当数据集中向量的数量膨胀到百万甚至十亿级别时,如何在这种规模下依然保证搜索又快又准,就成了一个必须面对的工程难题。本文将深入探讨向量搜索系统的三个核心优化方向:针对单节点性能的调优、融合词法与语义的混合搜索,以及支撑大规模部署的可扩展架构。
传统词法搜索的局限
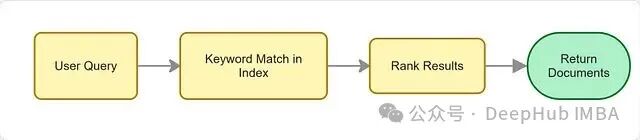
传统搜索系统的核心是词法匹配:检查文档中是否出现了查询中的关键词。至于查询背后的语义、用户意图或概念层面的相似性,并不在其考虑范围之内。
例如,用户查询 cheap car,而文档中写的是 affordable vehicle。两者意思完全一致,但传统搜索会判定为不匹配,因为没有任何一个词是相同的。
像 Elasticsearch 这类系统引入了 BM25 等排序算法,根据词频和文档重要性进行打分。但无论怎样优化打分策略,其底层逻辑依然依赖于关键词的重叠。一旦用户换一种说法表达相同的意思,检索结果的排名就可能大幅下降。在同义词、意译和深层语义理解面前,传统的词法搜索始终显得力不从心。
通过下面这段 Python 代码,可以直观感受传统关键词匹配的局限性:
documents = [
"Affordable vehicle for students",
"Best gaming laptop",
"Budget friendly smartphone"
]
def traditional_search(query, docs):
results = []
query_words = query.lower().split()
for doc in docs:
doc_lower = doc.lower()
if all(word in doc_lower for word in query_words):
results.append(doc)
return results
# Query
query = "cheap car"
print(traditional_search(query, documents))
输出:
[]
结果为空。尽管“Affordable vehicle”和“cheap car”在语义上几乎等价,但关键词匹配对此毫无办法。要解决这个问题,就需要引入新的思路——向量搜索。
什么是向量搜索?
向量搜索不再比较文本的字面词汇,而是比较其背后的含义。其核心思想是将文档和查询都转换为数值向量(即 Embedding模型),这些向量编码了文本的语义信息。即使两段文本用词完全不同,只要它们的含义相近,其对应的向量在高维空间中的位置也会彼此靠近。
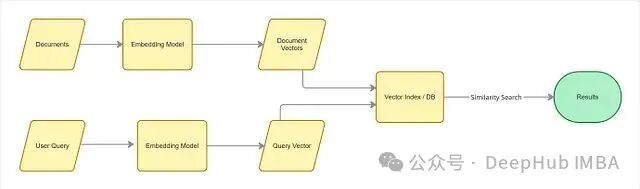
整个流程可以拆解为四个步骤:
- 文档处理(离线索引):将所有文档通过同一个 Embedding 模型转换为向量表示,并存入向量数据库或向量索引中。
- 查询处理(在线):用户提交查询后,使用同一个 Embedding 模型将查询文本也转换为向量。
- 相似性搜索:在向量索引内部,系统计算查询向量与所有文档向量之间的距离(如余弦相似度),找出最接近的向量。
- 返回结果:与查询向量距离最近的文档,即为语义上最相关的结果,即使它们和查询没有任何共同的关键词。
下面通过构建一个小型语义搜索引擎,来直观感受向量搜索的实践过程。
步骤1:将文本转换为 Embedding
使用 Sentence Transformers 库中的 all-MiniLM-L6-v2 模型:
from sentence_transformers import SentenceTransformer
documents = [
"Affordable vehicle for students",
"Best gaming laptop",
"Budget friendly smartphone"
]
model = SentenceTransformer("all-MiniLM-L6-v2")
