1. 什么是性能?
在开始设计之前,我们首先要明确目标:到底什么是性能,以及我们应该如何去衡量它。
1.1 专业性描述
软件系统的性能,指的是其处理请求任务的速度、效率以及有效利用计算资源(如CPU、内存、网络、磁盘I/O)的能力。其根本目标是在合理的资源消耗下,尽可能快地完成业务逻辑,并支撑尽可能多的用户同时访问。
1.2 大白话类比
这就好比评价一家超市的运营效率。
- 速度:一个顾客从进门、选购商品到结账离开总共花了多长时间(系统响应时间)。
- 效率:在一天之内,这家超市总共服务了多少名顾客(系统吞吐量)。
- 资源利用:超市的收银台、理货员是忙得脚不沾地,还是大量时间闲置(系统资源利用率)。一个好的超市经理,要追求让顾客等待时间短、每日服务顾客数量多,同时收银台等资源既不过度劳累(导致排队过长)也不大量闲置(造成成本浪费)。
1.3 性能的度量指标
衡量系统性能,我们主要看三类指标:
| 指标类型 |
描述 |
“易购网”示例 |
| 响应时间 |
系统对请求作出响应所需要的时间。这是用户最能直接感知的指标。 |
用户点击“搜索”按钮后,到结果页面完全加载出来的时间。我们不仅看平均值(如200毫秒),更关注95分位值(95%的请求在300毫秒内完成),因为少数慢请求非常影响用户体验。 |
| 吞吐量 |
单位时间内系统能成功处理的请求数量。它衡量系统的处理能力。 |
系统每秒能成功处理的订单创建请求数(如每秒1000单)。在“双十一”大促时,吞吐量是核心指标。 |
| 资源利用率 |
各类计算资源(如CPU、内存、磁盘IO、网络带宽)的使用率。 |
在吞吐量达到每秒1000单的时候,服务器的CPU利用率是70%,还是已经达到95%濒临瓶颈。通常,我们需要保留一定的余量以应对流量波动。 |
2. 性能设计:构建高速系统的“工具箱”
性能不是凭空产生的,而是通过一系列精心的设计实现的。下面我们来探讨几个核心的设计思想。
2.1 并发 vs. 并行:多任务处理的两种模式
专业性描述:并发指系统有能力同时处理多个任务。这些任务在一段时间内是交替执行的,从微观上看,在单个 CPU 核心上同一时刻只执行一个任务,但由于切换速度极快,宏观上感觉是“同时进行”。它主要解决阻塞等待问题,最大化利用CPU 时间。并行指系统真正同时执行多个任务。这要求有多个计算单元(如多核CPU、多台机器),每个单元在同一时刻各自执行一个独立的任务。它主要解决计算密集型问题,缩短整体任务完成时间。
大白话类比:并发就像一个服务员同时照看多桌客人。服务员在A桌点完单后,马上到B桌上菜,再到C桌结账。从宏观上看,他“同时”服务着多桌客人,但微观上他在某一时刻只为一桌服务。并行则是多个服务员同时工作,每个服务员独立负责一桌或几桌客人,真正同时提供服务。
“易购网”示例:处理用户下单请求是一个并发过程,Web服务器利用多线程技术,一个线程处理用户A的下单请求(等待数据库响应时),CPU会切换到另一个线程处理用户B的查询请求。而生成推荐商品列表时,需要计算海量商品之间的相似度,这是一个并行过程,我们会将这个大型计算任务拆分,分发到多个计算核心上同时运算,最后汇总结果。
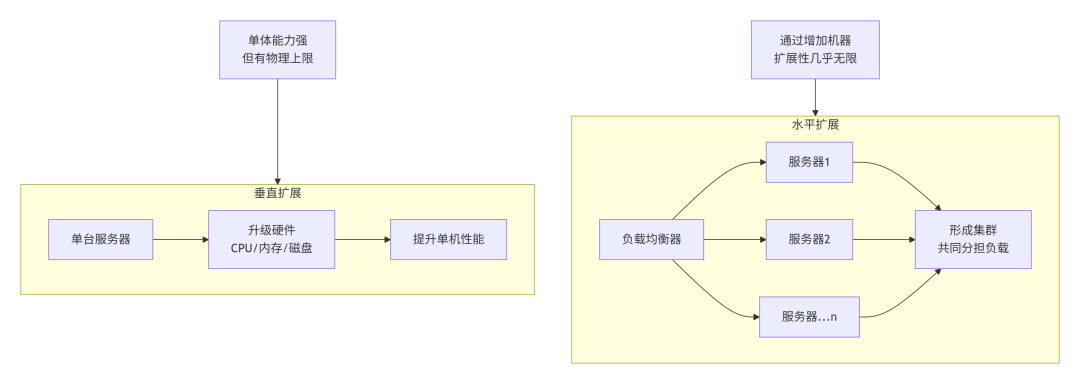
2.2 水平扩展 vs. 垂直扩展:提升系统能力的两种路径
专业性描述:垂直扩展指通过提升单个服务器节点的硬件能力来增强系统性能,如增加CPU核数、加大内存、使用更快的SSD硬盘。水平扩展指通过增加服务器节点的数量,并将它们组织成一个集群,共同分担负载,来增强系统性能。
大白话类比:垂直扩展是给一家小店进行豪华装修、扩容,比如把小卖部升级成大型超市,提升单店的接待能力和商品种类。但这家店再大,也有物理上限。水平扩展则是多开连锁分店,在不同区域开设多家门店,共同服务全市的顾客。哪个区域顾客多,就在那里多开分店。
“易购网”示例:在平台初期,流量不大,我们采用垂直扩展,给唯一的应用服务器升级到更高配置。但当“双十一”流量暴涨时,单台服务器的扩展上限和成本都成为问题。于是我们转向水平扩展,部署十几台甚至上百台应用服务器组成集群,前面用负载均衡器(如 Nginx)将用户请求分发给集群中相对空闲的服务器进行处理。这样,系统能力几乎可以无限增长。
下图清晰地对比了水平扩展与垂直扩展两种策略的核心区别与特点。
2.3 异步:不让等待拖慢整个系统
专业性描述:核心思想是将耗时的、非立即依赖结果的操作“后置”处理,使主流程不必等待其完成即可继续执行,从而快速释放系统资源去处理其他请求。
