2026年2月5日,Anthropic公司正式发布了其最强大模型的全新版本——Claude Opus 4.6。该模型在前代基础上实现了多项关键能力的跃升,尤其是在编程和长程代理任务方面表现突出。
全新的 Claude Opus 4.6 大幅提升了编程能力。它在规划复杂任务时表现得更加谨慎,能够长时间自主地执行任务,在大型代码库中的运行稳定性显著增强。同时,它在代码审查和调试方面也变得更加强大,能够更好地发现并纠正自身产生的错误。
作为Opus系列模型的首次尝试,Opus 4.6在测试版中支持了高达100万token的上下文窗口,这为处理超长文档和复杂任务流提供了可能。
此外,Opus 4.6能够将这些增强的能力应用到各种日常工作中,例如进行财务分析、开展深入研究,以及更高效地使用和创建文档、表格和演示文稿。在 Cowork 这类协作环境中,Claude可以自主并行处理多项任务,Opus 4.6能够充分代表用户发挥这种多任务处理能力。
在多项权威评测中,该模型都达到了业界的先进水平:
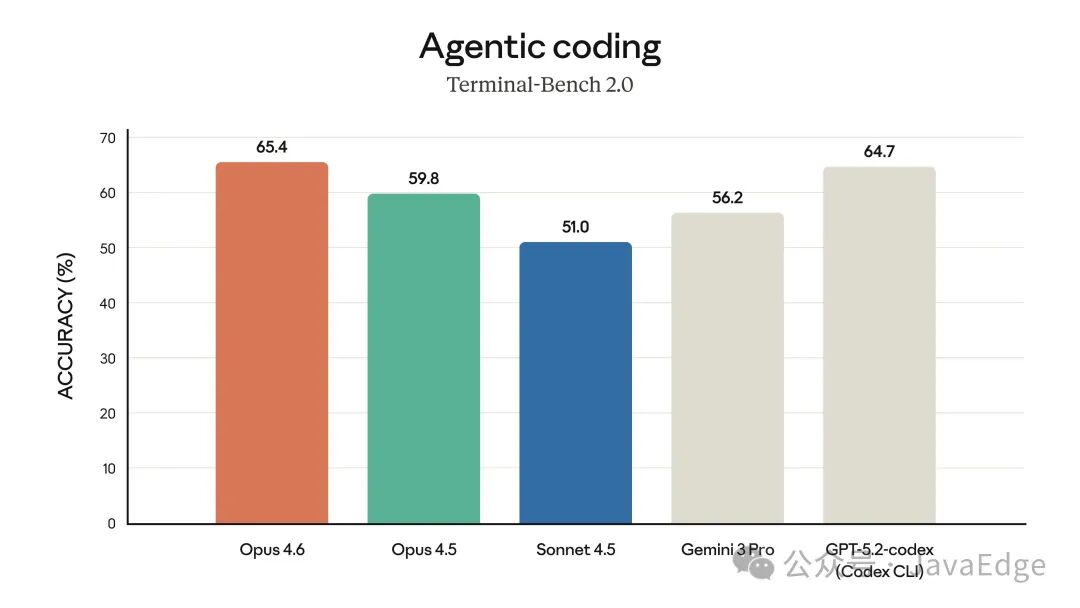
- 在衡量代理式编程能力的 Terminal-Bench 2.0 评测中,它取得了最高分。
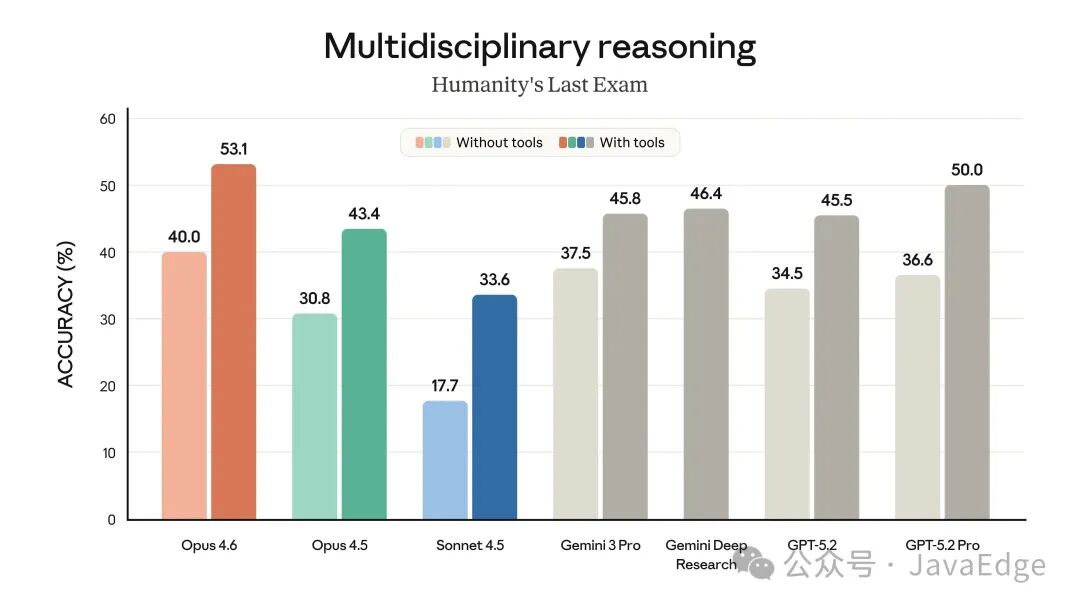
- 在复杂的多学科推理测试 Humanity’s Last Exam 中,其表现也领先于所有其他前沿模型。
