背景介绍
在实际生产环境中,许多团队的 Harbor 镜像仓库最初可能以单节点、本地磁盘存储的方式部署。这种架构虽然简单,但随着业务增长,单点故障的风险和巨大的本地 IO 压力逐渐凸显。为了追求更高的可用性和整体性能,将 Harbor 服务迁移至高可用架构势在必行。本文基于一次真实的 Harbor 运维服务迁移案例,详细梳理了从单节点到高可用集群的迁移全过程,并分享了在引入 COS 对象存储等组件时遇到的各种典型问题及其解决方案,希望能为面临类似挑战的开发者提供切实可行的参考。
架构演进
本次迁移的核心目标是解决单点故障和性能瓶颈。让我们先通过架构图直观地理解其变化。
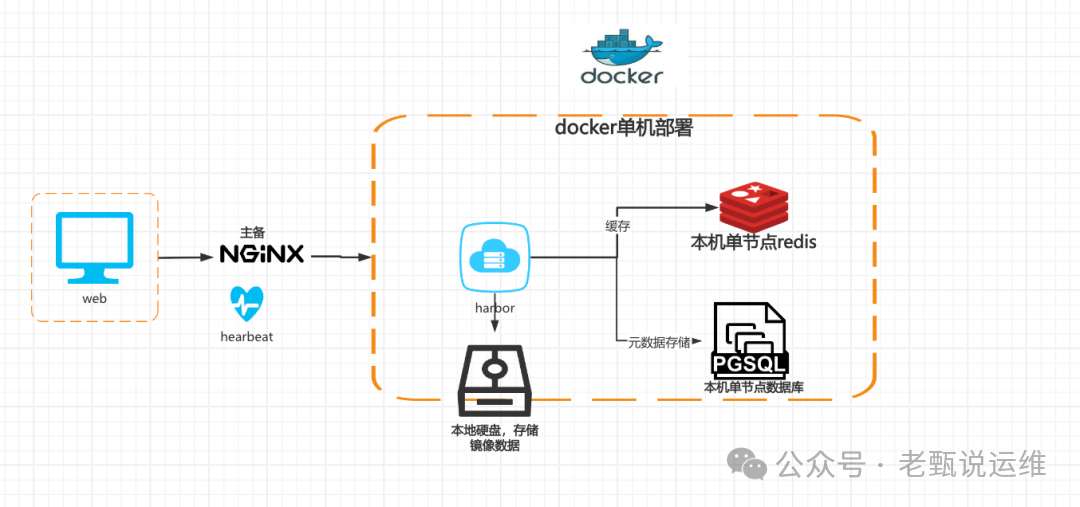
现有架构(改造前):
这是一个典型的 Docker 单机部署模型。Web 客户端请求经过 NGINX(配置了主备心跳)进入单 Harbor 服务。Harbor 的镜像数据存储在本地硬盘,而元数据则依赖于同一主机上的单节点 Redis 和 PGSQL 数据库。整个系统存在明显的单点风险。
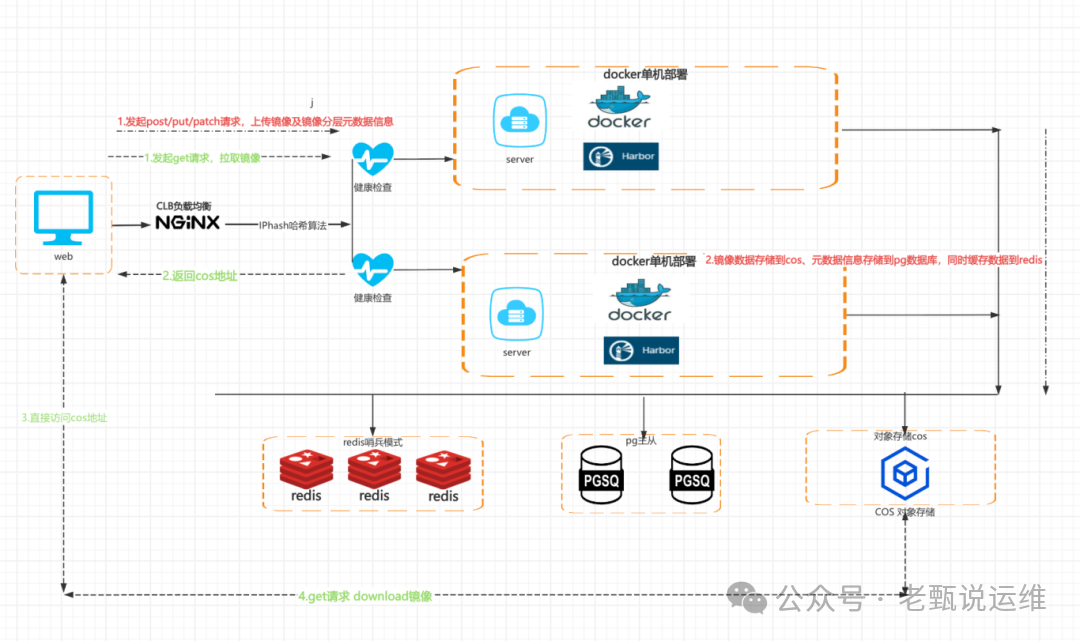
改造后架构(目标):
新架构围绕高可用和存储分离进行设计。前端通过 CLB(负载均衡器)进行流量分发,后端部署两个独立的 Harbor 服务实例,形成双节点。核心变化在于:
- 数据存储:镜像数据从本地硬盘迁移至 COS 对象存储。
- 缓存与数据库:Redis 采用哨兵集群模式,PGSQL 采用主从或高可用集群。
- 流量路径:客户端上传/下载镜像时,Harbor 服务端可返回 COS 地址,让客户端直连 COS,极大减轻服务器压力。
迁移过程
1. pg数据导出
迁移的第一步是确保元数据的安全转移。我们需要从旧的 Harbor 服务器(假设为服务器A)中导出 PostgreSQL 数据库。
登陆到旧的 Harbor 服务器,执行以下命令导出核心的 registry 数据库。使用 --no-owner 参数可以避免在新环境恢复时因用户角色不存在而报错。
docker exec -it harbor-db pg_dump -U postgres -d registry -F c --no-owner -f /tmp/registry_full_noowner.dump
2. 镜像数据拷贝
镜像仓库文件(通常位于 /data/registry 等目录)的体积往往很大。如果使用 Harbor 内置的镜像复制功能进行同步,速度可能较慢。实践表明,使用 mc (MinIO Client) 或 COS SDK 等工具直接同步到对象存储,效率要高得多。
对比测试:
