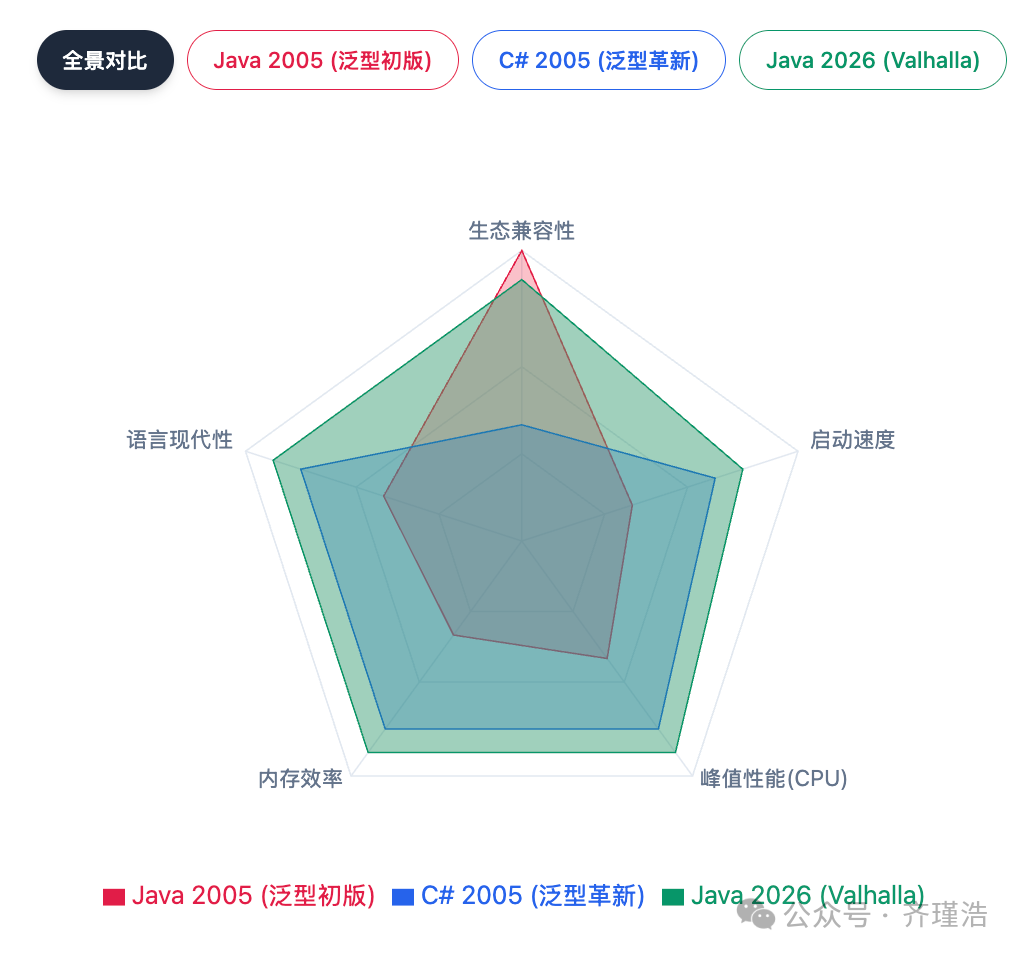
Java 2005、C# 2005与Java 2026 (Valhalla) 在多个维度的综合对比
数据与性能对比
表1:存储100万个整数的内存开销对比 (64位环境)
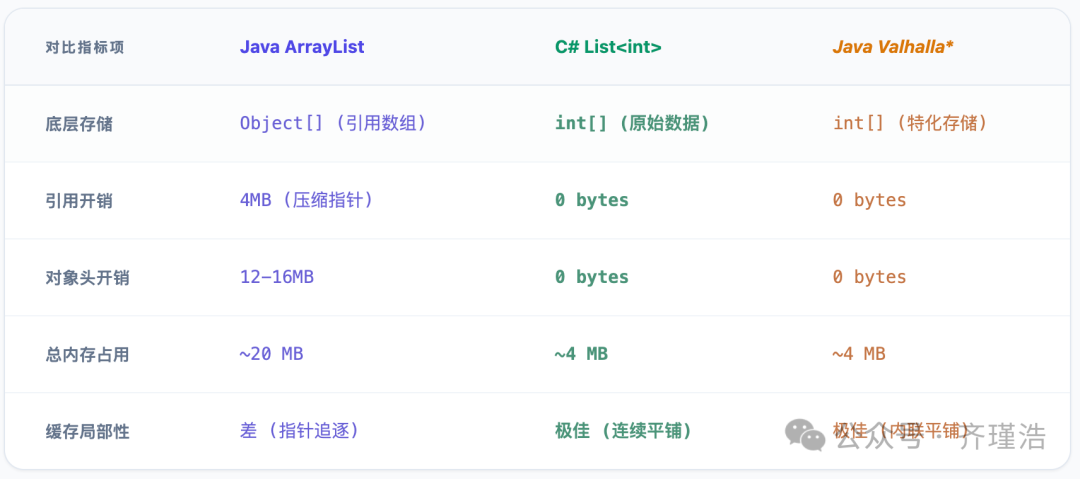
Post-Valhalla数据基于完全特化泛型和非空值类型的理想实现预估。
Tips: 那个带 * 的 Specialized 是 Java 苦等二十年的“完全体”。它意味着 JVM 会在运行时通过自动克隆技术,为 int 这种值类型单独复印一份专属代码。虽然会内存膨胀,但跑起来是真的快。
注释
[1] 托管语言 (Managed Language): 程序员不需要手动写 malloc 或 free 来管理内存。Java 的 JVM 和 C# 的 CLR 就像“管家”,自动帮你回收垃圾(GC)、管理运行安全。
[2] 具现化 (Reification): 让泛型信息在运行时真实存在。之所以叫“具现化”,是因为 C# 的泛型不是“写给编译器看的”,而是 T 在运行时也会现身,变成 CLR 能识别、能利用的真实类型。具现化 = T 不消失。
[3] 二进制兼容性 (Binary Compatibility): 指旧版编译器编译出来的 .class 或 .dll 文件,直接拿到新版虚拟机上也能跑,不需要重新修改代码或编译。这是 Java 宁愿背负“类型擦除”包袱也要守护的底线。
[4] 缓存行 (Cache Line): CPU 从内存拿数据不是一个字节一个字节拿,而是一次性抓一小块(通常 64 字节)。C# 的紧凑布局能让这一抓抓到 16 个整数,而 Java 往往只能抓到一个指针,还得再去别处找真正的数字。
 发表于 2026-2-8 23:43:19
|
查看: 219|
回复: 0
发表于 2026-2-8 23:43:19
|
查看: 219|
回复: 0