doc_embeddings = model.encode(documents)
print(doc_embeddings.shape)
输出:
(3, 384)
每个句子都被转换成了一个384维的向量。
步骤2:理解向量相似性
similarities = model.similarity(doc_embeddings, doc_embeddings)
print(similarities)
输出:
tensor([[1.0000, 0.1679, 0.3233],
[0.1679, 1.0000, 0.2726],
[0.3233, 0.2726, 1.0000]])
这是一个成对余弦相似度矩阵。可以看到,“Affordable vehicle for students”和“Budget friendly smartphone”之间的相似度(0.3233)要高于它和“Best gaming laptop”的相似度(0.1679),这符合我们的直觉——前两者都带有“经济实惠”的语义。
步骤3:创建 FAISS 索引
import faiss
import numpy as np
doc_embeddings = np.array(doc_embeddings).astype("float32")
dimension = doc_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(doc_embeddings)
FAISS 索引能够在高维空间中进行高效的 K 近邻搜索,使用 L2 距离作为度量标准,快速找到与查询向量最接近的 Top-K 个向量。
步骤4:执行语义搜索
query = "cheap car"
query_embedding = model.encode([query]).astype("float32")
distances, indices = index.search(query_embedding, k=1)
print(documents[indices[0][0]])
输出:
Affordable vehicle for students
查询 cheap car 被成功匹配到了 Affordable vehicle for students。尽管关键词毫无重叠,但语义搜索准确地捕捉到了两者含义的相似性。
这个小例子仅处理了三条文档,运行起来毫无压力。但在现实场景中,面对百万甚至十亿级别的向量时,上面使用的 IndexFlatL2 这种暴力全量比较的方式将完全无法胜任,搜索延迟会急剧上升,内存消耗和可扩展性都将成为问题。接下来,我们就探讨如何优化。
性能调优:从精确搜索到近似最近邻(ANN)
IndexFlatL2 会对每个查询都遍历所有向量进行比较。数据量小的时候没有问题,一旦数据量变大就是性能灾难。性能调优的核心围绕三件事展开:压缩搜索时间、降低内存占用,同时尽可能减少检索精度的损失。
精确搜索 vs 近似最近邻(ANN)
前面演示中使用的 faiss.IndexFlatL2(dimension) 是精确最近邻搜索,它能保证精度,但在百万级向量面前速度缓慢。
解决方案是采用近似最近邻(ANN)算法。ANN 通过牺牲一点点精度,换来数量级的速度提升。在 FAISS 中,常用的 ANN 索引有 IndexIVFFlat 和 IndexHNSWFlat,它们通过减少实际参与比较的向量数量来加速检索。
倒排文件索引(IVF)
IVF 的核心思想是先对向量进行聚类。查询时,系统只在与查询最相关的几个聚类中进行搜索,而不是扫描全部数据。对于大型数据集,这种方法能显著降低延迟。
quantizer = faiss.IndexFlatL2(dimension)
index = faiss.IndexIVFFlat(quantizer, dimension, nlist=100)
