一段简单的代码测试,却能揭示出 JVM 底层对象分配机制的奥秘。当你在高频创建对象的循环中,多写或少写一行打印语句,性能竟能有十倍的差距,这背后究竟是什么原理?
代码测试
我们先来看一下引发问题的测试代码。
import com.google.common.base.Stopwatch;
import java.util.concurrent.TimeUnit;
public class StackTest {
public static void main(String[] args) {
Stopwatch started = new Stopwatch();
started.start();
User user = null;
for (long i = 0; i < 1000_000_000; i++) {
user = new User();
}
started.stop();
System.out.println(started.elapsed(TimeUnit.MILLISECONDS) + "ms");
//不加打印 300ms
//加了打印 3000ms
// System.out.println(user);
}
}
class User {
private int age;
private String userName;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
}
这段代码的核心是循环创建 10 亿个 User 对象。关键点在于最后一行被注释掉的 System.out.println(user)。
测试结果表明:
- 不执行最后的打印语句,耗时大约在 300ms。
- 如果取消注释,执行打印语句,耗时则飙升至 3000ms 左右,性能下降高达 10 倍。(具体时间因机器配置而异)
如此简单的代码改动,竟能带来如此巨大的性能差异,这确实引人深思。要理解这个现象,我们必须深入 Java 对象在堆内存中的分配规则。
对象分配规则
一个Java对象在堆上诞生,并不是随意找块空地放下那么简单。JVM为了提升分配效率和程序性能,设计了一套精细的分配策略,其决策流程如下图所示:
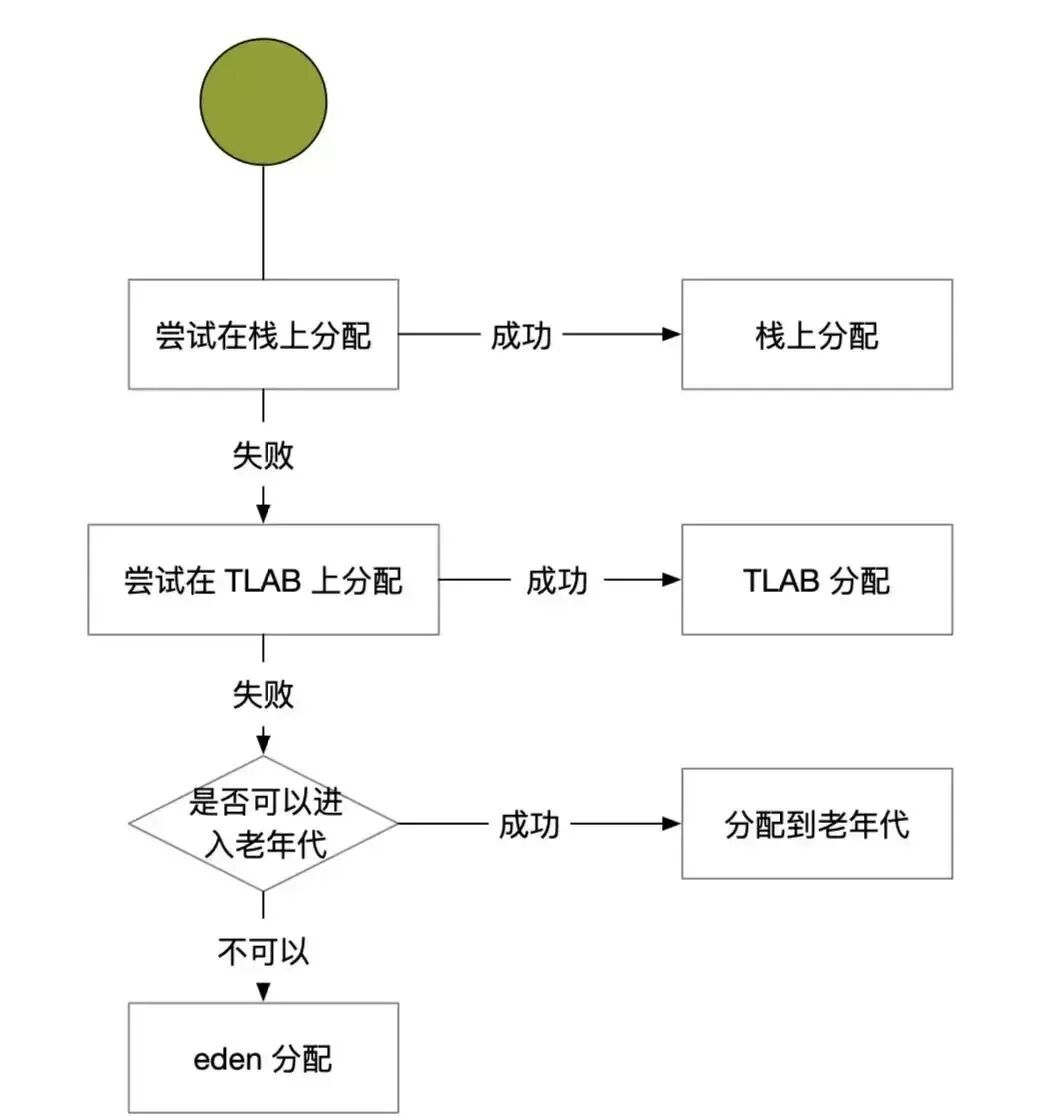
栈上分配
栈上分配是JVM提供的一项重要优化技术。它允许将一些线程私有的对象“打散”,将其字段直接分配在虚拟机栈的局部变量表中。这样分配的对象,其生命周期与栈帧一致,方法执行结束栈帧弹出时,对象内存也随之被回收,完全不需要垃圾收集器(GC)的介入,效率极高。
当然,栈上分配的条件也较为苛刻:
- 栈空间有限:无法容纳大对象。
- 对象不得逃逸:即对象不能在方法外部被引用(可通过JVM参数
-XX:+DoEscapeAnalysis 开启逃逸分析)。
- 对象可被标量替换:即对象能够被分解为其原生类型的字段来表示(通过
-XX:+EliminateAllocations 开启)。
例如在上面的Demo中,如果满足条件,JVM可能会直接用 int age 和 String userName 这两个变量来替代完整的 User 对象,从而避免在堆上创建。
TLAB 分配
TLAB,全称 Thread Local Allocation Buffer,即线程本地分配缓存。这是堆内 Eden 区中划出的一块线程专属内存区域。在TLAB启用的情况下(默认开启),JVM会为每个线程分配一小块TLAB。
