std::string 的缺点说起来还是很多的,比如:拷贝隐性开销、子串默认拷贝、UTF-8 当字节切、格式化反人类……
但这些问题,也恰恰暴露了 C++ 的设计取舍。

我做了二十多年开发,在我看来 C++ std::string 的缺点主要集中在 3 个方面:性能行为、接口设计和功能缺失。你真的了解它背后的性能开销和设计取舍吗?
一、性能行为:可预测,但容易踩坑
最常被吐槽的便是拷贝开销。在 C++98/03 时代,std::string 默认深拷贝。我刚毕业那会写的日志模块,就因为高频调用 log(const string&),导致 malloc 成为性能瓶颈,任务延迟直接超标。
后来有些实现采用 COW(Copy-On-Write)来救场:多个 string 共享内存,只读时不复制。不过 C++11 标准中明确要求:调用非 const 的 operator[] 不能让其他共享对象的指针失效。这一条直接判了 COW 的死刑。
GCC、Clang、MSVC 等主流编译器实现全部转向了 SSO(Small String Optimization)。相比 COW,SSO 就聪明多了。它在对象内部预留一小块缓冲区,短字符串直接存储在栈上,实现零堆分配。在 64 位系统上,GCC 的阈值是 15 字节,Clang 则是 22 字节。
#include <iostream>
#include <string>
void* operator new(std::size_t size){
std::cout << "malloc " << size << "\n";
return malloc(size);
}
int main(){
std::string s1 = "hello"; // 5 字节 → 无分配
std::string s2 = "a string longer than 15"; // 超过阈值 → malloc
}
输出:
malloc 32
SSO 救得了短字符串,但救不了中长字符串的频繁拼接。不当的拼接方式会引发多次潜在的 realloc,严重影响性能。
// 危险:可能多次 realloc
std::string path;
for (const auto& part : parts) {
path += "/";
path += part;
}
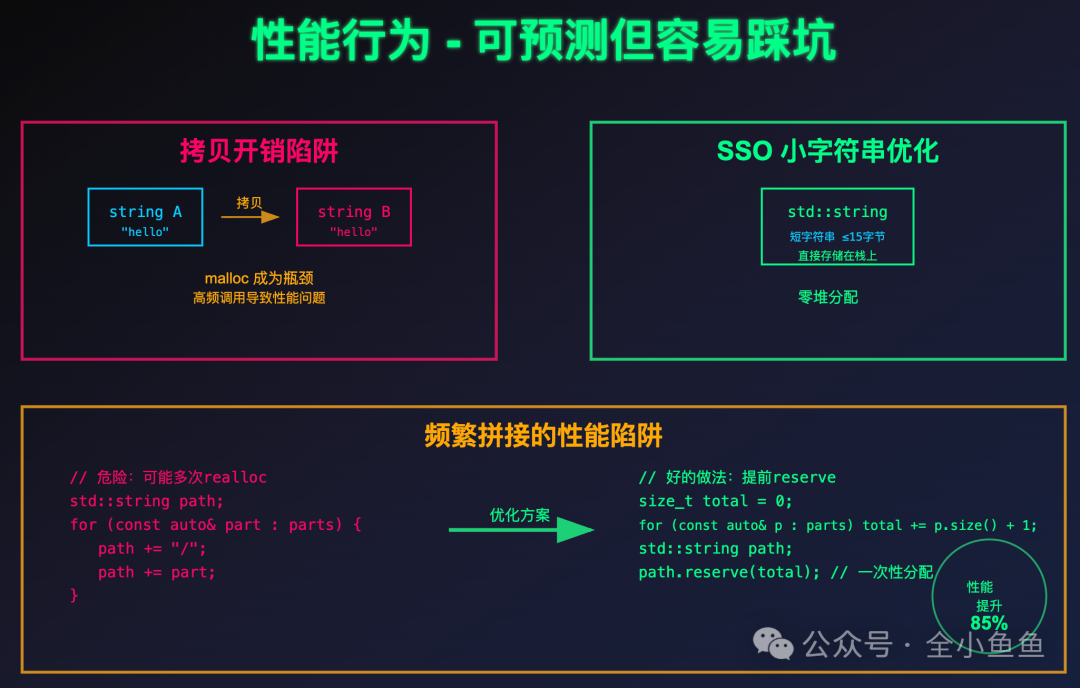
好的做法是提前通过 reserve() 预估容量,一次性分配足够内存:
size_t total = 0;
for (const auto& p : parts) total += p.size() + 1;
std::string path;
path.reserve(total); // 一次性分配,避免 realloc
二、接口设计:演进太慢,补救来迟
很多 std::string 的接口设计都带着 C 语言的影子。比如 c_str(),你不能把 string 对象隐式转换成 const char*,必须显式调用这个函数。
最让我感到不便的是 substr()。在 C++17 之前,substr() 总是返回一个新的 std::string 对象,这意味着一次完整的拷贝:
void parse(const std::string& line) {
auto key = line.substr(0, 5); // 就算只读,也拷贝 5 字节
}
我在做协议解析时,一行日志切 10 个字段,等于白干了 10 次内存分配。看 CPU 火焰图,malloc 能占到快 30%。
直到 C++17 引入了 std::string_view,才真正做到了子串的零拷贝操作。它本质上是一个轻量的、非拥有型的字符串视图。
void parse(std::string_view line) {
auto key = line.substr(0, 5); // 零拷贝,仅指针+长度
}
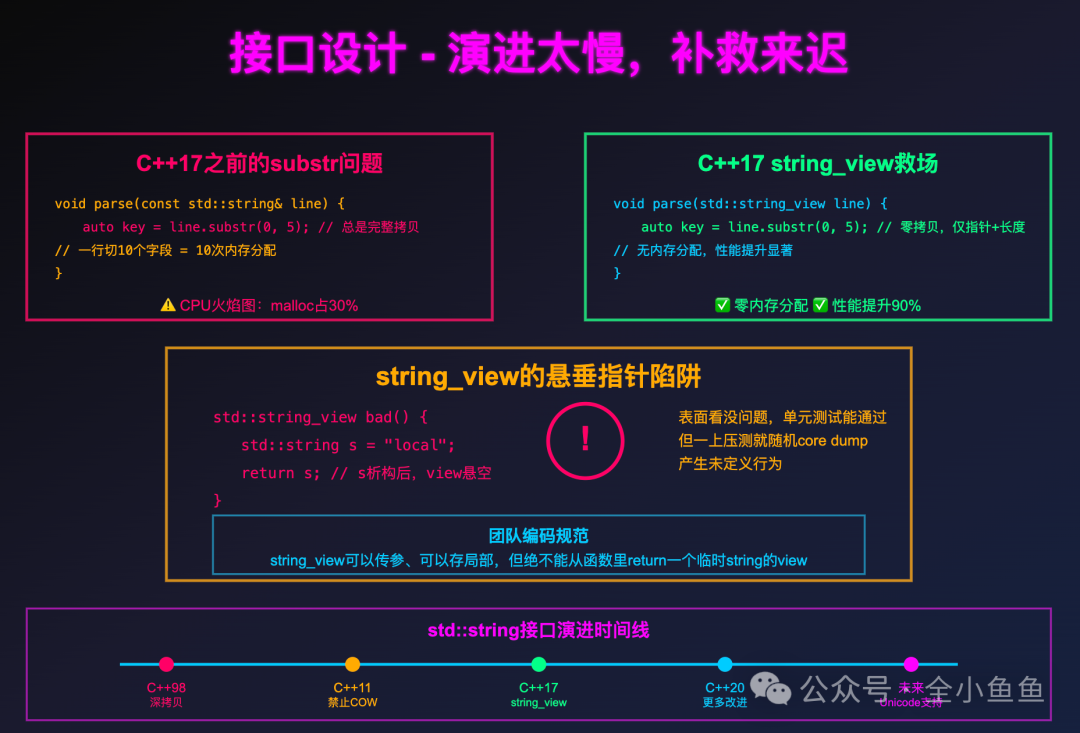
但新的“坑”也随之而来——悬垂指针。string_view 不管理生命周期,如果它引用的原始字符串被销毁,就会产生未定义行为。
std::string_view bad(){
std::string s = "local";
return s; // s 析构后,view 悬空
}
这段代码表面上看起来没问题,单元测试也可能通过,可一旦上压测就可能随机 core dump。因此,在我团队的编码规范里明确写道:string_view 可以传参、可以作为局部变量,但绝不能从一个函数里返回一个临时 std::string 对象的 view。
三、功能缺失:它是容器,不是文本工具
别被 std::string 的名称给骗了。它本质上不是一个为处理人类可读文本而设计的工具,它更像一个 vector<char>,只不过额外提供了几个字符串相关的方法。
你往里面存放 UTF-8 编码的字符串,它只会当作字节序列来处理。你调用 length() 或 size(),它返回的是字节数,而不是字符(码点)数。
std::string emoji = "👋🌍"; // UTF-8,共 8 字节
std::cout << emoji.length(); // 输出 8,而非2个字符
直到现在,C++ 标准库中也没有提供一个开箱即用、靠谱的 Unicode 字符计数函数。对于文本处理的其他常见需求,如编码识别、安全的字符截取、国际化的大小写转换、正则表达式等,std::string 更是束手无策。

