LuxTTS 是一款基于 ZipVoice 研发的轻量级文本转语音模型,支持快速高质量的语音克隆和生成。它采用 48kHz 的高保真声码器,在保证语音清晰自然的同时,推理速度能达到实时超过 150 倍。模型整体高效,仅需 1GB 显存即可运行,非常适合本地部署。
想快速搭建一个属于自己的文本转语音接口吗?借助轻量级的 LuxTTS 模型和高效的 FastAPI 框架,你可以轻松实现。本文将一步步教你如何完成环境搭建、功能集成与接口部署。
环境准备
首先,我们需要准备好项目运行所需的 Python 环境和相关依赖。
1. 下载 LuxTTS 源码
从 GitHub 克隆项目仓库:
git clone https://github.com/ysharma3501/LuxTTS.git
2. 创建并激活虚拟环境
建议使用 Python 3.10 版本。LuxTTS 依赖了特定版本的 llvmlite,高版本 Python 可能导致安装失败。使用 uv 工具或 venv 创建虚拟环境:
uv venv --python 3.10 --seed
激活虚拟环境(Windows):
.venv\Scripts\activate
3. 安装项目依赖
进入项目目录,安装所需的包:
pip install -r requirements.txt
pip install fastapi uvicorn
构建文本转语音服务
环境就绪后,我们就可以开始编写核心功能了。
1. 准备音色样本
为了让模型克隆不同的声音,你需要准备多个音色样本文件(如男声、女声等),并将其放入项目下的 voices 目录中。文件格式支持 wav 或 mp3。
2. 编写文本转语音核心函数
创建一个 tts.py 文件,用于封装 LuxTTS 的调用逻辑。
import datetime
import os
import uuid
import soundfile as sf
from zipvoice.luxvoice import LuxTTS
# 初始化 LuxTTS 模型,指定使用 GPU 运行
lux_tts = LuxTTS('YatharthS/LuxTTS', device='cuda')
# 预编码音色样本
prompt_files = {
"girl": lux_tts.encode_prompt('voices/girl.wav', rms=0.01),
"boy": lux_tts.encode_prompt('voices/boy.wav', rms=0.01)
}
def do_text_to_speech(text: str, gender: str) -> str:
# 根据选择的性别获取对应的音色编码
encoded_prompt = prompt_files[gender]
# 生成语音
final_wav = lux_tts.generate_speech(text, encoded_prompt, num_steps=4)
# 保存语音文件
final_wav = final_wav.numpy().squeeze()
file_path = generate_file_path()
print("保存文件:", file_path)
# 将音频数据写入文件
sf.write(file_path, final_wav, 48000)
return file_path
def generate_file_path() -> str:
# 获取当前日期和时间
now = datetime.datetime.now()
date_str = now.strftime("%Y-%m-%d") # 格式化为 YYYY-MM-DD
time_str = now.strftime("%H%M%S") # 格式化为 HHMMSS
# 创建按日期组织的输出文件夹
output_dir = f"outputs/{date_str}"
os.makedirs(output_dir, exist_ok=True)
# 生成唯一文件名(时间戳+UUID短码)
file_name = f"{time_str}_{uuid.uuid4().hex[:8]}.wav"
file_path = os.path.join(output_dir, file_name)
return file_path
3. 构建 FastAPI 接口
接下来,我们使用 FastAPI 框架创建一个 Web API。新建 api.py 文件。
import tempfile
from fastapi import FastAPI, HTTPException
from fastapi.responses import FileResponse
from pydantic import BaseModel
from starlette.middleware.cors import CORSMiddleware
from tts import do_text_to_speech
app = FastAPI(title="Text-to-Speech API", description="A simple API for converting text to speech.")
# 配置允许跨域的中间件
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许所有来源,生产环境中建议指定具体的域名
allow_credentials=True,
allow_methods=["*"], # 允许所有HTTP方法
allow_headers=["*"], # 允许所有请求头
)
# 定义请求参数的 Pydantic 模型
class TextToSpeechRequest(BaseModel):
text: str # 要转换的文本内容
gender: str # 声音性别 ("girl" 或 "boy")
@app.post("/text-to-speech/")
async def text_to_speech(request: TextToSpeechRequest):
"""
将文本转换为语音并返回音频文件。
参数:
- request: 包含文本和性别的请求对象
返回:
- 音频文件 (WAV 格式)
"""
# 检查性别参数是否合法
if request.gender not in ["girl", "boy"]:
raise HTTPException(status_code=400, detail="Invalid gender. Must be 'girl' or 'boy'.")