- 在 GDPval-AA(一项评估模型在金融、法律等高经济价值知识工作中表现的评测)中,Opus 4.6比行业中表现第二好的模型(OpenAI的GPT-5.2)高出约144个Elo分,比自身的前代模型Claude Opus 4.5高出190分。
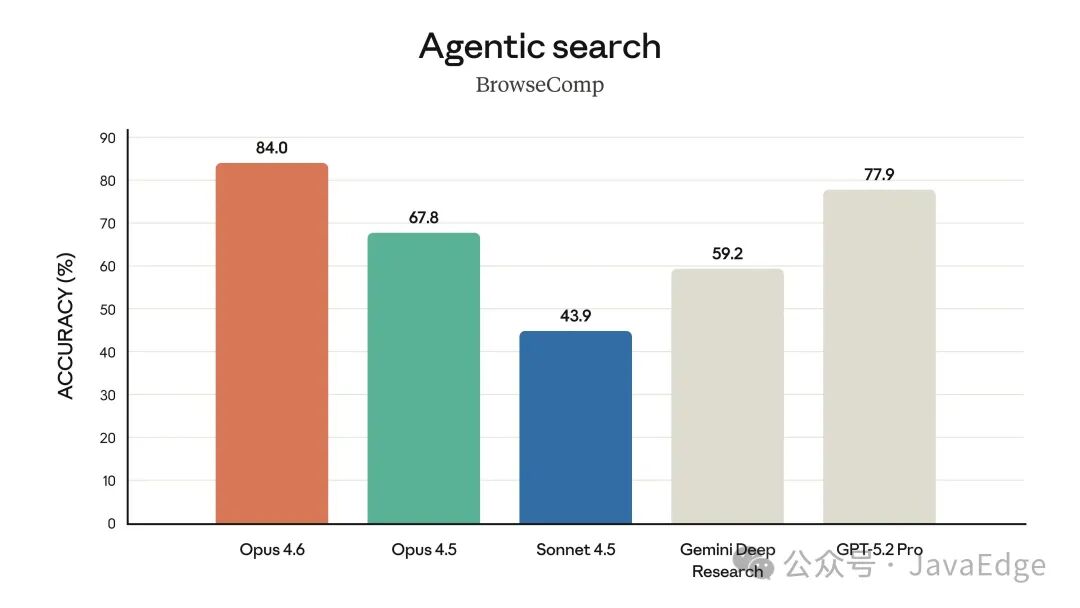
- 在衡量模型在线查找高难度信息能力的 BrowseComp 评测中,Opus 4.6同样优于其他所有模型。
根据官方发布的系统卡信息,Opus 4.6的整体安全性表现与行业中任何其他前沿模型相比都同样优秀,甚至更好。在多项安全评估中,其行为偏离的发生率都保持在较低水平。
核心能力评测展示
知识型工作(GDPval-AA Elo分数)
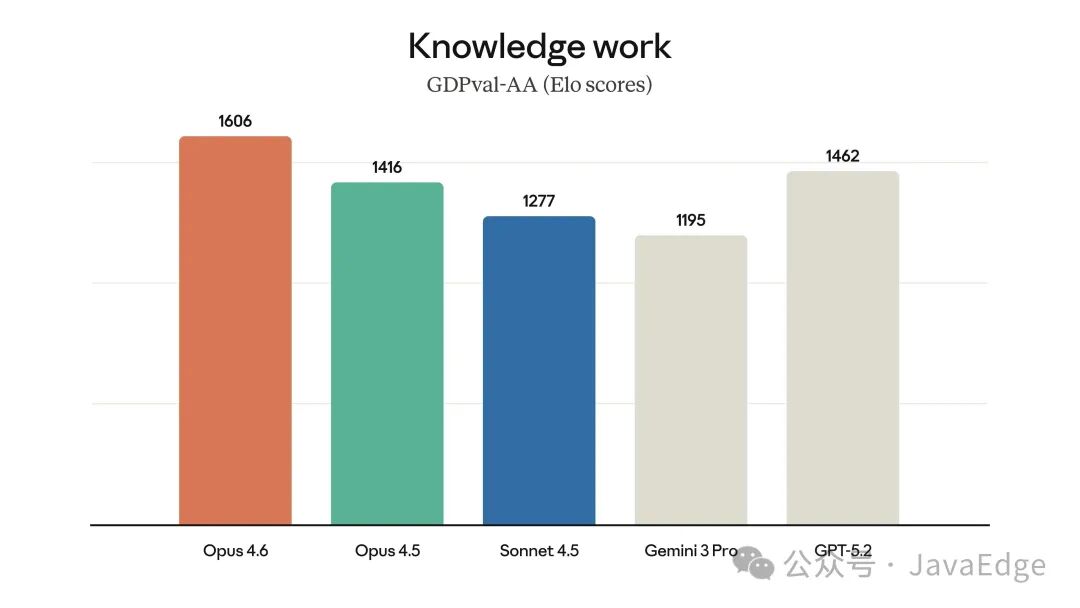
Opus 4.6在多个专业领域的真实工作任务中都达到了业界最先进水平。
代理式搜索(BrowseComp准确率)
编程(Terminal-Bench 2.0准确率)
多学科推理(Humanity‘s Last Exam)
在 Claude Code 中,用户现在可以组建 代理团队,让多个代理协同完成任务。在 API 层面,Claude 可以通过 上下文压缩 对自身上下文进行总结,从而在不触及限制的情况下执行更长时间的任务。同时,模型引入了 自适应思考 机制,可以根据上下文线索判断需要投入多少扩展思考能力。此外,新增的 effort 控制参数,让开发者在智能水平、响应速度和成本之间拥有更多的调节空间。
