上一篇文章介绍了Agent从0到1的实现过程,可能有些读者觉得内容较长。因此,这次我们聚焦于一个更核心的机制——Agent Loop。理解它,才能真正让大模型从“聊天机器人”变成“能解决问题的智能体”。
Agent Loop 是什么?
简单来说,Agent Loop = 调用模型 → 判断是否要用工具 → 执行工具 → 把结果回喂给模型 → 重复。
这个过程会持续进行,直到模型认为信息已经足够,可以输出最终的答案为止。正是这个循环,将大模型从一个强大的文本生成器,升级为一个能够自主完成任务的执行系统。
我们依然用之前那个可以执行Bash命令的最简单Agent作为例子,来看看它的核心代码结构:
import sys
import os
import traceback
from llm_factory import LLMFactory, LLMChatAdapter
from util.mylog import logger
from utils import run_bash, BASH_TOOLS
# 初始化 API 客户端
# 使用 LLMFactory 创建 LLM 实例
llm = LLMFactory.create(
model_type="openai",
model_name="deepseek-v3.2", # 使用支持的模型
temperature=0.0,
max_tokens=8192
)
client = LLMChatAdapter(llm)
# 系统提示词
SYSTEM = f"""你是一个位于 {os.getcwd()} 的 CLI 代理,系统为 {sys.platform}。使用 bash 命令解决问题。
## 规则:
- 优先使用工具而不是文字描述。先行动,后简要解释。
- 读取文件:cat, grep, find, rg, ls, head, tail
- 写入文件:echo '...' > file, sed -i, 或 cat << 'EOF' > file
- 避免危险操作,如 rm -rf等删除或者清理文件, 或格式化挂载点,或对系统文件进行写操作
## 要求
- 不使用其他工具,仅使用 bash 命令或者 shell 脚本
- 子代理可以通过生成 shell 代码执行
- 如果当前任务超过 bash 的处理范围,则终止不处理
"""
def extract_bash_commands(text):
"""从 LLM 响应中提取 bash 命令"""
import re
pattern = r'```bash\n(.*?)\n```'
matches = re.findall(pattern, text, re.DOTALL)
return [cmd.strip() for cmd in matches if cmd.strip()]
def chat(prompt, history=None, max_steps=10):
if history is None:
history = []
# 检查历史记录中是否已有系统提示词(作为系统消息)
has_system = any(msg.get("role") == "system" for msg in history)
if not has_system:
# 在开头添加系统提示词作为系统消息
history.insert(0, {"role": "system", "content": SYSTEM})
history.append({"role": "user", "content": prompt})
step = 0
while step < max_steps:
step += 1
# 1. 调用模型(传递 tools 参数)
# 使用 chat_with_tools 接口,支持 function calling
response = client.chat_with_tools(
prompt=prompt,
messages=history,
tools=BASH_TOOLS
)
if step == 1:
prompt = '继续'
# 2. 解析响应内容
assistant_text = []
tool_calls = []
logger.info(f"第 {step} 步响应: {response}")
# chat_with_tools 返回的是 Response 对象,包含 content 列表
for block in response.content:
if getattr(block, "type", "") == "text":
assistant_text.append(block.text)
elif getattr(block, "type", "") == "tool_use":
tool_calls.append(block)
# 记录助手文本回复
full_text = "\n".join(assistant_text)
if full_text:
logger.info(f"助手: {full_text}")
history.append({"role": "assistant", "content": full_text})
elif tool_calls:
# 如果只有工具调用没有文本,添加一个占位文本到历史,保持对话连贯
history.append({"role": "assistant", "content": "(Executing tools...)"})
# 3. 如果没有工具调用,直接返回内容
if not tool_calls:
logger.info(f"第 {step} 步结束,无工具调用")
if response.stop_reason == "end_turn":
return full_text
# 如果异常结束,也返回
return full_text or "(No response)"
# 4. 执行工具
logger.info(f"第 {step} 步工具调用: {tool_calls}")
all_outputs = []
for tc in tool_calls:
if tc.name == "bash":
cmd = tc.input.get("command")
if cmd:
logger.info(f"[使用工具] {cmd}") # 黄色显示命令
output = run_bash(cmd)
all_outputs.append(f"$ {cmd}\n{output}")
# 如果输出太长则截断打印
if len(output) > 200:
logger.info(f"输出: {output[:200]}... (已截断)")
else:
logger.info(f"输出: {output}")
else:
logger.warning(f"Unknown tool: {tc.name}")
# 5. 将命令执行结果添加到历史记录中
if all_outputs:
combined_output = "\n".join(all_outputs)
history.append({"role": "user", "content": f"执行结果:\n{combined_output}\n\n请继续处理。"})
else:
# 有工具调用但没产生输出(可能是解析失败或空命令)
history.append({"role": "user", "content": "Error: Tool call failed or produced no output."})
return "达到最大执行步数限制,停止执行。"
if __name__ == "__main__":
if len(sys.argv) > 1:
logger.info(chat(sys.argv[1]))
else:
# 交互模式
logger.info("Bash 代理已启动。输入 'exit' 退出。")
history = []
while True:
try:
user_input = input("> ")
if user_input.lower() in ['exit', 'quit']:
break
chat(user_input, history)
except KeyboardInterrupt:
logger.info("\n正在退出...")