大白话类比:在餐厅点餐,同步方式是:服务员等你点完菜,然后站在厨房门口直到菜做好,再给你端上来,期间他不能服务其他桌。异步方式是:服务员记下你的菜单后,交给后厨,然后立即去服务其他客人。后厨做好菜后,再由传菜员端给你。服务员的效率大大提高。
“易购网”示例:用户下单后,需要发送订单确认邮件和短信。如果采用同步方式,程序必须等待邮件和短信都发送成功后才能给用户返回“下单成功”的提示,这会导致用户等待时间很长。我们采用异步处理:主程序生成订单后,立即响应成功,同时将“发送通知”这个任务放入一个消息队列(如Kafka或RocketMQ)中。后置的专门处理通知的服务从队列里取出任务,慢慢处理。即使发送短信的第三方服务暂时不稳定,也不会影响用户下单的主流程。
2.4 池化思想:资源的“共享经济”
专业性描述:核心思想是预先创建并维护一组可重用的资源实例(形成一个“资源池”),当业务需要时,直接从池中获取(借用)一个已存在的实例,使用完毕后将其归还给池,而不是销毁。通过这种复用机制,避免了资源频繁创建、初始化和销毁的昂贵开销。
大白话类比:出租车候客区就是一个池子。出租车(资源)提前在候客区排队,乘客(业务)来了直接上车,到达目的地后下车(资源归还),出租车可以继续去接其他乘客。这比每次乘客都要打电话叫车(创建资源),下车后出租车就报废(销毁资源)要高效、经济得多。
“易购网”示例:数据库连接是昂贵资源。每次查询都新建一个连接,操作完就关闭,会耗费大量时间在建立网络连接和数据库权限验证上。我们使用数据库连接池(如HikariCP),在系统启动时就创建一定数量的数据库连接放在池中。当需要执行SQL时,从池中获取一个空闲连接,用完后再归还。这极大地提升了数据库操作的效率。
2.5 缓存:把“常用工具”放在手边
专业性描述:核心思想是将一部分可能会被再次访问的数据,存储在一个访问速度更快的介质(通常是内存)中,当后续请求需要这些数据时,可以直接从这个快速介质中获取,从而避免访问速度较慢的数据源头(如数据库、远程接口、磁盘文件),以此来减少系统延迟、提升吞吐量。
大白话类比:你的办公桌抽屉就是缓存。你把最常用的笔、本子放在抽屉里,需要时伸手可得,而不必每次都跑去遥远的仓库(数据库)里取。
“易购网”示例:商品的名称、价格、图片等基础信息变动不频繁,但被访问量巨大。如果每次查看商品详情都查询数据库,数据库压力会非常大。我们在多个层次建立缓存:
- 应用层缓存:使用
Redis 等分布式缓存,将热点商品数据存放在内存中,应用服务器直接读取Redis,速度极快。
- CDN缓存:将商品图片、静态网页等资源分发到全球各地的CDN节点上,用户可以从离自己最近的节点加载,极大提升加载速度。
- 浏览器缓存:用户的浏览器也会缓存静态资源,再次访问时无需重复下载。
2.6 更多关键设计策略
2.6.1 动静分离:给“不变”和“常变”的内容分家
将静态资源(如CSS, JS, 图片)与动态内容(如用户信息)分离,并使用不同服务器或CDN处理,大幅提升效率。
2.6.2 读写分离:数据库的“分工合作”
设置主数据库处理写操作(如下单、支付),多个从数据库同步主库数据并处理读操作(如商品浏览、搜索),提升读并发能力。
2.6.3 批量处理:化零为整,减少开销
将多个零散的数据库写操作合并成一个批量操作提交,显著减少网络和磁盘I/O开销,提升吞吐量。
2.6.4 预计算:提前算好,随用随取
将实时计算量大的任务(如商品排行榜)提前算好,请求来时直接返回结果,用空间换时间。
3. 记忆与实战技巧
核心口诀:
性能核心三指标,响应吞吐资源耗。
扩展之路有两条,水平扩展是王道。
异步池化缓存术,并发并行要记牢。
动静分离减压力,读写分离提效率。
4. 实战技巧
数据驱动,瓶颈优先:性能优化不是猜谜语。务必使用监控工具(APM)找出系统的真正瓶颈(是CPU、数据库IO还是网络?),然后针对性地优化,避免盲目优化。
权衡的艺术:性能设计往往是一种权衡(Trade-off)。引入缓存会带来数据一致性问题;异步处理增加了系统复杂性;反规范化设计牺牲了数据规范性。架构师需要根据业务场景做出最适合的决策。
迭代优化:性能优化是一个持续的过程,而非一蹴而就。随着业务量的增长,需要不断地测量、分析、调整和验证。如果你对更多的系统架构和性能设计思路感兴趣,欢迎来云栈社区的技术版块一起深入探讨。
 发表于 2026-2-9 07:24:20
|
查看: 203|
回复: 0
发表于 2026-2-9 07:24:20
|
查看: 203|
回复: 0