Anthropic还对 Claude in Excel 进行了大幅升级,并以研究预览形式发布了 Claude in PowerPoint,让 Claude 在日常办公场景中变得更加强大和实用。
Claude Opus 4.6 现已在 claude.ai、官方API以及所有主流云平台上线。对于开发者,可以通过 Claude API 使用模型标识符 claude-opus-4-6 进行调用,其定价保持不变。
早期体验反馈
用AI来打造AI,这是Anthropic工程师的日常。每一个新模型都会先在其内部开发工作中接受检验。对于Opus 4.6,开发团队发现它具备以下特点:
- 无需额外提示,就能自动将注意力集中在任务中最具挑战性的部分。
- 在相对简单的任务环节推进速度更快。
- 面对模糊或定义不清的问题时,判断更加稳健。
- 即使在长时间的对话会话中,依然能保持高效。
Opus 4.6往往会进行更深入、更谨慎的思考,在给出最终答案前会反复检查自己的推理过程。这使得它在解决复杂问题时能产出更好的结果,但在处理简单任务时可能会带来额外的计算成本和延迟。如果你发现模型在某些任务上“想得太多”,建议将默认的 high effort 级别调整为 medium,这可以通过 API 中的 /effort 参数进行控制。
以下是来自部分早期体验合作伙伴对 Claude Opus 4.6 的反馈:
Notion – Sarah Sachs, AI Lead
“能应对复杂请求,真正把事情做完:将任务拆解为具体步骤,逐一执行,并在任务目标宏大时依然产出完成度很高的成果。对 Notion 用户来说,它更像是一位得力的协作者,而不只是一个工具。”