break
except Exception as e:
logger.info(f"\n错误: {e}")
traceback.print_exc()
Agent Loop 怎么工作?(核心循环)
你可以把 Agent Loop 理解成一个递归或迭代的工作流,对应上面代码中的 while 循环。它的核心是不断将累积的历史数据和最新的执行结果信息作为上下文输入给大模型。
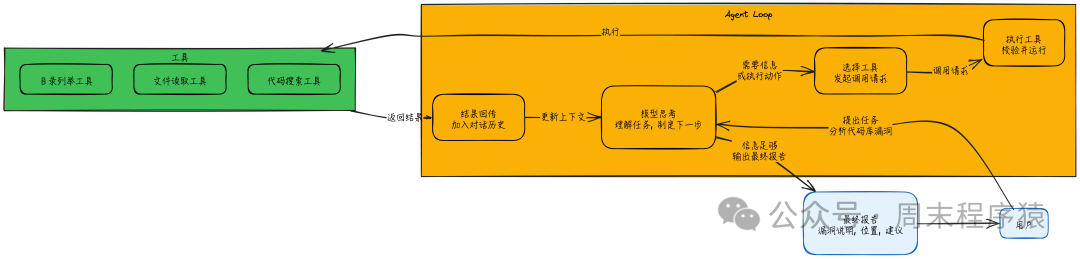
这个工作流通常包含以下几个关键步骤,如果你对如何撰写清晰的技术文档感兴趣,可以参考 技术文档 板块的实践:
- 模型思考:基于当前的对话历史和任务上下文,理解用户意图,并制定下一步行动计划;
- 选择工具:如果判断需要获取更多信息或执行某个动作,就发起一个结构化的工具调用请求;
- 执行工具:系统根据工具定义(schema)校验参数,并调用对应的函数或API执行实际操作;
- 结果回传:将工具执行的成功结果或失败信息,作为一条新的消息加入到对话历史中;
- 回到第 1 步,继续迭代,直到模型输出最终答案。
整个过程最核心的一点是:上下文会持续累积。模型不仅能看到用户最初提出的问题,还能看到自己之前调用过哪些工具、得到了哪些结果。这种“工作记忆”使得它能够完成复杂的多步推理与决策。
一个具体例子:扫描代码库安全漏洞
假设用户提出请求:“帮我分析这个代码库有没有安全漏洞。”
这显然不是一次问答就能解决的。通过 Agent Loop,整个过程会这样运行:
- 模型首先需要了解项目的整体结构 → 调用 目录列举工具
- 看到目录结构后,定位到主要的入口文件(如
main.py) → 调用 文件读取工具
- 在代码中发现有数据库查询操作 → 再去读取相关的数据库连接模块 → 再次调用 文件读取工具
- 识别出疑似 SQL 注入漏洞(例如用户输入被直接拼接进SQL语句) → 为了确认影响范围,调用 代码搜索工具 在全项目中查找该查询函数的调用点
- 工具返回发现12处调用 → 模型认为信息已收集足够 → 输出 最终分析报告(包含漏洞说明、具体位置、修复建议等)
每一轮迭代都遵循 “拿到新信息 → 决定继续行动还是结束输出” 的模式。而且,这些决策是模型基于当前所有上下文“自主”做出的,这体现了人工智能中智能体自主性的一个关键特征。
Agent Loop 里消息长什么样?(对话历史=工作记忆)
Agent Loop 主要维护一份“对话历史”,它就是模型的临时工作记忆。消息通常分为两类角色:
- user:不仅包含用户最初的输入,还包括后续的系统指令。在许多实现中,工具执行的结果也常常以“用户”或“系统”消息的形式注入到历史中,以模拟环境反馈。
- assistant:代表模型的输出,可能包含:
- 直接给用户的文本回答
- 工具调用请求(指明使用哪个工具,以及具体的参数)
- (部分高级模型支持)内部的推理痕迹(Chain-of-Thought)
随着循环进行,对话历史会越积越长。因此,通常需要设计“对话管理”策略来避免历史记录超出模型的上下文窗口限制,这也是实践中常见的一个挑战。
工具执行发生了什么?