这里的 nlist 是聚类数量。聚类越多,精度通常越高,但计算开销也越大。需要在实践中找到一个平衡点。
HNSW(基于图的搜索)
HNSW(Hierarchical Navigable Small World)采用了不同的思路:它不进行聚类,而是构建一个图结构。图中的每个向量都与其最近的邻居相连,搜索时沿着图的边进行“导航”。HNSW 搜索速度快、召回率高,且具有良好的可扩展性,是现代向量数据库中非常主流的索引方式。
向量压缩(乘积量化)
当数据量极大时,仅存储向量就会消耗大量内存。乘积量化(Product Quantization)技术通过对向量进行有损压缩,在减少内存占用的同时还能加速搜索。在处理百万乃至十亿级向量的场景下,这项技术几乎是标配。
硬件加速(GPU支持)
FAISS 支持 GPU 加速,通过并行化向量计算,可以大幅降低搜索延迟,非常适合对实时性要求高的场景,如推荐系统或大型搜索平台。
混合搜索:融合词法与语义的优势
在实际的搜索系统中,很少只使用关键词匹配或只使用向量相似性。更常见的做法是将两者结合起来,即混合搜索。
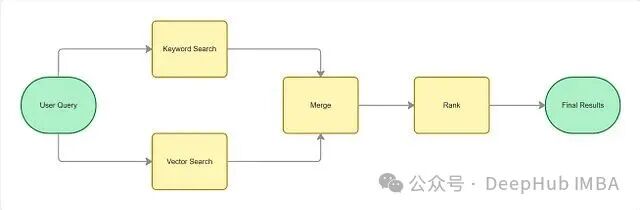
用户查询进入系统后,关键词搜索和向量搜索并行执行。关键词搜索产生一个基于词法相关性的分数(如 BM25 分数),向量搜索产生一个基于语义相似度的分数(如余弦相似度)。最后,系统将这两路分数融合成一个统一的排序分数。
评分融合公式
一种常见的加权融合公式如下:
FinalScore(d) = α * KeywordScore(d) + (1 - α) * VectorScore(d)
# 其中,d = document, α ∈ [0,1] 控制关键词精确度的重要性
这个分数并不代表绝对的“正确性”,而是用于对文档进行排序。系统按照 FinalScore 从高到低排列文档,排名靠前的即为最终结果。
混合搜索伪代码实现
# Step 1: Keyword Search
keyword_results = bm25.search(query)
# Step 2: Vector Search
query_embedding = embed(query)
vector_results = vector_db.search(query_embedding)
# Step 3: Merge + Weighted Ranking
def merge_and_rank(keyword_results, vector_results, alpha=0.6):
keyword_dict = {doc.id: doc.score for doc in keyword_results}
vector_dict = {doc.id: doc.score for doc in vector_results}
all_doc_ids = set(keyword_dict.keys()) | set(vector_dict.keys())
# Normalize scores (important in real systems)
def normalize(scores):
if not scores:
return {}
min_s = min(scores.values())
max_s = max(scores.values())
return {
doc: (score - min_s) / (max_s - min_s + 1e-9)
for doc, score in scores.items()
}
keyword_dict = normalize(keyword_dict)
vector_dict = normalize(vector_dict)
final_scores = {}
for doc_id in all_doc_ids:
kw_score = keyword_dict.get(doc_id, 0)