GitHub – Mario Rodriguez, Chief Product Officer
“能胜任开发者每天面对的复杂、多步骤编程工作——尤其是在需要规划和工具调用的代理式工作流中表现突出。这开始解锁前沿层面的长周期任务能力。”
Replit – Michele Catasta, President
“Claude Opus 4.6 在代理式规划方面实现了巨大飞跃。它能将复杂任务拆分为相互独立的子任务,并行运行工具和子代理,还能非常精准地识别阻塞点。”
Asana – Amritansh Raghav, Interim CTO
“为我们的 AI Teammates 提供支持时,展现出了卓越的推理和规划能力。同时,它也是一款出色的编程模型——在大型代码库中定位并做出正确修改的能力。”
Cognition – Scott Wu, CEO
“复杂问题上的推理水平,能考虑到其他模型容易忽略的边界情况,并且持续给出更加优雅、周密的解决方案。在 Devin Review 中对 Opus 4.6 的表现尤为印象深刻,它显著提升了我们的漏洞发现率。”
Thomson Reuters – Joel Hron, Chief Technology Officer
“在长上下文性能上实现了实质性的飞跃。在我们的测试中,它能够以高度一致的表现处理规模大得多的信息,这让我们在设计和部署复杂研究工作流时更加有底气。”
详细评测结果