- 使用 Harbor 镜像复制功能:同步约 2GB 镜像数据到 COS,耗时约 4分20秒。

- 使用
mc 工具直接同步:同步同样大小的数据,耗时仅约18秒。
time mc cp --recursive /root/docker qc__harbor-test/cos-tmp-125o99091/registry/
执行结果:
real 0m18.742s
user 0m7.263s
sys 0m5.976s
3. pg数据恢复
将上一步导出的数据文件拷贝到新的 数据库 环境。在恢复前,请确保目标数据库(registry)已创建且为空。
注意:如果恢复到空数据库,不应使用 -c (clean) 参数,否则会先尝试删除可能不存在的表导致报错。
以下是在新的 PGSQL 主节点上执行数据恢复的命令。我们使用 --no-owner --no-privileges 来规避用户和权限问题。
# 假设已登录到新的PG主服务器,并切换到了相应用户
./bin/pg_restore -h 127.0.0.1 -U harbor_rw -d registry --no-owner --no-privileges -W -v /tmp/registry_full_noowner.dump
4. harbor升级与服务部署
在本案例中,迁移伴随着 Harbor 版本的升级(v2.3.1 -> v2.14.1)。高可用架构下的多台 Harbor 节点,只需对其中一台执行完整的版本升级和数据迁移操作,另一台直接用新版本安装即可。
操作步骤(在服务器A上执行):
-
下载新版本安装包并解压:
wget https://github.com/goharbor/harbor/releases/download/v2.14.1/harbor-offline-installer-v2.14.1.tgz
tar -zxvf harbor-offline-installer-v2.14.1.tgz
-
准备配置文件:
-
执行数据库迁移:
docker run -it --rm -v /root/harbor_v2.14.1:/hostfs goharbor/prepare:v2.14.1 migrate -i harbor.yml
-
修改配置文件并安装:
- 根据新架构,在
harbor.yml 中配置 Redis 哨兵地址、外部数据库地址、COS存储等,并注释掉旧的本地数据库配置。
- 执行安装脚本:
./install.sh
-
验证迁移:
观察 harbor-core 容器的日志,当看到如下关键日志时,说明数据库表结构升级和数据迁移成功完成。