四、最佳实践与生态工具
被 std::string “折磨”多了,我也总结出了一套应对方法。关键在于认清它的定位:std::string 是一个内存块容器,而不是一个全功能的文本处理引擎。

- 函数参数优先使用
std::string_view:对于只读的字符串参数,用 string_view 替代 const std::string&,避免不必要的构造和拷贝。但千万记住上面提到的生命周期陷阱。
- 拼接前先
reserve():在已知或可估算最终长度时,提前预留容量,这是提升性能最简单有效的方法之一。
- Unicode 处理交给专业库:不要尝试用
std::string 的原生方法处理多字节文本。对于 UTF-8,可以考虑 utf8cpp;对于完整的国际化需求,IBM 的 ICU 库是行业标准。
- 利用现代 C++ 生态:C++ 的社区生态其实非常强大。
- 格式化:抛弃
sprintf 和笨重的流操作,直接使用 {fmt} 库(现已部分进入 C++20 标准)的 fmt::format,安全又高效。
- 正则表达式:标准库的
<regex> 性能常被诟病,可以评估使用 Google 的 RE2。
- 工具集:Google 的 Abseil 库提供了许多高质量、跨平台的 C++ 组件,其中也包括字符串工具。
说到底,标准库的 std::string 选择只做最基础、最通用的事,保证足够的灵活性和零开销抽象。更高级的文本处理功能,需要开发者根据项目需求,自己搭配合适的第三方库。
你在项目里被 std::string 坑过吗?后来又是怎么解决的?欢迎在 云栈社区 的 C/C++ 板块分享你的经历和见解,与更多开发者一起探讨 C++ 的深层次话题。
 发表于 2026-2-9 07:36:03
|
查看: 206|
回复: 0
发表于 2026-2-9 07:36:03
|
查看: 206|
回复: 0