在代理式编程、计算机使用、工具调用、搜索以及金融分析等多个专业领域中,Opus 4.6 都展现出了行业领先的性能,且往往优势明显。下图综合对比了 Claude Opus 4.6 与之前版本以及其他行业主流模型在多项基准测试中的表现。
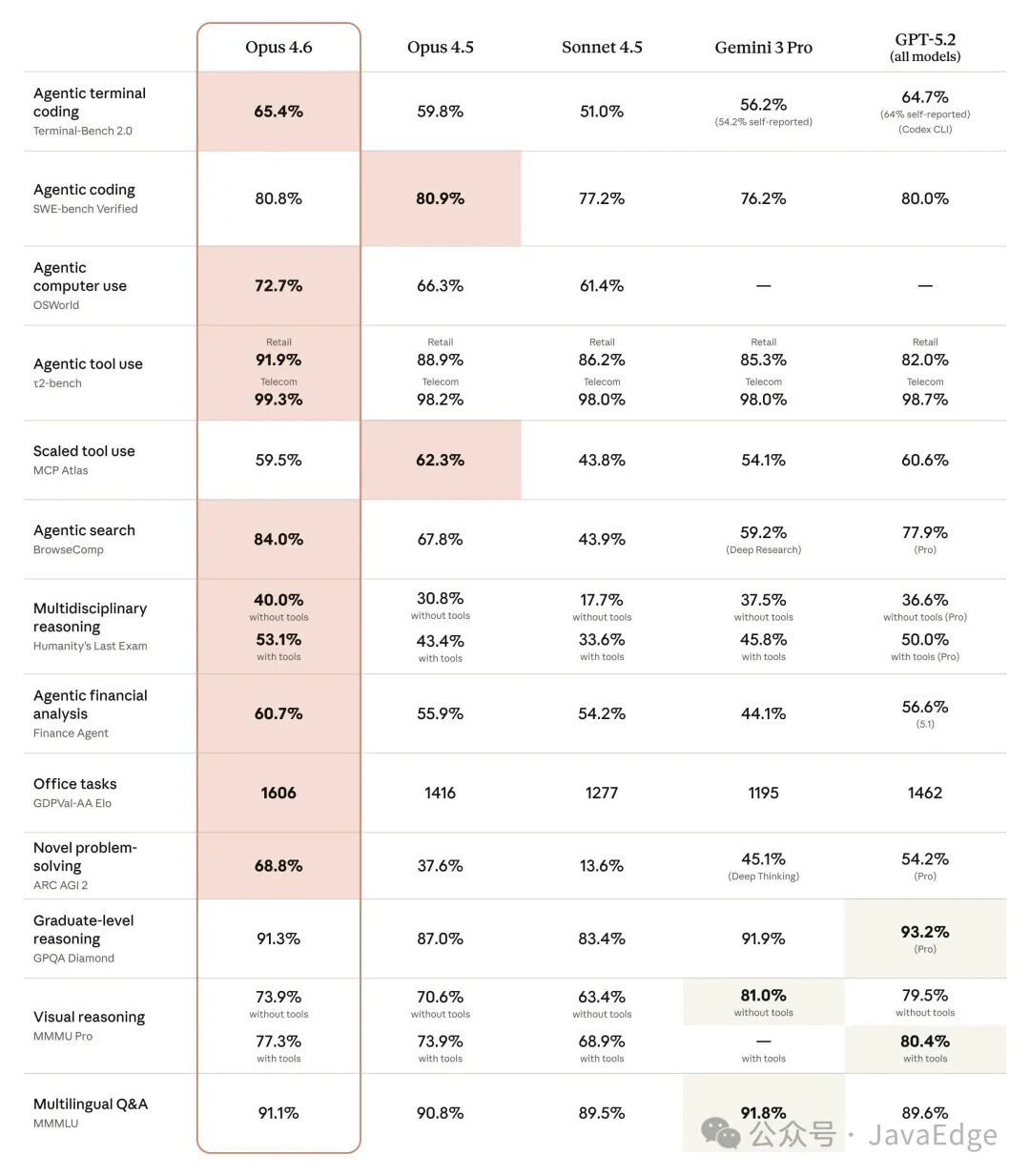
Opus 4.6 在从大型文档集合中检索关键信息方面表现出色。这一点在长上下文任务中尤为明显:它能够在几十万 token 的信息中保持更低的记忆偏移,更好地追踪细节,甚至能捕捉到连 Opus 4.5 都会遗漏的关键信息。
针对AI模型常见的“上下文腐化”问题(即随着对话token数增加,模型性能下降),Opus 4.6相较前代有了显著改进。在 MRCR v2 的 8-needle、100万token版本测试(用于评估模型在海量文本中定位“隐藏”信息的能力)中,Opus 4.6 的得分为 76%,而 Sonnet 4.5 仅为 18.5%。这代表着模型在真正利用超长上下文并保持高性能方面实现了质的飞跃。
长上下文检索(MRCR v2)
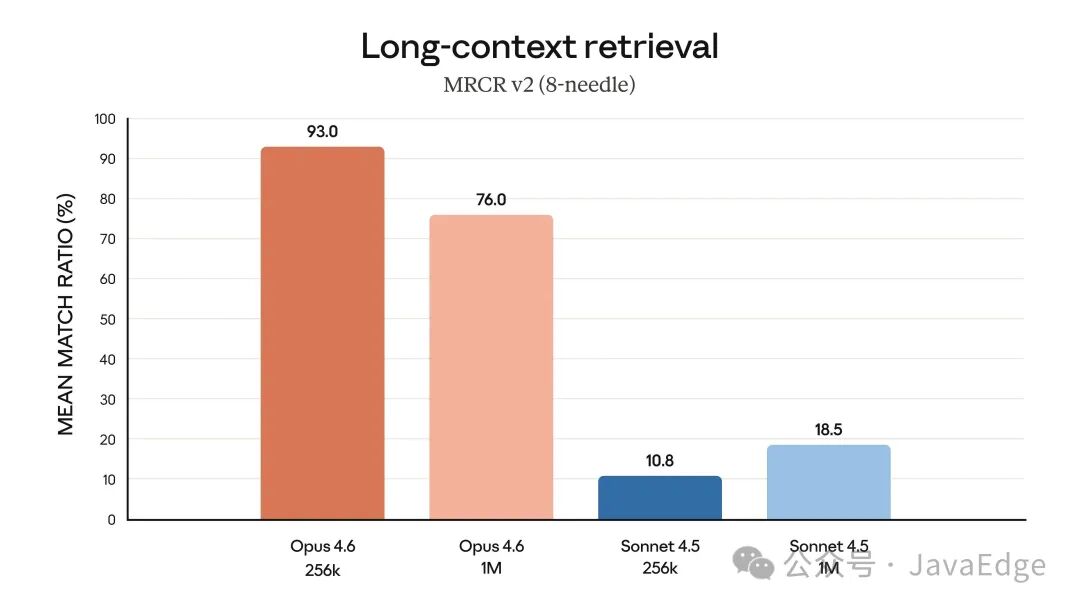
长上下文推理(Graphwalks)
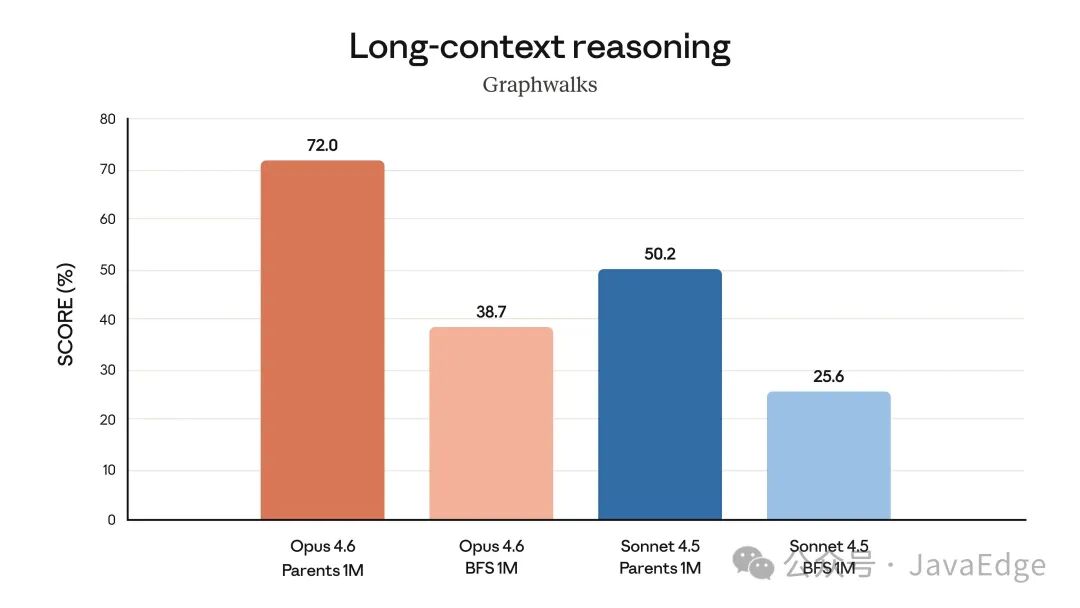
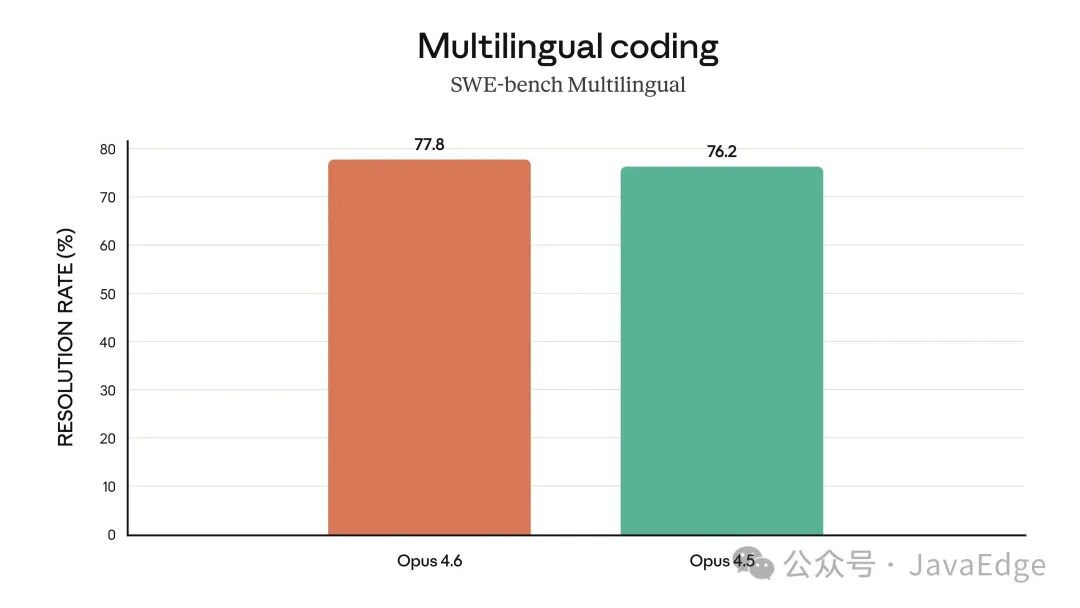
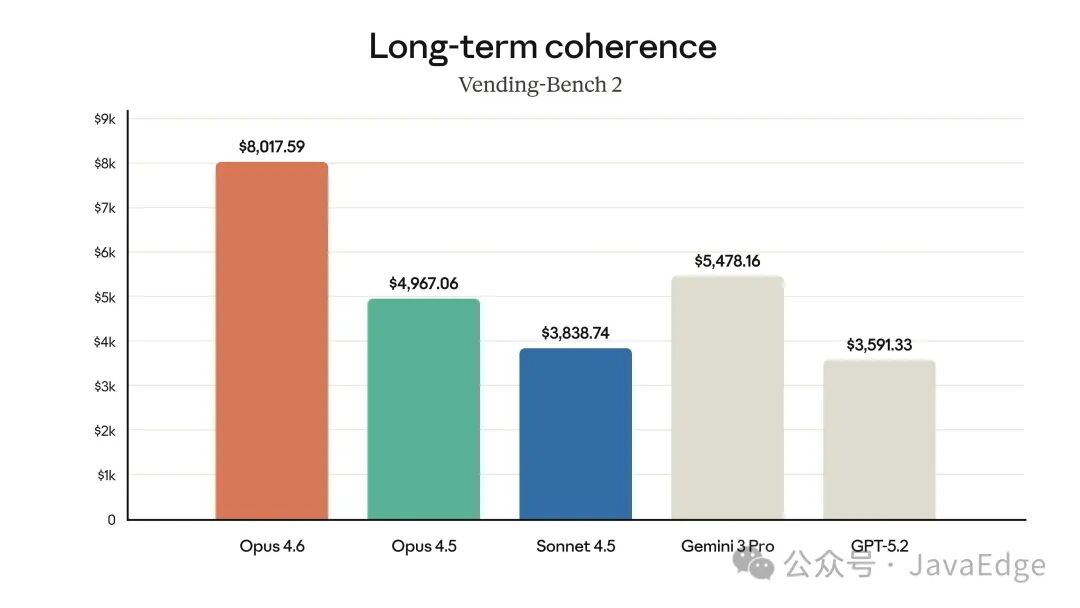
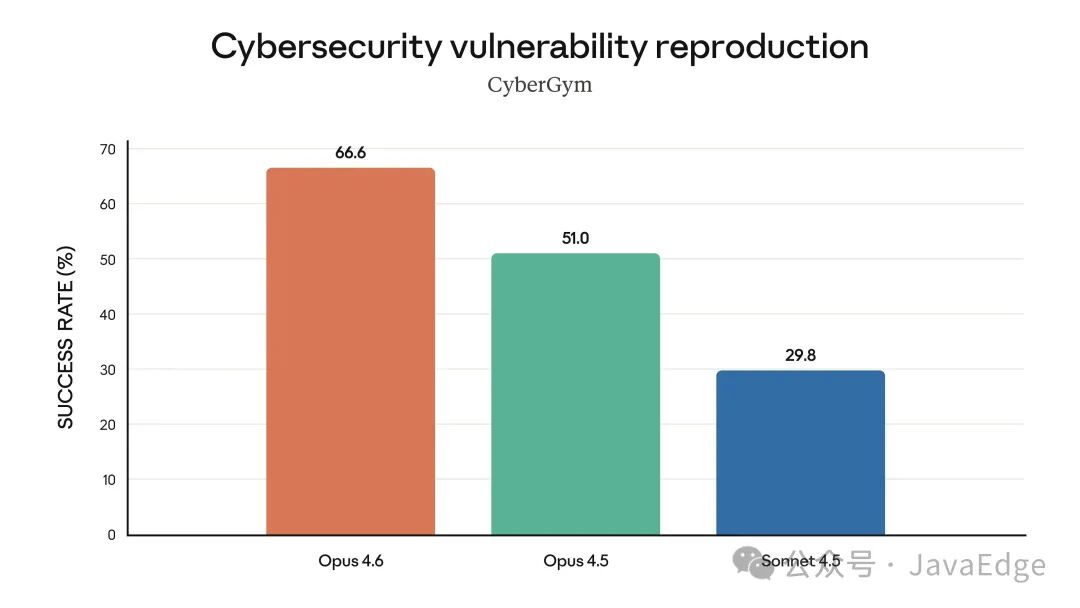