引入TLAB的目的是为了加速对象分配。因为堆是线程共享的,直接在上面分配对象需要同步操作(如指针碰撞),存在线程竞争开销。而TLAB是线程私有的,在其范围内分配对象无需加锁,极大地提升了高频分配场景下的效率。
同样,TLAB空间较小,所以大对象无法在TLAB内分配,只能走堆上分配的路径。
分配策略:
假设一个TLAB区域大小为100KB,已使用了80KB。此时需要分配一个30KB的对象,该如何处理?
- 废弃当前这个TLAB,为该线程重新申请一个新的TLAB。
- 将这30KB的对象直接分配到堆的共享Eden区,而当前这个剩余的20KB TLAB区域保留,供后续分配小对象时使用。
JVM采用第二种策略,并在内部维护一个名为 refill_waste 的阈值。当请求分配的对象大小超过 refill_waste 时,就选择在堆中分配;否则,就废弃当前TLAB,新建一个TLAB来分配新对象。默认情况下,TLAB的大小和 refill_waste 阈值都会在运行时自适应调整,以达到最优状态。
相关JVM参数
| 参数 |
作用 |
备注 |
-XX:+UseTLAB |
启用TLAB |
默认启用 |
-XX:TLABRefillWasteFraction |
设置允许空间浪费的比例 |
默认值64,即使用1/64的TLAB空间作为refill_waste值 |
-XX:-ResizeTLAB |
禁止系统自动调整TLAB大小 |
|
-XX:TLABSize |
指定TLAB大小 |
单位:B |
Demo 现象剖析
结合上面的知识,现在我们就能清晰地解释测试代码中的性能差异了。
不加 System.out.println(user) 的情况:
在循环中创建的 User 对象仅在循环内部被引用,没有暴露给外部方法(即 main 方法之外)。因此,这些对象被判定为“未逃逸”。在开启了逃逸分析(默认是开启的)和标量替换优化后,JVM极有可能对这些对象进行栈上分配或TLAB分配。这两种分配方式的速度都非常快,且避免了大量堆内存分配和后续的GC压力,所以耗时极短(约300ms)。
加上 System.out.println(user) 的情况:
打印语句导致在循环结束后,最后一个 User 对象被传递给了 System.out.println 方法。这使得该对象(从JVM优化视角看,可能影响到循环内对象的逃逸分析判断)发生了“逃逸”——它的引用被传递到了当前方法(main)之外。由于不满足栈上分配的核心条件,所有对象都必须在共享的堆Eden区进行分配。这带来了同步开销,并且创建的大量对象会迅速填满Eden区,触发频繁的Minor GC,从而导致性能急剧下降(约3000ms)。
如果你再尝试添加 -XX:-UseTLAB 参数来关闭TLAB分配,分配速度还会进一步下降(TLAB优化在多线程竞争分配时效果尤为明显,此处不再展开验证)。
这个案例生动地展示了,一行看似无害的代码,是如何改变JVM的底层行为模式,进而对程序性能产生巨大影响的。理解这些内存分配机制,对于编写高性能Java代码至关重要。如果你想深入探讨更多系统设计与性能优化的话题,欢迎在云栈社区交流分享。
 发表于 2026-2-9 03:55:34
|
查看: 171|
回复: 0
发表于 2026-2-9 03:55:34
|
查看: 171|
回复: 0
