你是否好奇过,Google和Apple地图中的街景视图是如何实现对人脸、车牌等敏感信息自动打码的?这背后并非依赖人工逐一处理,而是由一套高效、智能的自动化系统完成的。
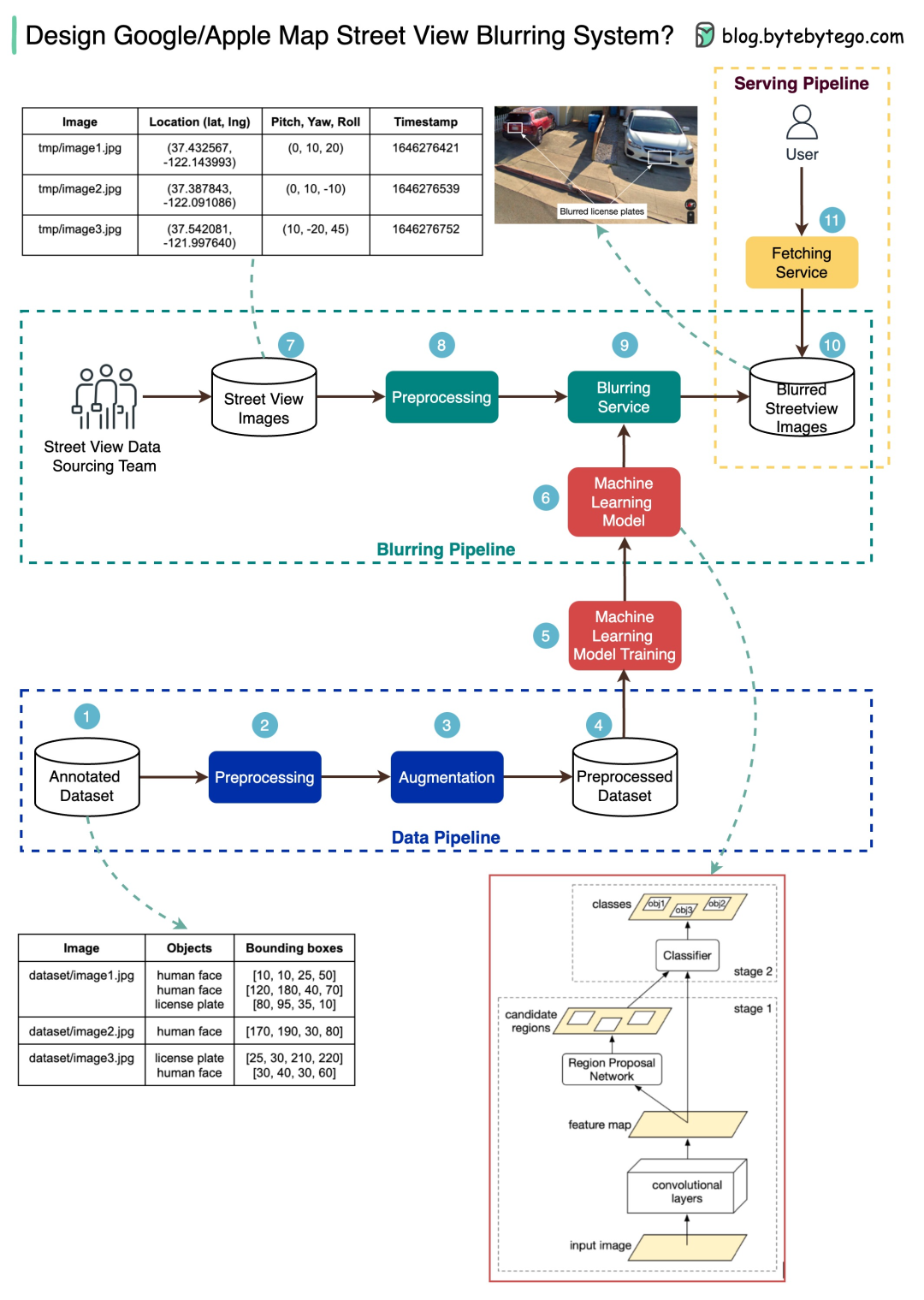
整个系统的运作可以清晰地划分为三个阶段,上图展示的正是其核心架构。
1. 数据管道 —— 构建模型的“训练场”
首要任务是准备高质量的“教材”。系统需要一批预先标注好的数据集,其中每张街景图片中的人脸、车牌等目标都被精确地框选出来。这些数据经过清洗、预处理、增强(如旋转、缩放以模拟不同拍摄条件)和归一化后,构成了一份标准化的“习题集”,用于训练一个强大的机器学习模型。这个过程是后续所有自动识别能力的基础。
2. 打码管道 —— 实时检测与处理
当新的街景照片被采集上传后,便会进入处理流水线。首先进行必要的图像预处理,然后由训练好的模型对图片进行扫描与识别。一旦检测到如人脸或车牌这类预设的敏感目标,系统会立即对其所在区域应用模糊算法进行处理。处理完成后的“洁净”图片,会被存储到可靠的对象存储服务中,等待调用。
3. 服务管道 —— 面向用户的交付层
这是直接与用户交互的一环。当用户在地图应用中浏览街景时,前端服务会向后台发起请求。后台服务则从存储中获取对应坐标的、已经完成模糊处理的图片,并将其快速返回给用户。整个流程对用户而言是无感的,他们看到的就是一张已经做好隐私保护的街景视图。
核心技术细节
为了实现高精度的识别,此类系统通常采用经典的两阶段目标检测网络。第一阶段(如Region Proposal Network)负责在图像中快速找出可能包含物体的候选区域;第二阶段则对这些候选区域进行精细分类,判断其是否属于需要打码的类别(如人脸、车牌),并修正其边界框位置。这种“先定位,后识别”的架构,在准确率和效率之间取得了良好平衡。
理解了这套技术框架,不仅有助于我们认识日常应用背后的复杂工程,也是应对系统设计类面试问题的绝佳案例。如果你对这类融合了人工智能与大型系统架构的话题感兴趣,欢迎在云栈社区与我们深入探讨。 |  发表于 2026-2-26 04:40:49
|
查看: 200|
回复: 0
发表于 2026-2-26 04:40:49
|
查看: 200|
回复: 0