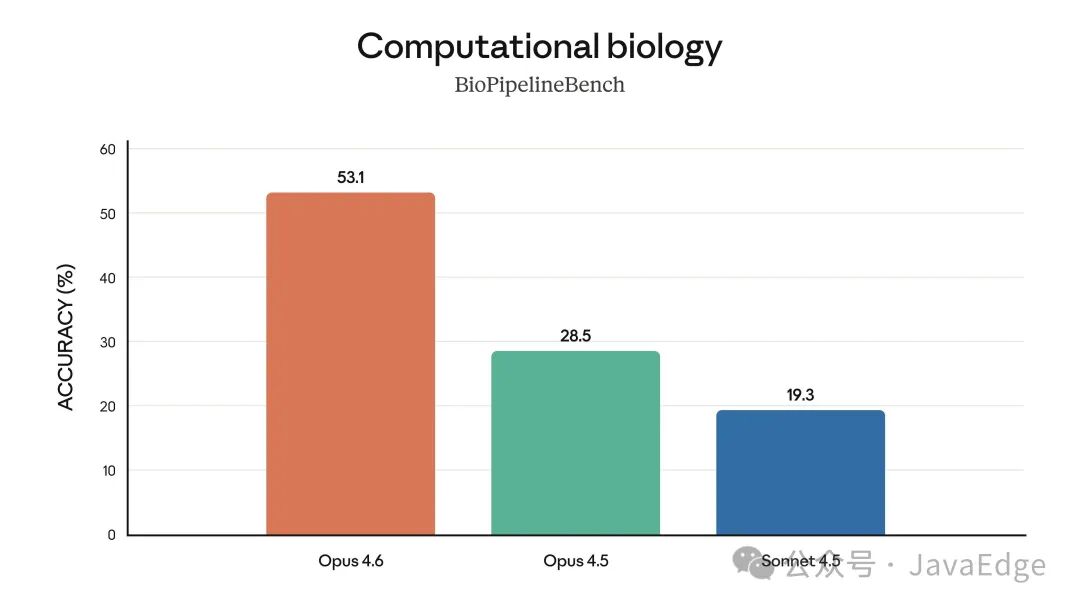
此外,Opus 4.6 在软件工程、多语言编程、长期一致性、网络安全及生命科学等垂直领域也表现卓越。
软件故障根因分析(OpenRCA)
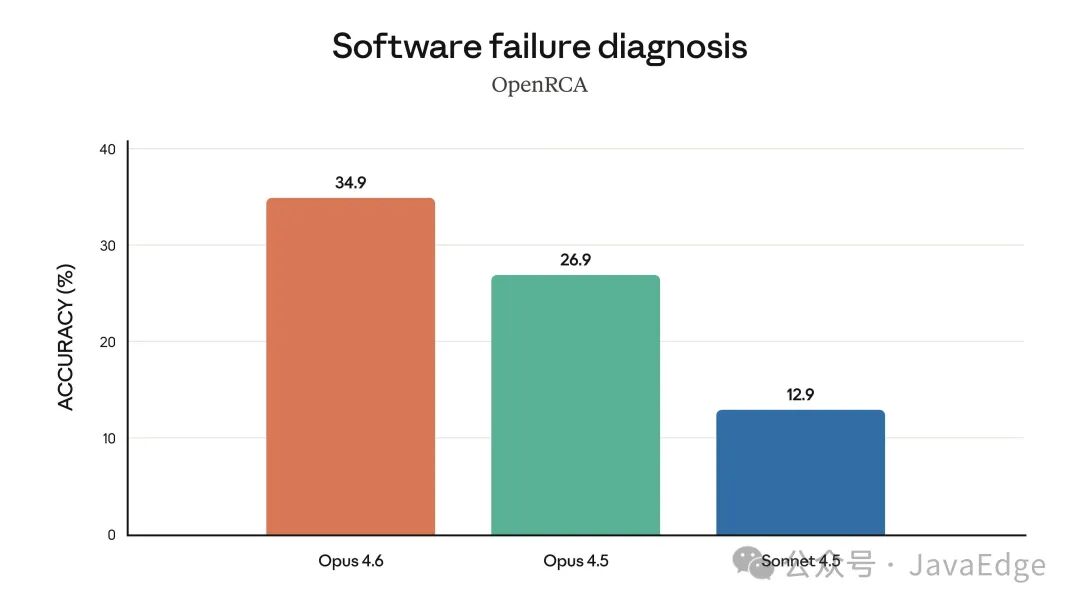
Opus 4.6 在诊断复杂软件故障方面表现尤为突出。
多语言编程(SWE-bench Multilingual)
长期一致性(Vending-Bench 2)
网络安全(CyberGym漏洞复现成功率)
计算生物学(BioPipelineBench准确率)
安全与对齐性提升
此次智能水平的提升并未以牺牲安全性为代价。在Anthropic的自动化行为审计中,Opus 4.6 在欺骗、讨好式迎合、强化用户妄想以及协助不当用途等偏离行为上的发生率都很低。其整体行为与前代 Claude Opus 4.5 一样保持了高度对齐,而后者此前已是其对齐度最高的前沿模型。
同时,Opus 4.6 也是近期所有Claude模型中“过度拒答”(即对无害问题未能作答)发生率最低的。
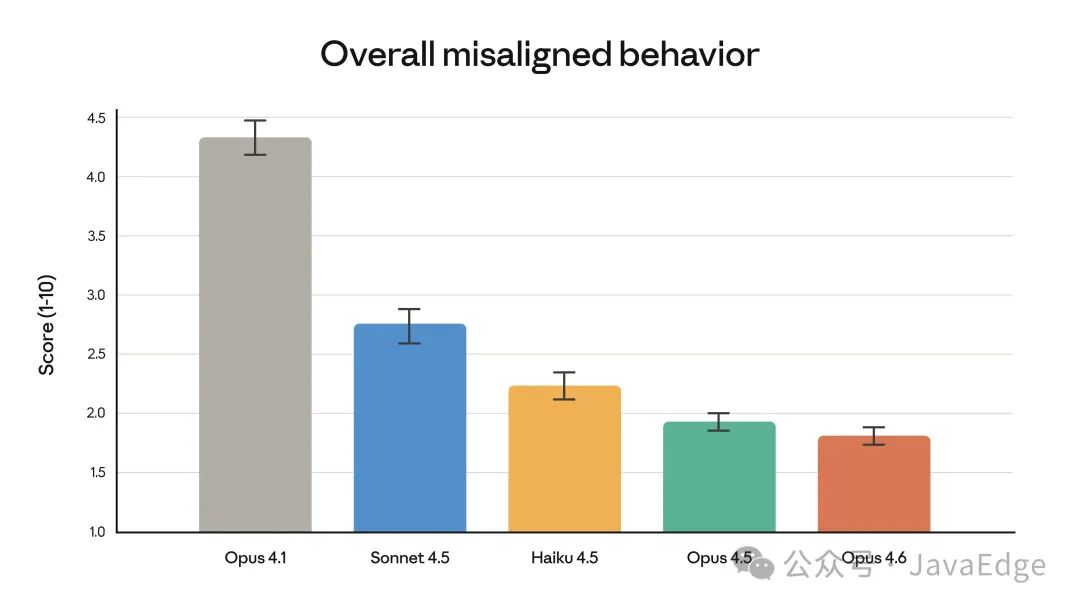
各代 Claude 模型在自动化行为审计中的整体偏离行为得分(得分越低越好)。
针对 Claude Opus 4.6,Anthropic开展了迄今为止最全面的一套安全评估,引入了多项全新的测试方法。特别是在网络安全方面,由于模型能力显著增强,团队开发了6种新的网络安全探针,用于检测潜在的有害输出,从而更好地监控不同形式的滥用风险。与此并行的是,他们也在加速模型在网络防御领域的应用,例如利用它帮助发现并修复开源软件中的漏洞。
