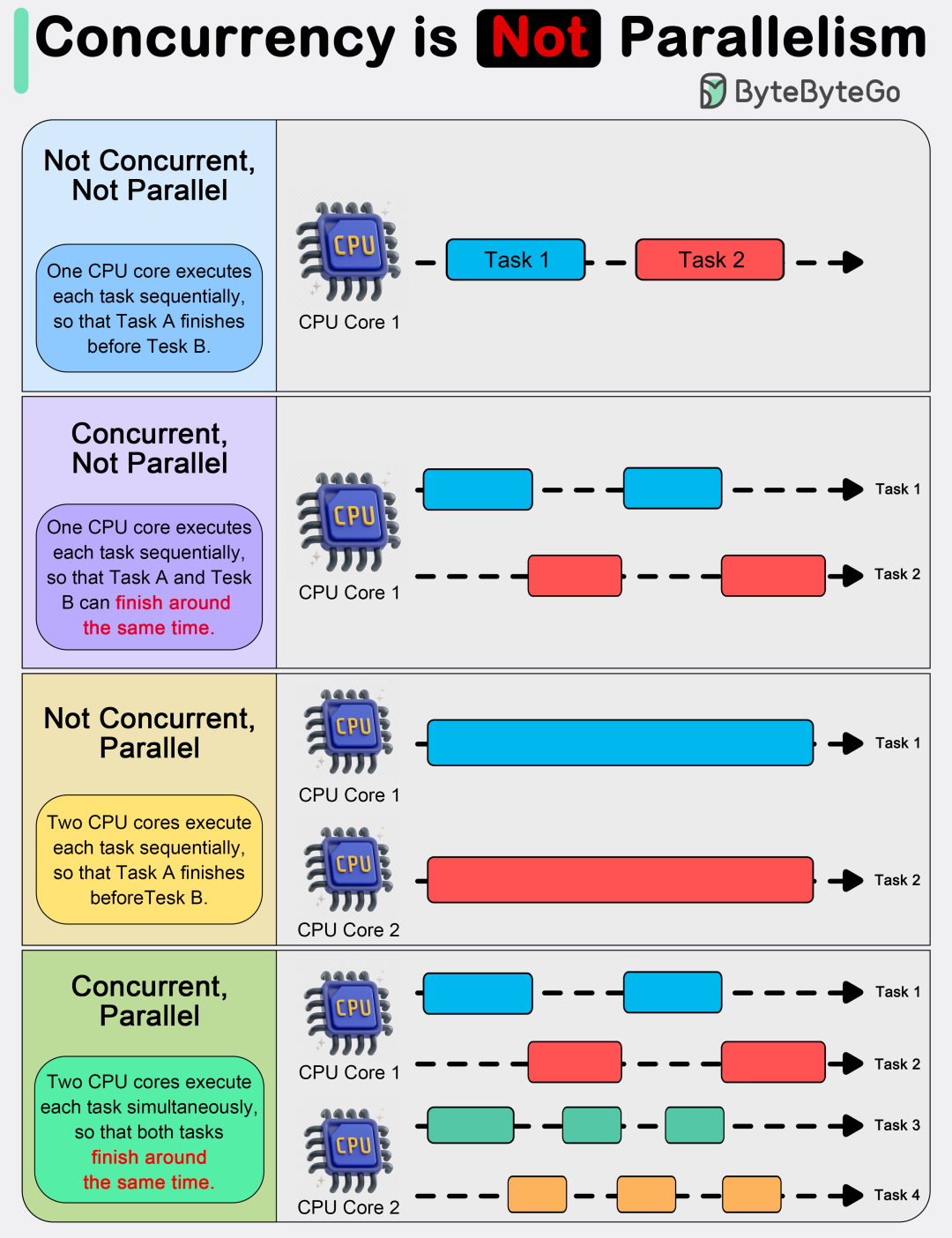
在系统设计和程序开发领域,“并发”(Concurrency)和“并行”(Parallelism)是两个经常被提及却又极易混淆的概念。许多开发者将它们混为一谈,这往往会导致在技术选型和架构设计时做出错误的判断。深入理解二者的区别,是构建高效、可扩展系统的基石。
一句话区分
Go 语言的创始人之一 Rob Pike 对此有过一句精辟的总结:
“并发是同时处理很多事情。并行是同时做很多事情。”
这句话点出了二者的核心:
- 并发关乎程序的结构设计。
- 并行关乎程序的执行方式。
并发是什么?
并发是一个结构问题。它指的是程序设计成能够处理多个可以重叠执行的任务。这些任务在时间上可以交替进行,但在物理上的任意一个瞬间,可能只有一个任务在执行。
关键特性:
- 任务可以启动、运行、完成在重叠的时间段内。
- 不需要多核 CPU,单核通过时间片轮转等技术就能实现并发。
- 本质上是“看起来同时”,通过快速切换任务来达到目的。
什么时候用并发?