当模型请求使用某个工具时,背后的执行系统一般会做这几件事:
- 校验参数:检查工具调用的格式和参数是否符合预定义的schema。一个典型的工具调用格式如下:
{
"type": "tool_use",
"id": "toolu_01A09q90qw90lq917835123",
"name": "my_function_name",
"input": {
"query": "Latest developments in quantum computing"
}
}
- 查找工具:在预先注册的工具列表中,根据
name 字段找到对应的可执行函数或API。
- 执行工具:以安全、可控的方式运行该工具,并做好异常和错误处理。
- 封装结果:将执行成功的结果或失败的错误信息,统一封装成一条“工具结果消息”,回传给模型。
这里有一个重要的设计原则:工具执行失败通常不会直接导致整个循环崩溃。系统会把错误信息返回给模型,让它有机会根据反馈调整策略,例如更换工具、修正参数或重试。
什么时候结束循环?(Stop Reasons)
每次调用大模型API,通常都会返回一个“停止原因”,这决定了 Loop 的下一步走向。常见的停止原因包括:
- end turn:模型认为自己已经完成了任务,可以正常结束并返回最终答案。
- tool use:模型请求使用一个或多个工具,需要执行工具后继续下一轮循环。
- max tokens:模型的输出达到了预设的token上限而被截断,这通常意味着当前轮次无法恢复,可能需要报错或拆分任务。
- stop sequence:模型的输出中遇到了预设的停止符(如
“<|endoftext|>”),按计划正常结束。
- content filtered / guardrail intervention:模型的输出触发了内容安全策略或护栏拦截,需要按照产品规则处理(如替换为安全提示)。
常见坑与解决思路
1)上下文窗口耗尽
循环次数多、工具返回的输出长,会迅速撑爆对话历史,导致输入长度超出模型限制,或模型因信息过载而表现变差。
应对方法:
- 让工具返回摘要或关键片段,而非完整的原始数据。
- 简化工具的描述schema,过于复杂的嵌套结构也会消耗大量token。
- 采用对话管理策略,如滑动窗口、总结压缩(将冗长的早期对话总结成简短描述)。
- 将大任务拆解为多个逻辑子任务,分段执行、分段总结。
2)模型老选错工具
通常是工具的功能描述不够清晰,或者多个工具的描述高度重叠,导致模型无法准确判断该用哪个。
应对方法:
- 为每个工具撰写清晰的“使用说明书”,明确其适用场景、输入输出格式和边界条件。
- 尽量避免多个工具在功能和描述上过于相似,可以合并或重新划分职责。
3)MaxTokensReached(输出太长)
这可能是最终答案本身太长,也可能是上下文历史占用了太多空间,导致留给模型生成答案的token配额不足。
应对方法:
- 如果可控,适当增加模型调用的
max_tokens 参数上限。
- 采用前述方法缩短上下文长度或工具输出。
- 通过任务拆分,确保每个子任务的输入输出都在可控范围内。
4)复杂的任务不要全部依赖大模型决策
可以参考这篇文章:https://mp.weixin.qq.com/s/Zhc-GDTJSQy69goSDRkfEQ ,它探讨了大模型为何不能总是准确地执行所有技能(对应工具调用),主要原因包括:
- 工具过多造成噪声:当工具列表很长时,大模型自主决策可能无法按照预设的最佳路径调用工具链。
- 缺乏明确决策点:大模型可能会选择“相似”的工具,但这个工具不一定是最佳或最高效的。
- 调用顺序不可控:大模型自主决策的调用顺序(A -> B -> C)可能不符合任务的最优逻辑或业务要求。
那该怎么做?
- 在系统提示词(
SYSTEM)或任务规则文件(如 rules.md)中,明确指出当前任务可能用到或必须使用哪些工具。
- 为复杂任务建议或规定大致的工具调用顺序。虽然这看起来增加了人为干预,但往往能更可靠、高效地解决问题。
参考
(1)https://strandsagents.com/latest/documentation/docs/user-guide/concepts/agents/agent-loop/
(2)https://mp.weixin.qq.com/s/Zhc-GDTJSQy69goSDRkfEQ
 发表于 2026-2-9 07:19:27
|
查看: 259|
回复: 0
发表于 2026-2-9 07:19:27
|
查看: 259|
回复: 0