2026-02-04T04:01:28Z [INFO] [/core/main.go:209]: The database has been migrated successfully
问题汇总及解决方法
在迁移和后续使用过程中,我们遇到了几个颇具代表性的问题。
问题1:推送镜像失败,报错“413 Request Entity Too Large”
现象:推送较大镜像时,负载均衡器(LB)返回 413 错误。
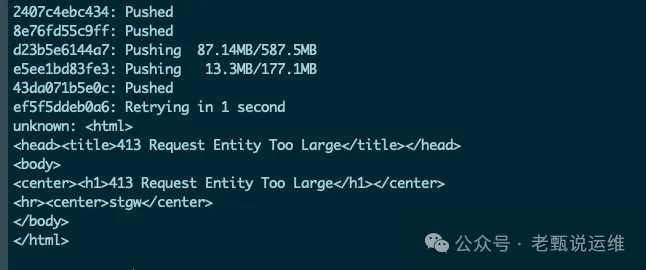
解决方法:
此问题源于 LB(如 Nginx)的默认请求体大小限制。需要在 LB 的配置中添加或调整以下参数:
client_header_timeout 120s;
client_header_buffer_size 32k;
client_body_timeout 120s;
client_max_body_size 10240M; # 根据实际需要调整
proxy_request_buffering off;
keepalive_timeout 75s;
proxy_connect_timeout 10s;
proxy_read_timeout 300s;
proxy_send_timeout 300s;
问题2:推送镜像返回“500 Internal Server Error”
现象:镜像推送过程中,部分 layer 上传成功,但最终报 500 错误。
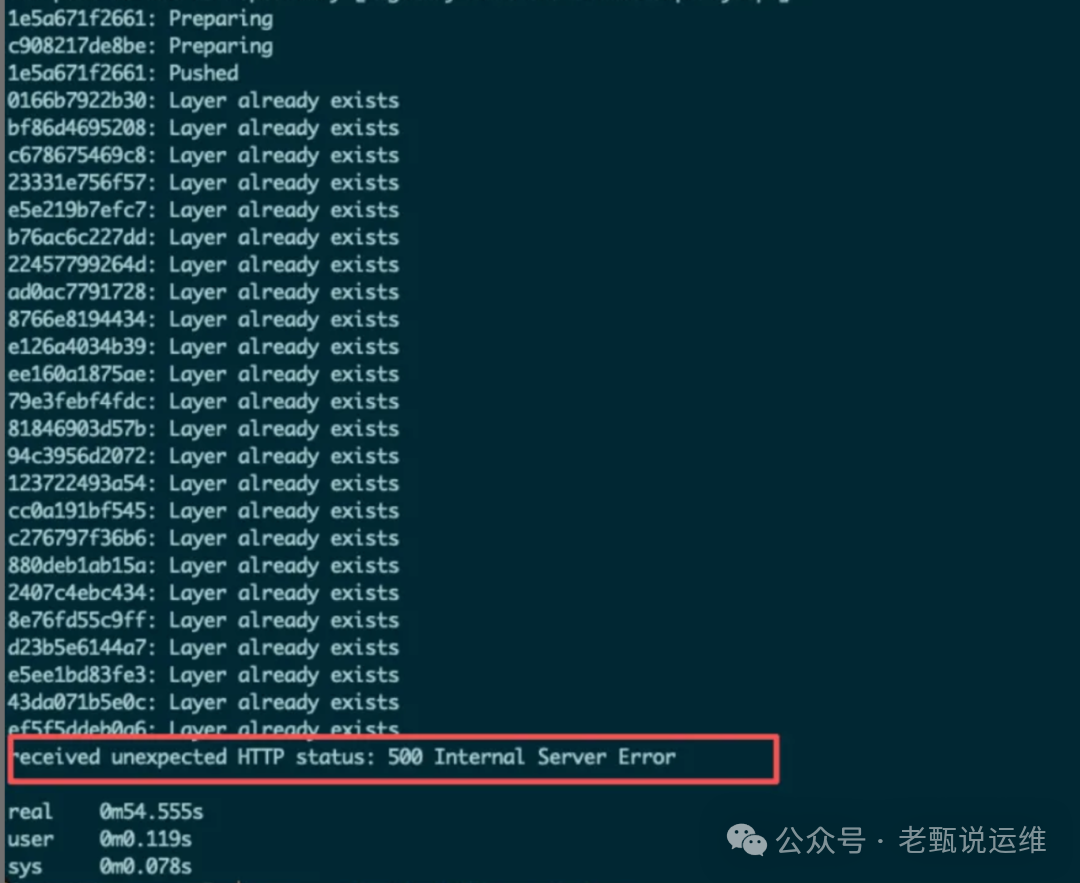
解决方法:
这个问题与 对象存储 COS 的一致性模型有关。Harbor 要求存储后端提供强一致性读,而某些 COS 存储桶默认可能未开启此功能,导致 Harbor 读取刚写入的数据时出现不一致,从而触发内部错误。
解决步骤:联系腾讯云技术支持,为你的 COS 存储桶开启强一致性功能。开启后问题即可解决。
问题3:COS S3协议配置格式错误
现象:Harbor 无法正确解析或访问 COS。
错误配置示例:
regionendpoint: https://桶名.cos.ap-beijing.myqcloud.com # 错误,将桶名放在了 endpoint 中
正确配置示例:
s3:
region: ap-beijing
bucket: your-bucket-name # 桶名单独配置在此处
regionendpoint: https://cos.ap-beijing.myqcloud.com # endpoint 不包含桶名
rootdirectory: registry
forcepathstyle: false
v4auth: true
secure: true
encrypt: false