产品与API重要更新
为了充分释放 Opus 4.6 的潜力,Anthropic在 Claude 开发者平台、Claude 及 Claude Code 产品中进行了全面升级。
API与开发者平台更新
Claude API为开发者提供了更精细的控制和对长时间运行代理的更高灵活性:
- 自适应思考(Adaptive thinking):过去开发者只能在开启或关闭扩展思考(thinking)之间二选一。现在,Claude可以自行判断何时需要进行更深入的推理。在默认的
high effort 下,模型会在合适的场景自动启用扩展思考。
- Effort 控制:现在共有四种
effort 级别可选:low、medium、high(默认)和 max。开发者可以尝试不同级别,以在智能、速度与成本间找到最佳平衡。
- 上下文压缩(Context compaction,测试版):该功能会在对话长度接近可配置的阈值时,自动总结并替换较早的上下文,使Claude能够在不触及上下文窗口限制的情况下,持续执行超长任务。
- 100 万 token 上下文(测试版):Opus 4.6 是首个支持100万token上下文的Opus系列模型。超过20万token的提示将采用特定的高级定价。
- 12.8 万 token 输出:模型支持最多128k token的单次输出,可一次性完成大规模内容生成,无需拆分成多次请求。
- 仅限美国的推理(US-only inference):对于有数据合规要求、需要在美国境内运行推理的工作负载,可使用此选项,价格为标准token定价的1.1倍。
产品功能更新
在 Claude 和 Claude Code 产品中,新增了多项功能:
- 代理团队(研究预览):用户现在可以在Claude Code中同时启动多个AI代理,让它们并行协作、自主协调。这特别适合可拆分为多个独立、偏重信息读取任务的场景,例如大型代码库审查。用户也可以随时接管任意子代理的控制权。
- 办公套件深度集成:Claude in Excel 在处理耗时更长、难度更高的任务时性能显著提升。新发布的 Claude in PowerPoint(研究预览) 允许用户先在Excel中处理数据,再让Claude将其以视觉化方式呈现在PowerPoint中,并自动匹配品牌版式、字体等风格。该功能已面向Max、Team和Enterprise套餐用户开放。
从编程能力的飞跃到长上下文处理的质变,Claude Opus 4.6的发布无疑在人工智能领域树立了新的标杆。其增强的代理能力和对智能 & 数据 & 云基础设施的深度利用,为开发者构建下一代复杂应用提供了强大的基础。对这类前沿AI技术动态感兴趣的开发者,不妨多关注像云栈社区这样的技术社区,与同行交流最新的实践与见解。
 发表于 2026-2-9 06:00:00
|
查看: 221|
回复: 0
发表于 2026-2-9 06:00:00
|
查看: 221|
回复: 0