vec_score = vector_dict.get(doc_id, 0)
final_scores[doc_id] = (
alpha * kw_score +
(1 - alpha) * vec_score
)
ranked_docs = sorted(
final_scores.items(),
key=lambda x: x[1],
reverse=True
)
return ranked_docs
final_results = merge_and_rank(
keyword_results,
vector_results,
alpha=0.6
)
return final_results
这里有一个关键细节值得注意:分数归一化。BM25 分数是无界的,而余弦相似度分数通常落在 [-1, 1] 区间。如果不进行归一化就直接加权求和,其中一路的分数可能会完全压倒另一路,导致排序失真。因此,在实际系统中,融合前必须对分数进行归一化处理。
扩展向量搜索:应对海量数据
在小数据集上,向量搜索可以运行得很完美。但当向量数量从几千增长到几百万甚至几十亿时,单机架构就难以支撑了。生产环境下的扩展策略主要围绕三个方面:分片、分布式搜索和缓存。
分片(水平扩展)
分片是指将向量数据分散存储到多台机器上。例如,一个包含3000万个向量的数据集,可以按顺序分成三份,每台机器存储1000万个。
当查询到达时,系统首先生成查询向量,然后将其广播到所有分片。每个分片独立计算并返回其本地的 Top-K 结果,最后由一个协调节点汇总所有结果并进行全局重排序。需要增加容量时,只需添加新的机器即可,这就是水平扩展的优势。
分布式搜索(并行查询处理)
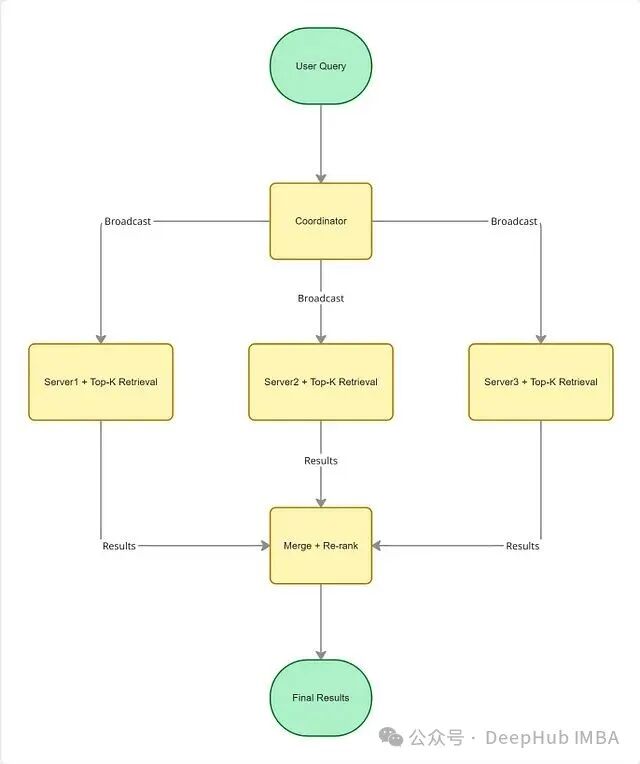
让一台服务器扫描1亿个向量太慢?那就将数据分布到10台服务器上,每台只需处理1000万个向量,并且可以并行执行搜索。工作量被分摊,搜索过程同步进行,结果最终在协调器节点汇合。这是分布式搜索引擎和现代向量数据库的标准架构。
缓存(显著优化响应速度)
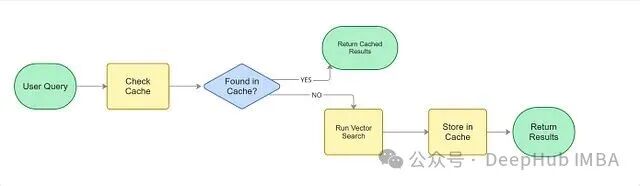
缓存的逻辑非常简单:If we have already answered this question before, don't compute again.
在没有缓存的情况下,每次查询都需要走完整个流程:生成 Embedding、向所有分片发送请求、计算相似度、合并结果、返回 Top-K。即使5秒前刚有人搜索过一模一样的内容,整套流程也得重新执行一遍,这无疑是巨大的资源浪费。
引入缓存后,系统在处理查询时会先检查缓存:Have we seen this query before? 如果命中,则直接返回预先计算并存储好的结果,跳过了 Embedding 生成和分布式搜索等所有耗时步骤。
设想一下像“iPhone 15 price”或“Weather today”这类热门查询,每天会被搜索成千上万次。只需计算一次,后续所有相同查询都可以复用结果。缓存机制能同时大幅降低搜索延迟和基础设施的计算成本。
总结
向量搜索将信息检索从字面匹配带入了语义理解的新时代。然而,仅仅拥有 Embedding 技术还不够,真正让系统在生产环境中稳定、高效运行的是背后的工程优化:混合搜索打通了词法与语义的桥梁;ANN 索引和向量压缩技术解决了性能瓶颈;而分布式架构与缓存策略则支撑起了大规模、高并发的部署需求。
本文相关代码可参考:https://github.com/Pawan-145/Vector-Search
如果你对构建高性能的搜索系统或 人工智能 应用的其他方面有更多兴趣,欢迎到 云栈社区 与更多开发者交流探讨。
 发表于 2026-2-26 04:43:07
|
查看: 167|
回复: 0
发表于 2026-2-26 04:43:07
|
查看: 167|
回复: 0