问题4:下载镜像产生外网流量
现象:监控发现,从 Harbor 拉取镜像时,产生了大量的 COS 外网下行流量。
原因分析:
Harbor 配置为 COS 存储后,默认会开启“重定向”功能。当客户端拉取镜像时,Harbor 服务端会直接将 COS 文件的临时下载地址返回给客户端,客户端随后直连 COS 进行下载。如果客户端与 COS 不在同一内网,或者 COS SDK 未正确解析内网域名,就会走公网流量。
解决方案:
- 推荐方案(全网劫持):在内部 DNS 或 hosts 文件中,将 COS 的公网域名(如
*.cos.ap-beijing.myqcloud.com)解析到对应的内网 IP 或内网域名。这样客户端直连 COS 时也会走内网,既能减轻 Harbor 服务器压力,又能节省流量费用。
- 备用方案(关闭重定向):在 Harbor 的
harbor.yml 配置中关闭存储重定向功能。这样所有镜像流量都会经过 Harbor 服务器代理。虽然能确保走内网,但会将下载压力集中到 Harbor 服务器上。
storage_service:
s3:
... # 其他s3配置
redirect:
disable: true # 关闭重定向
结尾彩蛋
你知道 Kubernetes Deployment 在进行滚动更新时,默认的副本批量更新的比例是多少吗?
Kubernetes Deployment 在进行滚动更新(RollingUpdate)时,默认的副本更新比例是由两个核心参数控制的:maxSurge 和 maxUnavailable。
在不进行手动配置的情况下,它们的默认值都是 25%。
1. 核心参数解析
maxSurge (最大增量):
定义:在更新过程中,允许并发创建的 Pod 数量超过期望副本数的最大比例或绝对值。
默认值:25%。
效果:如果你有 10 个副本,更新时最多会跑 13 个 Pod(10 + 10*25% 后向上取整)。
maxUnavailable (最大不可用量):
定义:在更新过程中,允许处于不可用状态的 Pod 数量占期望副本数的最大比例或绝对值。
默认值:25%。
效果:如果你有 10 个副本,更新时最少要保证有 8 个 Pod 是正常运行的(10 - 10*25% 后向下取整)。
希望这篇结合了架构演进、详细步骤和“踩坑”经验的实战记录,能帮助你更顺利地完成自己的 Harbor 高可用之旅。如果你有更多关于云原生技术实践的见解或问题,欢迎在云栈社区与大家交流探讨。
 发表于 2026-2-9 06:59:16
|
查看: 187|
回复: 0
发表于 2026-2-9 06:59:16
|
查看: 187|
回复: 0