- I/O 密集型任务:等待网络响应、读写文件、接收用户输入时,CPU 可以切换去执行其他任务。
- 保持响应性:例如在图形界面(UI)程序中,后台处理耗时操作时,主线程仍需响应用户交互。
- 后台任务:如日志记录、健康监控等不影响主流程的任务。
例子:一个餐厅服务员同时服务多桌客人。他并不是真的同时为所有客人点菜或上菜,而是在A桌点完单后,马上去B桌处理需求,通过快速切换来“同时”服务多桌。
并行是什么?
并行是一个执行问题。它指的是多个计算任务在物理上真正地同时执行,这通常需要硬件的支持,如多核 CPU、多个处理器或多台机器。
关键特性:
- 真正的物理同时执行。
- 需要硬件支持(多核、多处理器、多机集群)。
- 目标是提高吞吐量和计算速度,缩短任务的整体完成时间。
什么时候用并行?
- CPU 密集型任务:如图像渲染、科学计算、大规模数据处理等需要大量计算的操作。
- 可分解的独立任务:能够被拆分且彼此之间没有强依赖关系的工作负载。
- 需要显著缩短执行时间的场景。
例子:餐厅有多个服务员,他们可以同时分别为不同的桌子提供服务。这是真正的同时发生。
关系图解
我们可以用简单的文本图示来理解它们的执行模式:
并发:
CPU 1: [Task A] ---- [Task B] ---- [Task A] ---- [Task B]
(交替执行,看起来像同时进行)
并行:
CPU 1: [Task A] --------------------------
CPU 2: [Task B] --------------------------
(真正同时执行)
并发 + 并行:
CPU 1: [Task A] ---- [Task C] ---- [Task A]
CPU 2: [Task B] ---- [Task D] ---- [Task B]
(既有并发调度,又有并行执行)
现代高性能系统往往是“并发+并行”的结合体。程序被设计为并发结构(例如使用Goroutine或线程),然后这些并发单元被调度到多个CPU核心上并行执行。
实际应用
Web 服务器
- 并发:使用协程、线程或异步 I/O 模型来同时处理成千上万个连接请求。当一个请求等待数据库查询(I/O)时,服务器可以立刻切换去处理另一个请求。
- 并行:通过多进程(如Nginx的Worker进程)或多线程,利用服务器的多核CPU,同时处理多个请求的计算部分。
像 Nginx、Go 语言编写的 HTTP 服务,都是并发设计与并行执行的典范。
数据处理
- 并发:流式处理系统(如 Kafka Streams、Flink)需要“来一条处理一条”,并保持低延迟和高吞吐,这依赖于优秀的并发设计来管理数据流。
- 并行:批处理任务(如 Hadoop/Spark)将数据分片,分发到多个计算节点或核心上同时进行计算,属于典型的并行计算,目的是加速处理过程。
UI 程序(如桌面或移动应用)
- 并发:主线程(UI线程)必须始终保持流畅响应,任何耗时操作(如网络请求、复杂计算)都应交给后台线程,通过并发设计避免界面卡顿。
- 并行:在多核设备上,渲染引擎、业务逻辑计算和网络通信等任务可以被分配到不同的核心上同时执行,提升整体性能。
常见误区
- 并发一定更快? 不一定。对于纯CPU密集型任务,并发带来的上下文切换开销可能使程序比串行执行更慢。并发的优势在于提高资源利用率和响应性。
- 并行就是好的? 不总是。如果任务之间存在严重的数据依赖或同步(如锁)竞争,并行带来的协调开销可能会抵消甚至超过其收益,导致“并行不如串行”。
- 多线程就是并行? 不一定。在单核 CPU 上运行的多线程程序,只是并发而非并行。只有在多核CPU上,多个线程才可能真正并行执行。
总结
我们可以通过一个简单的表格来回顾核心区别:
| 关注点 |
并发 |
并行 |
| 核心能力 |
处理多任务 |
同时执行多任务 |
| 硬件要求 |
不需要多核 |
需要多核/多机 |
| 适用场景 |
I/O 密集型,响应性要求高 |
CPU 密集型,追求吞吐量 |
| 主要目标 |
资源利用率、程序结构清晰、响应性 |
执行速度、缩短任务时间 |
本质上,好的并发设计为并行执行提供了可能,但并发本身并不依赖于并行。一个设计优良的并发程序,在单核上能高效处理多任务,在多核上能自动获得并行加速。理解这个关键区别,能帮助你在系统设计中正确选择模型(如多线程、事件驱动、Actor模型)和工具,从而构建出更稳健、高效的应用。希望这篇梳理能帮你彻底厘清这两个重要的概念。如果你想深入探讨更多计算机基础或具体语言的并发模型,欢迎在云栈社区继续交流。 |  发表于 2026-2-9 03:28:30
|
查看: 223|
回复: 0
发表于 2026-2-9 03:28:30
|
查看: 223|
回复: 0