try:
tmp_file = do_text_to_speech(text=request.text, gender=request.gender)
# 返回生成的音频文件
return FileResponse(
path=tmp_file,
media_type="audio/wav",
filename="output.wav"
)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error generating speech: {str(e)}")
运行与测试
所有代码编写完成后,就可以启动服务并进行测试了。
1. 启动 FastAPI 服务
在项目根目录下执行命令:
uvicorn api:app --reload
--reload 参数会在代码修改后自动重启服务,方便调试。
2. 访问 API 文档
服务启动后,打开浏览器,输入 http://localhost:8000/docs。你将看到 FastAPI 自动生成的交互式 API 文档页面。
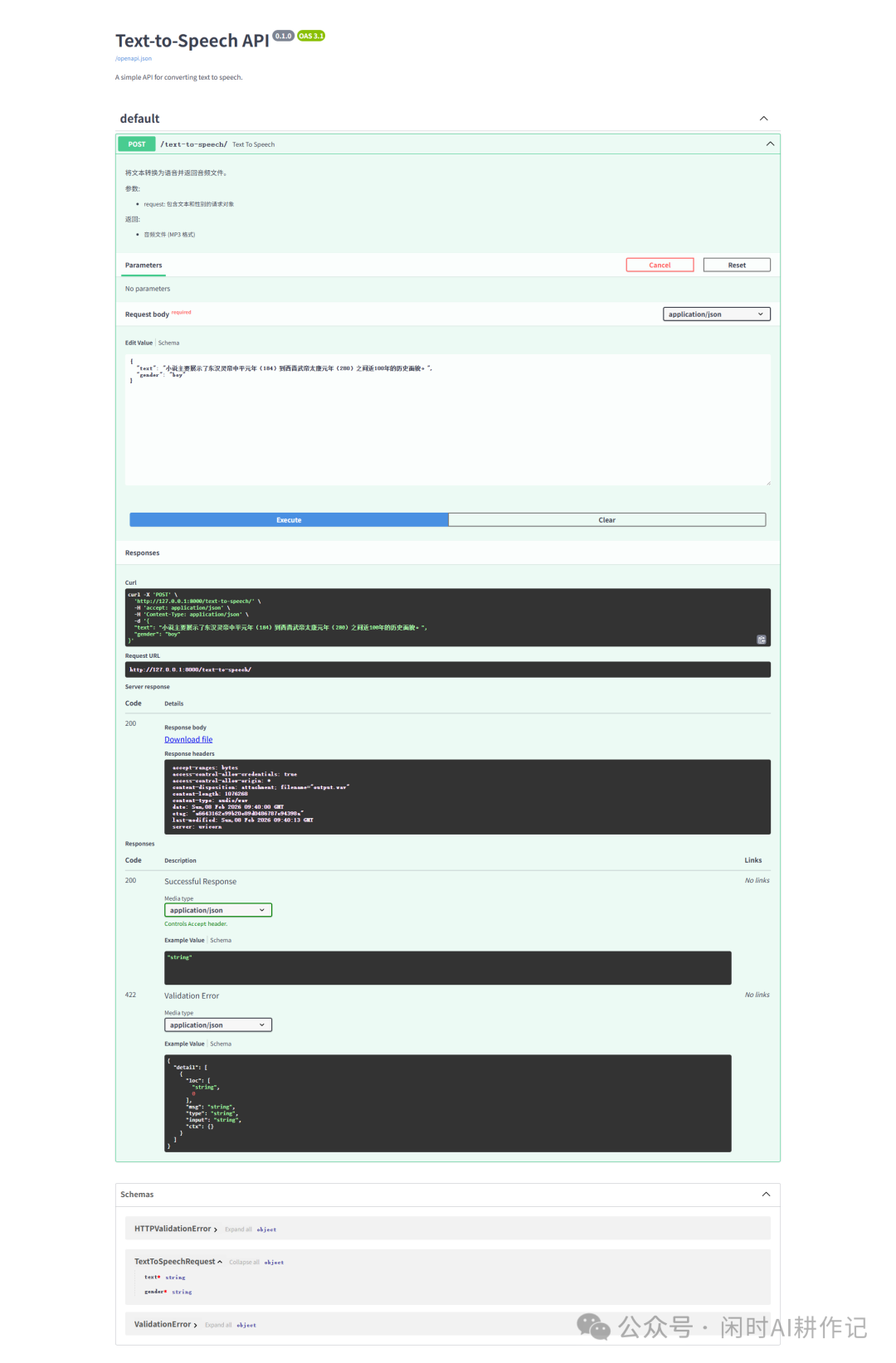
3. 测试接口功能
在文档页面中,找到 POST /text-to-speech/ 接口,点击 “Try it out”。在请求体(Request body)中编辑 JSON 数据,填入你想要转换的文本和音色类型(“girl” 或 “boy”),然后点击 “Execute”。如果一切正常,服务器将生成并返回一个 WAV 格式的音频文件,浏览器会自动下载它。
总结
通过以上步骤,我们成功地将一个先进的 人工智能 语音合成模型 LuxTTS 封装成了易于调用的 Web API 服务。整个过程清晰展示了从环境配置、核心功能开发到 开源实战 项目集成的完整路径。
你可以在此基础上进一步扩展,例如增加更多音色选项、优化音频输出格式、添加身份验证或将其部署到云服务器上。这种模式不仅适用于 TTS 应用,也为其他 AI 模型的快速服务化提供了很好的参考。如果你在实践过程中有更多想法或问题,欢迎在 云栈社区 与大家交流讨论。
 发表于 2026-2-9 07:22:09
|
查看: 755|
回复: 0
发表于 2026-2-9 07:22:09
|
查看: 755|
回复: 0
